
概要
この記事では、Dorisのcompute-storage coupledモードとcompute-storage decoupledモードの違い、利点、適用シナリオを紹介し、ユーザーの選択の参考を提供します。
以下のセクションでは、compute-storage decoupledモードでのApache Dorisのデプロイと使用方法について詳しく説明します。compute-storage coupledモードでのデプロイについては、クラスター Deploymentセクションを参照してください。
Compute-storage coupled VS decoupled
Dorisの全体アーキテクチャは、Frontend(FE)とBackend(BE)の2種類のプロセスで構成されています。FEは主にユーザーリクエストアクセス、クエリ解析と計画、メタデータ管理、ノード管理を担当します。BEはデータストレージとクエリプラン実行を担当します。(詳細情報)
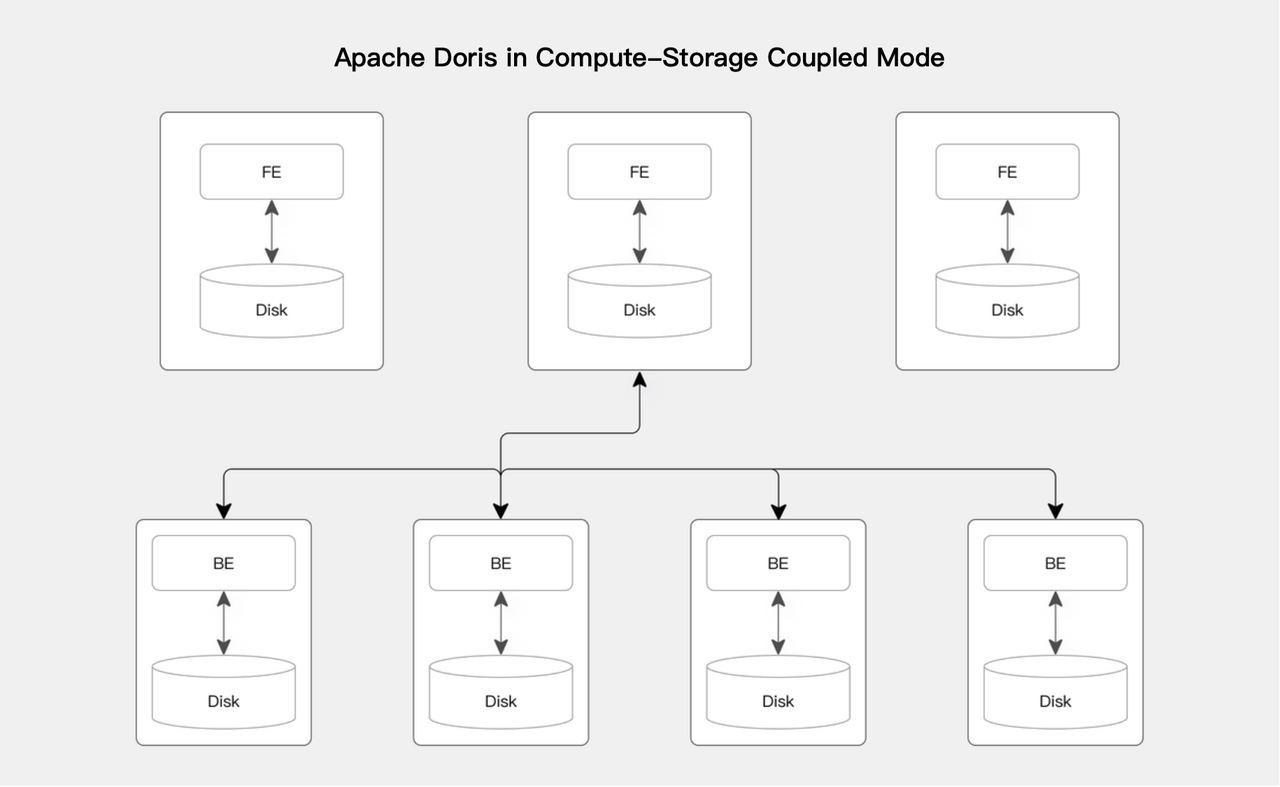
Compute-storage coupled
compute-storage coupledモードでは、BEノードはデータストレージと計算の両方を実行し、複数のBEノードがmassively parallel processing(MPP)分散コンピューティングアーキテクチャを形成します。
Compute-storage decoupled
BEノードはプライマリデータを保存しなくなります。代わりに、共有ストレージレイヤーが統一されたプライマリデータストレージとして機能します。さらに、基盤となるオブジェクトストレージシステムの制限とネットワーク伝送のオーバーヘッドによって引き起こされるパフォーマンス損失を克服するために、Dorisはローカルコンピュートノードに高速キャッシュを導入しています。
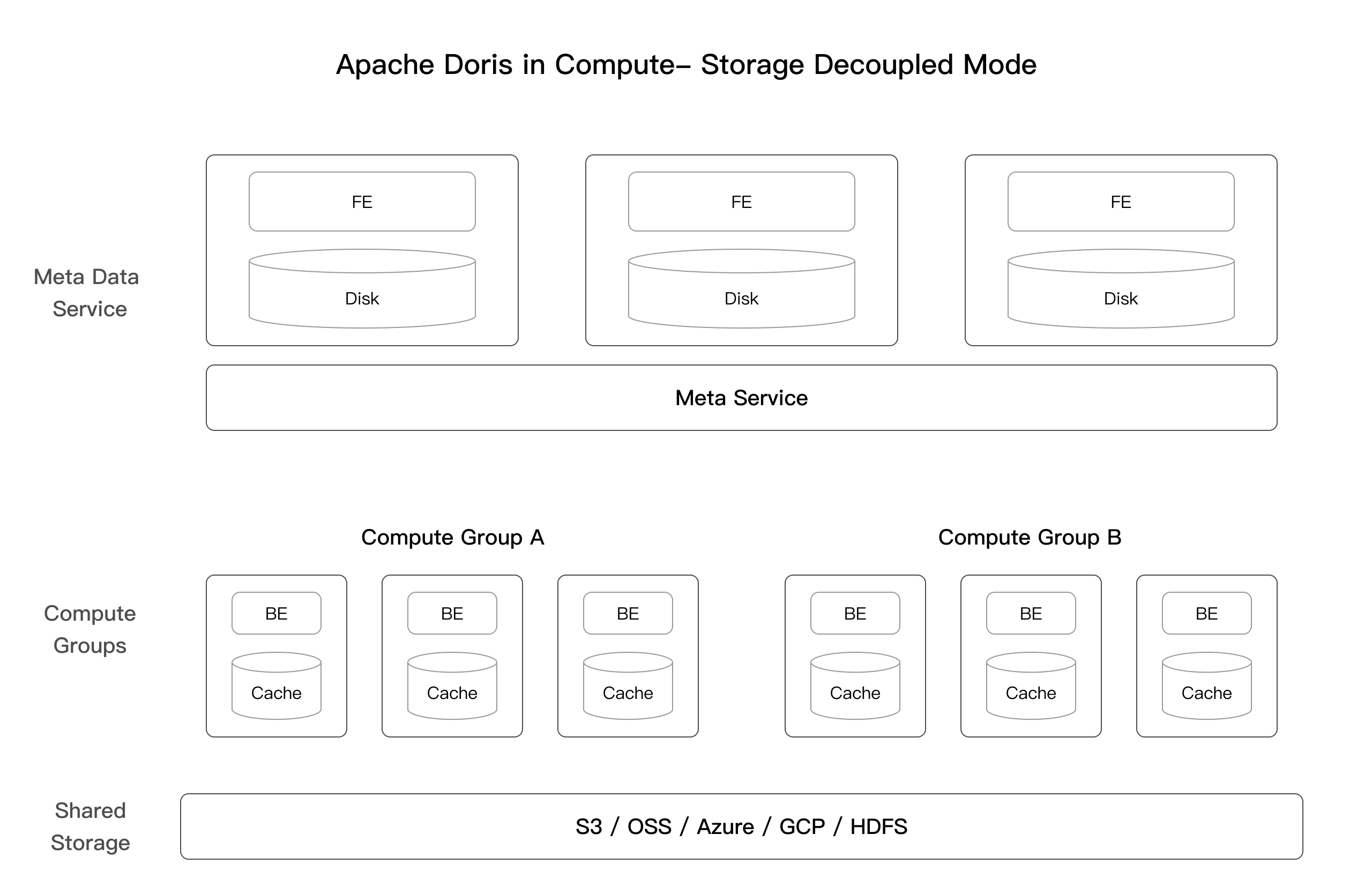
Meta dataレイヤー:
FEはメタデータ、ジョブ情報、権限、その他のMySQLプロトコル依存データを格納します。
Meta Serviceは、compute-storage decouplingモードでのDorisメタデータサービスです。データインポートトランザクション処理、tablet meta、rowset meta、クラスターリソース管理を担当します。これは水平スケール可能なステートレスサービスです。
Computationレイヤー:
compute-storage decoupledモードでは、BEノードはステートレスです。クエリパフォーマンスを向上させるために、tabletメタデータとデータの一部をキャッシュします。
compute clusterは、コンピューティングリソースとして機能するステートレスBEノードのコレクションです。複数のcompute clusterが単一のデータセットを共有し、compute clusterは必要に応じてノードを追加または削除することで弾力的にスケールできます。
compute-storage decoupledモードでのcompute clusterの概念は、[クラスター Deployment]と[Create クラスター]セクションで説明されている「cluster」とは異なります。
compute-storage decoupledモードの文脈では、「Compute クラスター」は、[クラスター Deployment]と[Create クラスター]セクションで説明されている複数のApache Dorisノードで構成される完全な分散システムではなく、コンピューティングリソースとして機能するステートレスBEノードのコレクションを特に指します。
Shared storageレイヤー:
共有ストレージレイヤーは、segmentファイルと転置インデックスファイルを含むデータファイルを格納します。
選択方法
compute-storage coupledモードの利点
- シンプルなデプロイメント: Apache Dorisは外部の共有ファイルシステムやオブジェクトストレージに依存しません。物理サーバー上にFEとBEプロセスをデプロイするだけでクラスターをセットアップできます。クラスターは単一ノードから数百ノードまでスケールできます。このようなアーキテクチャはシステムの安定性も向上させます。
- 高パフォーマンス: 計算を実行する際、Apache Dorisのコンピュートノードはローカルストレージに直接アクセスできます。これにより、マシンI/Oを完全に活用し、不要なネットワークオーバーヘッドを削減することで、より高いクエリパフォーマンスを実現できます。
compute-storage coupledモードの適用シナリオ
- Dorisのシンプルな使用や迅速な試用、または開発・テスト環境での使用の場合
- 信頼性の高い共有ストレージオプション(HDFS、Ceph、オブジェクトストレージなど)が不足している場合
- 会社の異なる事業チームがApache Dorisを独立して保守し、Dorisクラスターを管理する専任のDBAスタッフがいない場合
- 高弾性スケーラビリティが不要で、Kubernetesコンテナ化が不要で、パブリッククラウドやプライベートクラウドでの実行が不要な場合
compute-storage decoupledモードの利点
- 弾性コンピューティングリソース: Apache Dorisでは、異なる時点で異なる規模のコンピューティングリソースを使用して、異なるビジネスリクエストに対応できます。簡単に言えば、コストを節約するためのオンデマンドコンピューティングリソースをサポートします。
- (完全な)ワークロードの分離: 異なる事業チームが共有データの上で自分たちのコンピューティングリソースを分離できるため、安定性と高効率の両方を提供します。
- 低ストレージコスト: 計算とストレージを分離することで、オブジェクトストレージ、HDFS、その他の低コストストレージソリューションの使用が可能になります。
compute-storage decoupledモードの適用シナリオ
- すでにパブリッククラウドサービスを採用している場合
- HDFS、Ceph、オブジェクトストレージなどの信頼性の高い共有ストレージシステムがある場合
- 高弾性スケーラビリティ、Kubernetesコンテナ化、またはプライベートクラウドでの実行が必要な場合
- 複数のコンピューティンググループがデータを共有できる高スループット共有ストレージ機能がある場合
- 会社全体のデータウェアハウスプラットフォームの保守を担当する専任チームがいる場合