
リリース 3.0.0
Apache Doris 3.0のリリースを発表できることを嬉しく思います!
バージョン3.Xから、Apache Dorisはクラスター展開において従来のコンピュート・ストレージ結合モードに加えて、コンピュート・ストレージ分離モードをサポートします。計算層とストレージ層を分離するクラウドネイティブアーキテクチャにより、ユーザーは複数のコンピュートクラスター間でクエリ負荷の物理的分離、および読み書き負荷の分離を実現できます。さらに、ユーザーはオブジェクトストレージやHDFSなどの低コスト共有ストレージシステムを活用して、ストレージコストを大幅に削減できます。
バージョン3.0は、Apache Dorisが統合データレイク・データウェアハウスアーキテクチャに向けて進化する上でのマイルストーンとなります。このバージョンでは、データレイクへのデータ書き戻し機能が導入され、ユーザーはApache Doris内で複数のデータソースにわたってデータ分析、共有、処理、ストレージ操作を実行できるようになります。非同期マテリアライズドビューなどの機能により、Apache Dorisは企業の統合データ処理エンジンとして機能し、ユーザーがレイク、ウェアハウス、データベース間でデータをより適切に管理できるよう支援します。また、Apache Doris 3.0にはTrino Connectorが導入されました。これにより、ユーザーはより多くのデータソースに迅速に接続または適応し、Dorisのハイパフォーマンスコンピュートエンジンを活用してTrinoよりも高速なクエリ結果を提供できます。
バージョン3.0では、ETLバッチ処理シナリオのサポートも強化され、insert into select、delete、updateなどの操作に対する明示的トランザクションサポートが追加されました。クエリ実行の可観測性も改善されました。
パフォーマンスの面では、バージョン3.0でクエリオプティマイザーのフレームワーク機能、インフラストラクチャ、およびルールを改善しました。これにより、より複雑で多様なビジネスシナリオでのブラインドテストで実証されている最適化されたパフォーマンスを提供します。
適応Runtime Filterの計算方式では、実行時にデータサイズに基づいてフィルターを正確に推定し、大容量データと高負荷下でより良いパフォーマンスを提供します。さらに、非同期マテリアライズドビューは、クエリ高速化とデータモデリングにおいてより安定的でユーザーフレンドリーになりました。
バージョン3.0の開発期間中、200人を超える貢献者がApache Dorisに約5,000件の最適化と修正を提出しました。VeloDB、Baidu、Meituan、ByteDance、Tencent、Alibaba、Kwai、Huawei、Tianyi Cloudなどの企業の貢献者がコミュニティと積極的に協力し、実際のユースケースからのテストケースを提供してApache Dorisの改善に貢献しました。このリリースの開発、テスト、フィードバックプロセスに関わったすべての貢献者に心から感謝いたします。
1. コンピュート・ストレージ分離モード
V3.0から、Apache Dorisはコンピュート・ストレージ分離モードをサポートします。ユーザーはクラスター展開時に、これとコンピュート・ストレージ結合モードのいずれかを選択できます。
コンピュート・ストレージ分離モードでは、BEノードはデータを保存せず、代わりに共有ストレージ層(HDFSとオブジェクトストレージ)が共有データストレージ層として導入されます。コンピューティングリソースとストレージリソースは独立してスケールでき、ユーザーに複数のメリットをもたらします:
-
ワークロード分離: 複数のコンピュートクラスターが同じデータを共有でき、ユーザーは別々のコンピュートクラスターを使用して異なるビジネスワークロードやオフライン負荷を分離できます。
-
ストレージコスト削減: データセット全体がより費用対効果が高く高信頼性の共有ストレージに保存され、ローカルにはホットデータのみがキャッシュされます。3つのデータレプリカを持つコンピュート・ストレージ結合モードと比較して、ストレージコストを最大90%削減できます。
-
エラスティックコンピューティングリソース: BEノードにデータが保存されないため、コンピューティングリソースは負荷要件に基づいて柔軟にスケールできます。ユーザーは個別のコンピュートクラスターをスケールインまたはスケールアウトしたり、コンピュートクラスターの数を増減したりできます。これもコスト削減につながります。
-
システム堅牢性の向上: データを共有ストレージに保存することで、Dorisはマルチレプリカ一貫性の複雑なロジックを処理する必要がなくなり、分散ストレージの複雑性が簡素化され、システム全体の堅牢性が向上します。
-
柔軟なデータ共有とクローニング: コンピュート・ストレージ分離モードの柔軟性は、単一のDorisクラスターを超えて拡張されます。あるDorisクラスターのテーブルを別のDorisクラスターに簡単にクローンでき、メタデータの複製のみで済みます。
1-1. 結合から分離へ
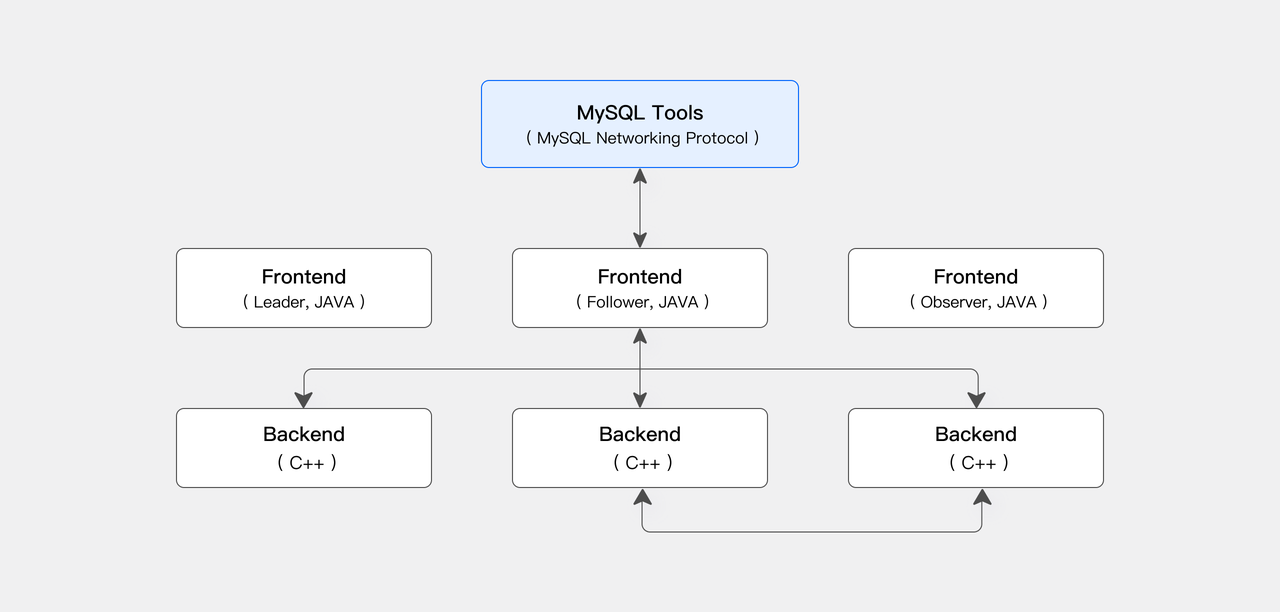
コンピュート・ストレージ結合モードでは、Apache Dorisアーキテクチャは2つの主要なプロセスタイプで構成されます:Frontend(FE)とBackend(BE)。FEは主にユーザーリクエストアクセス、クエリ解析と計画、メタデータ管理、ノード管理を担当します。BEはデータストレージとクエリプラン実行を担当します。
BEノードはMPP(Massively Parallel Processing)分散コンピューティングアーキテクチャを採用し、マルチレプリカ一貫性プロトコルを活用して高いサービス可用性と高いデータ信頼性を確保します。
パブリッククラウド、プライベートクラウド、Kubernetesベースのコンテナプラットフォームを含む新興クラウドコンピューティングインフラストラクチャの成熟により、クラウドネイティブ機能の必要性が高まっています。ますます多くのユーザーが、より多くの弾力性を提供するためにApache Dorisとクラウドコンピューティングインフラストラクチャとの深い統合を求めています。
このニーズに対応するため、VeloDBチームはコンピュートとストレージを分離するApache Dorisのクラウドネイティブバージョンを設計・実装し、VeloDB Cloudとして知られています。長期間にわたって数百の企業で広範囲な本番テストと改良を行った後、このクラウドネイティブソリューションはApache Dorisコミュニティに貢献され、コンピュート・ストレージ分離モードのApache Doris 3.0として現れています。
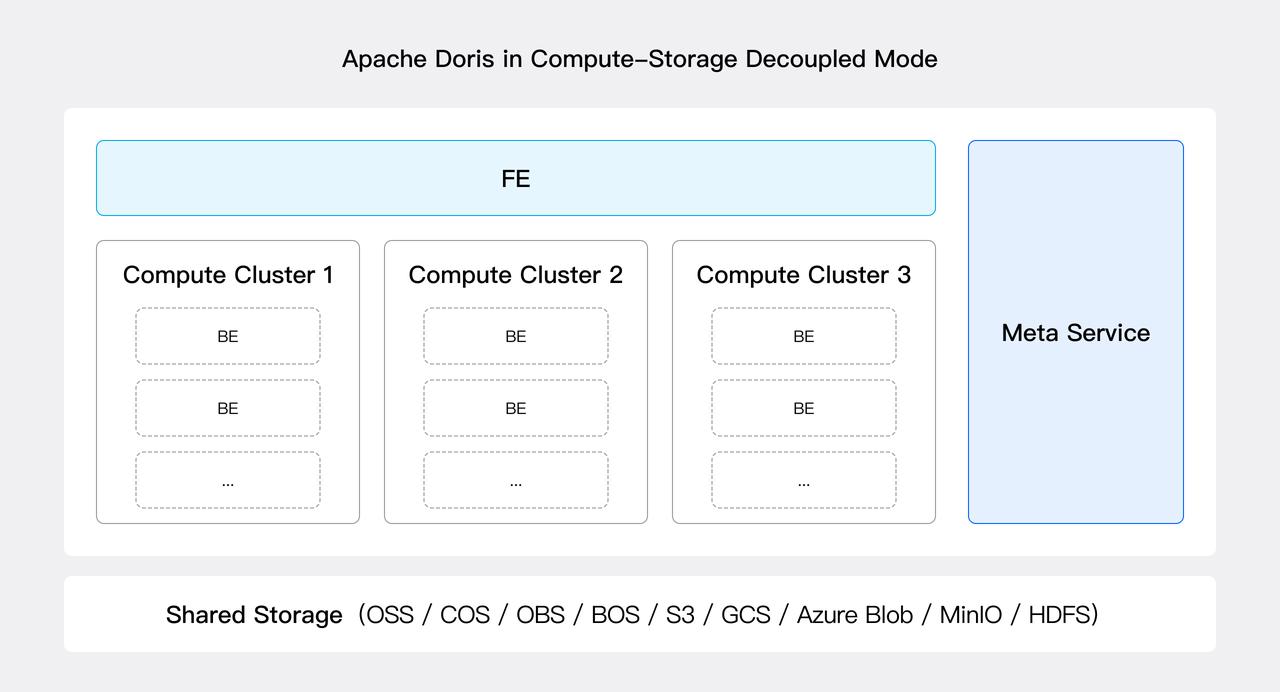
コンピュート・ストレージ分離モードでは、Apache Dorisアーキテクチャは3つの層で構成されます:
- メタデータ層: 新しいMeta Serviceモジュールが導入され、データベースとテーブル情報、スキーマ、rowsetメタ、トランザクションなどのメタデータサービスを提供します。Meta Serviceはステートレスで水平スケール可能です。V3.0では、BEのメタデータのすべてとFEのメタデータの一部がMeta Serviceに移行されました。残りの移行は将来のバージョンで完了予定です。
- コンピューティング層: ステートレスBEノードがクエリプランを実行し、クエリパフォーマンスを向上させるためにデータとタブレットメタデータの一部をローカルにキャッシュします。複数のステートレスBEノードをコンピューティングリソースプール(すなわち、コンピュートクラスター)に編成でき、複数のコンピュートクラスターが同じデータとメタデータサービスを共有できます。コンピュートクラスターは必要に応じてノードを追加または削除することでエラスティックにスケールできます。
- 共有ストレージ層: データは共有ストレージ層に永続化され、現在HDFSおよびS3、OSS、GCS、Azure Blob、COS、BOS、MinIOなどのS3プロトコルと互換性のある様々なクラウドベースオブジェクトストレージシステムをサポートしています。
1-2 設計のハイライト
Apache Dorisのコンピュート・ストレージ分離モードの設計は、FEのインメモリメタデータモデルを共有メタデータサービスに変換することをハイライトします。このアプローチはグローバルに一貫した状態ビューを提供し、任意のノードがFEを経由してパブリッシュする必要なく、直接書き込みを送信できるようにします。書き込み操作中、データは共有ストレージに保存され、メタデータはメタデータサービスによって管理されます。これにより共有ストレージの小ファイル数を効果的に制御します。同時に、個別テーブルのリアルタイム書き込みパフォーマンスは、コンピュート・ストレージ結合モードとほぼ同等です。システム全体の書き込み容量は、もはや単一FEノードの処理能力に制限されません。
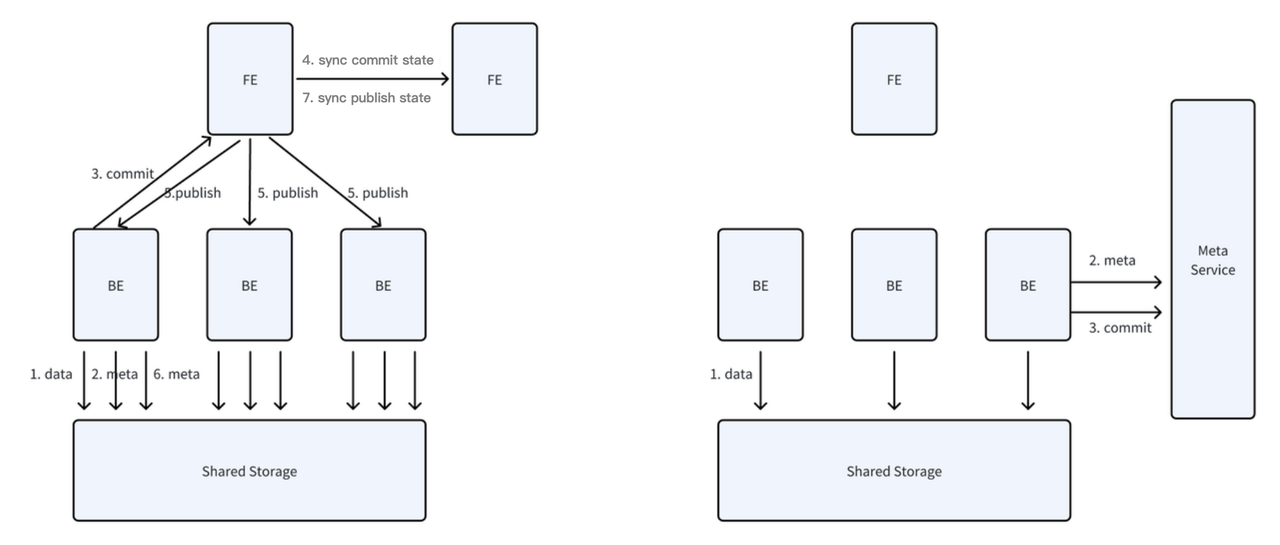
グローバルに一貫した状態ビューに基づいて、データガベージコレクションについては、より正確性を証明しやすく、より効率的なデータ削除の設計アプローチを採用しました。
具体的には、共有ストレージ内のデータは、共有メタデータサービスが提供するグローバルに一貫したビューに組み込まれます。データが生成されるたびに、それを独立した別のトランザクションにバインドします。同様に、メタデータ削除操作についても、それを独立した別のトランザクションにバインドします。このアプローチの目的は、削除と書き込み操作が一緒に成功できないことを確保することです。ビューはどのデータを削除する必要があるかを記録し、非同期削除プロセスはトランザクションレコードに基づいて単純にデータの前方削除を実行でき、逆ガベージコレクションの必要がありません。
FEのタブレット関連メタデータが徐々に共有メタデータサービスに移行されるにつれて、Dorisクラスターのスケーラビリティは単一FEノードのメモリ容量に制約されなくなります。共有メタデータサービスと前方データ削除技術に基づいて、データ共有や軽量クローニングなどの機能を便利に拡張できます。
1-3 代替ソリューションとの比較
業界におけるコンピュートとストレージの分離の別の設計は、データとBEノードメタデータを共有オブジェクトストレージやHDFSに保存することです。しかし、このアプローチは以下の問題をもたらします:
-
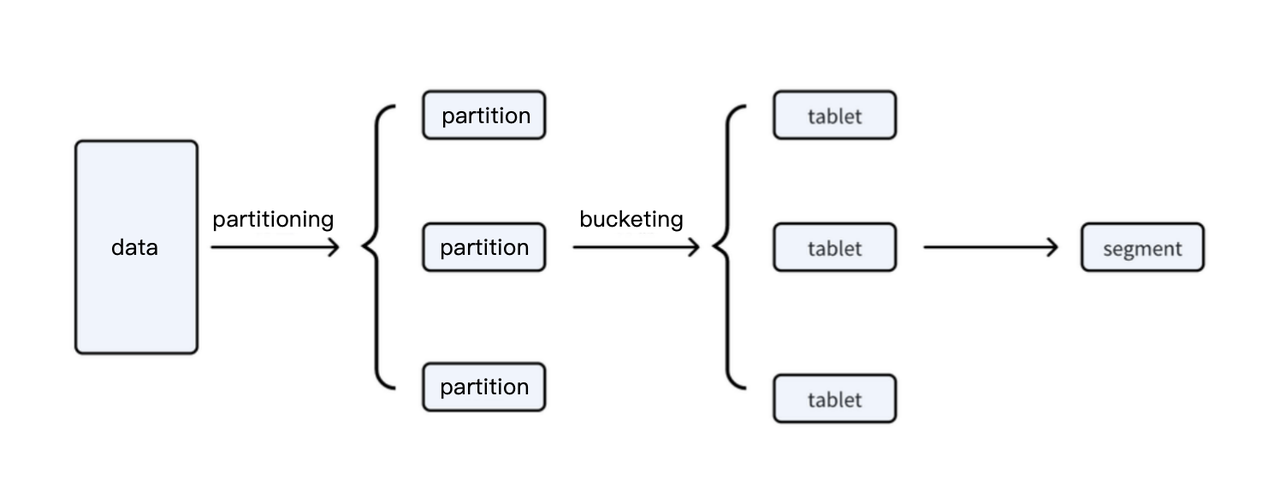
リアルタイム書き込みをサポートできない: データ書き込み時、データはパーティショニングとバケッティングルールに基づいてタブレットにマッピングされ、セグメントファイルとrowsetメタデータを生成します。書き込みプロセス中、FEを通じて2フェーズコミット(Publish)が実行されます。BEノードがPublishリクエストを受信すると、rowsetを可視に設定します。Publish操作は失敗してはいけません。rowsetメタデータが共有ストレージに保存される場合、リアルタイム書き込みプロセス中の小ファイルデータの合計は実際のデータファイルサイズの3倍になります - データファイルの1つのレプリカ、rowsetメタデータの1つ、Publish中のrowsetメタデータ変更のもう1つ。Publish操作は単一のFEノードによって駆動されるため、単一テーブルまたはシステム全体の書き込み容量はFEノードの能力に制限されます。
Apache Doris 3.0のリアルタイムデータ書き込みパフォーマンスを上記のソリューションと比較しました。同じコンピューティングリソースを使用して、それぞれ500行の10,000データファイルを書き込む500の並行タスクと、それぞれ20,000行の250データファイルを書き込む50の並行タスクをシミュレートしました。
結果は、50の並行タスクにおいて、Apache Dorisのコンピュート・ストレージ結合モードと分離モードの両方のマイクロバッチ書き込みパフォーマンスがほぼ同じであったことを示しましたが、業界ソリューションはApache Dorisより100倍遅れていました。
500の並行タスクにおいて、コンピュート・ストレージ分離モードのApache Dorisのパフォーマンスはわずかな劣化を示しましたが、依然として業界ソリューションより11倍の優位性を維持しました。公正なテストを確保するため、Apache DorisはGroup Commit機能を有効にしませんでした(業界ソリューションにはこの機能がありません)。Group Commitを有効にすると、リアルタイム書き込みパフォーマンスがさらに向上します。
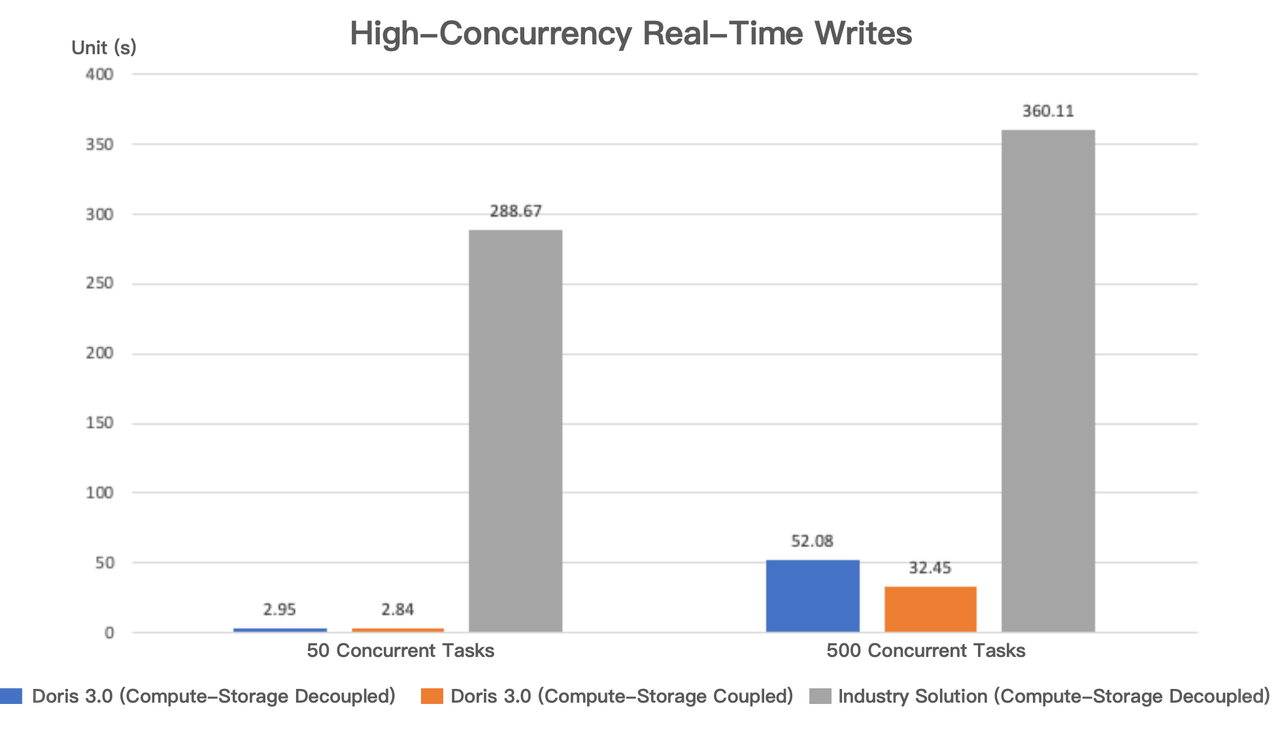
さらに、業界ソリューションはリアルタイムデータ取り込みの面で安定性とコストの問題にも直面しています:
-
安定性の懸念: 大量の小ファイルは共有ストレージ、特にHDFSに圧力をかけ、安定性リスクを導入する可能性があります。
-
高いオブジェクトストレージリクエストコスト: 一部のパブリッククラウドオブジェクトストレージサービスでは、PutとDelete操作の料金がGet操作の10倍になります。大量の小ファイルはオブジェクトストレージリクエストコストの大幅な増加を招き、ストレージコストを上回る場合もあります。
-
-
制限されたスケーラビリティ: コンピュート・ストレージ分離モデルのユースケースでは、FE(Frontend)メタデータが完全にインメモリであるため、より大きなデータストレージサイズを処理することが多く、タブレット数が一定の高いレベル(例:数千万)に達すると、FEのメモリ圧迫がシステムの全体的な書き込みスループットを制限するボトルネックになる可能性があります。
-
潜在的なデータ削除ロジックの問題: コンピュート・ストレージ分離アーキテクチャでは、データは単一レプリカで保存されます。したがって、データ削除ロジックはシステムの信頼性にとって重要です。差分を比較することによるシステム間データ削除の従来のアプローチは困難になる可能性があります。書き込みプロセス中、削除と書き込みが一緒に成功することを完全に避ける方法はなく、データ損失につながる可能性があります。さらに、ストレージシステムに異常が発生した場合、差分計算に使用される入力が不正確になる可能性があり、意図しないデータ削除につながる可能性があります。
-
データ共有と軽量クローニング: 分離ストレージ・コンピュートアーキテクチャの柔軟性により、将来のデータ共有と軽量データクローニングが可能になり、企業データ管理の負担を軽減できます。しかし、各クラスターが個別のFEを持つ場合、クラスター間でデータをクローニングした後、どのデータがもはや参照されておらず安全に削除できるかを正確に判断することが困難になります。クラスター間参照の計算は意図しないデータ削除を容易に招く可能性があるからです。
FEの完全インメモリメタデータモデルを共有メタデータサービスに進化させることで、Apache Doris 3.0は上記のすべての問題を回避します。
1-4 クエリパフォーマンスの比較
コンピュート・ストレージ分離モードでは、リモート共有ストレージシステムからデータを読み取る必要があり、主なボトルネックはコンピュート・ストレージ結合モードのディスクI/Oではなく、ネットワーク帯域幅になりました。
データアクセスを高速化するため、Apache Dorisはローカルディスクに基づく高速キャッシュメカニズムを実装し、LRU(Least Recently Used)とTTL(Time-To-Live)の2つのキャッシュ管理ポリシーを提供します。新しくインポートされたデータは非同期でキャッシュに書き込まれ、最新データへの初回アクセスを高速化します。クエリに必要なデータがキャッシュにない場合、システムはリモートストレージからメモリにデータを読み取り、後続のクエリのために同期的にキャッシュに書き込みます。
複数のコンピュートクラスターを含むユースケースでは、Apache Dorisはキャッシュ事前加熱機能を提供します。新しいコンピュートクラスターが確立されると、ユーザーは特定のデータ(テーブルやパーティションなど)を事前加熱してクエリ効率をさらに向上させることを選択できます。
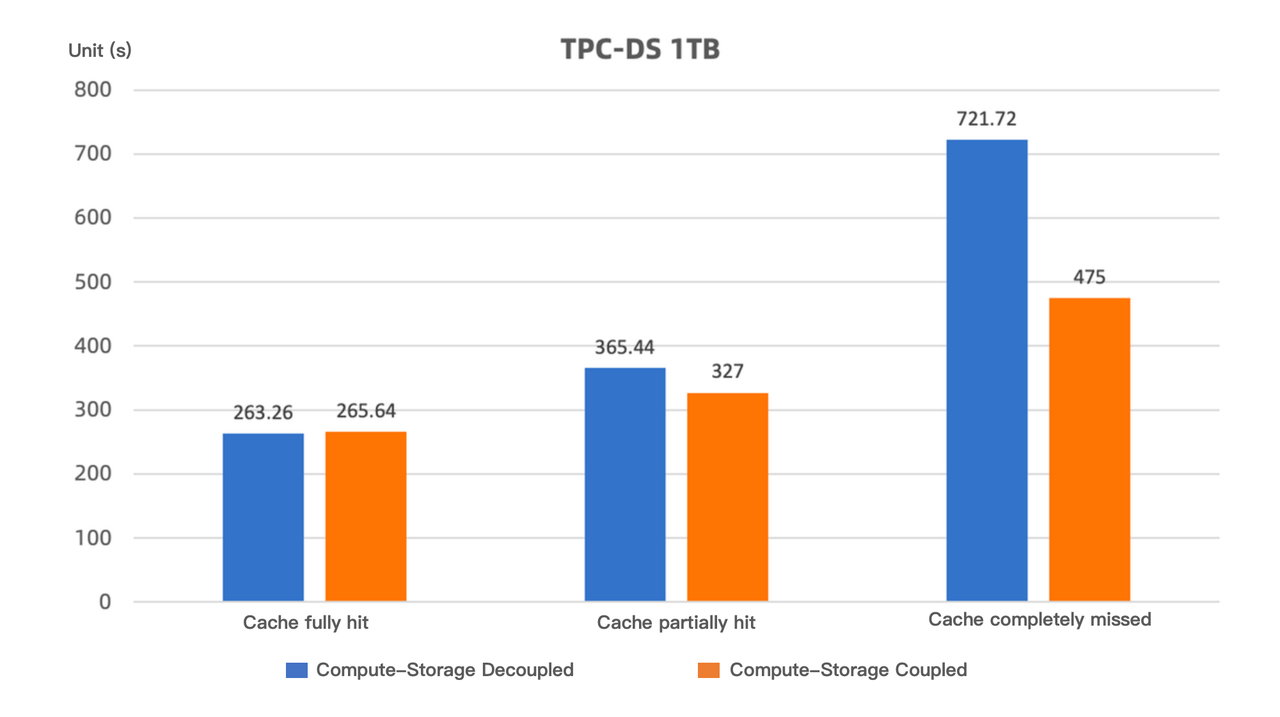
この文脈で、TPC-DS 1TBテストデータセットを使用して、コンピュート・ストレージ結合モードと分離モードの両方で異なるキャッシュ戦略によるパフォーマンステストを実施しました。結果は以下のとおりです:
-
キャッシュが完全にヒットする場合(すなわち、クエリに必要なすべてのデータがキャッシュにロードされる)、コンピュート・ストレージ分離モードのクエリパフォーマンスはコンピュート・ストレージ結合モードと同等です。
-
キャッシュが部分的にヒットする場合(すなわち、テスト前にキャッシュがクリアされ、テスト中にデータが徐々にキャッシュにロードされ、パフォーマンスが継続的に向上する)、コンピュート・ストレージ分離モードのクエリパフォーマンスはコンピュート・ストレージ結合モードより約10%低くなります。このテストシナリオは実際のユースケースに最も似ています。
-
キャッシュが完全にミスする場合(すなわち、SQL実行前にキャッシュがクリアされ、極端なケースをシミュレート)、パフォーマンス損失は約35%です。それでも、コンピュート・ストレージ分離モードのApache Dorisは代替ソリューションよりもはるかに高いパフォーマンスを提供します。
1-5 書き込み速度の比較
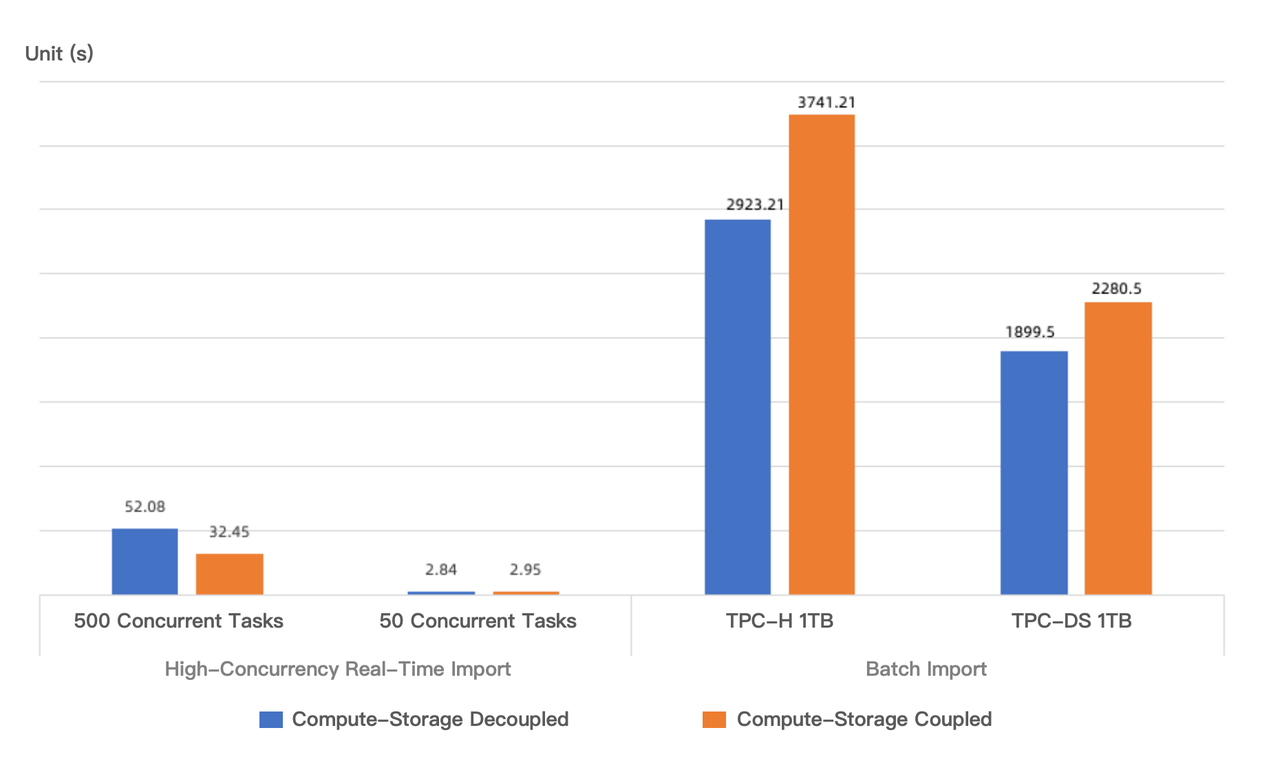
書き込みパフォーマンスの面では、同じコンピューティングリソース下で2つのテストケース:バッチインポートと高並行リアルタイムインポートをシミュレートしました。コンピュート・ストレージ結合モードとコンピュート・ストレージ分離モードの書き込みパフォーマンス比較は以下のとおりです:
-
バッチインポート: 1TB TPC-Hと1TB TPC-DSテストデータセットをインポートする際、コンピュート・ストレージ分離モードの書き込みパフォーマンスは、単一レプリカ構成下でコンピュート・ストレージ結合モードよりそれぞれ20.05%と27.98%高くなりました。バッチインポート中、セグメントファイルサイズは一般的に数十から数百MBの範囲です。コンピュート・ストレージ分離モードでは、セグメントファイルがより小さなファイルに分割され、オブジェクトストレージに並行アップロードされるため、ローカルディスクへの書き込みと比較してより高いスループットを実現できます。実際の展開では、コンピュート・ストレージ結合モードは通常3つのレプリカを使用するため、コンピュート・ストレージ分離モードの書き込み速度の優位性はさらに顕著になります。
-
高並行リアルタイムインポート: 「代替ソリューションとの比較」セクションで説明されています。
1-6 本番環境での使用のヒント
-
パフォーマンス: リアルタイムデータ分析では、ユーザーはキャッシュにTTL(Time-To-Live)を指定し、新しく取り込まれたデータをキャッシュに書き込むことで、コンピュート・ストレージ結合モードに匹敵するクエリパフォーマンスを実現できます。クエリのばらつきを防ぐため、ユーザーはデータの使用頻度に基づいて、コンパクションやスキーマ変更などのバックグラウンドタスクで生成されたデータをキャッシュできます。
-
ワークロード分離: ユーザーは複数のコンピュートクラスターを使用して、異なるビジネスの物理リソース分離を実現できます。単一のコンピュートクラスター内でのワークロード分離については、ユーザーはWorkload Groupメカニズムを利用して異なるクエリのリソースを制限・分離できます。
1-7 注意事項
-
Apache Doris 3.0は、コンピュート・ストレージ結合モードとコンピュート・ストレージ分離モードの共存をサポートしません。ユーザーはクラスター展開時にいずれかを指定する必要があります。
-
ユーザーがコンピュート・ストレージ結合モードを必要とする場合は、その展開とアップグレードのdocumentationに従ってください。迅速な展開とクラスターアップグレードにはDoris Managerの使用を推奨します。ただし、コンピュート・ストレージ分離モードはまだDoris Managerの展開とアップグレードをサポートしていません。将来のバージョンでより良いサポートのために継続的に改善を行います。
-
現在、Apache DorisはV2.1からV3.0のコンピュート・ストレージ分離モードへのインプレースアップグレードをサポートしていません。この目的のためには、ユーザーはコンピュート・ストレージ分離クラスターを展開した後にデータ移行を実行する必要があります。将来的には、CCR(Change Data Capture)機能を通じてサービス中断なしでの移行をサポートする予定です。
2. データレイクハウス
Apache Dorisはリアルタイムデータウェアハウスとして位置づけられていますが、それ以上の存在です。以前のバージョンでは、従来のデータウェアハウス機能の境界を一貫して押し広げ、統合データレイクハウスに向けて前進してきました。バージョン3.0はこの旅路のマイルストーンとなり、レイクハウスアーキテクチャでの機能が完全に成熟しました。統合レイクハウスは境界のないデータとレイクハウス融合によって識別されると考えています:
境界のないデータ: Apache Dorisは統合クエリ処理エンジンとして機能し、異なるシステム間のデータ障壁を打破します。データウェアハウス、データレイク、データストリーム、ローカルデータファイルを含むすべてのデータソースにわたって一貫した超高速分析体験を提供します。
-
レイクハウスクエリ高速化: データをApache Dorisに移行する必要なく、ユーザーはDorisの効率的なクエリエンジンを活用して、Iceberg、Hudi、PaimonなどのデータレイクやHiveなどのオフラインデータウェアハウスに保存されたデータを直接クエリし、クエリ分析を高速化できます。
-
統合分析: カタログとストレージプラグインを拡張することで、Apache Dorisは統合分析機能を強化し、ユーザーが単一のストレージシステムにデータを物理的に集中化することなく、複数の異種データソースにわたって統合分析を実行できるようにします。これにより外部テーブルクエリと内部・外部テーブル間の統合結合が可能になり、データサイロを打破してグローバルに一貫したデータインサイトを提供します。
-
データレイク構築: Apache DorisはHiveとIcebergの書き戻し機能を導入し、ユーザーがDorisを通じて直接HiveとIcebergテーブルを作成し、データを書
BEGIN;
DELETE FROM table WHERE date >= "2024-07-01" AND date <= "2024-07-31";
INSERT INTO table SELECT * FROM stage_table;
COMMIT; -
失敗したタスクの処理を簡素化: 例えば、単一のトランザクション内で2つの
insert into select操作が実行される際、いずれかの操作が失敗した場合、直接再試行することができます。BEGIN WITH LABEL label_etl_1;
INSERT INTO table1 SELECT * FROM stage_table1;
INSERT INTO table SELECT * FROM stage_table;
COMMIT;
参照ドキュメント: https://doris.apache.org/docs/3.0/data-operate/transaction/ 現在、Cross-Cluster Replication(CCR)では明示的なトランザクション同期はサポートされていません。
4-2. 可観測性の向上
-
リアルタイムプロファイル取得: 以前のバージョンでは、実行プランやデータの問題により、一部の複雑なクエリは高い計算要件を持つ可能性があるため、開発者はクエリ完了後にのみパフォーマンス分析のためのクエリプロファイルにアクセスできました。これにより、クエリ実行における問題を迅速に特定して本番環境の安定性を保証することが困難でした。リアルタイムプロファイルの取得機能により、V3.0ではユーザーはクエリ実行中にクエリ実行を監視できるようになります。また、各ETLジョブの進行状況をより適切に監視できるようになります。
-
backend_active_tasksシステムテーブル:backend_active_tasksシステムテーブルは、各BEノードの各クエリのリアルタイムリソース消費情報を提供します。ユーザーはSQLを使用してこのシステムテーブルを分析し、各クエリのリソース使用量を取得できるため、大規模なクエリや異常なワークロードの特定に役立ちます。
5. 非同期マテリアライズドビュー
V3.0では、非同期マテリアライズドビューはより高速で安定しています。また、クエリ高速化とデータモデリングシナリオにおいてよりユーザーフレンドリーです。透明なリライトのロジックを再構築し、その機能を拡張して2倍高速化しました。
5-1 更新
-
パーティションによるマテリアライズドビューの増分更新およびマテリアライズドビューのパーティションロールアップのサポートにより、異なる粒度での更新が可能。
-
ネストしたマテリアライズドビューのサポート。データモデリングシナリオで有用。
-
非同期マテリアライズドビューでのインデックス作成とソートキー指定のサポート。マテリアライズドビューがヒットした後のクエリパフォーマンスを向上。
-
マテリアライズドビューのアトミック置換をサポートするマテリアライズドビューDDLの高い使いやすさ。マテリアライズドビューを利用可能な状態に保ちながら、マテリアライズドビュー定義SQLの変更が可能。
-
マテリアライズドビューでの非決定的関数のサポート。日常的なマテリアライズドビュー作成により適切に対応。
-
トリガーベースのマテリアライズドビュー更新のサポート。ネストしたマテリアライズドビューを使用したデータモデリングでデータ整合性を確保。
-
パーティション化されたマテリアライズドビューを構築するためのより幅広いSQLパターンのサポート。より多くのユースケースで増分更新機能を利用可能。
5-2 更新安定性
- V3.0では、マテリアライズドビューの構築にWorkload Groupを指定することをサポート。マテリアライズドビュー構築プロセスで使用されるリソースを制限し、継続的なクエリに十分なリソースが利用可能であることを保証。
5-3 透明なリライト
-
派生Joinを含む、より多くのJoinタイプの透明なリライトをサポート。クエリとマテリアライズドビュー間でJoinタイプが一致しない場合でも、マテリアライズドビューがクエリに必要なすべてのデータを提供できる限り、追加の述語で補完することで透明なリライトを実行可能。
-
ロールアップのためのより多くの集約関数およびGROUPING SETS、ROLLUP、CUBEなどの多次元集約のリライトをサポート。マテリアライズドビューが集約を含まない場合の集約を含むクエリのリライトをサポートし、Join操作と式計算を簡素化。
-
ネストしたマテリアライズドビューの透明なリライトをサポートし、複雑なクエリでより高いパフォーマンスを実現。
-
部分的に無効なパーティション化されたマテリアライズドビューの場合、V3.0はデータ補完のためのベーステーブルの
Union Allをサポートし、パーティション化されたマテリアライズドビューの適用性を拡大。
5-4 透明なリライトパフォーマンス
- 透明なリライトパフォーマンスを向上させるための継続的な最適化を実施し、バージョン2.1.0と比較して2倍の速度を達成。
6. パフォーマンス向上
6-1 よりスマートなオプティマイザー
V3.0では、クエリオプティマイザーはフレームワーク機能、分散プランサポート、オプティマイザーインフラストラクチャ、ルール拡張の面で強化されています。より複雑で多様なビジネスシナリオに対してより優れた最適化機能を提供し、複雑なSQLでより高いブラインドテストパフォーマンスを実現します:
-
プラン列挙機能の向上: プラン列挙の主要構造Memoが再構築され、正規化されました。これにより、Cascadesフレームワークのプラン列挙効率とより良いプランの生成可能性が向上します。さらに、古いバージョンでのJoin Reorderプロセス中の不完全な列プルーニングを修正し、Join演算子の不要なオーバーヘッドを招いていた問題を解決することで、関連シナリオでの実行パフォーマンスを向上させます。
-
分散プランサポートの向上: 分散クエリプランが強化され、集約、join、ウィンドウ関数操作が中間計算結果のデータ特性をより賢く識別し、効果のないデータ再分散操作を回避できるようになりました。同時に、マルチレプリカ連続実行モード下での実行を最適化し、よりデータキャッシュフレンドリーにしました。
-
オプティマイザーインフラストラクチャの向上: V3では、コストモデルと統計情報推定におけるいくつかの問題を修正しました。コストモデルの修正は実行エンジンの進化により適応性があり、以前のバージョンと比較して実行プランをより安定させます。
-
Runtime Filterプランサポートの強化: Join Runtime Filterを基盤として、V3.0ではTopN Runtime Filterの機能を拡張し、TopN演算子を含むユースケースでより良いパフォーマンスを実現しました。
-
最適化ルールライブラリの充実: ユーザーフィードバックと内部テスト結果に基づき、Intersect Reorderなどの最適化ルールを導入してオプティマイザーのルールセットを充実させました。
6-2 自己適応Runtime Filter
以前のバージョンでは、Runtime Filterの生成は統計情報に基づくユーザーの手動設定に依存していました。しかし、特定のケースでの不正確な設定はパフォーマンス不安定性を引き起こす可能性がありました。
V3.0では、Dorisは自己適応Runtime Filter計算アプローチを実装しています。データサイズに基づいて実行時にRuntime Filterを高精度で推定でき、大容量データと高ワークロードのユースケースでより良いパフォーマンスを実現します。
6-3 関数パフォーマンス最適化
- V3.0では数十の関数のベクトル化実装を改善し、一般的に使用される一部の関数で50%以上のパフォーマンス向上を実現しました。
- V3.0ではnullableデータ型の集約に対して広範な最適化を行い、30%のパフォーマンス向上を実現しました。
6-4 ブラインドテストパフォーマンス向上
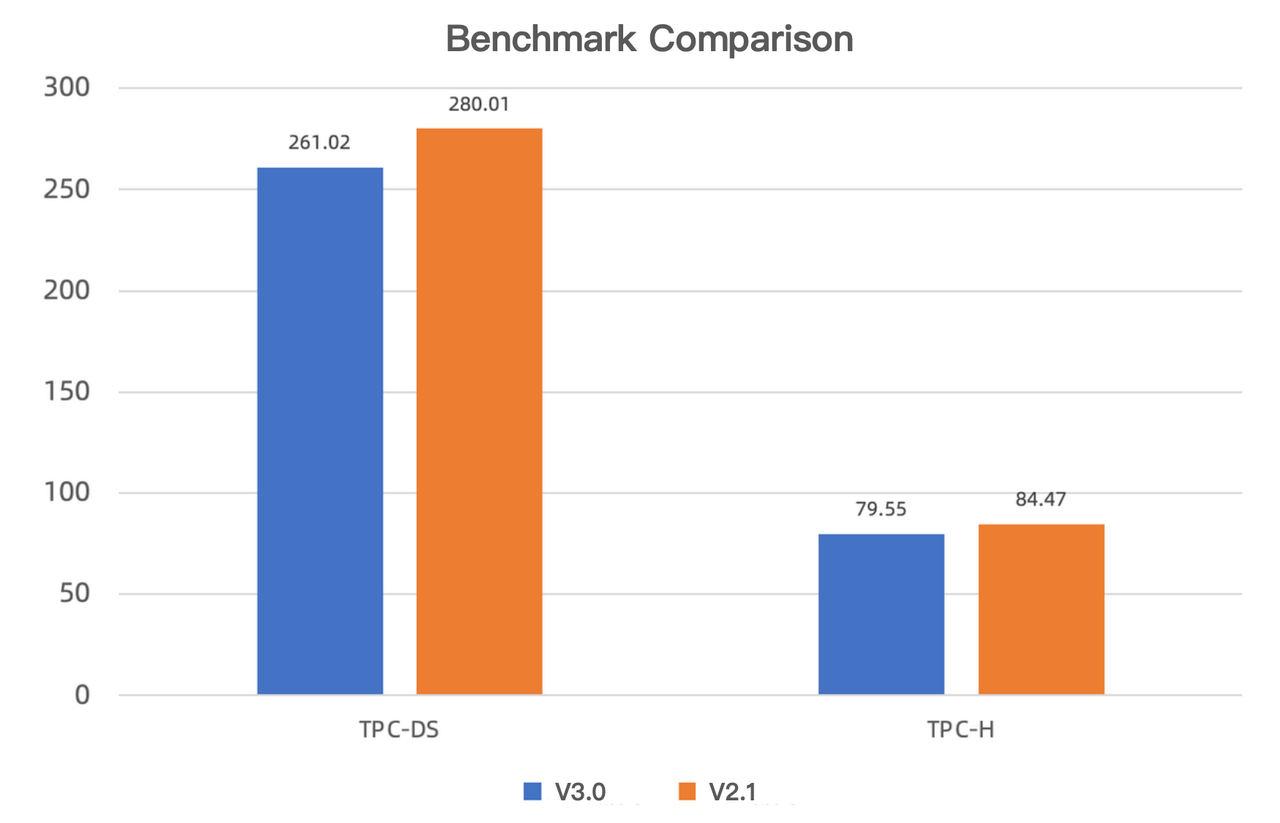
V3.0とV2.1のブラインドテストでは、新バージョンがTPC-DSとTPC-Hベンチマークテストでそれぞれ7.3%と6.2%高速であることが示されました。
7. 新機能
7-1 Java UDTF
バージョン3.0ではJava UDTFのサポートが追加されました。主要な操作は以下の通りです:
-
UDTFの実装: UDFと同様に、UDTFではユーザーが
evaluateメソッドを実装する必要があります。UDTF関数の戻り値はArrayデータ型である必要があることに注意してください。public class UDTFStringTest {
public ArrayList<String> evaluate(String value, String separator) {
if (value == null || separator == null) {
return null;
} else {
return new ArrayList<>(Arrays.asList(value.split(separator)));
}
}
} -
UDTFの作成: デフォルトでは、対応する2つの関数が作成されます -
java-utdfとjava-utdf_outerです。_outerサフィックスは、テーブル関数が0行の出力を生成する際に、NULLデータの単一行を追加します。CREATE TABLES FUNCTION java-utdf(string, string) RETURNS array<string> PROPERTIES (
"file"="file:///pathTo/java-udaf.jar",
"symbol"="org.apache.doris.udf.demo.UDTFStringTest",
"always_nullable"="true",
"type"="JAVA_UDF"
);
7-2 Generated column
Generated columnは、ユーザーが直接挿入や更新を行うのではなく、他のカラムの値から計算される特別なカラムです。式の結果を事前計算してデータベースに保存することをサポートし、頻繁なクエリや複雑な計算が必要なシナリオに適しています。
データのインポートや更新時に事前定義された式に基づいて結果を自動計算し、永続的に保存できます。これにより、その後のクエリでは、システムは複雑な計算を実行することなく、これらの計算結果に直接アクセスでき、クエリパフォーマンスを向上させます。
Generated columnはV3.0からサポートされています。テーブル作成時に、カラムをgenerated columnとして指定できます。Generated columnは、データ書き込み時に定義された式に基づいて値を自動計算します。Generated columnではより複雑な式を定義できますが、値を明示的に書き込んだり設定したりすることはできません。
8. 機能改善
8-1. Materialized view
マテリアライズドビューの選択ロジックをリファクタリングし、ルールベースオプティマイザー(RBO)からコストベースオプティマイザー(CBO)に移行しました。これにより、選択ロジックが非同期マテリアライズドビューのロジックと統一されました。この機能はデフォルトで有効になっています。何らかの問題が発生した場合は、set global enable_sync_mv_cost_based_rewrite = falseを使用してRBOモードに戻すことができます。
8-2. Routine Load
以前のバージョンでは、Routine Load機能にはいくつかのユーザビリティの課題がありました。例えば、BEノード間でのタスクスケジューリングの不均衡、タスクスケジューリングの遅延、複雑な設定要件(最適化のために複数のFEおよびBE設定を変更する必要性)、全体的な安定性の不足(再起動やアップグレードによってRoutine Loadジョブが頻繁に停止し、再開するためにユーザーの手動介入が必要)などです。
これらの問題に対処するため、Routine Load機能に対して広範囲にわたる最適化を行いました:
-
リソーススケジューリング: スケジューリングバランスを改善し、タスクがBEノード間でより均等に分散されるようにしました。修復不可能なエラーが発生したジョブは、無駄なスケジューリング試行でリソースを浪費することを避けるために迅速に停止されます。また、スケジューリングプロセスの適時性を改善し、Routine Loadのインポートパフォーマンスを向上させました。
-
パラメータ設定: ほとんどの環境のユーザーは、最適化のためにFEやBE設定を変更する必要がなくなりました。クラスター負荷が増加した際にタスクが絶えず再試行することを防ぐため、タイムアウトパラメータを持つ自動調整メカニズムを導入しました。
-
安定性: FEフェイルオーバー、BEローリングアップグレード、Kafkaクラスター異常など、さまざまな例外的なシナリオにおけるDorisの堅牢性を強化し、継続的で安定した動作を確保しました。また、Auto Resumeメカニズムを最適化し、障害が修復された後にRoutine Loadが自動的に動作を再開できるようにし、手動のユーザー介入の必要性を削減しました。
9. 動作変更
-
cpu_resource_limitはサポートされなくなり、すべてのタイプのリソース分離はWorkload Groupsを通じて実装されます。 -
Apache Doris 3.0以降のバージョンではJDK 17を使用してください。推奨バージョンは
jdk-17.0.10_linux-x64_bin.tar.gzです。
Apache Doris 3.0を今すぐお試しください!
バージョン3.0の正式リリース前に、Apache Dorisのコンピュート・ストレージ分離モードは、数百の企業の本番環境で約2年間にわたる広範囲なテストと最適化を経ています。多くのテック企業の貢献者がコミュニティと協力し、実際のビジネスニーズに基づいた大量のテストケースを提供しました。これによりバージョン3.0のユーザビリティと安定性が厳格に検証されました。
コンピュート・ストレージ分離のニーズを持つユーザーには、バージョン3.0をダウンロードして直接体験することを強く推奨します。
今後、リリースイテレーションサイクルを加速し、すべてのユーザーにより安定したバージョン体験を提供していきます。Apache Dorisコミュニティにぜひご参加いただき、コア開発者と直接交流してください。
Credits
このバージョンの開発、テスト、フィードバックの提供に参加してくださった以下の貢献者の皆様に特別な感謝を申し上げます:
@133tosakarin、@390008457、@924060929、@AcKing-Sam、@AshinGau、@BePPPower、@BiteTheDDDDt、@ByteYue、@CSTGluigi、@CalvinKirs、@Ceng23333、@DarvenDuan、@DongLiang-0、@Doris-Extras、@Dragonliu2018、@Emor-nj、@FreeOnePlus、@Gabriel39、@GoGoWen、@HappenLee、@HowardQin、@Hyman-zhao、@INNOCENT-BOY、@JNSimba、@JackDrogon、@Jibing-Li、@KassieZ、@Lchangliang、@LemonLiTree、@LiBinfeng-01、@LompleZ、@M1saka2003、@Mryange、@Nitin-Kashyap、@On-Work-Song、@SWJTU-ZhangLei、@StarryVerse、@TangSiyang2001、@Tech-Circle-48、@Thearas、@Vallishp、@WinkerDu、@XieJiann、@XuJianxu、@XuPengfei-1020、@Yukang-Lian、@Yulei-Yang、@Z-SWEI、@ZhongJinHacker、@adonis0147、@airborne12、@allenhooo、@amorynan、@bingquanzhao、@biohazard4321、@bobhan1、@caiconghui、@cambyzju、@caoliang-web、@catpineapple、@cjj2010、@csun5285、@dataroaring、@deardeng、@dongsilun、@dutyu、@echo-hhj、@eldenmoon、@elvestar、@englefly、@feelshana、@feifeifeimoon、@feiniaofeiafei、@felixwluo、@freemandealer、@gavinchou、@ghkang98、@gnehil、@hechao-ustc、@hello-stephen、@httpshirley、@hubgeter、@hust-hhb、@iszhangpch、@iwanttobepowerful、@ixzc、@jacktengg、@jackwener、@jeffreys-cat、@kaijchen、@kaka11chen、@kindred77、@koarz、@kobe6th、@kylinmac、@larshelge、@liaoxin01、@lide-reed、@liugddx、@liujiwen-up、@liutang123、@lsy3993、@luwei16、@luzhijing、@lxliyou001、@mongo360、@morningman、@morrySnow、@mrhhsg、@my-vegetable-has-exploded、@mymeiyi、@nanfeng1999、@nextdreamblue、@pingchunzhang、@platoneko、@py023、@qidaye、@qzsee、@raboof、@rohitrs1983、@rotkang、@ryanzryu、@seawinde、@shoothzj、@shuke987、@sjyango、@smallhibiscus、@sollhui、@sollhui、@spaces-X、@stalary、@starocean999、@superdiaodiao、@suxiaogang223、@taptao、@vhwzx、@vinlee19、@w41ter、@wangbo、@wangshuo128、@whutpencil、@wsjz、@wuwenchi、@wyxxxcat、@xiaokang、@xiedeyantu、@xiedeyantu、@xingyingone、@xinyiZzz、@xy720、@xzj7019、@yagagagaga、@yiguolei、@yongjinhou、@ytwp、@yuanyuan8983、@yujun777、@yuxuan-luo、@zclllyybb、@zddr、@zfr9527、@zgxme、@zhangbutao、@zhangstar333、@zhannngchen、@zhiqiang-hhhh、@ziyanTOP、@zxealous、@zy-kkk、@zzzxl1993、@zzzzzzzs