
圧縮の原理
1. Compactionの役割
Apache DorisはLSM-Treeベースのストレージエンジンを使用しており、書き込み時には既存のファイルを直接更新するのではなく、データが新しいデータファイルに順次追記されます。 この設計により高い書き込みパフォーマンスが確保されますが、時間の経過とともに異なるバージョンとサイズのデータファイルが蓄積され、以下の問題が発生します:
- クエリパフォーマンスの低下:クエリでは複数のファイルにわたるマルチウェイマージソートが必要
- ストレージ領域の無駄:削除マークされたデータや重複データが含まれる
Compaction(データ圧縮・整理)は、これらの問題を解決する重要なメカニズムです。バックグラウンドで自動的にデータファイルをマージ・書き直しを行い、同じプライマリキーまたは隣接する範囲のデータをより少ない、より整理されたファイルに集約し、削除済みまたは期限切れのデータをクリーンアップします。 これにより、高いクエリパフォーマンスを維持しながら、ストレージ領域の利用効率を最適化します。
DorisにおいてCompactionは継続的で自動的なプロセスであり、手動トリガーは不要です。ただし、その原理と動作状況を理解することで、高同時実行性とビッグデータシナリオでのパフォーマンスチューニングに役立ちます。
1.1 クエリパフォーマンスの向上
Dorisのデータインポートメカニズム:各インポートは、ターゲットパーティション内の各tabletに対してrowsetを生成します。
- 各rowsetは0からn個のsegmentを含む
- 各segmentはディスク上の順序付けられたファイルに対応
クエリ実行時、ストレージ層は集約または重複排除された結果を返す必要があるため、複数のrowset/segmentからのデータに対してマルチウェイマージソートを実行します。 rowsetの数が増加すると、マージパスの数も増加し、クエリ効率の低下につながります。
Compactionの役割:
- BEノードがバックグラウンドでこれらのrowsetを継続的にマージし、マージパスの数を削減することで、クエリ効率を向上
- Compactionはtablet単位で実行される
1.2 データクリーニング
パフォーマンス向上に加えて、Compactionはデータクリーニングの責任も担います:
- 削除マーク付きデータのクリーニング
- DorisのDELETE操作はデータを即座に削除せず、代わりにdelete rowset(削除述語のみを含み、実際のデータは含まない)を生成します。Compaction中に、これらの述語にマッチするデータがフィルタリングされ、実際に削除されます
- Merge-on-Writeタイプのテーブルでは、削除サインでマークされたデータもCompactionフェーズでクリーンアップされます
- 重複データの削除
- Aggregateモデル:同じキーを持つ行を集約
- Uniqueモデル:同じキーに対して最新のデータのみを保持
これにより、データの正確性と ストレージ領域使用量の削減の両方が確保されます。
2. 重要な概念
2.1 Compaction Score
Compaction Scoreは、tablet内のデータの無秩序度を測定する指標であり、Compactionの優先度を決定する基準でもあります。 これは、クエリ実行時にそのtabletが参加する必要があるマージパスの数に相当します。
- より高いScoreは、より高いクエリオーバーヘッドを意味する
- したがって、CompactionはScoreがより高いtabletを優先する
例:
"rowsets": [
"[0-100] 3 DATA NONOVERLAPPING 0200000000001c30804822f519cf378fbe6f162b7de393a6 500.32 MB",
"[101-101] 2 DATA OVERLAPPING 02000000000021d0804822f519cf378fbe6f162b7de393a6 180.46 MB",
"[102-102] 1 DATA NONOVERLAPPING 0200000000002211804822f519cf378fbe6f162b7de393a6 50.59 MB"
]
- [0-100] rowsetは3つのセグメントを持ちますが重複がない → 1つのパスを占有
- [101-101] rowsetは重複のある2つのセグメントを持つ → 2つのパスを占有
- [102-102] rowsetは1つのパスを占有 したがって、このタブレットのCompaction Score = 4です。
2.2 Compactionタイプ
- Cumulative Compaction: 小さな増分rowsetをマージして、マージ効率を向上させる
- Base Compaction: 特定のrowsetより前のすべてのrowsetを新しいrowsetにマージする
- Full Compaction: すべてのrowsetをマージする
- Cumulative Point: BaseとCumulative Compactionを分割する境界点
理想的な戦略は以下の通りです: まずCumulative Compactionで小さなrowsetをマージし、一定の規模まで蓄積した後、Base Compactionを実行する。
3. Compaction戦略
3.1 タブレット選択戦略
Compactionの目標はクエリ性能を向上させることなので、最も高いCompaction Scoreを持つタブレットを優先します。
3.2 Rowset選択戦略
対象タブレットを特定した後、Compactionに適切なrowsetを選択する必要があります。原則は以下の通りです:
- 計算負荷を最小化しながら、可能な限りCompaction Scoreを削減する
- 書き込み増幅率を制御する
- 過度なシステムリソースの占有を避ける
主要な考慮事項:
- コスト効率
- Cumulative Compaction: マージに参加するrowsetのサイズがあまり異ならないこと; 最大rowsetサイズ ≤ 全体の半分
- Base Compaction: Base rowsetと他の候補rowsetの比率が ≥ 0.3の場合のみトリガー
- 書き込み増幅制御
- Cumulative Compaction:
- 候補rowset Score > 5の場合のみトリガー
- データ量がプロモーションサイズを超える場合のみトリガー
- Base Compaction: 候補rowset Score > 5の場合のみトリガー
- Cumulative Compaction:
- システムリソース制御
- 単一のCumulative Compactionでのrowset数 ≤ 1000
- 単一のBase Compactionでのrowset数 ≤ 20
4. Compactionプロセス
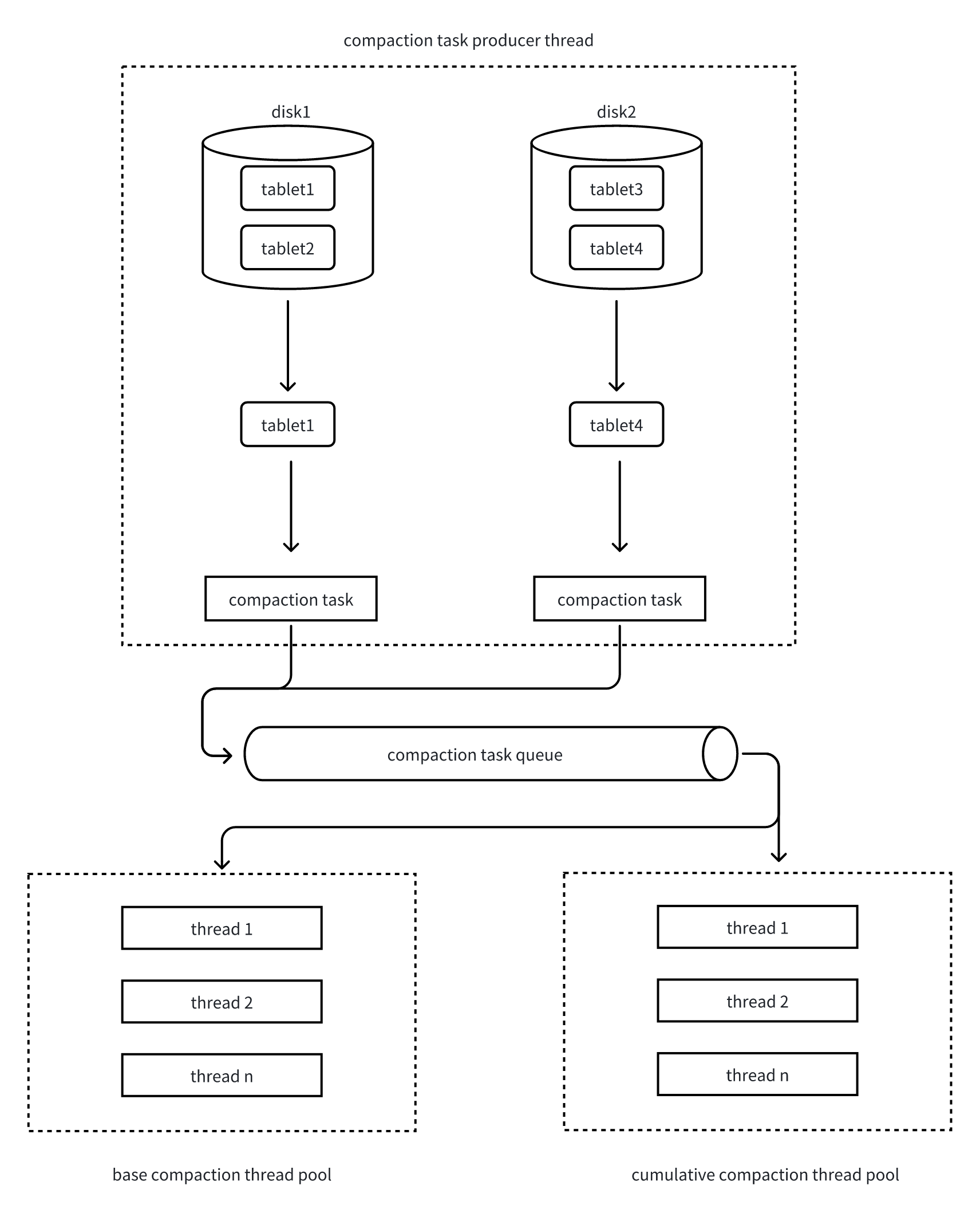
Compaction実行はプロデューサー・コンシューマーモデルに従います:
- タブレットスキャンとタスク生成
- Compactionタスクプロデューサースレッドが定期的にすべてのタブレットをスキャンし、Compaction Scoreを計算
- 各ラウンドで各ディスクから最も高いScoreのタブレットを選択
- Base Compactionは10ラウンドごとに選択され、他の9ラウンドはCumulative Compaction
- 並行制御
- 現在のディスクのCompactionタスク数が設定制限を超えているかチェック
- 超えていない場合、タブレットがCompactionに入ることを許可
- Rowset選択
- 類似したサイズの連続rowsetを入力として選択
- データ量の大きな格差による非効率的なマルチウェイマージを回避
- タスク送信
- タブレットと候補rowsetをCompaction Taskにパッケージ
- タスクタイプ(Base/Cumulative)に基づいて対応するスレッドプールキューに送信
- タスク実行
- Compactionスレッドプールがキューからタスクを取得
- マルチウェイマージソートを実行し、複数のrowsetを新しいrowsetにマージ
5. 一般的なCompactionパラメータ
| パラメータ名 | 意味 | デフォルト値 |
|---|---|---|
| tive_compaction_rounds_for_each_base_compaction_round | 1つのbase compactionタスクが生成される前に、何ラウンドのcumulative compactionタスクが生成されるか。このパラメータを調整することで、cumulativeとbase compactionタスクの比率を制御できます | 9 |
| compaction_task_num_per_fast_disk | SSDディスクあたりの最大同時compactionタスク数 | 8 |
| compaction_task_num_per_disk | HDDディスクあたりの最大同時compactionタスク数 | 4 |
| max_base_compaction_threads | Base compactionスレッドプール内のワーカースレッド数 | 4 |
| max_cumu_compaction_threads | Cumulative compactionスレッドプール内のワーカースレッド数。-1はスレッドプールサイズがディスク数によって決定され、ディスクあたり1つのスレッドを意味します | -1 |
| base_compaction_min_rowset_num | base compactionをトリガーする条件。rowset数によってトリガーされる場合、これはbase compactionに必要な最小rowset数です | 5 |
| base_compaction_max_compaction_score | base compactionに参加するrowsetの最大compaction score | 20 |
| cumulative_compaction_min_deltas | cumulative compactionに参加するrowsetの最小compaction score | 5 |
| cumulative_compaction_max_deltas | cumulative compactionに参加するrowsetの最大compaction score | 1000 |