
リリース 3.0.0
Apache Doris 3.0 のリリースを発表できることを嬉しく思います!
バージョン 3.X から、Apache Doris はクラスタ展開において、従来のコンピュート・ストレージ結合モードに加えて、コンピュート・ストレージ分離モードをサポートします。コンピュート層とストレージ層を分離するクラウドネイティブアーキテクチャにより、ユーザーは複数のコンピュートクラスタ間でクエリ負荷の物理的分離、および読み書き負荷の分離を実現できます。さらに、ユーザーはオブジェクトストレージや HDFS などの低コストの共有ストレージシステムを活用して、ストレージコストを大幅に削減できます。
バージョン 3.0 は、Apache Doris が統合データレイクおよびデータウェアハウスアーキテクチャに向けて進化する上でのマイルストーンです。このバージョンでは、データレイクへのデータ書き戻し機能が導入され、ユーザーは Apache Doris 内で複数のデータソースにわたってデータ分析、共有、処理、ストレージ操作を実行できます。非同期マテリアライズドビューなどの機能により、Apache Doris は企業向けの統合データ処理エンジンとして機能し、レイク、ウェアハウス、データベース間でのデータ管理をユーザーがより適切に行えるよう支援します。また、Apache Doris 3.0 では Trino Connector が導入されています。これにより、ユーザーはより多くのデータソースに迅速に接続または適応でき、Doris の高性能コンピュートエンジンを活用して Trino よりも高速なクエリ結果を提供できます。
バージョン 3.0 では ETL バッチ処理シナリオのサポートも強化され、insert into select、delete、update などの操作に対する明示的なトランザクションサポートが追加されています。クエリ実行の可観測性も向上しました。
パフォーマンスの面では、バージョン 3.0 でクエリオプティマイザーのフレームワーク機能、インフラストラクチャ、ルールを改善しました。これにより最適化されたパフォーマンスを提供し、より複雑で多様なビジネスシナリオでのブラインドテストによって実証されています。
適応型 Runtime Filter 計算方式は、実行時にデータサイズに基づいてフィルターを正確に推定し、大容量データと高負荷下でより良いパフォーマンスを実現します。さらに、非同期マテリアライズドビューは、クエリ高速化とデータモデリングにおいてより安定し、ユーザーフレンドリーになりました。
バージョン 3.0 の開発期間中、200名を超えるコントリビューターが Apache Doris に約5,000件の最適化と修正を提出しました。VeloDB、Baidu、Meituan、ByteDance、Tencent、Alibaba、Kwai、Huawei、Tianyi Cloud などの企業のコントリビューターがコミュニティと積極的に協力し、実際の使用事例からテストケースを提供して Apache Doris の改善を支援しました。このリリースの開発、テスト、フィードバックプロセスに関わったすべてのコントリビューターに心から感謝いたします。
1. コンピュート・ストレージ分離モード
V3.0 から、Apache Doris はコンピュート・ストレージ分離モードをサポートします。ユーザーはクラスタ展開時に、このモードとコンピュート・ストレージ結合モードのいずれかを選択できます。
コンピュート・ストレージ分離モードでは、BE ノードはもはやデータを保存せず、代わりに共有ストレージ層(HDFS とオブジェクトストレージ)が共有データストレージ層として導入されます。コンピューティングリソースとストレージリソースを独立してスケールでき、ユーザーに複数の利点をもたらします:
-
ワークロード分離: 複数のコンピュートクラスタが同じデータを共有できるため、ユーザーは別々のコンピュートクラスタを使用して異なるビジネスワークロードやオフライン負荷を分離できます。
-
ストレージコストの削減: 全データセットはより費用対効果が高く高信頼性の共有ストレージに保存され、ホットデータのみがローカルにキャッシュされます。3つのデータレプリカを持つコンピュート・ストレージ結合モードと比較して、ストレージコストを最大90%削減できます。
-
弾性的なコンピューティングリソース: BE ノードにデータが保存されないため、負荷要件に基づいてコンピューティングリソースを柔軟にスケールできます。ユーザーは個別のコンピュートクラスタをスケールインまたはスケールアウトしたり、コンピュートクラスタの数を増減したりできます。これもコスト削減につながります。
-
システム堅牢性の向上: データを共有ストレージに保存することで、Doris は複雑なマルチレプリカ整合性のロジックを処理する必要がなくなり、分散ストレージの複雑さが簡素化され、システム全体の堅牢性が向上します。
-
柔軟なデータ共有とクローン: コンピュート・ストレージ分離モードの柔軟性は、単一の Doris クラスタを超えて拡張されます。ある Doris クラスタのテーブルを別の Doris クラスタに簡単にクローンでき、メタデータの複製だけで済みます。
1-1. 結合から分離へ
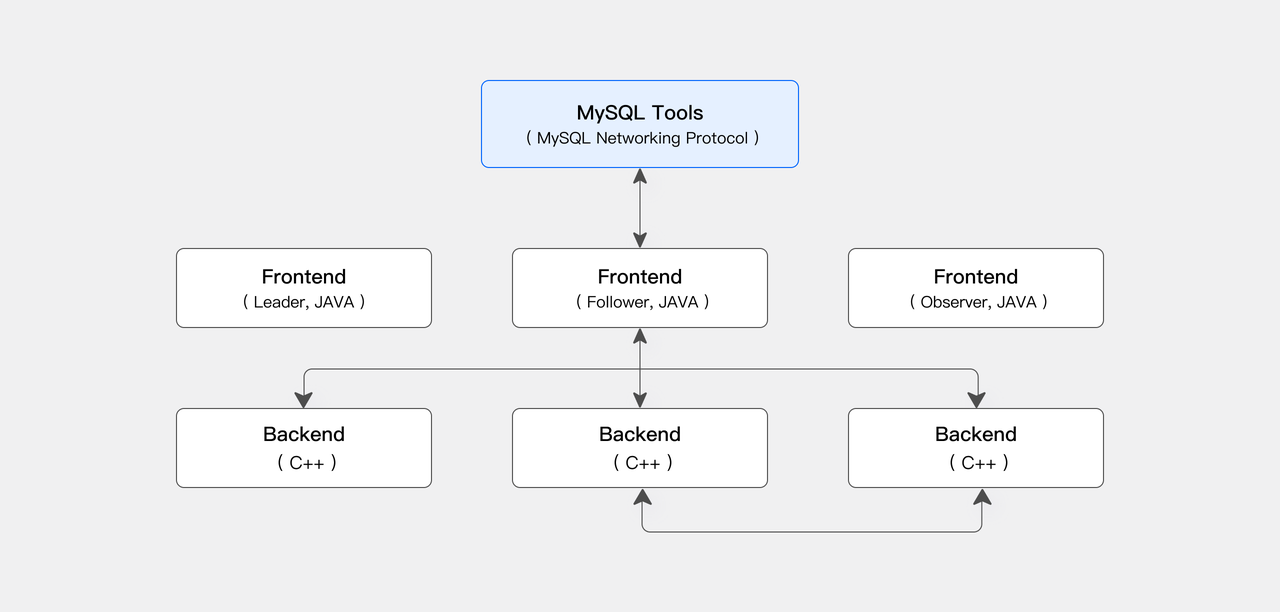
コンピュート・ストレージ結合モードでは、Apache Doris アーキテクチャは主に2つのプロセスタイプで構成されます:Frontend(FE)と Backend(BE)です。FE は主にユーザーリクエストアクセス、クエリ解析と計画、メタデータ管理、ノード管理を担当します。BE はデータストレージとクエリプラン実行を担当します。
BE ノードは MPP(Massively Parallel Processing)分散コンピューティングアーキテクチャを採用し、マルチレプリカ整合性プロトコルを活用して高いサービス可用性と高いデータ信頼性を確保します。
パブリッククラウド、プライベートクラウド、Kubernetes ベースのコンテナプラットフォームなどの新しいクラウドコンピューティングインフラストラクチャの成熟により、クラウドネイティブ機能の需要が高まっています。ますます多くのユーザーが、より多くの弾力性を提供するために Apache Doris とクラウドコンピューティングインフラストラクチャのより深い統合を求めています。
このニーズに対応するため、VeloDB チームは VeloDB Cloud として知られるコンピュートとストレージを分離した Apache Doris のクラウドネイティブバージョンを設計・実装しました。長期間にわたって数百の企業での広範囲な本番テストと改良を経て、このクラウドネイティブソリューションは Apache Doris コミュニティに貢献され、コンピュート・ストレージ分離モードの Apache Doris 3.0 として実現されました。
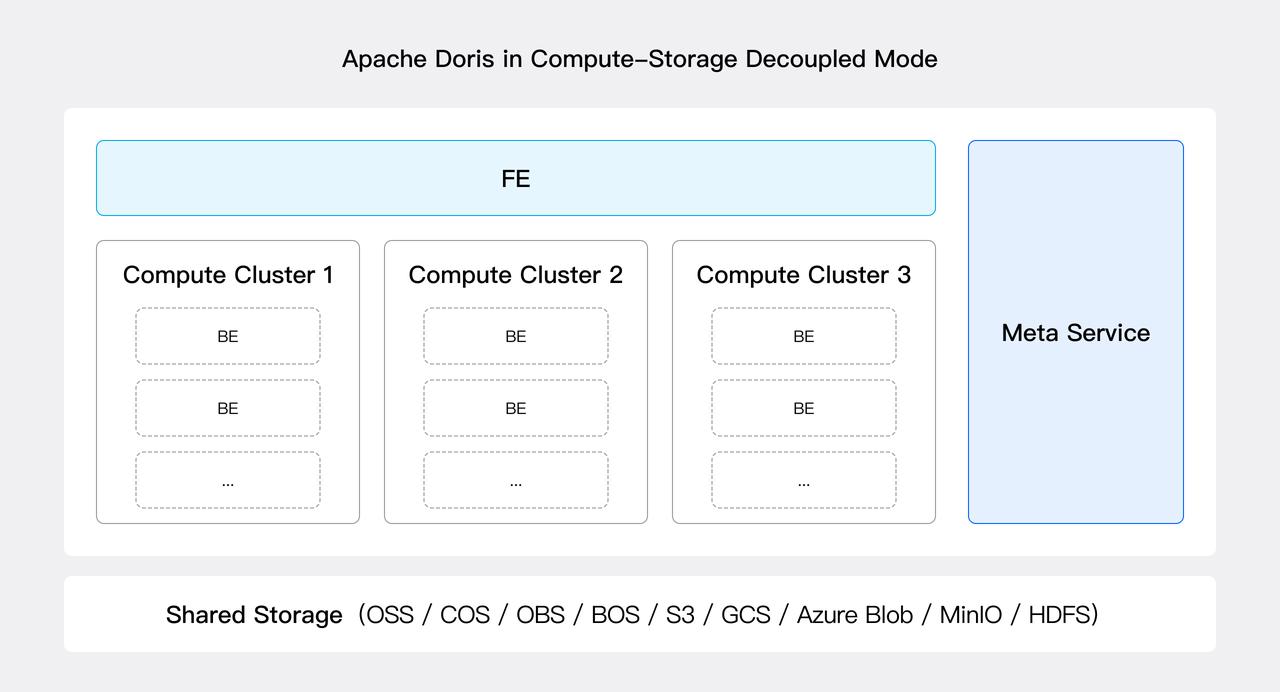
コンピュート・ストレージ分離モードでは、Apache Doris アーキテクチャは3つの層で構成されます:
- メタデータ層: データベースとテーブル情報、スキーマ、rowset メタ、トランザクションなどのメタデータサービスを提供する新しい Meta Service モジュールが導入されました。Meta Service はステートレスで水平スケーラブルです。V3.0 では、BE のすべてのメタデータと FE のメタデータの一部が Meta Service に移行されました。残りの移行は将来のバージョンで完了する予定です。
- コンピュート層: ステートレス BE ノードはクエリプランを実行し、クエリパフォーマンスを向上させるためにデータとタブレットメタデータの一部をローカルにキャッシュします。複数のステートレス BE ノードはコンピューティングリソースプール(つまり、コンピュートクラスタ)に編成でき、複数のコンピュートクラスタは同じデータとメタデータサービスを共有できます。コンピュートクラスタは必要に応じてノードを追加または削除することで弾力的にスケールできます。
- 共有ストレージ層: データは共有ストレージ層に永続化され、現在は HDFS および S3 プロトコルと互換性のある様々なクラウドベースオブジェクトストレージシステム(S3、OSS、GCS、Azure Blob、COS、BOS、MinIO など)をサポートします。
1-2 設計の特徴
Apache Doris のコンピュート・ストレージ分離モードの設計では、FE のインメモリメタデータモデルを共有メタデータサービスに変換することがハイライトされています。このアプローチにより、グローバルに一貫した状態ビューが提供され、どのノードでも FE を通した公開を必要とせずに直接書き込みを送信できます。書き込み操作中、データは共有ストレージに保存され、メタデータはメタデータサービスによって管理されます。これにより共有ストレージ内の小ファイル数が効果的に制御されます。同時に、個別テーブルのリアルタイム書き込みパフォーマンスは、コンピュート・ストレージ結合モードとほぼ同等です。システム全体の書き込み容量は、もはや単一 FE ノードの処理能力によって制限されません。
グローバルに一貫した状態ビューに基づき、データガベージコレクションについては、正確性の証明が容易でより効率的なデータ削除の設計アプローチを採用しました。
具体的には、共有ストレージ内のデータは、共有メタデータサービスが提供するグローバルに一貫したビューに組み込まれます。データが生成される際は常に、それを独立した個別のトランザクションにバインドします。同様に、メタデータ削除操作についても、それを独立した個別のトランザクションにバインドします。このアプローチの目的は、削除操作と書き込み操作が同時に成功することがないよう保証することです。ビューは削除が必要なデータを記録し、非同期削除プロセスは逆方向のガベージコレクションを必要とせず、トランザクション記録に基づいてデータの前方削除を単純に実行できます。
FE 内のタブレット関連メタデータが共有メタデータサービスに徐々に移行されるにつれ、Doris クラスタのスケーラビリティは単一 FE ノードのメモリ容量によって制約されなくなります。共有メタデータサービスと前方データ削除技術に基づき、データ共有や軽量クローンなどの機能を便利に拡張できます。
1-3 代替ソリューションとの比較
業界におけるコンピュートとストレージの分離の別の設計は、データと BE ノードメタデータを共有オブジェクトストレージまたは HDFS に保存することです。しかし、このアプローチには以下の問題があります:
-
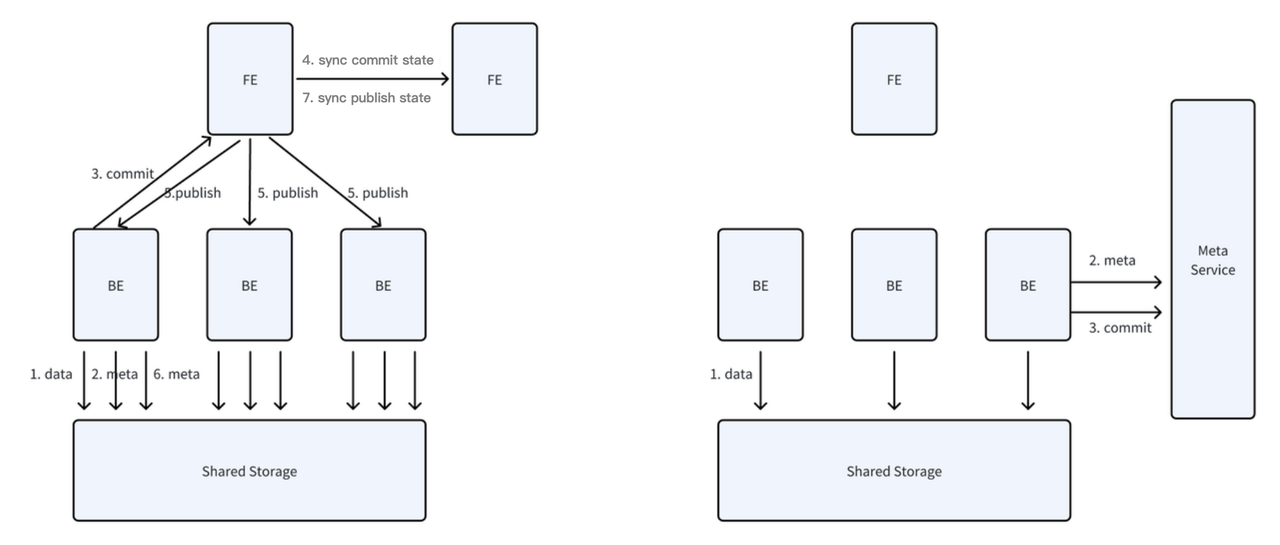
リアルタイム書き込みをサポートできない: データ書き込み中、データはパーティション分割とバケット分割ルールに基づいてタブレットにマッピングされ、セグメントファイルと rowset メタデータが生成されます。書き込みプロセス中、FE を通して2フェーズコミット(Publish)が実行されます。BE ノードが Publish リクエストを受信すると、rowset を可視に設定します。Publish 操作は失敗してはなりません。rowset メタデータが共有ストレージに保存される場合、リアルタイム書き込みプロセス中の小ファイルデータの総量は実際のデータファイルサイズの3倍になります - データファイルのレプリカ1つ、rowset メタデータ1つ、Publish 中の rowset メタデータ変更1つです。Publish 操作は単一 FE ノードによって駆動されるため、単一テーブルやシステム全体の書き込み容量が FE ノードの能力によって制限されます。
Apache Doris 3.0 のリアルタイムデータ書き込みパフォーマンスを上述のソリューションと比較しました。同じコンピューティングリソースを使用して、各500行の10,000データファイルを書き込む500並行タスクと、各20,000行の250データファイルを書き込む50並行タスクをシミュレートしました。
結果は、50並行タスクでは、コンピュート・ストレージ結合モードと分離モード両方での Apache Doris のマイクロバッチ書き込みパフォーマンスがほぼ同一である一方、業界ソリューションは Apache Doris より100倍遅いことを示しました。
500並行タスクでは、コンピュート・ストレージ分離モードでの Apache Doris のパフォーマンスはわずかに劣化しましたが、業界ソリューションより11倍の優位性を維持しました。公正なテストを保証するため、Apache Doris では Group Commit 機能を有効にしませんでした(業界ソリューションにはこの機能がありません)。Group Commit を有効にすると、リアルタイム書き込みパフォーマンスはさらに向上するでしょう。
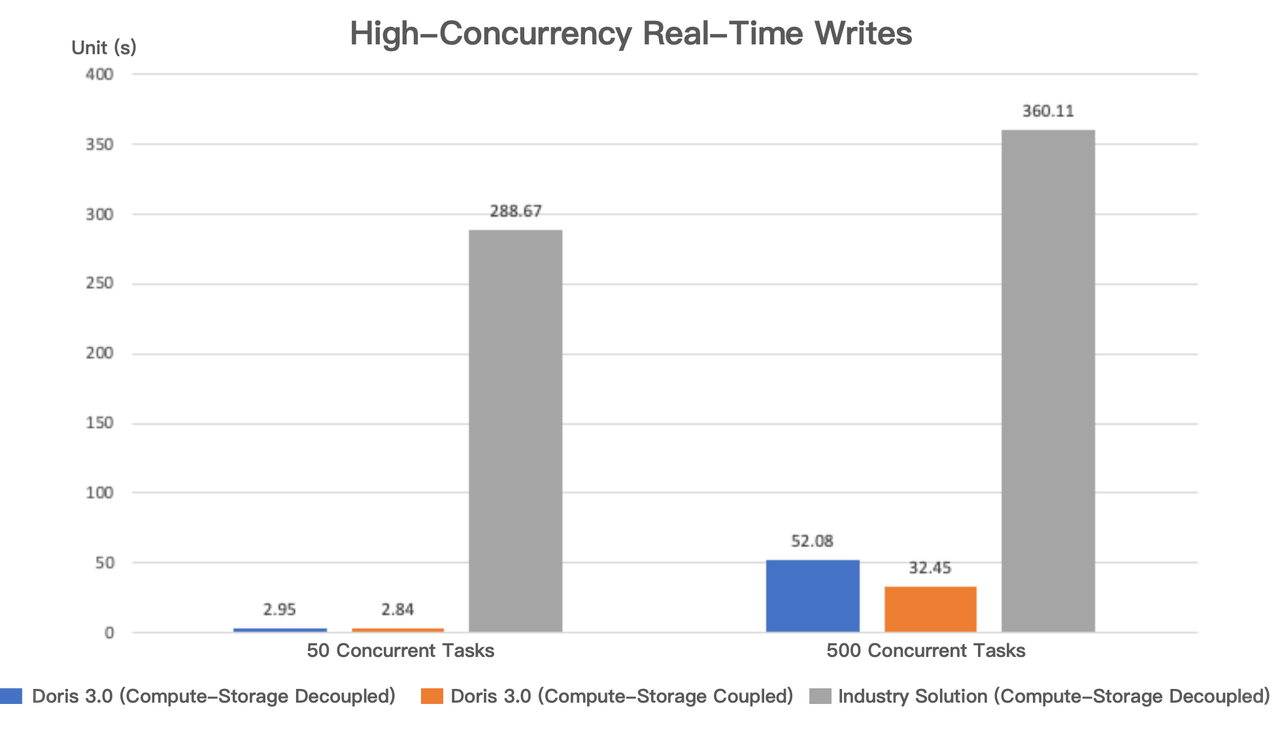
さらに、業界ソリューションはリアルタイムデータ取り込みにおいて安定性とコストの問題にも直面します:
-
安定性の懸念: 大量の小ファイルは共有ストレージ、特に HDFS に負荷をかけ、安定性リスクをもたらす可能性があります。
-
高いオブジェクトストレージリクエストコスト: 一部のパブリッククラウドオブジェクトストレージサービスでは、Put と Delete 操作が Get 操作と比較して10倍高い料金がかかります。大量の小ファイルは、ストレージコストを上回る可能性があるオブジェクトストレージリクエストコストの大幅な増加につながる可能性があります。
-
-
限定的なスケーラビリティ: コンピュート・ストレージ分離モデルの使用例では、FE(Frontend)メタデータが完全にインメモリであるため、より大きなデータストレージサイズを扱うことが多く、タブレット数が特定の高いレベル(例:数千万)に達すると、FE のメモリ圧迫がシステム全体の書き込みスループットを制限するボトルネックになる可能性があります。
-
潜在的なデータ削除ロジックの問題: コンピュート・ストレージ分離アーキテクチャでは、データは単一レプリカで保存されます。したがって、データ削除ロジックはシステムの信頼性にとって重要です。差分を比較してクロスシステムデータ削除を行う従来のアプローチは困難である可能性があります。書き込みプロセス中、削除と書き込みが同時に成功することを完全に避ける方法はなく、これがデータ損失につながる可能性があります。さらに、ストレージシステムで異常が発生した場合、差分計算に使用される入力が不正確である可能性があり、意図しないデータ削除につながる可能性があります。
-
データ共有と軽量クローン: 分離ストレージ・コンピュートアーキテクチャの柔軟性により、将来のデータ共有と軽量データクローンが可能になり、企業データ管理の負担を軽減できます。しかし、各クラスタが別々の FE を持つ場合、クラスタ間でデータをクローンした後、どのデータがもはや参照されておらず安全に削除できるかを正確に決定することが困難になります。クラスタ間参照の計算は意図しないデータ削除を簡単に引き起こす可能性があるためです。
FE の完全インメモリメタデータモデルを共有メタデータサービスに進化させることで、Apache Doris 3.0 は上述のすべての問題を回避します。
1-4 クエリパフォーマンス比較
コンピュート・ストレージ分離モードでは、リモート共有ストレージシステムからデータを読み取る必要があり、主なボトルネックはコンピュート・ストレージ結合モードでのディスク I/O ではなくネットワーク帯域幅になります。
データアクセスを高速化するため、Apache Doris はローカルディスクベースの高速キャッシュメカニズムを実装し、LRU(Least Recently Used)と TTL(Time-To-Live)の2つのキャッシュ管理ポリシーを提供します。新しくインポートされたデータは非同期でキャッシュに書き込まれ、最新データへの初回アクセスを高速化します。クエリで必要なデータがキャッシュにない場合、システムはリモートストレージからメモリにデータを読み取り、後続のクエリのために同期的にキャッシュに書き込みます。
複数のコンピュートクラスタを含む使用例では、Apache Doris はキャッシュ予熱機能を提供します。新しいコンピュートクラスタが確立された際、ユーザーは特定のデータ(テーブルやパーティションなど)を予熱してクエリ効率をさらに向上させることを選択できます。
この文脈で、TPC-DS 1TB テストデータセットを使用して、コンピュート・ストレージ結合モードと分離モードの両方で異なるキャッシュ戦略のパフォーマンステストを実施しました。結果は以下のようにまとめられます:
-
キャッシュが完全にヒットした場合(つまり、クエリに必要なすべてのデータがキャッシュにロードされる)、コンピュート・ストレージ分離モードのクエリパフォーマンスはコンピュート・ストレージ結合モードと同等です。
-
キャッシュが部分的にヒットした場合(つまり、テスト前にキャッシュがクリアされ、テスト中にデータが徐々にキャッシュにロードされ、パフォーマンスが継続的に向上する)、コンピュート・ストレージ分離モードのクエリパフォーマンスはコンピュート・ストレージ結合モードより約10%低くなります。このテストシナリオは実際の使用例に最も近いものです。
-
キャッシュが完全にミスした場合(つまり、すべての SQL 実行前にキャッシュがクリアされ、極端なケースをシミュレート)、パフォーマンス損失は約35%です。それでも、コンピュート・ストレージ分離モードの Apache Doris は代替ソリューションよりもはるかに高いパフォーマンスを提供します。
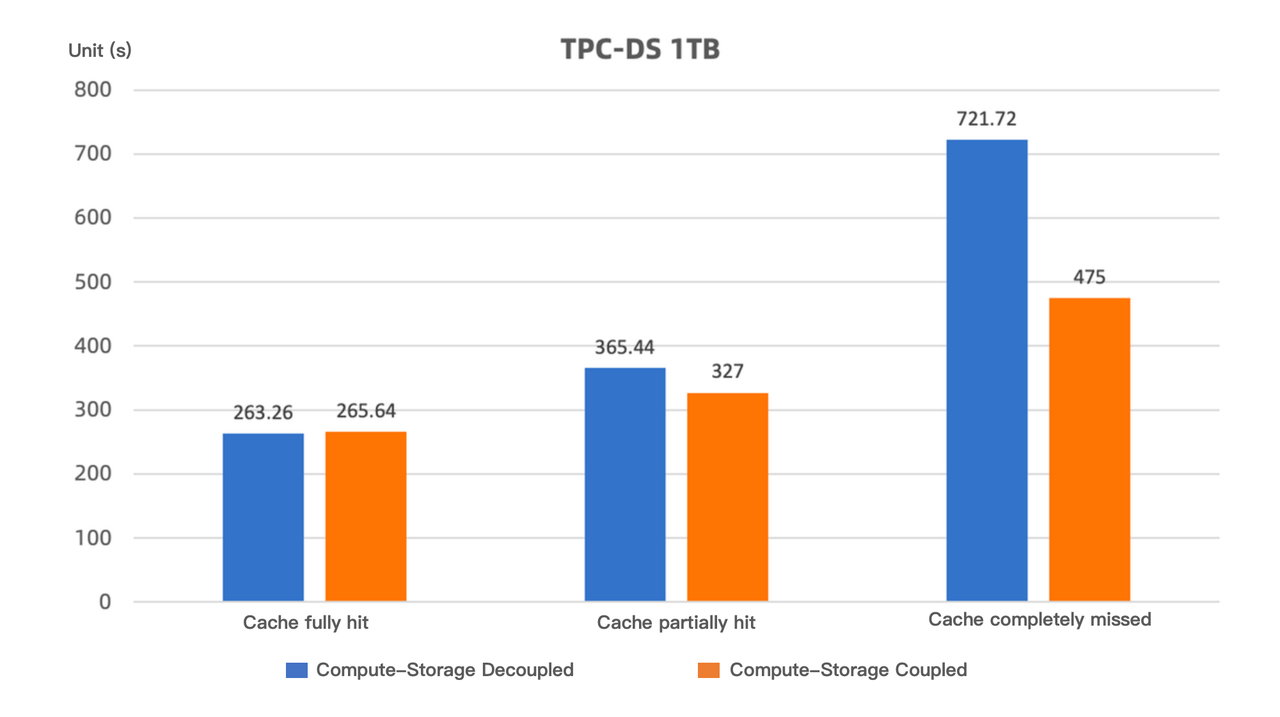
1-5 書き込み速度比較
書き込みパフォーマンスについては、同じコンピューティングリソース下で2つのテストケースをシミュレートしました:バッチインポートと高並行リアルタイムインポートです。コンピュート・ストレージ結合モードと分離モードの書き込みパフォーマンス比較は以下の通りです:
-
バッチインポート: 1TB TPC-H と 1TB TPC-DS テストデータセットをインポートする際、単一レプリカ構成下で、コンピュート・ストレージ分離モードの書き込みパフォーマンスはコンピュート・ストレージ結合モードよりそれぞれ 20.05% と 27.98% 高くなりました。バッチインポート中、セグメントファイルサイズは一般的に数十から数百 MB の範囲です。コンピュート・ストレージ分離モードでは、セグメントファイルがより小さなファイルに分割され、オブジェクトストレージに並行してアップロードされるため、ローカルディスクへの書き込みと比較してより高いスループットが得られます。実際の展開では、コンピュート・ストレージ結合モードは通常3つのレプリカを使用するため、コンピュート・ストレージ分離モードの書き込み速度の優位性はさらに顕著になります。
-
高並行リアルタイムインポート: 「代替ソリューションとの比較」セクションで説明した通りです。
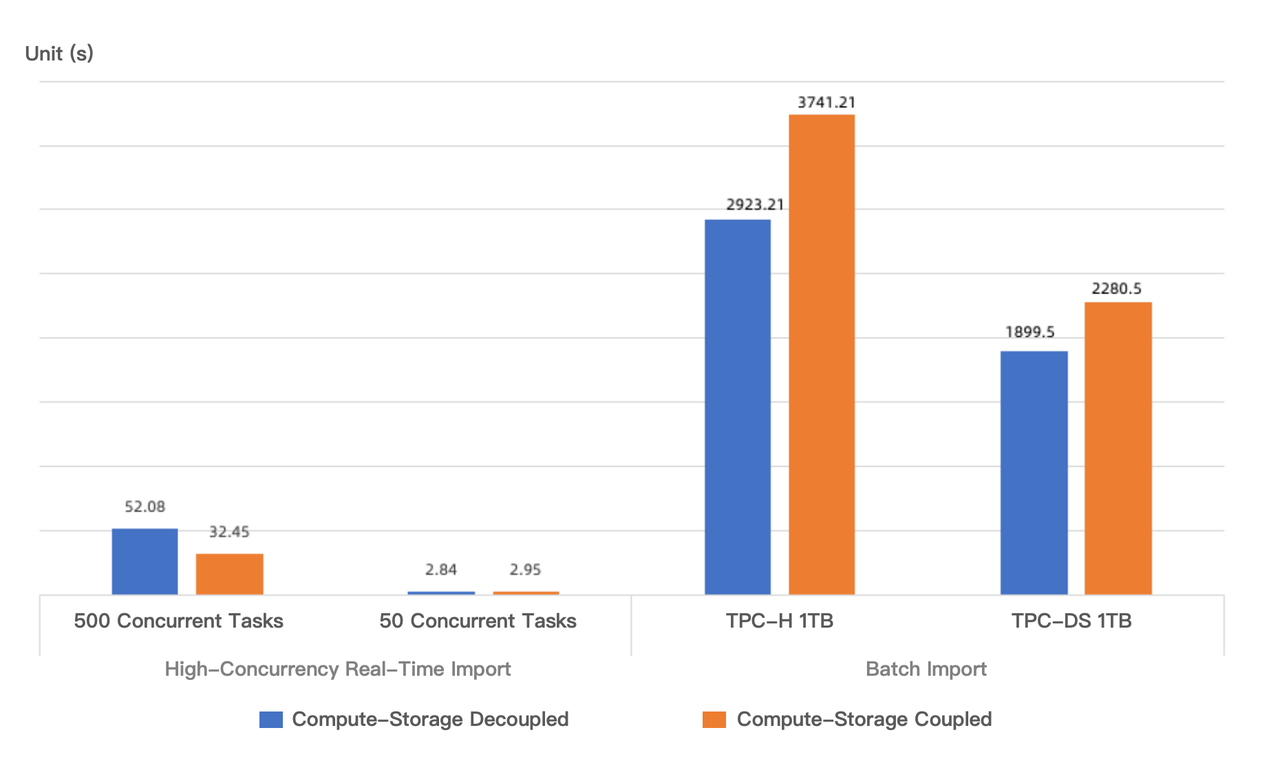
1-6 本番環境での Tips
-
パフォーマンス: リアルタイムデータ分析では、ユーザーはキャッシュに TTL(Time-To-Live)を指定し、新しく取り込まれたデータをキャッシュに書き込むことで、コンピュート・ストレージ結合モードに匹敵するクエリパフォーマンスを実現できます。クエリジッターを防ぐため、ユーザーはデータの使用頻度に基づいて、コンパクションやスキーマ変更などのバックグラウンドタスクによって生成されたデータをキャッシュできます。
-
ワークロード分離: ユーザーは複数のコンピュートクラスタを使用して、異なるビジネスの物理リソース分離を実現できます。単一コンピュートクラスタ内でのワークロード分離については、ユーザーは Workload Group メカニズムを利用して、異なるクエリのリソースを制限および分離できます。
1-7 注意事項
-
Apache Doris 3.0 はコンピュート・ストレージ結合モードとコンピュート・ストレージ分離モードの共存をサポートしません。ユーザーはクラスタ展開時にそのうちの1つを指定する必要があります。
-
ユーザーがコンピュート・ストレージ結合モードを必要とする場合は、展開とアップグレードについてドキュメントに従ってください。迅速な展開とクラスタアップグレードには Doris Manager の使用を推奨します。ただし、コンピュート・ストレージ分離モードは Doris Manager の展開とアップグレードをまだサポートしていません。将来のバージョンでより良いサポートのために継続的な改良を行います。
-
現在、Apache Doris は V2.1 から V3.0 のコンピュート・ストレージ分離モードへのインプレースアップグレードをサポートしていません。このような目的には、ユーザーはコンピュート・ストレージ分離クラスタを展開した後にデータ移行を実行する必要があります。将来的には、CCR(Change Data Capture)機能を通してサービス中断なしの移行をサポートする予定です。
2. データレイクハウス
Apache Doris はリアルタイムデータウェアハウスとして位置付けられていますが、それをはるかに超える存在です。以前のバージョンでは、従来のデータウェアハウス機能の境界を一貫して押し広げ、統合データレイクハウスに向けて前進してきました。バージョン 3.0 はこの旅路におけるマイルストーンであり、レイクハウスアーキテクチャでの機能が完全に成熟しました。統合レイクハウスは境界のないデータとレイクハウス融合によって特定されると考えています:
境界のないデータ: Apache Doris は統合クエリ処理エンジンとして機能し、異なるシステム間でのデータ境界を打破します。データウェアハウス、データレイク、データストリーム、ローカルデータファイルを含むすべてのデータソースにわたって、一貫した超高速分析体験を提供します。
-
レイクハウスクエリ高速化: データを Apache Doris に移行する必要なく、ユーザーは Doris の効率的なクエリエンジンを活用して、Iceberg、Hudi、Paimon などのデータレイクや Hive などのオフラインデータウェアハウスに保存されたデータを直接クエリし、クエリ分析を高速化できます。
-
フェデレート分析: カタログとストレージプラグインを拡張することで、Apache Doris はフェデレート分析機能を強化し、物理的に単一ストレージシステムにデータを集中化することなく、複数の異種データソースにわたって統合分析を実行できます。これにより外部テーブルクエリと内部・外部テーブル間のフェデレート結合が可能になり、データサイロを打破してグローバルに一貫したデータインサイトを提供します。
-
データレイク構築: Apache Doris は Hive と Iceberg への書き戻し機能を導入し、ユーザーが Doris を通じて直接 Hive と Iceberg テーブルを作成してデータを書き込めるように
BEGIN;
DELETE FROM table WHERE date >= "2024-07-01" AND date <= "2024-07-31";
INSERT INTO table SELECT * FROM stage_table;
COMMIT; -
失敗したタスクの処理を簡素化: 例えば、単一のトランザクション内で2つの
insert into select操作が実行される際、いずれかの操作が失敗した場合、直接再試行できます。BEGIN WITH LABEL label_etl_1;
INSERT INTO table1 SELECT * FROM stage_table1;
INSERT INTO table SELECT * FROM stage_table;
COMMIT;
ドキュメントを参照: https://doris.apache.org/docs/3.0/data-operate/transaction/ 現在、Cross-Cluster Replication (CCR)では明示的なトランザクション同期はサポートされていません。
4-2. 可観測性の向上
-
リアルタイムprofile取得: 以前のバージョンでは、実行計画やデータの問題により、複雑なクエリが高い計算要件を持つ場合がありました。そのため開発者はクエリの完了後にのみパフォーマンス分析のためのクエリprofileにアクセスできました。これにより、クエリ実行の問題を迅速に特定して本番環境の安定性を保証することが困難でした。リアルタイムprofileを取得する機能により、V3.0ではユーザーはクエリの実行中にクエリの実行を監視できます。また、各ETLジョブの進捗をより適切に監視することも可能です。
-
backend_active_tasksシステムテーブル:backend_active_tasksシステムテーブルは、各BEノード上の各クエリのリアルタイムリソース消費情報を提供します。ユーザーはSQLを使用してこのシステムテーブルを分析し、各クエリのリソース使用量を取得できます。これは大きなクエリや異常なワークロードを特定するのに役立ちます。
5. 非同期マテリアライズドビュー
V3.0では、非同期マテリアライズドビューがより高速で安定しています。また、クエリ高速化やデータモデリングシナリオにおいてよりユーザーフレンドリーです。透過的リライトのロジックを再構築し、その機能を拡張して2倍の高速化を実現しました。
5-1 リフレッシュ
-
パーティションによるマテリアライズドビューの増分更新とマテリアライズドビュー上のパーティションロールアップをサポートし、異なる粒度でのリフレッシュを可能にします。
-
ネストしたマテリアライズドビューをサポートし、これはデータモデリングシナリオで有用です。
-
非同期マテリアライズドビューでのインデックス作成とソートキー指定をサポートし、マテリアライズドビューがヒットした後のクエリパフォーマンスを向上させます。
-
マテリアライズドビューの原子的置き換えをサポートすることで、マテリアライズドビューDDLの使いやすさが向上し、マテリアライズドビューを利用可能な状態に保ちながらマテリアライズドビュー定義SQLの変更を可能にします。
-
マテリアライズドビューでの非決定論的関数をサポートし、日常的なマテリアライズドビュー作成により適しています。
-
トリガーベースのマテリアライズドビューリフレッシュをサポートし、ネストしたマテリアライズドビューによるデータモデリングでのデータ一貫性を保証します。
-
パーティション化されたマテリアライズドビューを構築するためのより広範なSQLパターンをサポートし、増分更新機能をより多くのユースケースで利用可能にします。
5-2 リフレッシュ安定性
- V3.0では、マテリアライズドビュー構築用のWorkload Groupの指定をサポートしています。これは、マテリアライズドビュー構築プロセスが使用するリソースを制限し、進行中のクエリに十分なリソースが利用可能な状態を保つためです。
5-3 透過的リライト
-
派生Joinを含む、より多くのJoinタイプの透過的リライトをサポートします。クエリとマテリアライズドビュー間でJoinタイプが一致しない場合でも、マテリアライズドビューがクエリに必要なすべてのデータを提供できる限り、追加の述語で補完することで透過的リライトを実行できます。
-
ロールアップ用のより多くの集約関数、およびGROUPING SETS、ROLLUP、CUBEなどの多次元集約のリライトをサポートし、マテリアライズドビューに集約が含まれていない場合の集約を含むクエリのリライトをサポートし、Join操作と式計算を簡素化します。
-
ネストしたマテリアライズドビューの透過的リライトをサポートし、複雑なクエリのより高いパフォーマンスを可能にします。
-
部分的に無効なパーティション化されたマテリアライズドビューに対して、V3.0ではデータ補完のためのベーステーブルの
Union Allをサポートし、パーティション化されたマテリアライズドビューの適用性を拡張します。
5-4 透過的リライトパフォーマンス
- 透過的リライトパフォーマンスを向上させるために継続的な最適化が行われ、バージョン2.1.0と比較して2倍の速度を達成しています。
6. パフォーマンス向上
6-1 よりスマートなオプティマイザー
V3.0では、クエリオプティマイザーがフレームワーク機能、分散プランサポート、オプティマイザーインフラストラクチャ、ルール拡張の面で強化されました。より複雑で多様なビジネスシナリオに対してより良い最適化機能を提供し、複雑なSQLに対してより高いブラインドテストパフォーマンスを実現します:
-
プラン列挙機能の向上: プラン列挙の鍵となる構造Memoが再構築され正規化されました。これにより、Cascadesフレームワークのプラン列挙における効率性とより良いプランを生成する可能性が向上しました。さらに、古いバージョンでのJoin Reorderプロセス中の不完全なカラムプルーニングが修正され、Join演算子の不要なオーバーヘッドが解消され、関連するシナリオでの実行パフォーマンスが向上しました。
-
分散プランサポートの向上: 分散クエリプランが強化され、集約、join、ウィンドウ関数操作が中間計算結果のデータ特性をより賢く識別し、効果のないデータ再分散操作を回避できるようになりました。同時に、マルチレプリカ連続実行モードでの実行を最適化し、よりデータキャッシュフレンドリーにしました。
-
オプティマイザーインフラストラクチャの向上: V3では、コストモデルと統計情報推定のいくつかの問題が修正されました。コストモデルの修正により、実行エンジンの進化により適応できるようになり、実行プランが以前のバージョンと比較してより安定しました。
-
Runtime Filterプランサポートの強化: Join Runtime Filterに基づいて、V3.0ではTopN Runtime Filterの機能を拡張し、TopN演算子を含むユースケースでより良いパフォーマンスを実現しました。
-
最適化ルールライブラリの充実: ユーザーフィードバックと内部テスト結果に基づいて、Intersect Reorderなどの最適化ルールを導入し、オプティマイザーのルールセットを充実させました。
6-2 自己適応Runtime Filter
以前のバージョンでは、Runtime Filterの生成は統計情報に基づくユーザーの手動設定に依存していました。しかし、特定のケースでの不正確な設定はパフォーマンスの不安定性を引き起こす可能性がありました。
V3.0では、Dorisは自己適応Runtime Filter計算アプローチを実装しています。これは、データサイズに基づいて実行時にRuntime Filterを高い精度で推定でき、大量データと高ワークロードのユースケースでより良いパフォーマンスを可能にします。
6-3 関数パフォーマンス最適化
- V3.0では数十の関数のベクトル化実装を改善し、一般的に使用される一部の関数で50%以上のパフォーマンス向上を実現しました。
- V3.0では、null許容データタイプの集約に対しても広範囲な最適化を行い、30%のパフォーマンス向上を実現しました。
6-4 ブラインドテストパフォーマンス向上
V3.0とV2.1でのブラインドテストでは、新バージョンがTPC-DSとTPC-Hベンチマークテストでそれぞれ7.3%と6.2%高速であることが示されました。
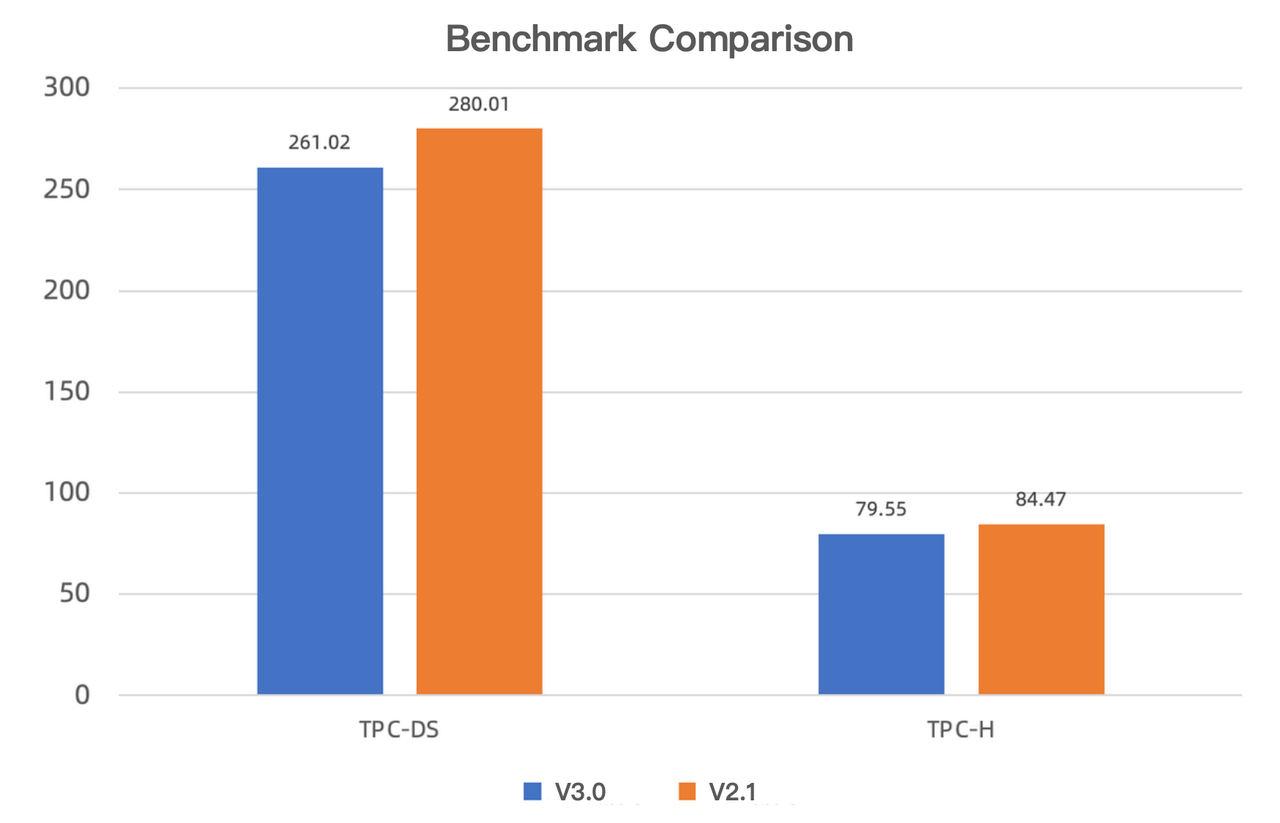
7. 新機能
7-1 Java UDTF
バージョン3.0ではJava UDTFのサポートが追加されました。主要な操作は以下のとおりです:
-
UDTFの実装: UDFと同様に、UDTFでは
evaluateメソッドの実装が必要です。UDTF関数の戻り値はArrayデータタイプである必要があることに注意してください。public class UDTFStringTest {
public ArrayList<String> evaluate(String value, String separator) {
if (value == null || separator == null) {
return null;
} else {
return new ArrayList<>(Arrays.asList(value.split(separator)));
}
}
} -
UDTFの作成: デフォルトでは、2つの対応する関数が作成されます -
java-utdfとjava-utdf_outer。_outerサフィックスは、テーブル関数が0行の出力を生成する場合に、NULLデータの単一行を追加します。CREATE TABLES FUNCTION java-utdf(string, string) RETURNS array<string> PROPERTIES (
"file"="file:///pathTo/java-udaf.jar",
"symbol"="org.apache.doris.udf.demo.UDTFStringTest",
"always_nullable"="true",
"type"="JAVA_UDF"
);
7-2 Generated column
Generated columnは、ユーザーが直接挿入や更新を行うのではなく、他の列の値から計算される特別な列です。式の結果を事前計算してデータベースに格納することをサポートし、頻繁なクエリや複雑な計算が必要なシナリオに適しています。
データのインポートや更新時に事前定義された式に基づいて結果を自動計算し、永続的に格納できます。これにより、後続のクエリでは複雑な計算を実行することなく、システムがこれらの計算結果に直接アクセスでき、クエリパフォーマンスが向上します。
Generated columnはV3.0からサポートされています。テーブル作成時に、列をgenerated columnとして指定できます。Generated columnはデータ書き込み時に定義された式に基づいて値を自動計算します。Generated columnではより複雑な式を定義できますが、値を明示的に書き込みや設定はできません。
8. 機能改善
8-1. Materialized view
マテリアライズドビューの選択ロジックをリファクタリングし、ルールベースオプティマイザー(RBO)からコストベースオプティマイザー(CBO)に移行しました。これにより選択ロジックが非同期マテリアライズドビューと一致します。この機能はデフォルトで有効になっています。何か問題が発生した場合は、set global enable_sync_mv_cost_based_rewrite = falseを使用してRBOモードに戻すことができます。
8-2. Routine Load
以前のバージョンでは、Routine Load機能はいくつかの使い勝手の課題に直面していました。BE nodes間でのタスクスケジューリングの不均衡、タスクスケジューリングの不適時性、複雑な設定要件(最適化のために複数のFEとBE設定を変更する必要)、全体的な安定性の不足(再起動やアップグレードでRoutine Loadジョブが頻繁に停止し、再開するために手動でのユーザー介入が必要)などです。
これらの問題に対処するため、Routine Load機能に大幅な最適化を行いました:
-
リソーススケジューリング:スケジューリングのバランスを改善し、BEノード間でタスクがより均等に分散されるようにしました。修復不可能なエラーが発生したジョブは迅速に停止され、無駄なスケジューリング試行でリソースを浪費することを避けます。さらに、スケジューリングプロセスの適時性を改善し、Routine Loadのインポートパフォーマンスを向上させました。
-
パラメータ設定:ほとんどの環境のユーザーは、最適化のためにFEとBEの設定を変更する必要がなくなりました。タイムアウトパラメータ付きの自動調整メカニズムを導入し、クラスター負荷が増加した際にタスクが継続的に再試行することを防ぎます。
-
安定性:FEフェイルオーバー、BEローリングアップグレード、Kafkaクラスター異常など、様々な例外シナリオでのDorisの堅牢性を強化し、継続的で安定した動作を保証しました。また、Auto Resumeメカニズムを最適化し、障害修復後にRoutine Loadが自動的に動作を再開できるようにし、手動でのユーザー介入の必要性を削減しました。
9. 動作変更
-
cpu_resource_limitはサポートされなくなり、すべてのタイプのリソース分離はWorkload Groupsを通じて実装されます。 -
Apache Doris 3.0以降のバージョンではJDK 17をご使用ください。推奨バージョンは
jdk-17.0.10_linux-x64_bin.tar.gzです。
今すぐApache Doris 3.0をお試しください!
バージョン3.0の正式リリース前に、Apache Dorisのcompute-storage decoupledモードは、数百の企業の本番環境で約2年間の広範囲なテストと最適化を受けました。多くのテクノロジー大手の貢献者がコミュニティと協力し、実際のビジネスニーズに基づいて大量のテストケースを提供しました。これによりバージョン3.0の使いやすさと安定性が厳格に検証されました。
compute-storage decouplingのニーズがあるユーザーには、バージョン3.0をダウンロードして直接体験することを強く推奨します。
今後は、リリースイテレーションサイクルを加速し、すべてのユーザーにより安定したバージョン体験を提供していきます。Apache Dorisコミュニティにぜひご参加いただき、コア開発者と直接交流してください。
クレジット
このバージョンの開発、テスト、フィードバックに参加していただいた以下の貢献者の皆様に特別な感謝を申し上げます:
@133tosakarin、@390008457、@924060929、@AcKing-Sam、@AshinGau、@BePPPower、@BiteTheDDDDt、@ByteYue、@CSTGluigi、@CalvinKirs、@Ceng23333、@DarvenDuan、@DongLiang-0、@Doris-Extras、@Dragonliu2018、@Emor-nj、@FreeOnePlus、@Gabriel39、@GoGoWen、@HappenLee、@HowardQin、@Hyman-zhao、@INNOCENT-BOY、@JNSimba、@JackDrogon、@Jibing-Li、@KassieZ、@Lchangliang、@LemonLiTree、@LiBinfeng-01、@LompleZ、@M1saka2003、@Mryange、@Nitin-Kashyap、@On-Work-Song、@SWJTU-ZhangLei、@StarryVerse、@TangSiyang2001、@Tech-Circle-48、@Thearas、@Vallishp、@WinkerDu、@XieJiann、@XuJianxu、@XuPengfei-1020、@Yukang-Lian、@Yulei-Yang、@Z-SWEI、@ZhongJinHacker、@adonis0147、@airborne12、@allenhooo、@amorynan、@bingquanzhao、@biohazard4321、@bobhan1、@caiconghui、@cambyzju、@caoliang-web、@catpineapple、@cjj2010、@csun5285、@dataroaring、@deardeng、@dongsilun、@dutyu、@echo-hhj、@eldenmoon、@elvestar、@englefly、@feelshana、@feifeifeimoon、@feiniaofeiafei、@felixwluo、@freemandealer、@gavinchou、@ghkang98、@gnehil、@hechao-ustc、@hello-stephen、@httpshirley、@hubgeter、@hust-hhb、@iszhangpch、@iwanttobepowerful、@ixzc、@jacktengg、@jackwener、@jeffreys-cat、@kaijchen、@kaka11chen、@kindred77、@koarz、@kobe6th、@kylinmac、@larshelge、@liaoxin01、@lide-reed、@liugddx、@liujiwen-up、@liutang123、@lsy3993、@luwei16、@luzhijing、@lxliyou001、@mongo360、@morningman、@morrySnow、@mrhhsg、@my-vegetable-has-exploded、@mymeiyi、@nanfeng1999、@nextdreamblue、@pingchunzhang、@platoneko、@py023、@qidaye、@qzsee、@raboof、@rohitrs1983、@rotkang、@ryanzryu、@seawinde、@shoothzj、@shuke987、@sjyango、@smallhibiscus、@sollhui、@sollhui、@spaces-X、@stalary、@starocean999、@superdiaodiao、@suxiaogang223、@taptao、@vhwzx、@vinlee19、@w41ter、@wangbo、@wangshuo128、@whutpencil、@wsjz、@wuwenchi、@wyxxxcat、@xiaokang、@xiedeyantu、@xiedeyantu、@xingyingone、@xinyiZzz、@xy720、@xzj7019、@yagagagaga、@yiguolei、@yongjinhou、@ytwp、@yuanyuan8983、@yujun777、@yuxuan-luo、@zclllyybb、@zddr、@zfr9527、@zgxme、@zhangbutao、@zhangstar333、@zhannngchen、@zhiqiang-hhhh、@ziyanTOP、@zxealous、@zy-kkk、@zzzxl1993、@zzzzzzzs