
ストリームロード
Stream Load は、HTTP プロトコルを通じてローカルファイルやデータストリームを Doris にインポートすることをサポートしています。
Stream Load は同期インポート方式で、インポート実行後にインポート結果を返すため、リクエストレスポンスを通じてインポートの成功を判断できます。一般的に、ユーザーは Stream Load を使用して 10GB 未満のファイルをインポートできます。ファイルが大きすぎる場合は、ファイルを分割してから Stream Load を使用してインポートすることを推奨します。Stream Load は一連のインポートタスクの原子性を保証できます。つまり、すべて成功するかすべて失敗するかのいずれかです。
curl を使用したシングルスレッドロードと比較して、Doris Streamloader は Apache Doris にデータをロードするために設計されたクライアントツールです。同時ロード機能により、大規模なデータセットの取り込み遅延を削減します。以下の機能を備えています:
- 並列ロード: Stream Load 方式のマルチスレッドロード。
workersパラメータを使用して並列度レベルを設定できます。 - マルチファイルロード: 複数のファイルとディレクトリを一度に同時にロード。再帰的ファイル取得をサポートし、ワイルドカード文字でファイル名を指定できます。
- パストラバーサルサポート: ソースファイルがディレクトリにある場合のパストラバーサルをサポート
- 復元性と継続性: 部分的なロード失敗の場合、失敗点からデータロードを再開できます。
- 自動リトライ機能: ロード失敗の場合、デフォルト回数の自動リトライが可能。ロードが依然として失敗する場合、手動リトライのためのコマンドを出力します。
詳細な手順とベストプラクティスについては Doris Streamloader を参照してください。
ユーザーガイド
Stream Load は、HTTP 経由でローカルまたはリモートソースから CSV、JSON、Parquet、および ORC 形式データのインポートをサポートしています。
- Null 値: null を表すには
\Nを使用します。例えば、a,\N,bは中央の列が null であることを示します。 - 空文字列: 2つのデリミタ間に文字がない場合、空文字列として表現されます。例えば、
a,,bでは、2つのカンマ間に文字がなく、中央の列値が空文字列であることを示します。
基本原理
Stream Load を使用する際は、HTTP プロトコルを通じて FE(Frontend)ノードにインポートジョブを開始する必要があります。FE はロードバランシングを実現するため、ラウンドロビン方式でリクエストを BE(Backend)ノードにリダイレクトします。特定の BE ノードに直接 HTTP リクエストを送信することも可能です。Stream Load では、Doris が1つのノードを Coordinator ノードとして選択します。Coordinator ノードはデータの受信と他のノードへの配信を担当します。
以下の図は Stream Load の主要なフローを示しており、一部のインポート詳細は省略されています。
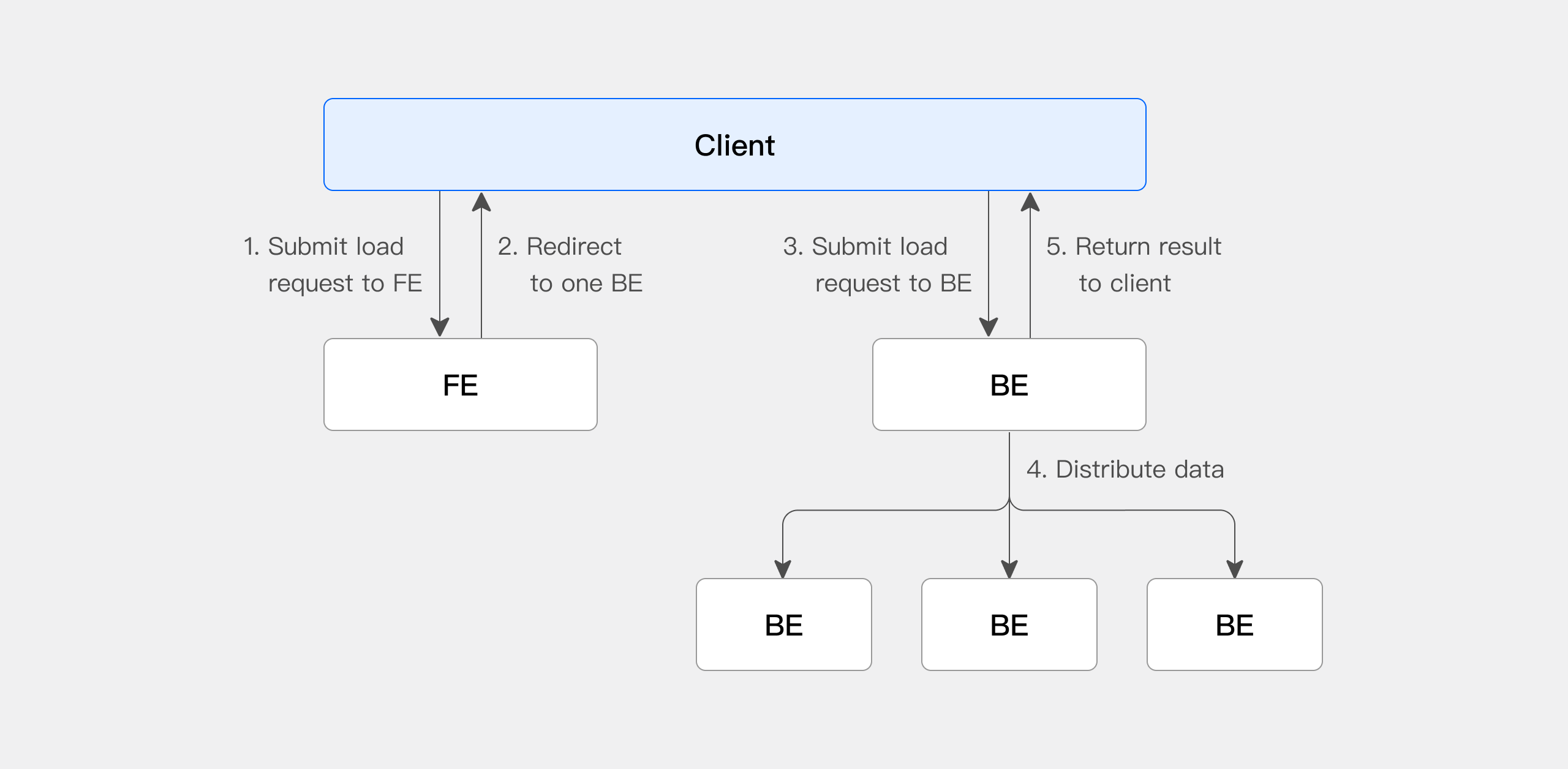
- クライアントが FE(Frontend)に Stream Load インポートジョブリクエストを送信します。
- FE がラウンドロビン方式でインポートジョブのスケジューリングを担当する BE(Backend)を Coordinator ノードとして選択し、クライアントに HTTP リダイレクトを返します。
- クライアントが Coordinator BE ノードに接続し、インポートリクエストを送信します。
- Coordinator BE が適切な BE ノードにデータを配信し、インポート完了後にクライアントにインポート結果を返します。
- 代替として、クライアントは直接 BE ノードを Coordinator として指定し、インポートジョブを直接配信できます。
クイックスタート
Stream Load は HTTP プロトコルを通じてデータをインポートします。以下の例では、curl ツールを使用して Stream Load 経由でインポートジョブを送信する方法を示します。
前提条件チェック
Stream Load にはターゲットテーブルに対する INSERT 権限が必要です。INSERT 権限がない場合は、GRANT コマンドを通じてユーザーに権限を付与できます。
ロードジョブの作成
CSV のロード
-
ロードデータの作成
streamload_example.csvという名前の CSV ファイルを作成します。具体的な内容は以下の通りです
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
-
ロード用のテーブルの作成
以下の特定の構文を使用して、インポート先となるテーブルを作成します:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User name",
age INT COMMENT "User age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
-
ロードジョブを有効化する
Stream Loadジョブは
curlコマンドを使用して送信できます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Stream Loadは同期メソッドで、結果はユーザーに直接返されます。
{
"TxnId": 3,
"Label": "123",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 118,
"LoadTimeMs": 173,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 70,
"ReadDataTimeMs": 2,
"WriteDataTimeMs": 48,
"CommitAndPublishTimeMs": 52
}
- データを表示
mysql> select count(*) from testdb.test_streamload;
+----------+
| count(*) |
+----------+
| 10 |
+----------+
JSONの読み込み
- 読み込みデータの作成
streamload_example.jsonという名前のJSONファイルを作成します。具体的な内容は以下の通りです
[
{"userid":1,"username":"Emily","userage":25},
{"userid":2,"username":"Benjamin","userage":35},
{"userid":3,"username":"Olivia","userage":28},
{"userid":4,"username":"Alexander","userage":60},
{"userid":5,"username":"Ava","userage":17},
{"userid":6,"username":"William","userage":69},
{"userid":7,"username":"Sophia","userage":32},
{"userid":8,"username":"James","userage":64},
{"userid":9,"username":"Emma","userage":37},
{"userid":10,"username":"Liam","userage":64}
]
-
ロード用のテーブルの作成
以下の特定の構文を使用して、インポート先となるテーブルを作成します:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User name",
age INT COMMENT "User age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
-
ロードジョブの有効化
Stream Loadジョブは
curlコマンドを使用して送信できます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:124" \
-H "Expect:100-continue" \
-H "format:json" -H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
JSONファイルがJSON配列ではなく、各行がJSONオブジェクトの場合は、ヘッダー -H "strip_outer_array:false" と -H "read_json_by_line:true" を追加してください。
JSONファイルのルートノードにあるJSONオブジェクトをロードする必要がある場合は、jsonpathsを . として指定する必要があります。例:`-H "jsonpaths:[\"."]`"
Stream Loadは同期メソッドで、結果は直接ユーザーに返されます。
{
"TxnId": 7,
"Label": "125",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 471,
"LoadTimeMs": 52,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 11,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 23,
"CommitAndPublishTimeMs": 16
}
ロード ジョブの表示
デフォルトでは、Stream Load は結果をクライアントに同期的に返すため、システムは Stream Load の履歴ジョブを記録しません。記録が必要な場合は、be.conf で設定 enable_stream_load_record=true を追加してください。具体的な詳細については、BE configuration options を参照してください。
設定後、show stream load コマンドを使用して、完了した Stream Load ジョブを表示できます。
mysql> show stream load from testdb;
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| Label | Db | Table | ClientIp | Status | Message | Url | TotalRows | LoadedRows | FilteredRows | UnselectedRows | LoadBytes | StartTime | FinishTime | User | Comment |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| 12356 | testdb | test_streamload | 192.168.88.31 | Success | OK | N/A | 10 | 10 | 0 | 0 | 118 | 2023-11-29 08:53:00.594 | 2023-11-29 08:53:00.650 | root | |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
1 row in set (0.00 sec)
Compute Groupの選択
ユーザーはStream Loadを実行する特定のCompute Groupを指定できます。
ストレージ・コンピュート分離モードでは、Compute Groupは以下の方法で指定できます:
- HTTPヘッダーパラメータで指定する。
-H "cloud_cluster:cluster1"
Doris 4.0.0以降、代替手段としてcompute_groupを使用できます
-H "compute_group:cluster1"
- Stream LoadにバインドされたユーザープロパティでCompute Groupを指定します。ユーザープロパティとHTTPヘッダーの両方でCompute Groupが指定されている場合、ヘッダーで指定されたCompute Groupが優先されます。
set property for user1 'default_compute_group'='cluster1';
- ユーザープロパティとHTTP Headerのいずれも Compute Group を指定しない場合、Stream Load にバインドされたユーザーがアクセス権限を持つ Compute Group が選択されます。 ユーザーがいずれの Compute Group にもアクセス権限を持たない場合、Load は失敗します。
統合ストレージ・コンピュート モードでは、Compute Group の指定は Stream Load にバインドされたユーザープロパティを通じてのみサポートされています。
ユーザープロパティで指定されていない場合、default という名前の Compute Group が選択されます。
set property for user1 'resource_tags.location'='group_1';
load ジョブのキャンセル
ユーザーは Stream Load 操作を手動でキャンセルすることはできません。Stream Load ジョブは、タイムアウト(0に設定)またはインポートエラーが発生した場合、システムによって自動的にキャンセルされます。
リファレンスマニュアル
コマンド
Stream Load の構文は以下の通りです:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" [-H ""...] \
-T <file_path> \
-XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Stream Load操作は、HTTPチャンク転送とノンチャンク転送の両方のインポート方法をサポートしています。ノンチャンク転送の場合、アップロードされるコンテンツの長さを示すContent-Lengthヘッダーが必要で、これによりデータの整合性が保証されます。
ロード設定パラメータ
FE設定
-
stream_load_default_timeout_second-
デフォルト値: 259200 (s)
-
動的設定: Yes
-
FE Master専用設定: Yes
-
パラメータの説明: Stream Loadのデフォルトタイムアウトです。設定されたタイムアウト(秒)内に完了しなかった場合、ロードジョブはシステムによってキャンセルされます。ソースファイルが指定された時間内にインポートできない場合、ユーザーはStream Loadリクエストで個別のタイムアウトを設定できます。または、FEのstream_load_default_timeout_secondパラメータを調整して、グローバルデフォルトタイムアウトを設定できます。
BE設定
-
streaming_load_max_mb- デフォルト値: 10240 (MB)
- 動的設定: Yes
- パラメータの説明: Stream Loadの最大インポートサイズです。ユーザーの元ファイルがこの値を超える場合、BEの
streaming_load_max_mbパラメータを調整する必要があります。
-
Headerパラメータ
ロードパラメータはHTTP Headerセクションを通じて渡すことができます。具体的なパラメータの説明については以下を参照してください。
| パラメータ | パラメータの説明 |
|---|---|
| label | このDorisインポートのラベルを指定するために使用されます。同じラベルのデータは複数回インポートできません。ラベルが指定されていない場合、Dorisは自動的に生成します。ユーザーはラベルを指定することで、同じデータの重複インポートを回避できます。Dorisはデフォルトで3日間インポートジョブのラベルを保持しますが、この期間はlabel_keep_max_secondを使用して調整できます。例えば、このインポートのラベルを123として指定するには、コマンド-H "label:123"を使用します。ラベルの使用により、ユーザーが同じデータを繰り返しインポートすることを防げます。同じバッチのデータに対しては同じラベルを使用することを強く推奨します。これにより、同じバッチデータの重複リクエストは一度だけ受け入れられ、At-Most-Onceセマンティクスが保証されます。ラベルに対応するインポートジョブのステータスがCANCELLEDの場合、そのラベルは再度使用できます。 |
| column_separator | インポートファイルの列区切り文字を指定するために使用され、デフォルトは\tです。区切り文字が非表示文字の場合、\xを前置し、16進数形式で表現する必要があります。複数の文字を組み合わせて列区切り文字として使用できます。例えば、Hiveファイルの区切り文字を\x01として指定するには、コマンド-H "column_separator:\x01"を使用します。 |
| line_delimiter | インポートファイルの行区切り文字を指定するために使用され、デフォルトは\nです。複数の文字を組み合わせて行区切り文字として使用できます。例えば、行区切り文字を\nとして指定するには、コマンド-H "line_delimiter:\n"を使用します。 |
| columns | インポートファイルの列とテーブルの列の対応関係を指定するために使用されます。ソースファイルの列がテーブルの内容と完全に一致する場合、このフィールドを指定する必要はありません。ソースファイルのスキーマがテーブルと一致しない場合、データ変換のためにこのフィールドが必要です。2つの形式があります:インポートファイルのフィールドへの直接列対応と、式で表現される派生列です。詳細な例についてはデータ変換を参照してください。 |
| where | 不要なデータをフィルタリングするために使用されます。ユーザーが特定のデータを除外する必要がある場合、このオプションを設定することで実現できます。例えば、k1列が20180601と等しいデータのみをインポートするには、インポート時に-H "where: k1 = 20180601"を指定します。 |
| max_filter_ratio | フィルタリング可能(不正または問題のある)データの最大許容比率を指定するために使用され、デフォルトでは許容しません。値の範囲は0から1です。インポートされるデータのエラー率がこの値を超える場合、インポートは失敗します。不正データにはwhere条件によってフィルタリングされた行は含まれません。例えば、すべての正しいデータを最大限インポートする(100%許容)には、コマンド-H "max_filter_ratio:1"を指定します。 |
| partitions | このインポートに関わるパーティションを指定するために使用されます。ユーザーがデータに対応するパーティションを特定できる場合、このオプションを指定することを推奨します。これらのパーティション条件を満たさないデータはフィルタリングされます。例えば、パーティションp1とp2へのインポートを指定するには、コマンド-H "partitions: p1, p2"を使用します。 |
| timeout | インポートのタイムアウトを秒単位で指定するために使用されます。デフォルトは600秒で、設定可能な範囲は1秒から259200秒です。例えば、インポートタイムアウトを1200秒として指定するには、コマンド-H "timeout:1200"を使用します。 |
| strict_mode | このインポートでstrictモードを有効にするかどうかを指定するために使用され、デフォルトでは無効です。例えば、strictモードを有効にするには、コマンド-H "strict_mode:true"を使用します。 |
| timezone | このインポートで使用されるタイムゾーンを指定するために使用され、デフォルトは現在のクラスタータイムゾーンです。このパラメータは、インポートに関わるすべてのタイムゾーン関連関数の結果に影響します。例えば、インポートタイムゾーンをAfrica/Abidjanとして指定するには、コマンド-H "timezone:Africa/Abidjan"を使用します。 |
| exec_mem_limit | インポートのメモリ制限で、デフォルトは2GBです。単位はバイトです。 |
| format | インポートデータの形式を指定するために使用され、デフォルトはCSVです。現在サポートされている形式には:CSV、JSON、arrow、csv_with_names(csvファイルの最初の行のフィルタリングをサポート)、csv_with_names_and_types(csvファイルの最初の2行のフィルタリングをサポート)、Parquet、ORCがあります。例えば、インポートデータ形式をJSONとして指定するには、コマンド-H "format:json"を使用します。 |
| jsonpaths | JSONデータ形式をインポートする方法は2つあります:シンプルモードとマッチングモードです。jsonpathsが指定されていない場合、シンプルモードとなり、JSONデータはオブジェクト型である必要があります。マッチングモードは、JSONデータが比較的複雑で、jsonpathsパラメータを通じて対応する値をマッチングする必要がある場合に使用されます。シンプルモードでは、JSONのキーがテーブルの列名と一対一で対応している必要があります。例えば、JSONデータ{"k1":1, "k2":2, "k3":"hello"}では、k1、k2、k3がそれぞれテーブルの列に対応します。 |
| strip_outer_array | strip_outer_arrayがtrueに設定されている場合、JSONデータが配列オブジェクトで始まり、配列内のオブジェクトを平坦化することを示します。デフォルト値はfalseです。JSONデータの最外層が配列を表す[]で表現されている場合、strip_outer_arrayをtrueに設定する必要があります。例えば、以下のデータでstrip_outer_arrayをtrueに設定すると、Dorisにインポートされる際に2行のデータが生成されます:[{"k1": 1, "v1": 2}, {"k1": 3, "v1": 4}]。 |
| json_root | json_rootはJSONドキュメントのルートノードを指定する有効なjsonpath文字列で、デフォルト値は""です。 |
| merge_type | データのマージタイプです。3つのタイプがサポートされています: - APPEND(デフォルト):このバッチのすべてのデータが既存のデータに追加されることを示します - DELETE:このバッチのデータとマッチするKeyを持つすべての行の削除を示します - MERGE:DELETE条件と組み合わせて使用する必要があります。DELETE条件を満たすデータはDELETEセマンティクスに従って処理され、残りはAPPENDセマンティクスに従って処理されます 例えば、マージモードをMERGEとして指定する場合: -H "merge_type: MERGE" -H "delete: flag=1" |
| delete | MERGEの場合のみ意味があり、データの削除条件を表します。 |
| function_column.sequence_col | UNIQUE KEYSモデルにのみ適用されます。同じKey列内で、指定されたsource_sequence列に従ってValue列が置き換えられることを保証します。source_sequenceは、データソースの列またはテーブル構造の既存の列のいずれかです。 |
| fuzzy_parse | boolean型です。trueに設定された場合、JSONは最初の行をスキーマとして解析されます。このオプションを有効にするとJSONインポートの効率が向上しますが、すべてのJSONオブジェクトのキーの順序が最初の行と一致している必要があります。デフォルトはfalseで、JSON形式でのみ使用されます。 |
| num_as_string | boolean型です。trueに設定された場合、JSON解析時に数値型が文字列に変換され、インポートプロセス中の精度の損失がないことを保証します。 |
| read_json_by_line | boolean型です。trueに設定された場合、1行につき1つのJSONオブジェクトの読み取りをサポートし、デフォルトはfalseです。 |
| send_batch_parallelism | バッチ処理されたデータを送信する並列度の並列度を設定します。並列度の値がBEで設定されたmax_send_batch_parallelism_per_jobを超える場合、コーディネートするBEはmax_send_batch_parallelism_per_job値を使用します。 |
| hidden_columns | インポートデータの非表示列を指定するために使用され、HeaderにColumnsが含まれていない場合に有効です。複数の非表示列はカンマで区切ります。システムはユーザーが指定したデータをインポートに使用します。以下の例では、インポートデータの最後の列は__DORIS_SEQUENCE_COL__です。hidden_columns: __DORIS_DELETE_SIGN__,__DORIS_SEQUENCE_COL__。 |
| load_to_single_tablet | boolean型です。trueに設定された場合、パーティションに対応する単一のTabletへのデータインポートのみをサポートし、デフォルトはfalseです。このパラメータは、ランダムバケティングを持つOLAPテーブルへのインポート時のみ許可されます。 |
| compress_type | 現在、CSVファイルの圧縮のみサポートされています。圧縮形式にはgz、lzo、bz2、lz4、lzop、deflateがあります。 |
| trim_double_quotes | boolean型です。trueに設定された場合、CSVファイルの各フィールドの最外側の二重引用符をトリムすることを示し、デフォルトはfalseです。 |
| skip_lines | integer型です。CSVファイルの先頭でスキップする行数を指定するために使用され、デフォルトは0です。formatがcsv_with_namesまたはcsv_with_names_and_typesに設定されている場合、このパラメータは無効になります。 |
| comment | String型で、デフォルト値は空文字列です。タスクに追加情報を追加するために使用されます。 |
| enclose | 囲み文字を指定します。CSVデータフィールドに行区切り文字または列区切り文字が含まれている場合、予期しない切り捨てを防ぐため、単一バイト文字を保護用の囲み文字として指定できます。例えば、列区切り文字が","で、囲み文字が"'"の場合、データ"a,'b,c'"は"b,c"が単一フィールドとして解析されます。注意:囲み文字が二重引用符(")に設定されている場合、trim_double_quotesをtrueに設定してください。 |
| escape | エスケープ文字を指定します。フィールド内で囲み文字と同じ文字をエスケープするために使用されます。例えば、データが"a,'b,'c'"で、囲み文字が"'"で、"b,'c"を単一フィールドとして解析したい場合、""などの単一バイトエスケープ文字を指定し、データを"a,'b','c'"に変更する必要があります。 |
| memtable_on_sink_node | データロード時にDataSinkノードでMemTableを有効にするかどうか、デフォルトはfalseです。 |
| unique_key_update_mode | Uniqueテーブルの更新モード、現在はMerge-On-Write Uniqueテーブルに対してのみ有効です。3つのタイプをサポート:UPSERT、UPDATE_FIXED_COLUMNS、UPDATE_FLEXIBLE_COLUMNS。UPSERT:データがupsertセマンティクスでロードされることを示します;UPDATE_FIXED_COLUMNS:データが部分更新によってロードされることを示します;UPDATE_FLEXIBLE_COLUMNS:データが柔軟な部分更新によってロードされることを示します。 |
| partial_update_new_key_behavior | Uniqueテーブルで部分列更新または柔軟列更新を実行する際、このパラメータは新しい行の処理方法を制御します。2つのタイプがあります:APPENDとERROR。- APPEND:新しい行データの挿入を許可します- ERROR:新しい行を挿入する際に失敗してエラーを報告します |
ロード戻り値
Stream Loadは同期インポート方法で、ロード結果はロード戻り値の作成を通じて直接ユーザーに提供されます。以下に示します:
{
"TxnId": 1003,
"Label": "b6f3bc78-0d2c-45d9-9e4c-faa0a0149bee",
"Status": "Success",
"ExistingJobStatus": "FINISHED", // optional
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 325,
"WriteDataTimeMs": 1933,
"CommitAndPublishTimeMs": 106,
"ErrorURL": "http://192.168.1.1:8042/api/_load_error_log?file=__shard_0/error_log_insert_stmt_db18266d4d9b4ee5-abb00ddd64bdf005_db18266d4d9b4ee5_abb00ddd64bdf005"
}
戻り値のパラメーターについて以下の表で説明します:
| Parameters | Parameters description |
|---|---|
| TxnId | インポートトランザクションID |
| Label | ロードジョブのLabel、-H "label:<label_id>"で指定 |
| Status | 最終的なロードStatus。Success:ロードジョブが成功しました。Publish Timeout:ロードジョブは完了しましたが、データの可視性に遅延がある可能性があります。Label Already Exists:labelが重複しているため、新しいlabelが必要です。Fail:ロードジョブが失敗しました。 |
| ExistingJobStatus | 既に存在するlabelに対応するロードジョブのステータス。このフィールドはStatusがLabel Already Existsの場合のみ表示されます。ユーザーはこのステータスを使用して、既存のlabelに対応するインポートジョブのステータスを知ることができます。RUNNINGはジョブがまだ実行中であることを意味し、FINISHEDはジョブが成功したことを意味します。 |
| Message | ロードジョブに関連するエラー情報 |
| NumberTotalRows | ロードジョブ中に処理された行の総数 |
| NumberLoadedRows | 正常にロードされた行数 |
| NumberFilteredRows | データ品質基準を満たさなかった行数 |
| NumberUnselectedRows | WHERE条件に基づいてフィルタリングされた行数 |
| LoadBytes | データ量(バイト単位) |
| LoadTimeMs | ロードジョブの完了にかかった時間(ミリ秒単位) |
| BeginTxnTimeMs | Frontendノード(FE)からトランザクションの開始を要求するのにかかった時間(ミリ秒単位) |
| StreamLoadPutTimeMs | FEからロードジョブデータの実行計画を要求するのにかかった時間(ミリ秒単位) |
| ReadDataTimeMs | ロードジョブ中にデータを読み取るのに費やした時間(ミリ秒単位) |
| WriteDataTimeMs | ロードジョブ中にデータ書き込み操作を実行するのにかかった時間(ミリ秒単位) |
| CommitAndPublishTimeMs | FEからトランザクションのcommitとpublishを要求するのにかかった時間(ミリ秒単位) |
| ErrorURL | データ品質に問題がある場合、ユーザーはこのURLにアクセスして、エラーのある特定の行を表示できます |
ユーザーはErrorURLにアクセスして、データ品質の問題によりインポートに失敗したデータを確認できます。curl "<ErrorURL>"コマンドを実行することで、ユーザーは直接エラーのあるデータに関する情報を取得できます。
ロードの例
ロードタイムアウトと最大サイズの設定
ロードジョブのタイムアウトは秒単位で測定されます。指定されたタイムアウト時間内にロードジョブが完了しない場合、システムによってキャンセルされ、CANCELLEDとしてマークされます。timeoutパラメーターを指定するか、fe.confファイルにstream_load_default_timeout_secondパラメーターを追加することで、Stream Loadジョブのタイムアウトを調整できます。
ロードを開始する前に、ファイルサイズに基づいてタイムアウトを計算する必要があります。例えば、100GBのファイルで推定ロードパフォーマンスが50MB/sの場合:
Load time ≈ 100GB / 50MB/s ≈ 2048s
Stream Load ジョブの作成に 3000 秒のタイムアウトを指定するには、以下のコマンドを使用できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "timeout:3000"
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
最大エラー許容率の設定
Load jobは、フォーマットエラーのあるデータを一定量まで許容できます。許容率はmax_filter_ratioパラメータを使用して設定されます。デフォルトでは0に設定されており、これは1つでもエラーのあるデータ行が存在する場合、Load job全体が失敗することを意味します。ユーザーが問題のあるデータ行を無視したい場合は、このパラメータを0から1の間の値に設定できます。Dorisは不正なデータフォーマットの行を自動的にスキップします。許容率の計算に関する詳細については、Data Transformationのドキュメントを参照してください。
以下のコマンドを使用して、Stream Load jobの作成時にmax_filter_ratio許容率を0.4に指定できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.4" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
ロード時のフィルタリング条件の設定
ロードジョブ実行中に、WHEREパラメータを使用してインポートされるデータに条件フィルタリングを適用できます。フィルタリングされたデータはフィルタ比率の計算に含まれず、max_filter_ratioの設定にも影響しません。ロードジョブの完了後、num_rows_unselectedを確認することでフィルタリングされた行数を確認できます。
Stream Loadジョブの作成時にWHEREフィルタリング条件を指定するには、以下のコマンドを使用できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "where:age>=35" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
特定のパーティションへのデータ読み込み
ローカルファイルからテーブルのパーティションp1とp2にデータを読み込み、20%のエラー率を許可します。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:123" \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.2" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-H "partitions: p1, p2" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
特定のタイムゾーンへのデータの読み込み
DATETIME関連の型は絶対時刻のみを表し、タイムゾーン情報を含まず、Dorisシステムのタイムゾーンの変更によって変わることはありません。そのため、タイムゾーン付きデータのインポートに対して、統一的な処理方法として特定のターゲットタイムゾーンのデータに変換します。Dorisシステムでは、これはセッション変数time_zoneによって表されるタイムゾーンです。
インポートにおいて、ターゲットタイムゾーンはパラメータtimezoneで指定します。この変数は、タイムゾーン変換が発生し、タイムゾーンに依存する関数が計算される際に、セッション変数time_zoneを置き換えます。そのため、特別な事情がない限り、インポートトランザクションではtimezoneを現在のDorisクラスタのtime_zoneと一致するように設定する必要があります。これは、タイムゾーン付きのすべての時刻データがこのタイムゾーンに変換されることを意味します。
例えば、Dorisシステムのタイムゾーンが"+08:00"で、インポートするデータの時刻カラムに"2012-01-01 01:00:00+00:00"と"2015-12-12 12:12:12-08:00"という2つのデータが含まれている場合、インポート時に-H "timezone: +08:00"でインポートトランザクションのタイムゾーンを指定すると、両方のデータがそのタイムゾーンに変換され、"2012-01-01 09:00:00"と"2015-12-13 04:12:12"という結果が得られます。
タイムゾーンの解釈に関する詳細情報については、ドキュメントTime Zoneを参照してください。
ストリーミングインポート
Stream LoadはHTTPプロトコルに基づくインポート方式で、Java、Go、Pythonなどのプログラミング言語を使用したストリーミングインポートをサポートしています。これがStream Loadと呼ばれる理由です。
以下の例は、bashコマンドパイプラインを通じてこの使用法を実演しています。インポートするデータは、ローカルファイルからではなく、プログラムによってストリーミング生成されます。
seq 1 10 | awk '{OFS="\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load
CSV の最初の行のフィルタリングを設定
ファイルデータ:
id,name,age
1,doris,20
2,flink,10
format=csv_with_namesを指定してロード時に最初の行をフィルタリングする
curl --location-trusted -u root -T test.csv -H "label:1" -H "format:csv_with_names" -H "column_separator:," http://host:port/api/testDb/testTbl/_stream_load
DELETE操作におけるmerge_typeの指定
Stream Loadには、APPEND、DELETE、MERGEの3つのインポートタイプがあります。これらはmerge_typeパラメータを指定することで調整できます。インポートされたデータと同じキーを持つすべてのデータを削除することを指定したい場合は、以下のコマンドを使用できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
読み込み前:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 3 | 2 | tom | 2 |
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
インポートされたデータは以下の通りです:
3,2,tom,0
インポート後、元のテーブルデータは削除され、以下の結果となります:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
MERGE操作における merge_type の指定
merge_typeをMERGEとして指定することで、インポートされたデータをテーブルにマージできます。MERGEセマンティクスはDELETE条件と組み合わせて使用する必要があり、これはDELETE条件を満たすデータがDELETEセマンティクスに従って処理され、残りのデータがAPPENDセマンティクスに従ってテーブルに追加されることを意味します。以下の操作は、siteidが1の行を削除し、残りのデータをテーブルに追加することを表しています:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: MERGE" \
-H "delete: siteid=1" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
読み込み前:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
| 1 | 1 | jim | 2 |
+--------+----------+----------+------+
インポートされたデータは以下の通りです:
2,1,grace,2
3,2,tom,2
1,1,jim,2
読み込み後、条件に従ってsiteid = 1の行が削除され、siteidが2と3の行がテーブルに追加されます:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 2 | 1 | grace | 2 |
| 3 | 2 | tom | 2 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
merge時のsequenceカラムの指定
Unique Keyを持つテーブルにSequenceカラムがある場合、Sequenceカラムの値は、同一のKeyカラム下でのREPLACE集約関数における置換順序の基準として機能します。より大きな値がより小さな値を置換できます。このようなテーブルに対してDORIS_DELETE_SIGNに基づく削除をマークする場合、Keyが同一であり、Sequenceカラムの値が現在の値以上であることを確実にする必要があります。function_column.sequence_colパラメータを指定することで、merge_type: DELETEと組み合わせて削除操作を実行できます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "function_column.sequence_col: age" \
-H "column_separator:," \
-H "columns: name, gender, age"
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
以下のテーブルスキーマが与えられた場合:
SET show_hidden_columns=true;
Query OK, 0 rows affected (0.00 sec)
DESC table1;
+------------------------+--------------+------+-------+---------+---------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+--------------+------+-------+---------+---------+
| name | VARCHAR(100) | No | true | NULL | |
| gender | VARCHAR(10) | Yes | false | NULL | REPLACE |
| age | INT | Yes | false | NULL | REPLACE |
| __DORIS_DELETE_SIGN__ | TINYINT | No | false | 0 | REPLACE |
| __DORIS_SEQUENCE_COL__ | INT | Yes | false | NULL | REPLACE |
+------------------------+--------------+------+-------+---------+---------+
4 rows in set (0.00 sec)
元のテーブルデータは以下の通りです:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
-
Sequenceパラメータは Eeffect を取り、loading sequence カラム値はテーブル内の既存データ以上になります。
データのロードは以下の通りです:
li,male,10
function_column.sequence_colにageが指定されており、ageの値がテーブル内の既存の列以上であるため、元のテーブルデータが削除されます。テーブルデータは次のようになります:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
-
Sequenceパラメータが有効にならない場合、読み込みシーケンス列の値がテーブル内の既存データ以下になります:
読み込みデータ:
li,male,9
function_column.sequence_colにageが指定されていますが、ageの値がテーブル内の既存の列より小さいため、削除操作は実行されません。テーブルデータは変更されず、主キーがliの行は引き続き表示されます:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
削除されない理由は、基盤となる依存関係レベルで、まず同じキーを持つ行をチェックするためです。より大きなsequence列の値を持つ行データを表示します。次に、その行のDORIS_DELETE_SIGN値をチェックします。1の場合、外部に表示されません。0の場合、まだ読み取られ表示されます。
囲み文字を使用したデータの読み込み
CSVファイル内のデータに区切り文字や分離文字が含まれている場合、単一バイト文字を囲み文字として指定することで、データが切り詰められることを防ぐことができます。
例えば、以下のデータでは、コンマが分離文字として使用されているが、フィールド内にも存在している場合:
zhangsan,30,'Shanghai, HuangPu District, Dagu Road'
単一引用符 ' などの囲み文字を指定することで、Shanghai, HuangPu District, Dagu Road 全体を単一のフィールドとして扱うことができます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
囲み文字がフィールド内にも出現する場合、例えばShanghai City, Huangpu District, \'Dagu Roadを単一のフィールドとして扱いたい場合は、まず列内で文字列エスケープを実行する必要があります:
Zhang San,30,'Shanghai, Huangpu District, \'Dagu Road'
エスケープ文字は、単一バイト文字であり、escapeパラメータを使用して指定できます。この例では、バックスラッシュ\がエスケープ文字として使用されています。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "escape:\\" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
DEFAULT CURRENT_TIMESTAMP型を含むフィールドの読み込み
DEFAULT CURRENT_TIMESTAMP型のフィールドを含むテーブルにデータを読み込む例を以下に示します:
テーブルスキーマ:
`id` bigint(30) NOT NULL,
`order_code` varchar(30) DEFAULT NULL COMMENT '',
`create_time` datetimev2(3) DEFAULT CURRENT_TIMESTAMP
JSONデータ型:
{"id":1,"order_Code":"avc"}
コマンド:
curl --location-trusted -u root -T test.json -H "label:1" -H "format:json" -H 'columns: id, order_code, create_time=CURRENT_TIMESTAMP()' http://host:port/api/testDb/testTbl/_stream_load
JSON形式データの読み込みのためのシンプルモード
JSONフィールドがテーブルの列名と一対一で対応している場合、パラメータ"strip_outer_array:true"と"format:json"を指定することで、JSON データ形式をテーブルにインポートできます。
例えば、テーブルが以下のように定義されている場合:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User name",
age INT COMMENT "User age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
データフィールド名はテーブル内の列名と一対一で対応します:
[
{"user_id":1,"name":"Emily","age":25},
{"user_id":2,"name":"Benjamin","age":35},
{"user_id":3,"name":"Olivia","age":28},
{"user_id":4,"name":"Alexander","age":60},
{"user_id":5,"name":"Ava","age":17},
{"user_id":6,"name":"William","age":69},
{"user_id":7,"name":"Sophia","age":32},
{"user_id":8,"name":"James","age":64},
{"user_id":9,"name":"Emma","age":37},
{"user_id":10,"name":"Liam","age":64}
]
次のコマンドを使用してJSONデータをテーブルに読み込むことができます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
複雑なJSON形式データの読み込みにおけるマッチングモード
JSONデータがより複雑で、テーブルの列名と一対一で対応できない場合や、余分な列がある場合は、jsonpathsパラメータを使用して列名マッピングを完了し、データマッチングインポートを実行できます。例えば、以下のデータの場合:
[
{"userid":1,"hudi":"lala","username":"Emily","userage":25,"userhp":101},
{"userid":2,"hudi":"kpkp","username":"Benjamin","userage":35,"userhp":102},
{"userid":3,"hudi":"ji","username":"Olivia","userage":28,"userhp":103},
{"userid":4,"hudi":"popo","username":"Alexander","userage":60,"userhp":103},
{"userid":5,"hudi":"uio","username":"Ava","userage":17,"userhp":104},
{"userid":6,"hudi":"lkj","username":"William","userage":69,"userhp":105},
{"userid":7,"hudi":"komf","username":"Sophia","userage":32,"userhp":106},
{"userid":8,"hudi":"mki","username":"James","userage":64,"userhp":107},
{"userid":9,"hudi":"hjk","username":"Emma","userage":37,"userhp":108},
{"userid":10,"hudi":"hua","username":"Liam","userage":64,"userhp":109}
]
指定された列にマッチするようにjsonpathsパラメータを指定できます:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
データ読み込み時のJSONルートノードの指定
JSONデータにネストされたJSONフィールドが含まれている場合、インポートするJSONのルートノードを指定する必要があります。デフォルト値は ""です。
例えば、以下のデータで、commentカラム内のデータをテーブルにインポートしたい場合:
[
{"user":1,"comment":{"userid":101,"username":"Emily","userage":25}},
{"user":2,"comment":{"userid":102,"username":"Benjamin","userage":35}},
{"user":3,"comment":{"userid":103,"username":"Olivia","userage":28}},
{"user":4,"comment":{"userid":104,"username":"Alexander","userage":60}},
{"user":5,"comment":{"userid":105,"username":"Ava","userage":17}},
{"user":6,"comment":{"userid":106,"username":"William","userage":69}},
{"user":7,"comment":{"userid":107,"username":"Sophia","userage":32}},
{"user":8,"comment":{"userid":108,"username":"James","userage":64}},
{"user":9,"comment":{"userid":109,"username":"Emma","userage":37}},
{"user":10,"comment":{"userid":110,"username":"Liam","userage":64}}
]
まず、json_rootパラメータを使用してルートノードをコメントとして指定し、その後jsonpathsパラメータに従ってカラム名マッピングを完了する必要があります。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "json_root: $.comment" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
配列データ型の読み込み
例えば、以下のデータに配列型が含まれている場合:
1|Emily|[1,2,3,4]
2|Benjamin|[22,45,90,12]
3|Olivia|[23,16,19,16]
4|Alexander|[123,234,456]
5|Ava|[12,15,789]
6|William|[57,68,97]
7|Sophia|[46,47,49]
8|James|[110,127,128]
9|Emma|[19,18,123,446]
10|Liam|[89,87,96,12]
以下のテーブル構造にデータを読み込みます:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NOT NULL COMMENT "ID",
name VARCHAR(20) NULL COMMENT "Name",
arr ARRAY<int(10)> NULL COMMENT "Array"
)
DUPLICATE KEY(typ_id)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
Stream Load ジョブを使用して、テキストファイルから ARRAY 型を直接テーブルに読み込むことができます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:|" \
-H "columns:typ_id,name,arr" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
マップデータ型の読み込み
インポートされたデータがマップ型を含む場合、以下の例のように:
[
{"user_id":1,"namemap":{"Emily":101,"age":25}},
{"user_id":2,"namemap":{"Benjamin":102,"age":35}},
{"user_id":3,"namemap":{"Olivia":103,"age":28}},
{"user_id":4,"namemap":{"Alexander":104,"age":60}},
{"user_id":5,"namemap":{"Ava":105,"age":17}},
{"user_id":6,"namemap":{"William":106,"age":69}},
{"user_id":7,"namemap":{"Sophia":107,"age":32}},
{"user_id":8,"namemap":{"James":108,"age":64}},
{"user_id":9,"namemap":{"Emma":109,"age":37}},
{"user_id":10,"namemap":{"Liam":110,"age":64}}
]
以下のテーブル構造にデータをロードします:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "ID",
namemap Map<STRING, INT> NULL COMMENT "Name"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
Stream Load タスクを使用して、テキストファイルからmap型を直接テーブルにロードできます。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format: json" \
-H "strip_outer_array:true" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
bitmap データ型の読み込み
インポート処理中に、Bitmap 型のデータに遭遇した場合、to_bitmap を使用してデータを Bitmap に変換するか、bitmap_empty 関数を使用して Bitmap を埋めることができます。
例えば、以下のデータの場合:
1|koga|17723
2|nijg|146285
3|lojn|347890
4|lofn|489871
5|jfin|545679
6|kon|676724
7|nhga|767689
8|nfubg|879878
9|huang|969798
10|buag|97997
Bitmap型を含む以下のテーブルにデータを読み込む:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
hou VARCHAR(10) NULL COMMENT "one",
arr BITMAP BITMAP_UNION NOT NULL COMMENT "two"
)
AGGREGATE KEY(typ_id,hou)
DISTRIBUTED BY HASH(typ_id,hou) BUCKETS 10;
そして、to_bitmapを使用してデータをBitmap型に変換します。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "columns:typ_id,hou,arr,arr=to_bitmap(arr)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
HyperLogLog データ型の読み込み
hll_hash 関数を使用してデータを hll 型に変換できます。以下の例をご覧ください:
1001|koga
1002|nijg
1003|lojn
1004|lofn
1005|jfin
1006|kon
1007|nhga
1008|nfubg
1009|huang
1010|buag
以下のテーブルにデータを読み込みます:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
typ_name VARCHAR(10) NULL COMMENT "NAME",
pv hll hll_union NOT NULL COMMENT "hll"
)
AGGREGATE KEY(typ_id,typ_name)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
そして、インポートにはhll_hashコマンドを使用します。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "column_separator:|" \
-H "columns:typ_id,typ_name,pv=hll_hash(typ_id)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
カラムマッピング、派生カラム、およびフィルタリング
Dorisは、ロード文において非常に豊富なカラム変換およびフィルタリング操作をサポートしています。ほとんどの組み込み関数をサポートしています。この機能を正しく使用する方法については、Data Transformationドキュメントを参照してください。
strict modeインポートの有効化
strict_mode属性は、インポートタスクがstrict modeで実行されるかどうかを設定するために使用されます。この属性は、カラムマッピング、変換、およびフィルタリングの結果に影響します。strict modeの具体的な手順については、Handling Messy Dataドキュメントを参照してください。
インポート中の部分カラム更新/柔軟な部分更新の実行
インポート中に部分カラム更新を表現する方法については、Partial Column Updateドキュメントを参照してください。