
データバケッティング
パーティションは、ビジネスロジックに基づいてさらに異なるデータバケットに分割できます。各バケットは物理的なデータタブレットとして保存されます。適切なバケット戦略により、クエリ時にスキャンするデータ量を効果的に削減し、クエリパフォーマンスの向上とクエリ並行性の増加を実現できます。
バケット方式
Dorisは2つのバケット方式をサポートしています:Hash BucketingとRandom Bucketingです。
Hash Bucketing
テーブル作成時またはパーティション追加時、ユーザーはバケットカラムとして1つ以上のカラムを選択し、バケット数を指定する必要があります。同一パーティション内で、システムはバケットキーとバケット数に基づいてハッシュ計算を実行します。同じハッシュ値を持つデータは同じバケットに割り当てられます。例えば、下図では、パーティションp250102がregionカラムに基づいて3つのバケットに分割され、同じハッシュ値を持つ行が同じバケットに配置されています。
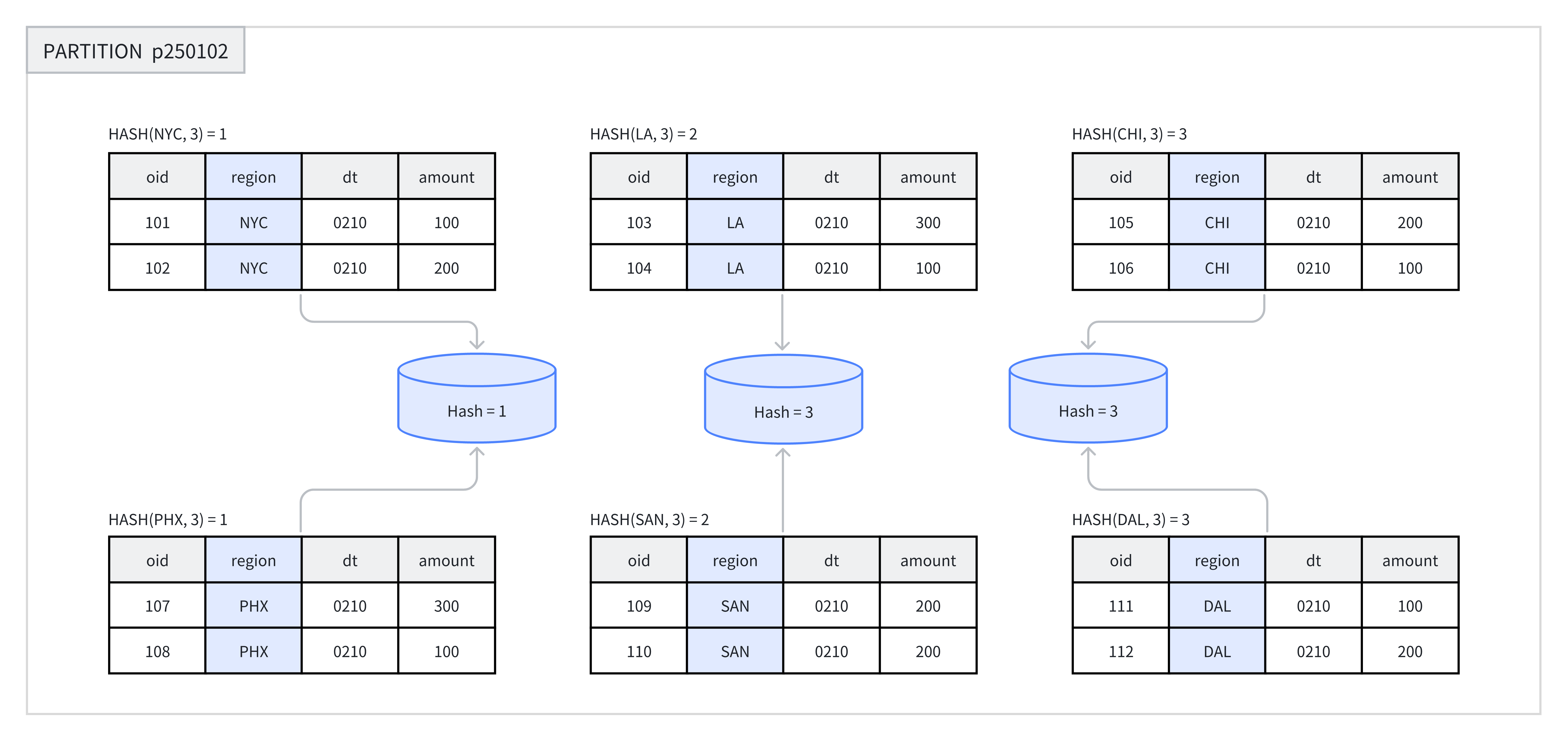
以下のシナリオでHash Bucketingの使用を推奨します:
-
ビジネスで特定のフィールドに基づく頻繁なフィルタリングが必要な場合、このフィールドをバケットキーとしてHash Bucketingに使用することで、クエリ効率を向上できます。
-
テーブル内のデータ分布が比較的均一な場合、Hash Bucketingも適切な選択肢です。
以下の例では、Hash Bucketingを使用してテーブルを作成する方法を示しています。詳細な構文については、CREATE TABLEステートメントを参照してください。
CREATE TABLE demo.hash_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
この例では、DISTRIBUTED BY HASH(region) がHash Bucketingの作成を指定し、bucket keyとして region 列を選択しています。一方、BUCKETS 8 は8個のbucketの作成を指定しています。
Random Bucketing
各パーティション内で、Random Bucketingは特定のフィールドのハッシュ値に依存せずに、データをさまざまなbucketにランダムに分散します。Random Bucketingは均一なデータ分散を保証し、不適切なbucket key選択によるデータスキューを回避します。
データインポート中、単一インポートジョブの各バッチはtabletにランダムに書き込まれ、均一なデータ分散が保証されます。例えば、1つの操作で、8つのデータバッチがパーティション p250102 の下の3つのbucketにランダムに割り当てられます。
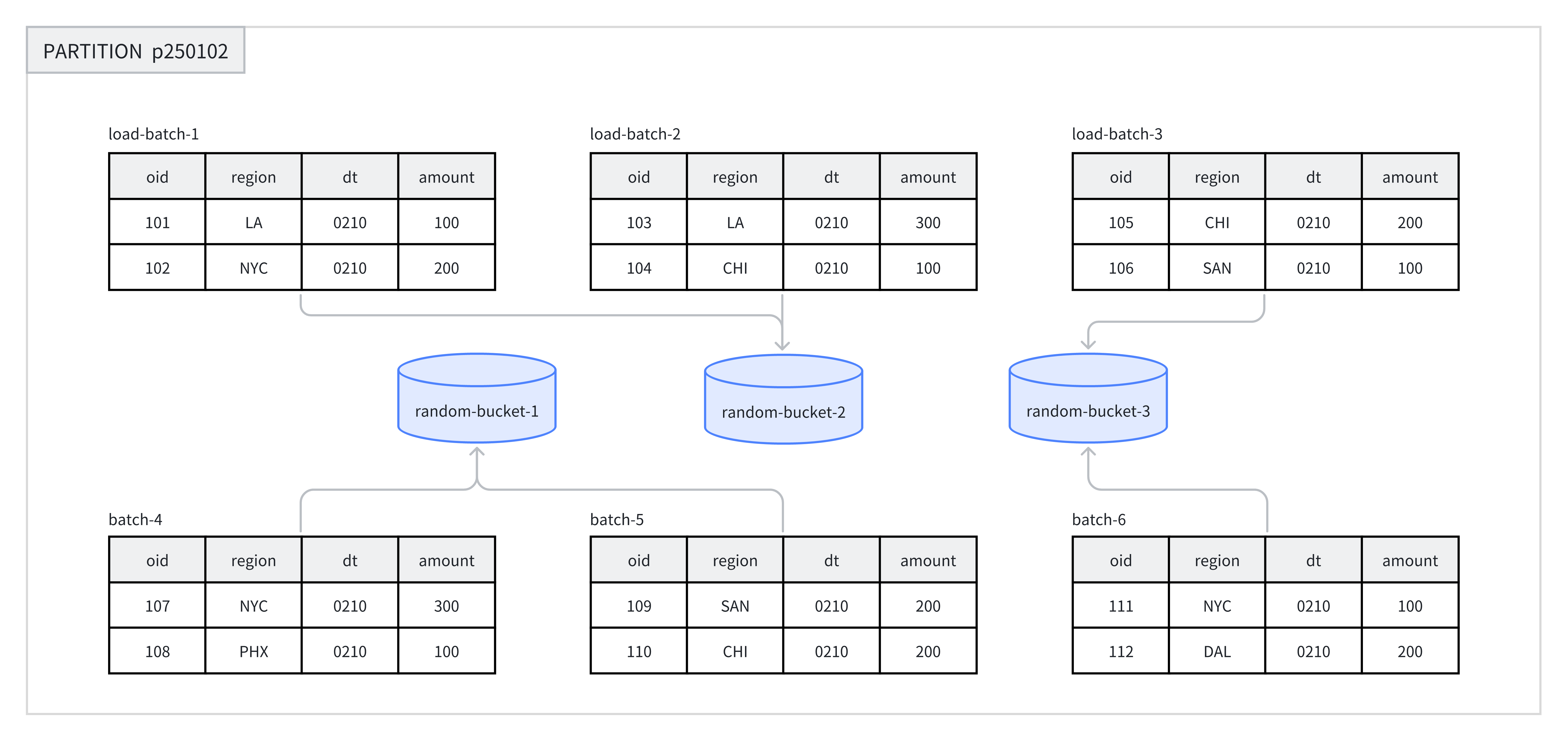
Random Bucketingを使用する場合、単一tabletインポートモード(load_to_single_tablet を true に設定)を有効にできます。大規模データインポート中、1つのデータバッチは1つのデータtabletにのみ書き込まれ、データインポートの同時実行性とスループットの向上に役立ち、データインポートとCompactionによる書き込み増幅を削減し、クラスタの安定性を確保します。
以下のシナリオでRandom Bucketingの使用を推奨します:
-
任意の次元分析のシナリオで、ビジネスが特定の列に基づくフィルタやjoinクエリを頻繁に行わない場合、Random Bucketingを選択できます。
-
頻繁にクエリされる列や列の組み合わせのデータ分散が極端に不均一な場合、Random Bucketingを使用することでデータスキューを回避できます。
-
Random Bucketingはbucket keyに基づくプルーニングができず、ヒットしたパーティション内のすべてのデータをスキャンするため、ポイントクエリのシナリオには推奨されません。
-
DUPLICATEテーブルのみがRandom partitioningを使用できます。UNIQUEおよびAGGREGATEテーブルはRandom Bucketingを使用できません。
以下の例では、Random Bucketingでテーブルを作成する方法を示しています。詳細な構文については、CREATE TABLE文を参照してください:
CREATE TABLE demo.random_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY RANDOM BUCKETS 8;
この例では、DISTRIBUTED BY RANDOMステートメントがRandom Bucketingの使用を指定しています。Random Bucketingの作成にはバケットキーの選択は必要なく、BUCKETS 8ステートメントが8個のバケットの作成を指定します。
バケットキーの選択
Hash Bucketingのみバケットキーの選択が必要です。Random Bucketingではバケットキーの選択は不要です。
バケットキーは1つまたは複数のカラムにすることができます。DUPLICATEテーブルの場合、任意のKeyカラムまたはValueカラムをバケットキーとして使用できます。AGGREGATEまたはUNIQUEテーブルの場合、段階的な集約を確実にするため、バケットカラムはKeyカラムである必要があります。
一般的に、以下のルールに基づいてバケットキーを選択できます:
-
クエリフィルタ条件の使用: Hash Bucketingにクエリフィルタ条件を使用することで、データのプルーニングに役立ち、データスキャン量を削減します;
-
高カーディナリティカラムの使用: Hash Bucketingに高カーディナリティ(多くのユニーク値)カラムを選択することで、各バケット間でデータを均等に分散するのに役立ちます;
-
高同時実行ポイントクエリシナリオ: バケットには単一のカラムまたはより少ないカラムを選択することを推奨します。ポイントクエリは1つのバケットのスキャンのみをトリガーし、異なるクエリが異なるバケットのスキャンをトリガーする確率が高いため、クエリ間のIO影響を削減します。
-
高スループットクエリシナリオ: データをより均等に分散させるため、バケットには複数のカラムを選択することを推奨します。クエリ条件がすべてのバケットキーの等価条件を含められない場合、クエリスループットが向上し、単一クエリのレイテンシが削減されます。
バケット数の選択
Dorisでは、バケットは物理ファイル(tablet)として保存されます。テーブル内のtablet数はpartition_num(パーティション数)にbucket_num(バケット数)を掛けた値と等しくなります。パーティション数が指定されると、変更することはできません。
バケット数を決定する際は、マシンの拡張を事前に考慮する必要があります。バージョン2.0以降、Dorisはマシンリソースとクラスタ情報に基づいてパーティション内のバケット数を自動的に設定することをサポートしています。
バケット数の手動設定
DISTRIBUTEDステートメントを使用してバケット数を指定できます:
-- Set hash bucket num to 8
DISTRIBUTED BY HASH(region) BUCKETS 8
-- Set random bucket num to 8
DISTRIBUTED BY RANDOM BUCKETS 8
bucket数を決定する際、通常は量と大きさという2つの原則に従います。この2つの間に競合がある場合、大きさの原則が優先されます:
-
大きさの原則: tabletの大きさは1-10GBの範囲内にすることが推奨されます。tabletが小さすぎると集約効果が悪くなり、メタデータ管理の負担が増加する可能性があります。tabletが大きすぎるとreplicaの移行と補完に不利となり、Schema Change操作の再試行コストが増加します。
-
量の原則: 拡張を考慮しない場合、テーブルのtablet数はクラスタ全体のディスク数よりもわずかに多くすることが推奨されます。
例えば、BEあたり1つのディスクを持つ10台のBEマシンがあると仮定すると、データのbucketingについて以下の推奨事項に従うことができます:
| Table Size | Recommended Number of Buckets |
|---|---|
| 500MB | 4-8 buckets |
| 5GB | 6-16 buckets |
| 50GB | 32 buckets |
| 500GB | Partition recommended, 50GB per partition, 16-32 buckets per partition |
| 5TB | Partition recommended, 50GB per partition, 16-32 buckets per partition |
テーブルのデータ量はSHOW DATAコマンドを使用して確認できます。結果はreplica数とテーブルのデータ量で除算する必要があります。
自動Bucket数設定
自動bucket数計算機能は、一定期間のpartitionサイズに基づいて将来のpartitionサイズを自動的に予測し、それに応じてbucket数を決定します。
-- Set hash bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
-- Set random bucket auto
DISTRIBUTED BY RANDOM BUCKETS AUTO
properties("estimate_partition_size" = "20G")
バケット作成時には、estimate_partition_size属性を通じて推定パーティションサイズを調整できます。このパラメータはオプションであり、提供されない場合、Dorisはデフォルトで10GBに設定されます。このパラメータは、過去のパーティションデータに基づいてシステムが計算する将来のパーティションサイズとは関係がないことに注意してください。
データバケットの維持
現在、Dorisは新しく追加されたパーティションのバケット数の変更のみをサポートしており、以下の操作はサポートしていません:
- バケットタイプの変更
- バケットキーの変更
- 既存のバケットのバケット数の変更
テーブル作成時、各パーティションのバケット数はDISTRIBUTED文を通じて統一的に指定されます。データの増減に対応するため、パーティションを動的に追加する際に新しいパーティションのバケット数を指定できます。以下の例では、ALTER TABLEコマンドを使用して新しく追加されたパーティションのバケット数を変更する方法を示します:
-- Modify hash bucket table
ALTER TABLE demo.hash_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY HASH(region) BUCKETS 16;
-- Modify random bucket table
ALTER TABLE demo.random_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY RANDOM BUCKETS 16;
-- Modify dynamic partition table
ALTER TABLE demo.dynamic_partition_tbl
SET ("dynamic_partition.buckets"="16");
バケット数を変更した後、SHOW PARTITIONコマンドを使用して、更新されたバケット数を確認できます。