
ルーチンロード
Dorisは、Routine Loadを使用してKafka Topicからデータを継続的に消費することができます。Routine Loadジョブを送信すると、Dorisはインポートジョブを実行し続け、Kafkaクラスタ内の指定されたTopicからメッセージを消費するインポートタスクを継続的に生成します。
Routine Loadは、Exactly-Onceセマンティクスをサポートするストリーミングインポートジョブで、データの損失や重複を防ぎます。
使用例
サポートされるデータソース
Routine LoadはKafkaクラスタからのデータ消費をサポートします。
サポートされるデータファイル形式
Routine LoadはCSVおよびJSON形式のデータをサポートします。
CSV形式をインポートする場合、null値と空文字列を明確に区別する必要があります:
-
Null値は
\nで表現する必要があります。データa,\n,bは、中央の列がnull値であることを示します。 -
空文字列('')は直接空のままにします。データ
a,,bは、中央の列が空文字列であることを示します。
使用上の制限
Routine Loadを使用してKafkaからデータを消費する場合、以下の制限があります:
-
サポートされるメッセージ形式は、CSVおよびJSONテキスト形式です。各CSVメッセージは1行で、その行は末尾に改行を含みません。
-
デフォルトでは、Kafkaバージョン0.10.0.0(含む)以降がサポートされています。Kafka 0.10.0.0未満のバージョン(0.9.0、0.8.2、0.8.1、0.8.0)を使用するには、
kafka_broker_version_fallbackの値を互換性のある古いバージョンに設定してBE設定を変更するか、Routine Load作成時にproperty.broker.version.fallbackの値を直接互換性のある古いバージョンに設定する必要があります。古いバージョンを使用するコストは、時間に基づくKafkaパーティションオフセットの設定など、Routine Loadの一部の新機能が利用できない可能性があることです。
基本原理
Routine LoadはKafka Topicからデータを継続的に消費し、Dorisに書き込みます。
Dorisでは、Routine Loadジョブを作成すると、いくつかのインポートタスクを含む永続的なインポートジョブが生成されます:
-
Import Job(Load Job):Routine Load Jobは、データソースからデータを継続的に消費する永続的なインポートジョブです。
-
Import Task(Load Task):インポートジョブは、実際の消費のためにいくつかのインポートタスクに分割されます。各タスクは独立したトランザクションです。
Routine Loadインポートの具体的なプロセスを以下の図に示します:
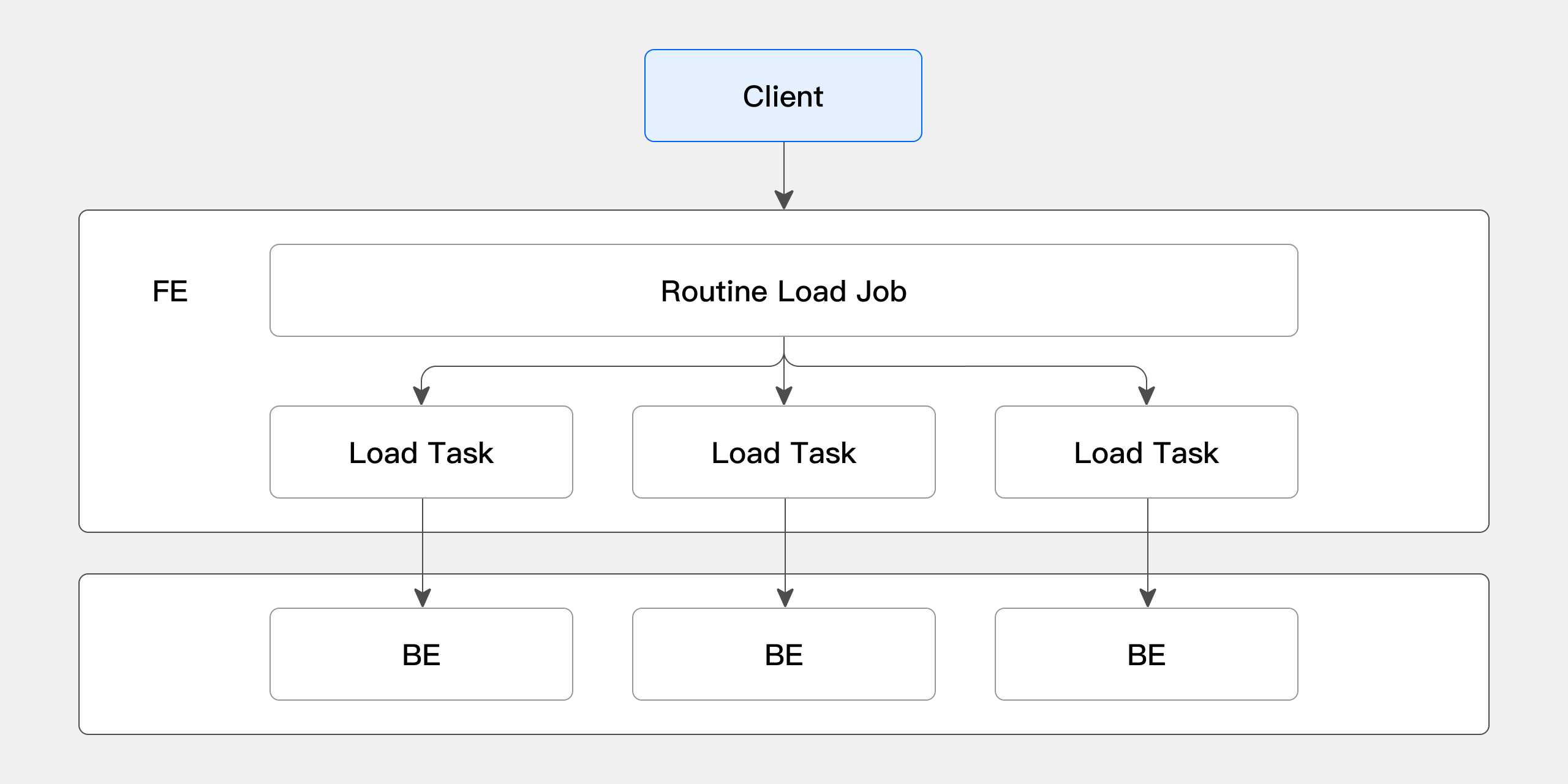
-
クライアントがFEにRoutine Loadジョブを作成するリクエストを送信します。FEはRoutine Load Managerを通じて永続的なインポートジョブ(Routine Load Job)を生成します。
-
FEはJob Schedulerを通じてRoutine Load JobをいくつかのRoutine Load Taskに分割し、Task Schedulerによってスケジュールされ、BEノードにディスパッチされます。
-
BEでは、Routine Load Taskがインポートを完了すると、トランザクションをFEに送信し、Jobメタデータを更新します。
-
Routine Load Taskが送信された後、新しいTaskが生成されるか、タイムアウトしたTaskが再試行されます。
-
新しく生成されたRoutine Load TaskはTask Schedulerによって継続的なサイクルで引き続きスケジュールされます。
自動復旧
ジョブの高可用性を確保するため、自動復旧メカニズムが導入されています。予期しない一時停止の場合、Routine Load Schedulerスレッドがジョブの自動復旧を試行します。予期しないKafka障害やその他の非動作状況の場合、自動復旧メカニズムにより、Kafka復旧後にインポートジョブが手動介入なしに正常に実行を継続できることが保証されます。
自動復旧しないケース:
-
ユーザが手動で
PAUSE ROUTINE LOADコマンドを実行した場合。 -
データ品質の問題が存在する場合。
-
データベーステーブルが削除されるなど、自動復旧できないケース。
上記3つのケースを除き、その他の一時停止したジョブは自動復旧を試行します。
クイックスタート
インポートジョブの作成
Dorisでは、CREATE ROUTINE LOADコマンドを使用して永続的なRoutine Loadインポートタスクを作成できます。詳細な構文については、CREATE ROUTINE LOADを参照してください。Routine LoadはCSVおよびJSONデータを消費できます。
CSVデータのインポート
- サンプルインポートデータ
Kafkaには以下のサンプルデータがあります:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-csv --from-beginning
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
- インポートするテーブルを作成する
Dorisで、以下の構文を使用してインポートするテーブルを作成します:
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
- Routine Load インポートジョブの作成
Doris では、CREATE ROUTINE LOAD コマンドを使用してインポートジョブを作成します:
CREATE ROUTINE LOAD testdb.example_routine_load_csv ON test_routineload_tbl
COLUMNS TERMINATED BY ",",
COLUMNS(user_id, name, age)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092",
"kafka_topic" = "test-routine-load-csv",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
JSONデータのインポート
- サンプルインポートデータ
Kafkaには、以下のサンプルデータがあります:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-json --from-beginning
{"user_id":1,"name":"Emily","age":25}
{"user_id":2,"name":"Benjamin","age":35}
{"user_id":3,"name":"Olivia","age":28}
{"user_id":4,"name":"Alexander","age":60}
{"user_id":5,"name":"Ava","age":17}
{"user_id":6,"name":"William","age":69}
{"user_id":7,"name":"Sophia","age":32}
{"user_id":8,"name":"James","age":64}
{"user_id":9,"name":"Emma","age":37}
{"user_id":10,"name":"Liam","age":64}
- インポートするテーブルを作成する
Dorisで、以下の構文を使用してインポートするテーブルを作成します:
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
- Routine Loadインポートジョブの作成
Dorisでは、CREATE ROUTINE LOADコマンドを使用してインポートジョブを作成します:
CREATE ROUTINE LOAD testdb.example_routine_load_json ON test_routineload_tbl
COLUMNS(user_id,name,age)
PROPERTIES(
"format"="json",
"jsonpaths"="[\"$.user_id\",\"$.name\",\"$.age\"]"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092",
"kafka_topic" = "test-routine-load-json",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
JSON ファイルのルートノードから JSON オブジェクトをインポートする必要がある場合、jsonpaths を $. として指定する必要があります。例: PROPERTIES("jsonpaths"="$.")。
インポートステータスの確認
Doris では、Routine Load のインポートジョブステータスとインポートタスクステータス:
-
Import Job: 主にインポートタスクの対象テーブル、サブタスク数、インポート遅延ステータス、インポート設定、およびインポート結果を確認するために使用されます。
-
Import Task: 主にインポートサブタスクのステータス、消費進行状況、および割り当てられた BE ノードを確認するために使用されます。
01 実行中のインポートジョブの確認
SHOW ROUTINE LOAD コマンドを使用してインポートジョブステータスを確認できます。SHOW ROUTINE LOAD は、インポート対象テーブル、インポート遅延ステータス、インポート設定情報、インポートエラー情報など、現在のジョブの基本ステータスを表示します。
例えば、次のコマンドで testdb.example_routine_load_csv のジョブステータスを確認できます:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
02 実行中のインポートタスクの確認
SHOW ROUTINE LOAD TASKコマンドを使用してインポートサブタスクのステータスを確認できます。SHOW ROUTINE LOAD TASKは、サブタスクのステータスや割り当てられたBE IDなど、現在のジョブ下のサブタスク情報を表示します。
例えば、以下のコマンドでtestdb.example_routine_load_csvのタスクステータスを確認できます:
mysql> SHOW ROUTINE LOAD TASK WHERE jobname = 'example_routine_load_csv';
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| TaskId | TxnId | TxnStatus | JobId | CreateTime | ExecuteStartTime | Timeout | BeId | DataSourceProperties |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| 8cf47e6a68ed4da3-8f45b431db50e466 | 195 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 10429 | {"4":1231,"9":2603} |
| f2d4525c54074aa2-b6478cf8daaeb393 | 196 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 12109 | {"1":1225,"6":1216} |
| cb870f1553864250-975279875a25fab6 | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"2":7234,"7":4865} |
| 68771fd8a1824637-90a9dac2a7a0075e | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"3":1769,"8":2982} |
| 77112dfea5e54b0a-a10eab3d5b19e565 | 197 | PREPARE | 12177 | 2024-01-15 12:21:02 | 2024-01-15 12:21:02 | 20 | 12098 | {"0":3000,"5":2622} |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
Import Jobの一時停止
PAUSE ROUTINE LOADコマンドを使用してimport jobを一時停止できます。import jobを一時停止すると、PAUSED状態になりますが、import jobは終了せず、RESUME ROUTINE LOADコマンドを使用して再開できます。
例えば、以下のコマンドでtestdb.example_routine_load_csvのimport jobを一時停止できます:
PAUSE ROUTINE LOAD FOR testdb.example_routine_load_csv;
インポートジョブの再開
RESUME ROUTINE LOADコマンドを使用してインポートジョブを再開できます。
例えば、以下のコマンドでtestdb.example_routine_load_csvインポートジョブを再開できます:
RESUME ROUTINE LOAD FOR testdb.example_routine_load_csv;
インポートジョブの変更
ALTER ROUTINE LOADコマンドを使用して、作成済みのインポートジョブを変更できます。インポートジョブを変更する前に、PAUSE ROUTINE LOADを使用してジョブを一時停止し、変更後にRESUME ROUTINE LOADを使用して再開する必要があります。
例えば、以下のコマンドで目的のインポートタスク並行パラメータdesired_concurrent_numberを変更し、Kafka Topic情報を変更できます:
ALTER ROUTINE LOAD FOR testdb.example_routine_load_csv
PROPERTIES(
"desired_concurrent_number" = "3"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.60:9092",
"kafka_topic" = "test-topic"
);
インポートジョブのキャンセル
STOP ROUTINE LOADコマンドを使用して、Routine Loadインポートジョブを停止および削除できます。削除されたインポートジョブは復旧できず、SHOW ROUTINE LOADコマンドで表示することもできません。
以下のコマンドで、インポートジョブtestdb.example_routine_load_csvを停止および削除できます:
STOP ROUTINE LOAD FOR testdb.example_routine_load_csv;
Compute Groupのバインド
ストレージとコンピューティング分離モードでは、Routine LoadのCompute Group選択ロジックは以下の優先順位に従います:
use db@cluster文で指定されたCompute Groupを選択する。- ユーザー属性
default_compute_groupで指定されたCompute Groupを選択する。 - 現在のユーザーがアクセス権限を持つCompute Groupから1つ選択する。
ストレージとコンピューティング統合モードでは、ユーザー属性resource_tags.locationで指定されたCompute Groupを選択します。ユーザー属性で指定されていない場合は、defaultという名前のCompute Groupを使用します。
Routine LoadジョブのCompute Groupは作成時にのみ指定できることに注意してください。Routine Loadジョブが作成されると、バインドされたCompute Groupは変更できません。
リファレンスマニュアル
インポートコマンド
Routine Load永続インポートジョブを作成する構文は以下の通りです:
CREATE ROUTINE LOAD [<db_name>.]<job_name> [ON <tbl_name>]
[merge_type]
[load_properties]
[job_properties]
FROM KAFKA [data_source_properties]
[COMMENT "<comment>"]
import ジョブ作成のためのモジュール説明:
| モジュール | 説明 |
|---|---|
| db_name | import タスクを作成するデータベースを指定します。 |
| job_name | 作成する import タスクの名前を指定します。同一データベース内で同じ名前のタスクは存在できません。 |
| tbl_name | import するテーブル名を指定します。これはオプションです。指定されない場合、動的テーブルモードが使用され、Kafka データにテーブル名情報が含まれている必要があります。 |
| merge_type | データマージタイプ。デフォルトは APPEND です。 merge_type には3つのオプションがあります: - APPEND: 追記 import モード - MERGE: マージ import モード - DELETE: import されたすべてのデータが削除されます。 |
| load_properties | import 説明モジュール。以下のコンポーネントを含みます: - column_separator 句 - columns_mapping 句 - preceding_filter 句 - where_predicates 句 - partitions 句 - delete_on 句 - order_by 句 |
| job_properties | Routine Load の一般的な import パラメータを指定するために使用されます。 |
| data_source_properties | Kafka データソースプロパティを記述するために使用されます。 |
| comment | import ジョブの備考を記述するために使用されます。 |
Import パラメータ説明
01 FE 設定パラメータ
| パラメータ名 | デフォルト値 | 動的設定 | FE Master 専用設定 | パラメータ説明 |
|---|---|---|---|---|
| max_routine_load_task_concurrent_num | 256 | Yes | Yes | 並行 Routine Load import ジョブサブタスクの最大数を制限します。デフォルト値を維持することを推奨します。大きすぎる値に設定すると、並行タスクが多すぎてクラスターリソースを占有する可能性があります。 |
| max_routine_load_task_num_per_be | 1024 | Yes | Yes | BE ごとに制限される並行 Routine Load タスクの最大数。max_routine_load_task_num_per_be は routine_load_thread_pool_size より小さくする必要があります。 |
| max_routine_load_job_num | 100 | Yes | Yes | NEED_SCHEDULED、RUNNING、PAUSE を含む Routine Load ジョブの最大数を制限します。 |
| max_tolerable_backend_down_num | 0 | Yes | Yes | BE が1つでもダウンしている限り、Routine Load は自動復旧できません。特定の条件下で、Doris は PAUSED タスクを RUNNING 状態に再スケジュールできます。このパラメータが0の場合、すべての BE ノードが稼働している時のみ再スケジューリングが許可されることを意味します。 |
| period_of_auto_resume_min | 5 (分) | Yes | Yes | Routine Load の自動復旧期間。 |
02 BE 設定パラメータ
| パラメータ名 | デフォルト値 | 動的設定 | 説明 |
|---|---|---|---|
| max_consumer_num_per_group | 3 | Yes | サブタスクが消費のために生成できるコンシューマーの最大数。 |
03 Import 設定パラメータ
Routine Load ジョブを作成する際、CREATE ROUTINE LOAD コマンドを通じて異なるモジュールに対して異なる import 設定パラメータを指定できます。
tbl_name 句
import するテーブルの名前を指定します。これはオプションです。
指定されない場合、動的テーブルモードが使用され、Kafka データにテーブル名情報が含まれている必要があります。現在、動的テーブル名は Kafka の Value からのみ取得でき、この形式に準拠する必要があります: JSON 形式: table_name|{"col1": "val1", "col2": "val2"}、ここで tbl_name はテーブル名で、| がテーブル名とテーブルデータの間の区切り文字です。CSV 形式データも同様です。例: table_name|val1,val2,val3。ここでの table_name は Doris のテーブル名と一致する必要があり、そうでなければ import は失敗します。動的テーブルは後述の column_mapping 設定をサポートしないことに注意してください。
merge_type 句
merge_type モジュールを通じてデータマージタイプを指定できます。merge_type には3つのオプションがあります:
-
APPEND: 追記 import モード
-
MERGE: マージ import モード。Unique Key モデルにのみ適用されます。Delete Flag 列をマークするために [DELETE ON] モジュールと組み合わせて使用する必要があります
-
DELETE: import されたすべてのデータが削除されます
load_properties 句
load_properties モジュールを通じて import データプロパティを記述できます。具体的な構文は以下の通りです:
[COLUMNS TERMINATED BY <column_separator>,]
[COLUMNS (<column1_name>[, <column2_name>, <column_mapping>, ...]),]
[WHERE <where_expr>,]
[PARTITION(<partition1_name>, [<partition2_name>, <partition3_name>, ...]),]
[DELETE ON <delete_expr>,]
[ORDER BY <order_by_column1>[, <order_by_column2>, <order_by_column3>, ...]]
特定モジュールの対応するパラメータは以下の通りです:
| サブモジュール | パラメータ | 説明 |
|---|---|---|
| COLUMNS TERMINATED BY | <column_separator> | カラム区切り文字を指定するために使用します。デフォルトは \t です。例えば、区切り文字としてカンマを指定する場合は、次のコマンドを使用します:COLUMN TERMINATED BY ","null値の処理については、以下に注意してください: - null値は - 空文字列('')は直接空のままにしておきます。データ |
| COLUMNS | <column_name> | 対応するカラム名を指定するために使用します。例えば、インポートカラム (k1, k2, k3) を指定する場合は、次のコマンドを使用します:COLUMNS(k1, k2, k3)COLUMNS句は以下の場合に省略できます: - CSVのカラムがテーブルのカラムと一対一で対応している場合 - JSONのキーカラムがテーブルのカラムと同じ名前の場合 |
| <column_mapping> | インポート時に、カラムフィルタリングと変換にカラムマッピングを使用できます。例えば、インポート時にターゲットカラムがデータソースの特定のカラムから導出される必要があり、ターゲットカラムk4がカラムk3から式k3+1を使用して計算される場合は、次のコマンドを使用します:COLUMNS(k1, k2, k3, k4 = k3 + 1)詳細については、Data Transformationを参照してください | |
| WHERE | <where_expr> | where_exprを指定すると、条件に基づいてインポートされるデータソースをフィルタリングできます。例えば、age > 30のデータのみをインポートする場合は、次のコマンドを使用します:WHERE age > 30 |
| PARTITION | <partition_name> | ターゲットテーブルのどのパーティションにインポートするかを指定します。指定しない場合は、対応するパーティションに自動的にインポートされます。例えば、ターゲットテーブルのパーティションp1とp2にインポートする場合は、次のコマンドを使用します:PARTITION(p1, p2) |
| DELETE ON | <delete_expr> | MERGEインポートモードでは、delete_exprを使用して削除が必要なカラムをマークします。例えば、MERGE中にage > 30のカラムを削除する場合は、次のコマンドを使用します:DELETE ON age > 30 |
| ORDER BY | <order_by_column> | Unique Keyモデルでのみ有効です。インポートされるデータのSequence Columnを指定してデータの順序を保証するために使用します。例えば、Unique Keyテーブルをインポートする際に、Sequence Columnとしてcreate_timeを指定する場合は、次のコマンドを使用します:ORDER BY create_timeUnique KeyモデルのSequence Columnの説明については、ドキュメントData Update/Sequence Columnを参照してください |
job_properties句
Routine Loadインポートジョブを作成する際に、job_properties句を指定してインポートジョブのプロパティを指定できます。構文は以下の通りです:
PROPERTIES ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
job_properties句の具体的なパラメータオプションは以下の通りです:
| パラメータ | 説明 |
|---|---|
| desired_concurrent_number | デフォルト値:256 パラメータ説明:単一インポートサブタスク(loadタスク)の希望並行数で、Routine Loadインポートジョブが分割される希望インポートサブタスクの数を変更します。インポート時、希望サブタスク並行数は実際の並行数と等しくない場合があります。実際の並行数は、クラスターノード数、負荷、データソース条件を総合的に考慮し、以下の式を使用して実際のインポートサブタスク数を計算します:
- topic_partition_numはKafka Topicのパーティション数を表します - desired_concurrent_numberは設定されたパラメータサイズを表します - max_routine_load_task_concurrent_numはRoutine Loadの最大タスク並行数を設定するFEのパラメータです |
| max_batch_interval | 各サブタスクの最大実行時間(秒単位)。0より大きい値である必要があり、デフォルトは60(s)です。max_batch_interval/max_batch_rows/max_batch_sizeは、サブタスク実行しきい値を構成します。いずれかのパラメータがしきい値に達すると、インポートサブタスクが終了し、新しいインポートサブタスクが生成されます。 |
| max_batch_rows | 各サブタスクが読み取る最大行数。200000以上である必要があります。デフォルトは20000000です。max_batch_interval/max_batch_rows/max_batch_sizeは、サブタスク実行しきい値を構成します。いずれかのパラメータがしきい値に達すると、インポートサブタスクが終了し、新しいインポートサブタスクが生成されます。 |
| max_batch_size | 各サブタスクが読み取る最大バイト数。単位はbytesで、範囲は100MBから1GBです。デフォルトは1Gです。max_batch_interval/max_batch_rows/max_batch_sizeは、サブタスク実行しきい値を構成します。いずれかのパラメータがしきい値に達すると、インポートサブタスクが終了し、新しいインポートサブタスクが生成されます。 |
| max_error_number | サンプリングウィンドウ内で許可される最大エラー行数。0以上である必要があります。デフォルトは0で、エラー行が許可されないことを意味します。サンプリングウィンドウはmax_batch_rows * 10です。サンプリングウィンドウ内のエラー行数がmax_error_numberより大きい場合、routineジョブが一時停止され、SHOW ROUTINE LOADコマンドのErrorLogUrlsでデータ品質問題を確認するための手動介入が必要になります。where条件でフィルタリングされた行はエラー行としてカウントされません。 |
| strict_mode | strict modeを有効にするかどうか。デフォルトはoffです。Strict modeは、インポート過程で列タイプ変換の厳格なフィルタリングを意味します。有効にすると、列タイプ変換結果がNULLになる非null生データがフィルタリングされます。 Strict modeフィルタリング戦略: - 派生列(関数変換によって生成された列)に対して、Strict Modeは効果がありません - 列タイプの変換が必要な場合、型が正しくないデータはフィルタリングされ、SHOW ROUTINE LOADの - 範囲制限を含むインポート列に対して、生データが型変換を正常に通過できても範囲制限を通過できない場合、strict modeはそれに対して効果がありません。例:型がdecimal(1,0)で、生データが10の場合、型変換は通過できますが、宣言された範囲内にありません。このデータはstrict modeの影響を受けません。詳細については、Strict Modeを参照してください。 |
| timezone | インポートジョブで使用するタイムゾーンを指定します。デフォルトはSessionのtimezoneパラメータを使用します。このパラメータは、インポートに関わるすべてのタイムゾーン関連関数結果に影響します。 |
| format | インポートデータ形式を指定します。デフォルトはCSVで、JSON形式をサポートします。 |
| jsonpaths | インポートデータ形式がJSONの場合、jsonpathsでJSONデータから抽出するフィールドを指定できます。例えば、以下のコマンドでインポート用のjsonpathsを指定します:"jsonpaths" = "[\"$.userid\",\"$.username\",\"$.age\",\"$.city\"]" |
| json_root | インポートデータ形式がJSONの場合、json_rootでJSONデータのルートノードを指定できます。Dorisはルートノードから要素を抽出して解析します。デフォルトは空です。例えば、以下のコマンドでインポート用のJSONルートノードを指定します:"json_root" = "$.RECORDS" |
| strip_outer_array | インポートデータ形式がjsonの場合、strip_outer_arrayがtrueの場合、JSONデータが配列として提示され、データ内の各要素が1行として扱われることを意味します。デフォルト値はfalseです。通常、KafkaのJSONデータは配列形式、つまり外側の角括弧[]を含む場合があります。この場合、"strip_outer_array" = "true"を指定して、配列モードでTopic内のデータを消費できます。例えば、以下のデータは2行に解析されます:[{"user_id":1,"name":"Emily","age":25},{"user_id":2,"name":"Benjamin","age":35}] |
| send_batch_parallelism | バッチデータ送信の並列度を設定するために使用します。並列度の値がBE設定のmax_send_batch_parallelism_per_jobを超える場合、coordinatorとして機能するBEはmax_send_batch_parallelism_per_jobの値を使用します。 |
| load_to_single_tablet | タスクごとに対応するパーティションの1つのtabletのみにデータをインポートすることをサポートします。デフォルト値はfalseです。このパラメータは、random bucketingを使用するolapテーブルにデータをインポートする場合のみ許可されます。 |
| partial_columns | 部分列更新を有効にするかどうかを指定します。デフォルト値はfalseです。このパラメータは、テーブルモデルがUniqueで、Merge on Writeを使用している場合のみ許可されます。マルチテーブルストリーミングではこのパラメータはサポートされません。詳細については、Partial Column Updateを参照してください |
| unique_key_update_mode | Unique Keyテーブルの更新モードを指定します。選択可能な値:
|
| partial_update_new_key_behavior | Unique Merge on Writeテーブルで部分列更新を実行する際の新規挿入行の処理方法。2つのタイプ:APPEND、ERROR。- APPEND:新規行データの挿入を許可- ERROR:新規行を挿入する際にインポートが失敗し、エラーを報告 |
| max_filter_ratio | サンプリングウィンドウ内で許可される最大フィルタリング率。0以上1以下である必要があります。デフォルト値は1.0で、任意のエラー行を許容できることを意味します。サンプリングウィンドウはmax_batch_rows * 10です。サンプリングウィンドウでエラー行数/総行数がmax_filter_ratioより大きい場合、routineジョブが一時停止され、データ品質問題を確認するための手動介入が必要になります。where条件でフィルタリングされた行はエラー行としてカウントされません。 |
| enclose | 囲み文字を指定します。CSVデータフィールドに行または列区切り文字が含まれる場合、保護のために単一バイト文字を囲み文字として指定できます。例えば、列区切り文字が","で、囲み文字が"'"の場合、データ"a,'b,c'"に対して、"b,c"が1つのフィールドとして解析されます。 |
| escape | エスケープ文字を指定します。フィールド内の囲み文字と同じ文字をエスケープするために使用します。例えば、データが"a,'b,'c'"で、囲み文字が"'"、"b,'cを1つのフィールドとして解析したい場合、""などの単一バイトエスケープ文字を指定し、データを"a,'b,'c'"に変更する必要があります。 |
04 data_source_properties句
Routine Loadインポートジョブを作成する際、data_source_properties句を指定してKafkaデータソースのプロパティを指定できます。構文は以下の通りです:
FROM KAFKA ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
data_source_properties句の具体的なパラメータオプションは以下の通りです:
| パラメータ | 説明 |
|---|---|
| kafka_broker_list | Kafkaブローカーの接続情報を指定します。形式は<kafka_broker_ip>:<kafka port>です。複数のブローカーはカンマで区切ります。例えば、Kafka Brokerではデフォルトのポート番号は9092です。Broker Listは以下のコマンドで指定できます:"kafka_broker_list" = "<broker1_ip>:9092,<broker2_ip>:9092" |
| kafka_topic | 購読するKafkaトピックを指定します。1つのインポートジョブは1つのKafka Topicのみを消費できます。 |
| kafka_partitions | 購読するKafka Partitionsを指定します。指定しない場合、デフォルトですべてのパーティションが消費されます。 |
| kafka_offsets | 消費対象のKafka Partitionでの消費開始点(offset)。時間が指定された場合、その時間以上の最も近いoffsetから消費が開始されます。Offsetは0以上の特定のoffsetを指定するか、以下の形式を使用できます: - OFFSET_BEGINNING:データが存在する位置から購読します。 - OFFSET_END:終端から購読します。 - 時間形式、例:"2021-05-22 11:00:00" 指定しない場合、デフォルトで 複数の消費開始点を指定でき、カンマで区切ります。例: 時間形式とOFFSET形式を混在させることはできないことに注意してください。 |
| property | カスタムkafkaパラメータを指定します。kafka shellの"--property"パラメータと機能的に同等です。パラメータValueがファイルの場合、Valueの前にキーワード"FILE:"を追加する必要があります。ファイルの作成については、CREATE FILEコマンドのドキュメントを参照してください。サポートされているその他のカスタムパラメータについては、librdkafkaの公式CONFIGURATIONドキュメントのクライアント設定項目を参照してください。例:"property.client.id" = "12345"、"property.group.id" = "group_id_0"、"property.ssl.ca.location" = "FILE:ca.pem"。 |
data_source_propertiesでkafka propertyパラメータを設定することで、セキュアアクセスオプションを設定できます。現在、Dorisは複数のKafkaセキュリティプロトコルをサポートしています。plaintext(デフォルト)、SSL、PLAIN、Kerberosなどです。
インポート状況
インポートジョブの状況は、SHOW ROUTINE LOADコマンドで確認できます。具体的な構文は以下の通りです:
SHOW [ALL] ROUTINE LOAD [FOR jobName];
例えば、SHOW ROUTINE LOADは以下の結果セットの例を返します:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
特定の表示結果の説明は以下の通りです:
| 結果列 | 列の説明 |
|---|---|
| Id | ジョブID。Dorisによって自動生成されます。 |
| Name | ジョブ名。 |
| CreateTime | ジョブ作成時刻。 |
| PauseTime | 最新のジョブ一時停止時刻。 |
| EndTime | ジョブ終了時刻。 |
| DbName | 対応するデータベース名 |
| TableName | 対応するテーブル名。マルチテーブルの場合、動的テーブルのため、具体的なテーブル名は表示されず、multi-tableと表示されます。 |
| IsMultiTbl | マルチテーブルかどうか。 |
| State | ジョブ実行状態。5つの状態があります: - NEED_SCHEDULE: ジョブがスケジュール待ち。CREATE ROUTINE LOADまたはRESUME ROUTINE LOADの後、ジョブは最初にNEED_SCHEDULE状態に入ります; - RUNNING: ジョブが実行中; - PAUSED: ジョブが一時停止中、RESUME ROUTINE LOADによって再開可能; - STOPPED: ジョブが終了し、再開不可; - CANCELLED: ジョブがキャンセルされました。 |
| DataSourceType | データソースタイプ: KAFKA。 |
| CurrentTaskNum | 現在のサブタスク数。 |
| JobProperties | ジョブ設定の詳細。 |
| DataSourceProperties | データソース設定の詳細。 |
| CustomProperties | カスタム設定。 |
| Statistic | ジョブ実行状態の統計。 |
| Progress | ジョブ実行進捗。Kafkaデータソースの場合、各パーティションで現在消費されているoffsetを表示します。例えば、{"0":"2"}はKafkaパーティション0の消費進捗が2であることを意味します。 |
| Lag | ジョブ遅延状態。Kafkaデータソースの場合、各パーティションの消費遅延を表示します。例えば、{"0":10}はKafkaパーティション0の消費遅延が10であることを意味します。 |
| ReasonOfStateChanged | ジョブステータス変更の理由 |
| ErrorLogUrls | フィルタされた低品質データの表示アドレス |
| OtherMsg | その他のエラーメッセージ |
インポート例
最大インポートエラー許容率の設定
-
サンプルインポートデータ
1,Benjamin,18
2,Emily,20
3,Alexander,dirty_data -
テーブル構造
CREATE TABLE demo.routine_test01 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job01 ON routine_test01
COLUMNS TERMINATED BY ","
PROPERTIES
(
"max_filter_ratio"="0.5",
"max_error_number" = "100",
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test01;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
+------+------------+------+
2 rows in set (0.01 sec)
指定された消費ポイントからのデータ消費
-
サンプルインポートデータ
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
テーブル構造
CREATE TABLE demo.routine_test02 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Import コマンド
CREATE ROUTINE LOAD demo.kafka_job02 ON routine_test02
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad02",
"kafka_partitions" = "0",
"kafka_offsets" = "3"
); -
インポート結果
mysql> select * from routine_test02;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
Consumer Groupのgroup.idとclient.idを指定する
-
サンプルインポートデータ
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
テーブル構造
CREATE TABLE demo.routine_test03 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job03 ON routine_test03
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.group.id" = "kafka_job03",
"property.client.id" = "kafka_client_03",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test03;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+------------+------+
3 rows in set (0.01 sec)
インポートフィルター条件の設定
-
サンプルインポートデータ
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
テーブル構造
CREATE TABLE demo.routine_test04 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
インポートコマンド
CREATE ROUTINE LOAD demo.kafka_job04 ON routine_test04
COLUMNS TERMINATED BY ",",
WHERE id >= 3
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad04",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test04;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
指定されたパーティションデータのインポート
-
サンプルインポートデータ
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
テーブル構造
CREATE TABLE demo.routine_test05 (
id INT NOT NULL COMMENT "ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age",
date DATETIME COMMENT "Date"
)
DUPLICATE KEY(`id`)
PARTITION BY RANGE(`id`)
(PARTITION partition_a VALUES [("0"), ("1")),
PARTITION partition_b VALUES [("1"), ("2")),
PARTITION partition_c VALUES [("2"), ("3")))
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job05 ON routine_test05
COLUMNS TERMINATED BY ",",
PARTITION(partition_b)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad05",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test05;
+------+----------+------+---------------------+
| id | name | age | date |
+------+----------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
+------+----------+------+---------------------+
1 rows in set (0.01 sec)
Import Timezone を設定する
-
サンプルインポートデータ
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
テーブル構造
CREATE TABLE demo.routine_test06 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
date DATETIME COMMENT "date"
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job06 ON routine_test06
COLUMNS TERMINATED BY ","
PROPERTIES
(
"timezone" = "Asia/Shanghai"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad06",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test06;
+------+-------------+------+---------------------+
| id | name | age | date |
+------+-------------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
| 2 | Emily | 20 | 2024-02-05 11:00:00 |
| 3 | Alexander | 22 | 2024-02-06 12:00:00 |
+------+-------------+------+---------------------+
3 rows in set (0.00 sec)
merge_typeの設定
削除操作のmerge_typeの指定
-
サンプルインポートデータ
3,Alexander,22
5,William,26
インポート前のテーブル内のデータ:
```sql
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
```
2. テーブル構造
```sql
CREATE TABLE demo.routine_test07 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
```
3. importコマンド
```sql
CREATE ROUTINE LOAD demo.kafka_job07 ON routine_test07
WITH DELETE
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad07",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. インポート結果
```sql
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 4 | Sophia | 24 |
| 6 | Charlotte | 28 |
+------+----------------+------+
```
Merge操作のmerge_typeを指定する
-
サンプルインポートデータ
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38
インポート前のテーブル内のデータ:
```sql
mysql> SELECT * FROM routine_test08;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec)
```
2. テーブル構造
```sql
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
```
3. Importコマンド
```sql
CREATE ROUTINE LOAD demo.kafka_job08 ON routine_test08
WITH MERGE
COLUMNS TERMINATED BY ",",
DELETE ON id = 2
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad08",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. インポート結果
```sql
mysql> SELECT * FROM routine_test08;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
```
インポート時のマージ用シーケンス列の指定
-
サンプルインポートデータ
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38
インポート前のテーブル内のデータ:
```sql
mysql> SELECT * FROM routine_test09;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec)
```
2. テーブル構造
```sql
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"function_column.sequence_col" = "age"
);
```
3. Importコマンド
```sql
CREATE ROUTINE LOAD demo.kafka_job09 ON routine_test09
WITH MERGE
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age),
DELETE ON id = 2,
ORDER BY age
PROPERTIES
(
"desired_concurrent_number"="1",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad09",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. インポート結果
```sql
mysql> SELECT * FROM routine_test09;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
```
インポート時の完全な列マッピングと派生列計算
-
サンプルインポートデータ
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
テーブル構造
CREATE TABLE demo.routine_test10 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
importコマンド
CREATE ROUTINE LOAD demo.kafka_job10 ON routine_test10
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age, num=age*10)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad10",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> SELECT * FROM routine_test10;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
囲み文字を使用したデータのインポート
-
サンプルインポートデータ
1,"Benjamin",18
2,"Emily",20
3,"Alexander",22 -
テーブル構造
CREATE TABLE demo.routine_test11 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job11 ON routine_test11
COLUMNS TERMINATED BY ","
PROPERTIES
(
"desired_concurrent_number"="1",
"enclose" = "\""
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> SELECT * FROM routine_test11;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.02 sec)
JSON形式インポート
シンプルモードでJSON形式データをインポート
-
サンプルインポートデータ
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
テーブル構造
CREATE TABLE demo.routine_test12 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Import コマンド
CREATE ROUTINE LOAD demo.kafka_job12 ON routine_test12
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test12;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.02 sec)
Matching Mode での複雑な JSON フォーマットデータのインポート
-
サンプルインポートデータ
{ "name" : "Benjamin", "id" : 1, "num":180 , "age":18 }
{ "name" : "Emily", "id" : 2, "num":200 , "age":20 }
{ "name" : "Alexander", "id" : 3, "num":220 , "age":22 } -
テーブル構造
CREATE TABLE demo.routine_test13 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
importコマンド
CREATE ROUTINE LOAD demo.kafka_job13 ON routine_test13
COLUMNS(name, id, num, age)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.name\",\"$.id\",\"$.num\",\"$.age\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad13",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test13;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
データをインポートするためのJSONルートノードを指定する
-
サンプルインポートデータ
{"id": 1231, "source" :{ "id" : 1, "name" : "Benjamin", "age":18 }}
{"id": 1232, "source" :{ "id" : 2, "name" : "Emily", "age":20 }}
{"id": 1233, "source" :{ "id" : 3, "name" : "Alexander", "age":22 }} -
テーブル構造
CREATE TABLE demo.routine_test14 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Import コマンド
CREATE ROUTINE LOAD demo.kafka_job14 ON routine_test14
PROPERTIES
(
"format" = "json",
"json_root" = "$.source"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad14",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test14;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.01 sec)
インポート時の完全な列マッピングと派生列計算
-
サンプルインポートデータ
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
テーブル構造
CREATE TABLE demo.routine_test15 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job15 ON routine_test15
COLUMNS(id, name, age, num=age*10)
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad15",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test15;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
柔軟な部分カラム更新
この例では、各行が異なるカラムを更新できる柔軟な部分カラム更新の使用方法を説明します。これは、変更レコードが異なるフィールドを含む可能性があるCDCシナリオで非常に有用です。
-
サンプルインポートデータ(各JSONレコードが異なるカラムを更新):
{"id": 1, "balance": 150.00, "last_active": "2024-01-15 10:30:00"}
{"id": 2, "city": "Shanghai", "age": 28}
{"id": 3, "name": "Alice", "balance": 500.00, "city": "Beijing"}
{"id": 1, "age": 30}
{"id": 4, "__DORIS_DELETE_SIGN__": 1} -
テーブルを作成する(Merge-on-Writeを有効にし、bitmapカラムをスキップする必要があります):
CREATE TABLE demo.routine_test_flexible (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) COMMENT "Name",
age INT COMMENT "Age",
city VARCHAR(50) COMMENT "City",
balance DECIMAL(10,2) COMMENT "Balance",
last_active DATETIME COMMENT "Last Active Time"
)
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"enable_unique_key_merge_on_write" = "true",
"enable_unique_key_skip_bitmap_column" = "true"
); -
初期データを挿入する:
INSERT INTO demo.routine_test_flexible VALUES
(1, 'John', 25, 'Shenzhen', 100.00, '2024-01-01 08:00:00'),
(2, 'Jane', 30, 'Guangzhou', 200.00, '2024-01-02 09:00:00'),
(3, 'Bob', 35, 'Hangzhou', 300.00, '2024-01-03 10:00:00'),
(4, 'Tom', 40, 'Nanjing', 400.00, '2024-01-04 11:00:00'); -
importコマンド:
CREATE ROUTINE LOAD demo.kafka_job_flexible ON routine_test_flexible
PROPERTIES
(
"format" = "json",
"unique_key_update_mode" = "UPDATE_FLEXIBLE_COLUMNS"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoadFlexible",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果:
mysql> SELECT * FROM demo.routine_test_flexible ORDER BY id;
+------+-------+------+-----------+---------+---------------------+
| id | name | age | city | balance | last_active |
+------+-------+------+-----------+---------+---------------------+
| 1 | John | 30 | Shenzhen | 150.00 | 2024-01-15 10:30:00 |
| 2 | Jane | 28 | Shanghai | 200.00 | 2024-01-02 09:00:00 |
| 3 | Alice | 35 | Beijing | 500.00 | 2024-01-03 10:00:00 |
+------+-------+------+-----------+---------+---------------------+
3 rows in set (0.01 sec)
注意:id=4の行は__DORIS_DELETE_SIGN__により削除され、各行はそれぞれ対応するJSONレコードに含まれる列のみが更新されました。
複合型のインポート
Array データ型のインポート
-
サンプルインポートデータ
{ "id" : 1, "name" : "Benjamin", "age":18, "array":[1,2,3,4,5]}
{ "id" : 2, "name" : "Emily", "age":20, "array":[6,7,8,9,10]}
{ "id" : 3, "name" : "Alexander", "age":22, "array":[11,12,13,14,15]} -
テーブル構造
CREATE TABLE demo.routine_test16
(
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
array ARRAY<int(11)> NULL COMMENT "test array column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job16 ON routine_test16
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad16",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test16;
+------+----------------+------+----------------------+
| id | name | age | array |
+------+----------------+------+----------------------+
| 1 | Benjamin | 18 | [1, 2, 3, 4, 5] |
| 2 | Emily | 20 | [6, 7, 8, 9, 10] |
| 3 | Alexander | 22 | [11, 12, 13, 14, 15] |
+------+----------------+------+----------------------+
3 rows in set (0.00 sec)
Import Map データ型
-
サンプルインポートデータ
{ "id" : 1, "name" : "Benjamin", "age":18, "map":{"a": 100, "b": 200}}
{ "id" : 2, "name" : "Emily", "age":20, "map":{"c": 300, "d": 400}}
{ "id" : 3, "name" : "Alexander", "age":22, "map":{"e": 500, "f": 600}} -
テーブル構造
CREATE TABLE demo.routine_test17 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
map Map<STRING, INT> NULL COMMENT "test column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
importコマンド
CREATE ROUTINE LOAD demo.kafka_job17 ON routine_test17
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad17",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test17;
+------+----------------+------+--------------------+
| id | name | age | map |
+------+----------------+------+--------------------+
| 1 | Benjamin | 18 | {"a":100, "b":200} |
| 2 | Emily | 20 | {"c":300, "d":400} |
| 3 | Alexander | 22 | {"e":500, "f":600} |
+------+----------------+------+--------------------+
3 rows in set (0.01 sec)
Bitmap Data Typeのインポート
-
サンプルインポートデータ
{ "id" : 1, "name" : "Benjamin", "age":18, "bitmap_id":243}
{ "id" : 2, "name" : "Emily", "age":20, "bitmap_id":28574}
{ "id" : 3, "name" : "Alexander", "age":22, "bitmap_id":8573} -
テーブル構造
CREATE TABLE demo.routine_test18 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
bitmap_id INT COMMENT "test",
device_id BITMAP BITMAP_UNION COMMENT "test column"
)
AGGREGATE KEY (`id`,`name`,`age`,`bitmap_id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job18 ON routine_test18
COLUMNS(id, name, age, bitmap_id, device_id=to_bitmap(bitmap_id))
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad18",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select id, BITMAP_UNION_COUNT(pv) over(order by id) uv from(
-> select id, BITMAP_UNION(device_id) as pv
-> from routine_test18
-> group by id
-> ) final;
+------+------+
| id | uv |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
3 rows in set (0.00 sec)
HLL Data Type のインポート
-
サンプルインポートデータ
2022-05-05,10001,Test01,Beijing,windows
2022-05-05,10002,Test01,Beijing,linux
2022-05-05,10003,Test01,Beijing,macos
2022-05-05,10004,Test01,Hebei,windows
2022-05-06,10001,Test01,Shanghai,windows
2022-05-06,10002,Test01,Shanghai,linux
2022-05-06,10003,Test01,Jiangsu,macos
2022-05-06,10004,Test01,Shaanxi,windows -
テーブル構造
create table demo.routine_test19 (
dt DATE,
id INT,
name VARCHAR(10),
province VARCHAR(10),
os VARCHAR(10),
pv hll hll_union
)
Aggregate KEY (dt,id,name,province,os)
distributed by hash(id) buckets 10; -
Importコマンド
CREATE ROUTINE LOAD demo.kafka_job19 ON routine_test19
COLUMNS TERMINATED BY ",",
COLUMNS(dt, id, name, province, os, pv=hll_hash(id))
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad19",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
インポート結果
mysql> select * from routine_test19;
+------------+-------+----------+----------+---------+------+
| dt | id | name | province | os | pv |
+------------+-------+----------+----------+---------+------+
| 2022-05-05 | 10001 | Test01 | Beijing | windows | NULL |
| 2022-05-06 | 10001 | Test01 | Shanghai | windows | NULL |
| 2022-05-05 | 10002 | Test01 | Beijing | linux | NULL |
| 2022-05-06 | 10002 | Test01 | Shanghai | linux | NULL |
| 2022-05-05 | 10004 | Test01 | Hebei | windows | NULL |
| 2022-05-06 | 10004 | Test01 | Shaanxi | windows | NULL |
| 2022-05-05 | 10003 | Test01 | Beijing | macos | NULL |
| 2022-05-06 | 10003 | Test01 | Jiangsu | macos | NULL |
+------------+-------+----------+----------+---------+------+
8 rows in set (0.01 sec)
mysql> SELECT HLL_UNION_AGG(pv) FROM routine_test19;
+-------------------+
| hll_union_agg(pv) |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.01 sec)
Kafka Security Authentication
SSL認証されたKafkaからのデータインポート
サンプルインポートコマンド:
CREATE ROUTINE LOAD demo.kafka_job20 ON routine_test20
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "ssl",
"property.ssl.ca.location" = "FILE:ca.pem",
"property.ssl.certificate.location" = "FILE:client.pem",
"property.ssl.key.location" = "FILE:client.key",
"property.ssl.key.password" = "ssl_passwd"
);
パラメータの説明:
| パラメータ | 説明 |
|---|---|
| property.security.protocol | 使用されるセキュリティプロトコル(上記の例ではSSLなど) |
| property.ssl.ca.location | CA(Certificate Authority)証明書の場所 |
| property.ssl.certificate.location | (Kafkaサーバーでクライアント認証が有効になっている場合のみ必要)クライアントの公開鍵の場所 |
| property.ssl.key.location | (Kafkaサーバーでクライアント認証が有効になっている場合のみ必要)クライアントの秘密鍵の場所 |
| property.ssl.key.password | (Kafkaサーバーでクライアント認証が有効になっている場合のみ必要)クライアントの秘密鍵のパスワード |
Kerberos認証されたKafkaからのデータインポート
サンプルインポートコマンド:
CREATE ROUTINE LOAD demo.kafka_job21 ON routine_test21
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "SASL_PLAINTEXT",
"property.sasl.kerberos.service.name" = "kafka",
"property.sasl.kerberos.keytab"="/opt/third/kafka/kerberos/kafka_client.keytab",
"property.sasl.kerberos.principal" = "clients/stream.dt.local@EXAMPLE.COM"
);
パラメータ説明:
| Parameter | Description |
|---|---|
| property.security.protocol | 使用されるセキュリティプロトコル、上記の例ではSASL_PLAINTEXTなど |
| property.sasl.kerberos.service.name | brokerサービス名を指定、デフォルトはKafka |
| property.sasl.kerberos.keytab | keytabファイルの場所 |
| property.sasl.kerberos.principal | kerberosプリンシパルを指定 |
krb5.confでrdnbs=trueを設定することを推奨します。そうでないと、次のエラーが発生する可能性があります:Server kafka/15.5.4.68@EXAMPLE.COM not found in Kerberos database
PLAIN認証Kafkaクラスターからのインポート
サンプルインポートコマンド:
CREATE ROUTINE LOAD demo.kafka_job22 ON routine_test22
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad22",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="admin",
"property.sasl.password"="admin"
);
パラメータの説明:
| パラメータ | 説明 |
|---|---|
| property.security.protocol | 使用されるセキュリティプロトコル(上記の例ではSASL_PLAINTEXTなど) |
| property.sasl.mechanism | SASL認証メカニズムをPLAINとして指定 |
| property.sasl.username | SASLユーザー名 |
| property.sasl.password | SASLパスワード |
単一ストリームからのマルチテーブルインポート
example_db用のtest1という名前のKafkaルーチン動的マルチテーブルインポートタスクを作成します。列区切り文字とgroup.idおよびclient.idを指定し、デフォルトですべてのパーティションを自動的に消費し、データが存在する位置(OFFSET_BEGINNING)から購読を開始します。
ここでは、KafkaからexampleDbのtbl1とtbl2の両方のテーブルにデータをインポートする必要があると仮定します。my_topicという名前のKafka Topicからtbl1とtbl2の両方に同時にデータをインポートするtest1という名前のルーチンインポートタスクを作成します。これにより、1つのルーチンインポートタスクでKafkaデータを2つのテーブルにインポートできます。
CREATE ROUTINE LOAD example_db.test1
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
この時点で、Kafkaのデータにはテーブル名情報が含まれている必要があります。現在、動的テーブル名はKafkaのValueからのみ取得でき、次の形式に準拠する必要があります:JSON形式:table_name|{"col1": "val1", "col2": "val2"}、ここでtbl_nameはテーブル名で、|がテーブル名とテーブルデータの区切り文字です。CSV形式のデータも同様で、例えば:table_name|val1,val2,val3です。ここでのtable_nameはDorisのテーブル名と一致する必要があり、そうでなければインポートが失敗することに注意してください。動的テーブルは後述するcolumn_mapping設定をサポートしないことに注意してください。
Strict Modeインポート
example_dbのexample_tblに対してtest1という名前のKafka routine importタスクを作成します。インポートタスクはstrict modeです。
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),
PRECEDING FILTER k1 = 1,
WHERE k1 < 100 and k2 like "%doris%"
PROPERTIES
(
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic"
);
暗号化および認証されたKafkaサービスへの接続
ここではStreamNative messagingサービスへのアクセスを例として使用します:
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(user_id, name, age)
FROM KAFKA (
"kafka_broker_list" = "pc-xxxx.aws-mec1-test-xwiqv.aws.snio.cloud:9093",
"kafka_topic" = "my_topic",
"property.security.protocol" = "SASL_SSL",
"property.sasl.mechanism" = "PLAIN",
"property.sasl.username" = "user",
"property.sasl.password" = "token:eyJhbxxx",
"property.group.id" = "my_group_id_1",
"property.client.id" = "my_client_id_1",
"property.enable.ssl.certificate.verification" = "false"
);
注意: BE側で信頼されたCA証明書パスが設定されていない場合、サーバー証明書が信頼されているかどうかを検証しないように "property.enable.ssl.certificate.verification" = "false" を設定する必要があります。
そうでない場合は、信頼されたCA証明書パスを設定する必要があります: "property.ssl.ca.location" = "/path/to/ca-cert.pem"。
さらなるヘルプ
SQLマニュアルのRoutine Loadを参照してください。また、クライアントのコマンドラインで HELP ROUTINE LOAD を入力することで、より多くのヘルプ情報を取得できます。