
Apache Doris 4.0: 分析、全文検索、ベクター検索のためのワンエンジン
Apache Doris 4.0の正式リリースを発表できることを嬉しく思います。これは4つの主要な領域の改善に焦点を当てた重要なマイルストーンリリースです:1) 新しいAI機能であるベクター検索とAI関数、2) より強力な全文検索、3) より良いETL/ELT処理、4) TopN遅延マテリアル化とSQLキャッシュによるパフォーマンス最適化。
Apache Doris 4.0の主なハイライト:
- ベクター検索、AI関数、ハイブリッド検索によるAI対応:
- ベクター検索: Doris 4.0はvector indexingを導入してベクター検索をサポートします。これにより、ユーザーは外部のベクターデータベースを必要とすることなく、Apache Doris内でベクター検索と通常のSQL分析の両方を直接実行できます。
- AI関数: これらの関数により、データアナリストはSQL経由で大規模言語モデルを直接呼び出し、Doris内で情報抽出、感情分析、テキスト要約などのタスクを実行できます。接続コードが少なく、よりクリーンなパイプラインを実現します。
- Hybrid Search and Analytics Processing (HSAP): Doris 4.0は、ベクター検索、全文検索、構造化分析をすべて1つのエンジンに統合します。この統一されたアプローチにより、精密なキーワード検索、セマンティックマッチング、複雑な分析クエリを、外部システムやデータの重複なしに、単一のSQLワークフロー内でシームレスに実行できます。
- より良い全文検索:全く新しいSEARCH()関数により、Elasticsearch Query Stringに類似した軽量なDSL構文が導入され、より高速で柔軟で使いやすいテキスト検索を提供します。
- より強力なETL/ELT:Doris 4.0は、重いETL/ELT処理とマルチテーブル具体化ビューを改善する新しいSpill Disk機能を導入します。この機能は、メモリ制限を超えた際に中間データを自動的にディスクに書き込み、大規模ETLタスクの安定性と耐障害性を向上させます。
- パフォーマンス最適化: Doris 4.0は、TopN遅延マテリアル化とSQLキャッシュ改善により大幅なパフォーマンス向上を実現します。TopNクエリは、特定の幅広テーブルシナリオにおいて数十倍高速に実行されるようになりました。また、デフォルトで有効化されたSQLキャッシュも改善し、SQL解析効率を100倍向上させました。
このリリースは200名を超えるコミュニティメンバーによるチームの成果であり、9,000を超える改善と修正が提出されました。このマイルストーンバージョンのテスト、レビュー、改良にご協力いただいたすべての方々に感謝いたします。
- GitHub: https://github.com/apache/doris/releases
- Download Doris 4.0: https://doris.apache.org/download
1. AI機能:ベクター検索とAI関数
A. ベクター検索のためのベクターインデックス
Doris 4.0は、ベクター検索を改善するためにvector indexingを導入します。4.0により、ユーザーはDorisのネイティブSQL分析と併せてvector indexを使用し、Doris内で構造化クエリとベクター類似検索の両方を実行できるようになりました。これにより、セマンティック検索、スマートレコメンデーション、画像検索などのAIワークロードのアーキテクチャが大幅に簡素化されます。
ベクターインデックス検索関数
l2_distance_approximate():HNSWインデックスを使用して、ユークリッド距離(L2)に基づく類似性計算を近似します。値が小さいほど類似性が高くなります。inner_product_approximate():HNSWインデックスを使用して、内積に基づく類似性計算を近似します。値が大きいほど類似性が高くなります。
例
-- 1) create table
CREATE TABLE doc_store (
id BIGINT,
title STRING,
tags ARRAY<STRING>,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_vec (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768",
"quantizer" = "flat" -- options:flat / sq8 / sq4
),
INDEX idx_title (title) USING INVERTED PROPERTIES ("parser" = "english")
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 16
PROPERTIES("replication_num"="1");
-- 2) TopN
SELECT id, l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
ORDER BY dist ASC
LIMIT 10;
-- 3) hybrid search : filter first and then topn
SELECT id, title,
l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
WHERE title MATCH_ANY 'music' -- filter using full text index
AND array_contains(tags, 'recommendation') -- filter using structured filter
ORDER BY dist ASC
LIMIT 5;
-- 4) range query
SELECT COUNT(*)
FROM doc_store
WHERE l2_distance_approximate(embedding, [...]) <= 0.35;
パラメータ
index_type: 必須。現在はhnsw(Hierarchical Navigable Small Worlds) をサポートしています。metric_type: 必須。オプションはl2_distance(ユークリッド距離) またはinner_productです。dim: 必須。インポートするベクトルの次元と厳密に一致する必要がある正の整数。max_degree: オプション。デフォルト値は32。HNSWグラフ内のノードの出次数(HNSWアルゴリズムのパラメータM)を制御します。ef_construction: オプション。デフォルト値は40。インデックス構築フェーズ中の候補キューの長さ(HNSWアルゴリズムのパラメータefConstruction)を指定します。quant: オプション。オプションはflat(デフォルト)、sq8(8ビットスカラー量子化)、またはsq4(4ビットスカラー量子化)です。量子化によりメモリ使用量が大幅に削減されます:SQ8インデックスのサイズはFLATインデックスの約1/3で、わずかな再現率の損失と引き換えに、より高いストレージ容量とより低いコストを実現します。
注意事項
- デフォルトでは、Dorisは「プレフィルタリング」メカニズムを使用します:最初に正確に位置特定可能なインデックス(例:転置インデックス)を使用して述語フィルタリングを適用し、その後残りのデータセットでANN TopN(近似最近傍)検索を実行します。これにより、結果の解釈可能性と再現率の安定性が確保されます。
- SQLクエリにセカンダリインデックスで正確に位置特定できない述語が含まれている場合(例:idカラムに転置インデックスなどのセカンダリインデックスが存在しない場合のROUND(id) > 100)、システムはプレフィルタリングのセマンティクスと正確性を保持するため、正確な総当たり検索にフォールバックします。
- ベクトルカラムは
ARRAY<FLOAT> NOT NULL型である必要があり、インポートするベクトルの次元はインデックスのdimパラメータと一致する必要があります。 - 現在、ANN検索は Duplicate Key テーブルモデルのみをサポートしています。
B. AI Functions
Doris 4.0では、一連のAI Functionsも導入されました。
データアナリストは、AI Functionsを使用して、外部ツールを必要とせず、簡単なSQLクエリで大規模言語モデルを直接呼び出すことができます。重要な情報の抽出、レビューでの感情分類、簡潔なテキスト要約の生成など、すべてのLLMとのやり取りがApache Doris内でシームレスに実行できるようになりました。
- AI_CLASSIFY: テキスト内容と最も一致度の高い単一のラベル文字列を(指定されたラベルセットから)抽出します。
- AI_EXTRACT: テキスト内容に基づいて、指定された各ラベルに関連する情報を抽出します。
- AI_FILTER: テキスト内容の正確性を判定し、
bool値(true/false)を返します。 - AI_FIXGRAMMAR: テキスト内の文法とスペルミスを修正します。
- AI_GENERATE: 入力パラメータに基づいてコンテンツを生成します。
- AI_MASK: 指定されたラベルに従って、元のテキスト内の機密情報を
[MASKED]に置き換えます(データの非機密化のため)。 - AI_SENTIMENT: テキストの感情傾向を分析し、次の値のいずれかを返します:
positive、negative、neutral、またはmixed。 - AI_SIMILARITY: 2つのテキスト間の意味的類似度を評価し、0から10の間の浮動小数点数を返します(値が高いほど意味的類似度が高いことを示します)。
- AI_SUMMARIZE: テキストの簡潔な要約を生成します。
- AI_TRANSLATE: テキストを指定された言語に翻訳します。
- AI_AGG: 複数のテキストエントリに対して行横断的な集約分析を実行します。
現在、以下のLLMをサポートしています:Local(ローカルデプロイメント)、OpenAI、Anthropic、Gemini、DeepSeek、MoonShot、MiniMax、Zhipu、Qwen、Baichuan。
AI Functions使用例
模擬的な就職面接のシナリオでAI_FILTER関数を使用した例をご確認ください。
まず、求職者の履歴書と採用の求人要件のテーブルを模擬しました:
CREATE TABLE candidate_profiles (
candidate_id INT,
name VARCHAR(50),
self_intro VARCHAR(500)
)
DUPLICATE KEY(candidate_id)
DISTRIBUTED BY HASH(candidate_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE job_requirements (
job_id INT,
title VARCHAR(100),
jd_text VARCHAR(500)
)
DUPLICATE KEY(job_id)
DISTRIBUTED BY HASH(job_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO candidate_profiles VALUES
(1, 'Alice', 'I am a senior backend engineer with 7 years of experience in Java, Spring Cloud and high-concurrency systems.'),
(2, 'Bob', 'Frontend developer focusing on React, TypeScript and performance optimization for e-commerce sites.'),
(3, 'Cathy', 'Data scientist specializing in NLP, large language models and recommendation systems.');
INSERT INTO job_requirements VALUES
(101, 'Backend Engineer', 'Looking for a senior backend engineer with deep Java expertise and experience designing distributed systems.'),
(102, 'ML Engineer', 'Seeking a data scientist or ML engineer familiar with NLP and large language models.');
AI_FILTERを使用して、求人要件と候補者のプロフィール間でセマンティックマッチングを実行し、それにより適切な候補者を絞り込むことができます:
SELECT
c.candidate_id, c.name,
j.job_id, j.title
FROM candidate_profiles AS c
JOIN job_requirements AS j
WHERE AI_FILTER(CONCAT('Does the following candidate self-introduction match the job description?',
'Job: ', j.jd_text, ' Candidate: ', c.self_intro));
+--------------+-------+--------+------------------+
| candidate_id | name | job_id | title |
+--------------+-------+--------+------------------+
| 3 | Cathy | 102 | ML Engineer |
| 1 | Alice | 101 | Backend Engineer |
+--------------+-------+--------+------------------+
2. 強化された全文検索
企業の多様な検索ニーズに応えるため、Doris 4.0では全文検索機能を大幅に改善し、より精密で柔軟な全文検索体験を提供し、ハイブリッド検索シナリオのサポートを向上させました。
A. 新しいSEARCH()関数:全文検索のための統一された軽量DSL
ハイライト
- 1つの関数で全文検索を処理: Doris 4.0では複雑なテキスト検索オペレータを統一された
SEARCH()関数に統合し、Elasticsearch Query Stringに近い構文により、SQLの連結の複雑さと移行コストを大幅に削減します。 - 複数条件インデックスプッシュダウン: 複雑な検索条件を直接転置インデックスに推下して実行し、「1回解析して1回連結する」という反復的なオーバーヘッドを回避することで、パフォーマンスを大幅に向上させます。
現在のバージョンでサポートされている構文機能
- Term Query:
field:value - ANY / ALL複数値マッチング:
field:ANY(v1 v2 ...)/field:ALL(v1 v2 ...) - Boolean組み合わせ:括弧グループ化を含む
AND/OR/NOT - 複数フィールド検索:単一の
search()関数内で複数フィールドに対するboolean組み合わせを実行
将来のバージョンでサポート予定の構文機能(継続的な反復による)
- フレーズ
- プレフィックス
- ワイルドカード
- 正規表現
- 範囲
- リスト
例
-- Term Queries
SELECT * FROM docs WHERE search('title:apache');
-- ANY: Matches any one of the specified values
SELECT * FROM docs WHERE search('tags:ANY(java python golang)');
-- ALL: Requires all specified values to be present simultaneously
SELECT * FROM docs WHERE search('tags:ALL(machine learning)');
-- Boolean logic with multiple fields
SELECT * FROM docs
WHERE search('(title:Doris OR content:database) AND NOT category:archived');
-- Combined with structured filtering (structured conditions do not affect scoring)
SELECT * FROM docs
WHERE search('title:apache') AND publish_date >= '2025-01-01';
B. テキスト検索スコアリング
ハイブリッド検索シナリオをより適切にサポートするため、Doris 4.0では業界をリードするBM25関連性スコアリングアルゴリズムを従来のTF-IDFアルゴリズムの代替として導入しています。BM25は文書の長さに基づいて用語頻度の重みを動的に調整し、特にログ解析や文書検索などの長文テキストや複数フィールド検索シナリオにおいて、結果の関連性と検索精度を大幅に向上させます。
例:
SELECT *, score() as score
FROM search_demo
WHERE content MATCH_ANY 'search query'
ORDER BY score DESC
LIMIT 10;
機能と制限事項
サポートされるインデックスタイプ
- Tokenized Index: 事前定義されたトークナイザーとカスタムトークナイザーをサポート。
- Non-Tokenized Index: トークン化を実行しないインデックス(全文インデックス)。
サポートされるテキスト検索演算子
- MATCH_ANY
- MATCH_ALL
- MATCH_PHRASE
- MATCH_PHRASE_PREFIX
- SEARCH
注意事項
- スコア範囲:BM25スコアには固定の上限または下限がありません。スコアの絶対値よりも相対的な大きさの方が意味があります。
- 空のクエリ:クエリ項目がデータセット内に存在しない場合、0のスコアが返されます。
- ドキュメント長の影響:短いドキュメントは、クエリ項目を含む場合、通常より高いスコアを受け取ります。
- クエリ項目数:複数項目クエリの場合、合計スコアは個々の項目のスコアの組み合わせ(合計)です。
C. Better Inverted Index Tokenization
Doris 3.1では基本的なトークン化機能を導入しました。これらの機能は4.0でさらに改良され、さまざまなシナリオにおける多様なトークン化とテキスト検索のニーズに対応します。
-
新しい組み込みトークナイザー
- ICU (International Components for Unicode) Tokenizer
適用可能なシナリオ:複雑な文字体系を持つ国際化されたテキスト、特に多言語混合ドキュメントに適しています。
例:
SELECT TOKENIZE('مرحبا بالعالم Hello 世界', '"parser"="icu"');
-- Result: ["مرحبا", "بالعالم", "Hello", "世界"]
SELECT TOKENIZE('มนไมเปนไปตามความตองการ', '"parser"="icu"');
-- Result: ["มน", "ไมเปน", "ไป", "ตาม", "ความ", "ตองการ"]
- Basic Tokenizer
適用シナリオ: シンプルなシナリオまたは極めて高いパフォーマンスが要求されるシナリオ。ログ処理シナリオにおいてUnicodeトークナイザーの代替として使用可能。
例:
-- English Text Tokenization
SELECT TOKENIZE('Hello World! This is a test.', '"parser"="basic"');
-- Result: ["hello", "world", "this", "is", "a", "test"]
-- Chinese Text Tokenization
SELECT TOKENIZE('你好世界', '"parser"="basic"');
-- Result: ["你", "好", "世", "界"]
-- Mixed-Language Tokenization
SELECT TOKENIZE('Hello你好World世界', '"parser"="basic"');
-- Result: ["hello", "你", "好", "world", "世", "界"]
-- Supports Numbers and Special Characters
SELECT TOKENIZE('GET /images/hm_bg.jpg HTTP/1.0', '"parser"="basic"');
-- Result: ["get", "images", "hm", "bg", "jpg", "http", "1", "0"]
-- Handles Long Numeric Sequences
SELECT TOKENIZE('12345678901234567890', '"parser"="basic"');
-- Result: ["12345678901234567890"]
-
新しいカスタムトークン化機能
- 柔軟なパイプライン:
char filter、tokenizer、複数のtoken filtersの連鎖設定を通じて、カスタムテキスト処理ワークフローを構築します。 - 再利用可能なコンポーネント: 一般的に使用される
tokenizersとfiltersは複数のanalyzers間で共有でき、冗長な定義を減らしメンテナンスコストを削減します。 - ユーザーはDorisのカスタムトークン化機能を活用して、
char filters、tokenizers、token filtersを柔軟に組み合わせることができます。これにより、異なるフィールドに適したカスタマイズされたトークン化ワークフローが可能になり、多様なシナリオでのパーソナライズされたテキスト検索要件を満たします。
使用例 1:
word_delimiterタイプのtoken filterを作成し、Word Delimiter Filterを設定してドット(.)とアンダースコア(_)を区切り文字として設定します。token filterのcomplex_word_splitterを参照するカスタムtokenizercomplex_identifier_analyzerを作成します。
-- 1. Create a custom token filter
CREATE INVERTED INDEX TOKEN_FILTER IF NOT EXISTS complex_word_splitter
PROPERTIES
(
"type" = "word_delimiter",
"type_table" = "[. => SUBWORD_DELIM], [_ => SUBWORD_DELIM]");
-- 2. Create a custom tokenizer
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS complex_identifier_analyzer
PROPERTIES
(
"tokenizer" = "standard",
"token_filter" = "complex_word_splitter, lowercase"
);
SELECT TOKENIZE('apy217.39_202501260000026_526', '”analyzer“=” complex_identifier_analyzer“');
-- Result:[apy],[217],[39],[202501260000026],[526]
-- MATCH('apy217') or MATCH('202501260000026') can both work
使用例2:
|記号のみを区切り文字として使用する、multi_value_tokenizerという名前のchar_groupタイプのtokenizerを作成します。tokenizermulti_value_tokenizerを参照するカスタムtokenizermulti_value_analyzerを作成します。
-- Create a char group tokenizer for multi-valued column splitting
CREATE INVERTED INDEX TOKENIZER IF NOT EXISTS multi_value_tokenizer
PROPERTIES
(
"type" = "char_group",
"tokenize_on_chars" = "[|]",
"max_token_length" = "255"
);
-- Create a tokenizer for multi-valued columns
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS multi_value_analyzer
PROPERTIES
(
"tokenizer" = "multi_value_tokenizer",
"token_filter" = "lowercase, asciifolding"
);
SELECT tokenize('alice|123456|company', '"analyzer"="multi_value_analyzer"');
-- Result: [alice]、[123456]、[company]
-- Both MATCH_ANY('alice') and MATCH_ANY('123456') can successfully match
-
より良いETL/ELT処理
Doris 4.0では、大規模なETL/ELTデータ処理の安定性とフォルトトレラント性を向上させる新しいSpill Disk機能を導入しています。この機能により、コンピューティングタスクがメモリ閾値を超えた場合に、中間データの一部が自動的にディスクに書き込まれ、メモリ不足によるタスク失敗を防ぎます。
現在、spill-to-diskは以下の演算子でサポートされています:
- Hash Join演算子
- Aggregation演算子
- Sort演算子
- CTE演算子
BE設定項目
spill_storage_root_path=/mnt/disk1/spilltest/doris/be/storage;/mnt/disk2/doris-spill;/mnt/disk3/doris-spill
spill_storage_limit=100%
- spill_storage_root_path: ディスクにスピルされる中間結果ファイルのストレージパス。デフォルトでは、
storage_root_pathと同じです。 - spill_storage_limit: スピルファイルのディスク容量制限。特定のサイズ(例:100G、1T)またはパーセンテージで設定でき、デフォルト値は20%です。
spill_storage_root_pathが専用ディスクに設定されている場合、このパラメータは100%として設定できます。その主な目的は、スピルファイルが過度なディスク容量を占有し、通常のデータストレージを妨げることを防ぐことです。
FE Session Variable
set enable_spill=true;
set exec_mem_limit = 10g;
set query_timeout = 3600;
- enable_spill: クエリがデータをディスクにスピルするかどうかを決定します。デフォルトでは無効になっています。有効にすると、クエリはメモリ不足による失敗を防ぐために中間データを自動的にディスクにスピルします。
- exec_mem_limit: 単一のクエリが使用できる最大メモリサイズを指定します。
- query_timeout: ディスクへのスピルが有効になっている場合、クエリの実行時間が大幅に増加する可能性があるため、このパラメータを適切に調整する必要があります。
スピル実行ステータスの監視
ディスクへのスピルが発生すると、ユーザーは複数の方法でその実行ステータスを監視できます:
監査ログ
FE監査ログにSpillWriteBytesToLocalStorageとSpillReadBytesFromLocalStorageの2つのフィールドが追加されました。これらはそれぞれ、スピル中にディスクに書き込まれたデータの総量とディスクから読み取られたデータの総量を表します。
SpillWriteBytesToLocalStorage=503412182|SpillReadBytesFromLocalStorage=503412182
Query Profile
クエリ実行中にディスクへのスピルがトリガーされた場合、Spillで始まる複数のカウンターがQuery Profileに追加され、スピル関連のメトリクスをマークおよび追跡します。HashJoinの「Build HashTable」ステップを例にとると、以下のカウンターが利用可能です:
PARTITIONED_HASH_JOIN_SINK_OPERATOR (id=4 , nereids_id=179):(ExecTime: 6sec351ms)
- Spilled: true
- CloseTime: 528ns
- ExecTime: 6sec351ms
- InitTime: 5.751us
- InputRows: 6.001215M (6001215)
- MemoryUsage: 0.00
- MemoryUsagePeak: 554.42 MB
- MemoryUsageReserved: 1024.00 KB
- OpenTime: 2.267ms
- PendingFinishDependency: 0ns
- SpillBuildTime: 2sec437ms
- SpillInMemRow: 0
- SpillMaxRowsOfPartition: 68.569K (68569)
- SpillMinRowsOfPartition: 67.455K (67455)
- SpillPartitionShuffleTime: 836.302ms
- SpillPartitionTime: 131.839ms
- SpillTotalTime: 5sec563ms
- SpillWriteBlockBytes: 714.13 MB
- SpillWriteBlockCount: 1.344K (1344)
- SpillWriteFileBytes: 244.40 MB
- SpillWriteFileTime: 350.754ms
- SpillWriteFileTotalCount: 32
- SpillWriteRows: 6.001215M (6001215)
- SpillWriteSerializeBlockTime: 4sec378ms
- SpillWriteTaskCount: 417
- SpillWriteTaskWaitInQueueCount: 0
- SpillWriteTaskWaitInQueueTime: 8.731ms
- SpillWriteTime: 5sec549ms
システムテーブル: backend_active_tasks
テーブルに2つのフィールドを追加しました:SPILL_WRITE_BYTES_TO_LOCAL_STORAGE と SPILL_READ_BYTES_FROM_LOCAL_STORAGE。これらはそれぞれ、クエリ実行中の中間スピルデータに対してディスクに書き込まれたデータの総量とディスクから読み取られたデータの総量を表します。
クエリ結果例:
mysql [information_schema]>select * from backend_active_tasks;
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| BE_ID | FE_HOST | WORKLOAD_GROUP_ID | QUERY_ID | TASK_TIME_MS | TASK_CPU_TIME_MS | SCAN_ROWS | SCAN_BYTES | BE_PEAK_MEMORY_BYTES | CURRENT_USED_MEMORY_BYTES | SHUFFLE_SEND_BYTES | SHUFFLE_SEND_ROWS | QUERY_TYPE | SPILL_WRITE_BYTES_TO_LOCAL_STORAGE | SPILL_READ_BYTES_FROM_LOCAL_STORAGE |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| 10009 | 10.16.10.8 | 1 | 6f08c74afbd44fff-9af951270933842d | 13612 | 11025 | 12002430 | 1960955904 | 733243057 | 70113260 | 0 | 0 | SELECT | 508110119 | 26383070 |
| 10009 | 10.16.10.8 | 1 | 871d643b87bf447b-865eb799403bec96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | SELECT | 0 | 0 |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
2 rows in set (0.00 sec)
テスト
Spill Disk機能の安定性を検証するため、TPC-DS 10TB標準データセットを使用してテストを実施しました。テスト環境は、AWS上の3台のBEサーバー(各16コアCPUおよび64GBメモリ)で構成され、BEメモリ対データサイズ比は1:52でした。
テスト結果では、総実行時間は28102.386秒で、TPC-DSベンチマークの99クエリがすべて正常に完了し、Spill Disk機能の安定性が検証されました。
Spill Disk機能の詳細については、こちらのドキュメントをご覧ください:https://doris.apache.org/docs/dev/admin-manual/workload-management/spill-disk
-
データ品質保証:エンドツーエンド
データ精度は健全なビジネス判断の礎です。この基盤を強化するため、Doris 4.0では関数動作の包括的な見直しと標準化を導入し、エンドツーエンド検証メカニズムを確立しました:データ取り込みから分析計算まで。これにより、すべての処理結果の正確性と信頼性を保証し、企業の意思決定に堅固なデータ基盤を提供します。
注:これらのデータ品質向上により、以前のバージョンから動作が変更される場合があります。アップグレード前にドキュメントを注意深く確認してください。
CAST関数
CASTは、SQLにおいて最も論理的に複雑な関数の一つで、その核となる機能は異なるデータ型を変換することです。このプロセスでは、大量の詳細なフォーマットルールとエッジケースの処理が必要なだけでなく、型セマンティクスの正確なマッピングも関わります。これらすべてにより、CASTは実際の使用においてエラーが発生しやすいプロセスの一部となっています。
特にデータインポートシナリオでは、これは本質的に外部文字列を内部データベース型に変換するCASTプロセスです。そのため、CASTの動作はインポートロジックの正確性と安定性を直接決定します。
また、多くのデータベースがAIシステムによって運用されるようになることを予想しており、これにはデータベース動作の明確な定義が必要です。そのため、BNF(バッカス・ナウア記法)を導入しました。BNFによって動作を定義することで、開発者とAI Agentに明確な運用ガイドラインを提供することを目指しています。
例えば、DATE型のCAST操作だけでも、BNFを通じて数十のフォーマット組み合わせシナリオを既にカバーしています(参照:https://doris.apache.org/docs/dev/sql-manual/basic-element/sql-data-types/conversion/datetime-conversion)。テストフェーズでは、これらのルールに基づいて数百万のテストケースも導出し、結果の正確性を保証しました。
<datetime> ::= <date> (("T" | " ") <time> <whitespace>* <offset>?)?
| <digit>{14} <fraction>? <whitespace>* <offset>?
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<date> ::= <year> ("-" | "/") <month1> ("-" | "/") <day1>
| <year> <month2> <day2>
<year> ::= <digit>{2} | <digit>{4} ; Till 1970
<month1> ::= <digit>{1,2} ; 01–12
<day1> ::= <digit>{1,2} ; 01–28/29/30/31
<month2> ::= <digit>{2} ; 01–12
<day2> ::= <digit>{2} ; 01–28/29/30/31
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<time> ::= <hour1> (":" <minute1> (":" <second1> <fraction>?)?)?
| <hour2> (<minute2> (<second2> <fraction>?)?)?
<hour1> ::= <digit>{1,2} ; 00–23
<minute1> ::= <digit>{1,2} ; 00–59
<second1> ::= <digit>{1,2} ; 00–59
<hour2> ::= <digit>{2} ; 00–23
<minute2> ::= <digit>{2} ; 00–59
<second2> ::= <digit>{2} ; 00–59
<fraction> ::= "." <digit>*
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<offset> ::= ( "+" | "-" ) <hour-offset> [ ":"? <minute-offset> ]
| <special-tz>
| <long-tz>
<hour-offset> ::= <digit>{1,2} ; 0–14
<minute-offset> ::= <digit>{2} ; 00/30/45
<special-tz> ::= "CST" | "UTC" | "GMT" | "ZULU" | "Z" ;
<long-tz> ::= ( ^<whitespace> )+ ; e.g. America/New_York
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
<area> ::= <alpha>+
<location> ::= (<alpha> | "_")+
<alpha> ::= "A" | … | "Z" | "a" | … | "z"
<whitespace> ::= " " | "\t" | "\n" | "\r" | "\v" | "\f"
Strict Mode、Non-Strict Mode、およびTRY_CAST
Doris 4.0では、CAST操作のために3つのメカニズムを追加しました:Strict Mode、Non-Strict Mode(enable_strict_castセッション変数で制御)、およびTRY_CAST関数です。これらのメカニズムにより、Dorisはデータ型変換をより適切に処理できます。
Strict Mode
システムは、事前定義されたBNF(Backus-Naur Form)構文ルールに従って、入力データの形式、型、および値の範囲に対して厳密な検証を実行します。データがルールを満たさない場合(例えば、「数値型」が必要なフィールドに文字列が渡された場合、または日付が「YYYY-MM-DD」標準に準拠していない場合)、システムはデータ処理ワークフローを直接終了し、明確なエラー(特定の非準拠フィールドと理由を含む)をスローします。これにより、無効なデータがストレージや計算プロセスに入ることを防ぎます。
この「ゼロ・トレランス」検証ロジックは、PostgreSQLの厳密なデータ検証動作と高い整合性があります。ソースからデータの正確性と一貫性を保証し、データ信頼性に対して極めて高い要件があるシナリオには不可欠です:金融業界での取引照合、財務での請求書会計、政府システムでの情報登録などです。これらのシナリオでの無効なデータ(例:負の取引金額、誤った請求書日付形式)は、財務損失、コンプライアンスリスク、またはビジネスプロセスの中断につながる可能性があります。
Non-Strict Mode
システムはデータをBNFルールに対して検証しますが、「フォルトトレラント」な処理ロジックを採用します:データが非準拠の場合、ワークフローは終了されず、エラーもスローされません。代わりに、無効なデータは自動的にNULL値に変換されてからSQLの実行が継続されます(例:文字列「xyz」を数値NULLに変換)。これによりSQLタスクが正常に完了し、ビジネスプロセスの継続性と実行効率を優先します。
このモードは「データ整合性要件は低いが、SQL実行成功率が重要」なシナリオにより適しています:ログデータ処理、ユーザー行動データクリーニング、アドホックデータ分析などです。これらのシナリオでは、データ量が大量で、データソースが複雑です(例:APPログは、デバイス異常により文字化けした形式のフィールドを含む可能性があります)。少量の無効なデータによってSQL タスク全体が中断されると、処理効率が大幅に低下します。一方、少数のNULL値は全体的な分析結果への影響は最小限です(例:アクティブユーザー数やクリック率の統計)。
TRY_CAST関数
enable_strict_castパラメータは、ステートメントレベルですべてのCAST操作の動作を制御します。しかし、単一のSQLが複数のCAST関数を含むシナリオが発生する可能性があります:一部はStrict Modeが必要で、他の部分はNon-Strict Modeが必要な場合です。これに対処するため、TRY_CAST関数が導入されました。
TRY_CAST関数は、式を指定されたデータ型に変換します。変換が成功した場合、変換された値を返します。失敗した場合はNULLを返します。その構文はTRY_CAST(source_expr AS target_type)で、source_exprは変換される式、target_typeはターゲットデータ型です。
例:
TRY_CAST('123' AS INT)は123を返しますTRY_CAST('abc' AS INT)はNULLを返します
TRY_CAST関数は、型変換に対するより柔軟なアプローチを提供します。厳密な変換成功が必要でないシナリオでは、この関数を使用して変換失敗によるエラーを回避できます。
浮動小数点数の計算
Dorisは2つの浮動小数点データ型をサポートしています:FLOATとDOUBLEです。しかし、INF(無限大)とNAN(非数)の不確実な動作は、従来ORDER BYやGROUP BYなどの操作で潜在的なエラーを引き起こしていました。Doris 4.0では、これらの値の動作を標準化し、明確に定義しました。
算術演算
Dorisの浮動小数点数は、加算、減算、乗算、除算を含む一般的な算術演算をサポートします。
Dorisは浮動小数点のゼロ除算を処理する際、IEEE 754標準に完全に準拠していないことをお知らせします。代わりに、DorisはPostgreSQLの実装を参考にしています:ゼロで除算する場合、特殊な値(例:INF)は生成されません。代わりに、返される結果はSQL NULLです。
| 式 | PostgreSQL | IEEE 754 | Doris |
|---|---|---|---|
| 1.0 / 0.0 | Error | Infinity | NULL |
| 0.0 / 0.0 | Error | NaN | NULL |
| -1.0 / 0.0 | Error | -Infinity | NULL |
| 'Infinity' / 'Infinity' | NaN | NaN | NaN |
| 1.0 / 'Infinity' | 0 | 0 | 0 |
| 'Infinity' - 'Infinity' | NaN | NaN | NaN |
| 'Infinity' - 1.0 | Infinity | Infinity | Infinity |
比較演算
IEEE標準で定義される浮動小数点比較は、一般的な整数比較と重要な違いがあります。例:
- 負のゼロと正のゼロは等しいと見なされます
- 任意のNaN(非数)値は、それ自体を含む他のいかなる値とも等しくありません
- すべての有限浮動小数点数は+∞より厳密に小さく、-∞より厳密に大きいです
結果の一貫性と予測可能性を保証するため、DorisはIEEE標準とは異なる方法でNaNを処理します。Dorisでは:
- NaNは他のすべての値(Infinityを含む)より大きいと見なされます
- NaNはNaNと等しいです
例
mysql> select * from sort_float order by d;
+------+-----------+
| id | d |
+------+-----------+
| 5 | -Infinity |
| 2 | -123 |
| 1 | 123 |
| 4 | Infinity |
| 8 | NaN |
| 9 | NaN |
+------+-----------+
mysql> select
cast('Nan' as double) = cast('Nan' as double) ,
cast('Nan' as double) > cast('Inf' as double) ,
cast('Nan' as double) > cast('123456.789' as double);
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
| cast('Nan' as double) = cast('Nan' as double) | cast('Nan' as double) > cast('Inf' as double) | cast('Nan' as double) > cast('123456.789' as double) |
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
| 1 | 1 | 1 |
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
Date Functions
この最適化は、日付関数とタイムゾーンサポートという2つの主要領域に焦点を当て、データ処理の精度と適用性をさらに向上させます。
統一された日付オーバーフロー動作
オーバーフローシナリオ(例:0000-01-01より前または9999-12-31より後の日付)における多数の日付関数の動作が標準化されました。以前は、異なる関数がオーバーフローを一貫性なく処理していましたが、現在はすべての関連関数が日付オーバーフローがトリガーされた際に一様にエラーを返し、異常な結果によるデータ計算の偏差を防ぎます。
拡張された日付関数サポート
一部の日付型関数のパラメータシグネチャがint32からint64にアップグレードされました。この調整により、元のint32型の日付範囲制限が解除され、関連関数がより広いスパンでの日付計算をサポートできるようになります。
改善されたタイムゾーンサポートドキュメント
まとめ
真にAIエージェント対応のデータベースエコシステムを構築し、大規模モデルがDorisをより正確かつ深く理解できるよう支援するため、我々はDorisのSQL Referenceを体系的に改善しました。これには、データ型定義、関数定義、データ変換ルールなどのコア内容の精緻化が含まれ、AIとデータベース間の協調的相互作用のための明確で信頼性の高い技術基盤を築いています。
この取り組みは、洞察とエネルギーでプロジェクトに重要な推進力をもたらしたコミュニティ貢献者の素晴らしいサポートによって実現されました。我々は、より多くのコミュニティメンバーに参加していただくことを心から歓迎します。イノベーションの境界を押し広げ、エコシステムを強化し、すべての人にとってより大きな価値を創造するために一緒に取り組みましょう。
5. パフォーマンス最適化
TopN
クエリパターンSELECT * FROM tableX ORDER BY columnA ASC/DESC LIMIT Nは典型的なTopNクエリであり、ログ分析、ベクター検索、データ探索などの高頻度シナリオで広く使用されています。このようなクエリはフィルタリング条件を含まないため、従来の実行方法では大きなデータセットを扱う際にフルテーブルスキャンとソートが必要になります。これにより、過度な不要データ読み込みと深刻な読み取り増幅問題が生じます。特に高同時実行リクエストや大容量データストレージシナリオでは、これらのクエリのパフォーマンスボトルネックがより顕著になり、最適化の緊急な必要性が生まれています。
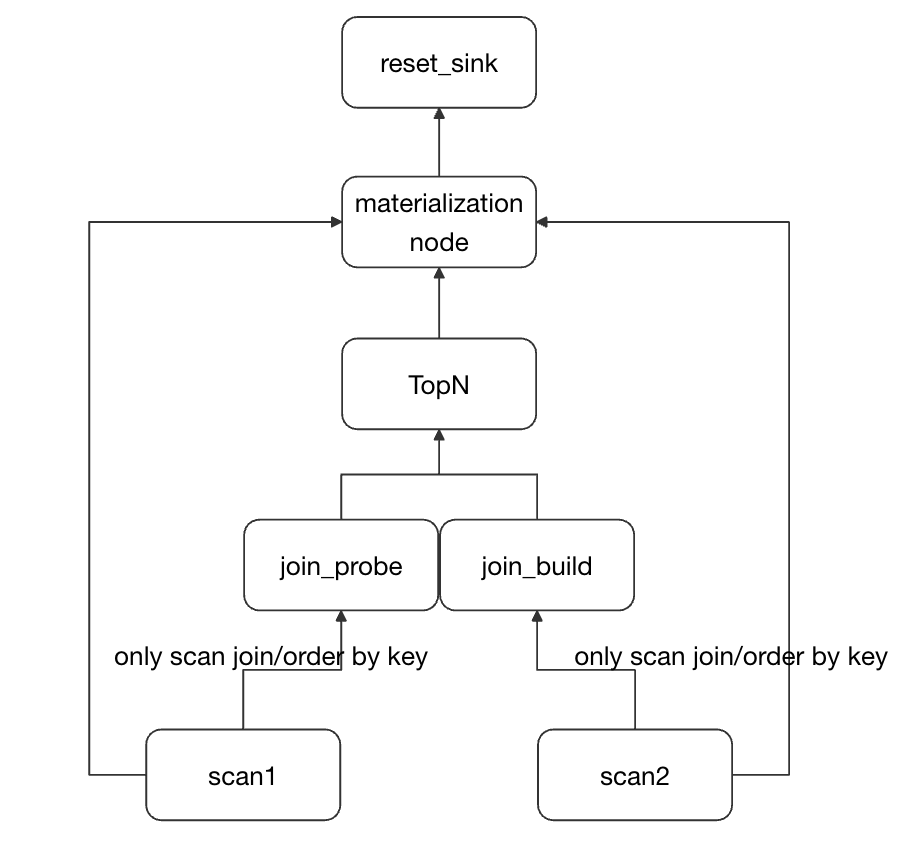
この課題に対処するため、我々は「Lazy Materialization」最適化メカニズムを導入し、TopNクエリを効率的な実行のために2段階に分割しました:
- 第1段階:ソート列(
columnA)とデータ位置特定に使用される主キー/行識別子のみを読み取ります。ソートを通じてLIMIT N条件を満たすターゲット行を迅速にフィルタリングします。 - 第2段階:行識別子に基づいてターゲット行のすべての列データを正確に読み取ります。
Doris 4.0では、この機能をさらに拡張しました:
- マルチテーブル結合でのTopN lazy materializationのサポート
- 外部テーブルクエリでのTopN lazy materializationのサポート
これら2つの新しいシナリオにおいて、このソリューションは不要な列読み取り量を大幅に削減し、読み取り増幅を根本的に減少させます。小さなLIMIT値を持つ幅広テーブルシナリオでは、TopNクエリの実行効率も数十倍改善されました。
SQL Cache
SQL CacheはDorisの初期バージョンで提供されていた機能でしたが、多くの条件により使用が制限され、デフォルトで無効になっていました。このバージョンでは、SQL Cache結果の正確性に影響を与える可能性のある問題を体系的に解決しました:
- カタログ、データベース、テーブル、または列のクエリ権限の変更
- Session変数の変更
- 定数畳み込みルールで簡略化できない非決定的関数の存在
SQL Cache結果の正確性を確保した後、この機能はデフォルトで有効になりました。
また、クエリオプティマイザーでのSQL解析パフォーマンスを大幅に最適化し、SQL解析効率を100倍改善しました。
例として、以下のSQLを考えてみてください。ここでbig_viewはネストされたビューを含む大きなビューで、合計163個の結合と17個の和集合があります:
SELECT *, now() as etl_time from big_view;
このクエリのSQL解析時間は400msから2msに短縮されました。この最適化はSQL Cacheにメリットをもたらすだけでなく、高並行クエリシナリオにおけるDorisのパフォーマンスも大幅に向上させます。
JSONパフォーマンス最適化
JSONは半構造化データの標準ストレージ形式です。Doris 4.0では、JSONBもアップグレードしました:
Decimal型のサポートを追加
これにより、JSONのNumber型とDoris内部型間のマッピングシステムが補完されます(従来はInt8/Int16/Int32/Int64/Int128/Float/Doubleをカバー)。高精度数値シナリオでのストレージと処理ニーズをさらに満たし、大きなデータや高精度データの型適応問題によるJSON変換での精度損失を回避します。これはVARIANTデータ型の導出にも役立ちます。
JSONB関連関数の体系的なパフォーマンス最適化
Doris 4.0では、JSONB関連関数(例:json_extractシリーズ、json_exists_path、json_type)の全面的なパフォーマンス改善を行いました。最適化後、これらの関数の実行効率は30%以上向上し、JSONフィールド抽出、型判定、パス検証などの高頻度操作の処理速度を大幅に加速しました。これにより、半構造化データの効率的な分析により強力なサポートを提供します。
関連機能の詳細については、Doris公式ドキュメントを参照してください:https://doris.apache.org/docs/dev/sql-manual/basic-element/sql-data-types/semi-structured/JSON
6. よりユーザーフレンドリーなリソース管理
Doris 4.0では、workload groupの使用メカニズムも最適化されました:
- CPUとメモリのソフトリミットとハードリミットの定義方法を統一しました。もはや様々な設定項目でソフト/ハードリミット機能を個別に有効にする必要はありません。
- 同じ
workload groupでソフトリミットとハードリミットの両方を使用することをサポート。
この最適化により、パラメータ設定プロセスが簡素化されるだけでなく、workload groupの柔軟性も向上し、より多様なリソース管理ニーズに対応します。
CPUリソース設定
MIN_CPU_PERCENTとMAX_CPU_PERCENTは、CPU競合が発生した際のWorkload Group内のすべてのリクエストに対する最小および最大保証CPUリソースを定義します:
- MAX_CPU_PERCENT(最大CPU割合):グループのCPU帯域幅の上限。現在のCPU使用状況に関係なく、Workload GroupのCPU使用率はこの値を超えることはありません。
- MIN_CPU_PERCENT(最小CPU割合):グループのために予約されたCPU帯域幅。競合時、他のグループはこの部分の帯域幅を使用できませんが、リソースがアイドル状態の時は、グループは
MIN_CPU_PERCENTを超える帯域幅を使用できます。
例:ある企業の営業部門とマーケティング部門が同じDorisインスタンスを共有しているとします。営業部門のワークロードはCPU集約的で高優先度のクエリを含み、マーケティング部門のワークロードもCPU集約的ですが低優先度のクエリです。各部門に個別のWorkload Groupを作成することで:
- 営業Workload Groupに40%の
MIN_CPU_PERCENTを割り当て。 - マーケティングWorkload Groupに30%の
MAX_CPU_PERCENTを割り当て。
この設定により、営業ワークロードが必要なCPUリソースを確保しながら、マーケティングワークロードが営業部門のCPUニーズに影響を与えることを防ぎます。
メモリリソース設定
MIN_MEMORY_PERCENTとMAX_MEMORY_PERCENTは、Workload Groupが使用できる最小および最大メモリを表します:
- MAX_MEMORY_PERCENT:グループでリクエストが実行される際、そのメモリ使用量は総メモリのこの割合を超えることはありません。超過した場合、クエリはディスクへのスピリングをトリガーするか終了(kill)されます。
- MIN_MEMORY_PERCENT:グループのために予約された最小メモリ。リソースがアイドル状態の時は、グループは
MIN_MEMORY_PERCENTを超えるメモリを使用できますが、メモリが不足している時は、システムはMIN_MEMORY_PERCENTに基づいてメモリを割り当てます。グループのメモリ使用量をMIN_MEMORY_PERCENTまで削減するために一部のクエリをkillし、他のWorkload Groupが十分なメモリを確保できるようにします。
Spill Diskとの統合
Doris 4.0では、Workload Groupのメモリ管理機能とSpill Disk機能を統合しました。ユーザーは個別のクエリにメモリサイズを設定してスピリングを制御するだけでなく、Workload Groupのスロットメカニズムを通じて動的スピリングを実装することもできます。Workload Groupに対して以下のポリシーが実装されています:
- none(デフォルト):ポリシーを無効化。クエリは可能な限りメモリを使用しますが、Workload Groupのメモリ制限に達するとスピリングがトリガーされます(クエリサイズに基づく選択なし)。
- fixed:クエリあたりの利用可能メモリ =
workload groupのmem_limit * query_slot_count / max_concurrency。このポリシーは並行性に基づいて各クエリに固定メモリを割り当てます。 - dynamic:クエリあたりの利用可能メモリ =
workload groupのmem_limit * query_slot_count / sum(実行中クエリスロット)。これは主にfixedモードでの未使用スロットに対処し、基本的に大きなクエリを最初にスピリングをトリガーします。
fixedとdynamicの両方がクエリにハードリミットを設定します:制限を超えるとスピリングまたはkillがトリガーされ、ユーザーが設定した静的メモリ割り当てパラメータを上書きします。したがって、slot_memory_policyを設定する際は、Workload Groupのmax_concurrencyを適切に設定して、メモリ不足を避けるようにしてください。
まとめ
Apache Doris 4.0は、新しいAIサポート(ベクトル検索、AI Functions)とより優れた全文検索機能で大きな前進を遂げました。これらのアップグレードにより、ユーザーはAIとエージェント時代で先頭に立ち続けることができ、企業は従来のBI分析からAI駆動のワークロードまであらゆることを処理できるようになります。
リアルタイムダッシュボードやユーザー行動分析の強化から、ドキュメント検索や大規模オフラインデータ処理のサポートまで、Doris 4.0はテクノロジー、金融、Web3、小売、ヘルスケアなど様々な業界において、より高速で信頼性が高く、AI対応の分析体験を提供します。
Apache Dorisの最新版がダウンロード可能になりました。詳細なリリースノートとアップグレードガイドについてはdoris.apache.orgをご覧ください。Dorisコミュニティに参加して、探索、テスト、フィードバックの共有を行ってください。
謝辞
改めて、このバージョンの研究開発、テスト、要件フィードバックに参加されたすべての貢献者の皆様に、心からの感謝を表したいと思います:
Pxl, walter, Gabriel, Mingyu Chen (Rayner), Mryange, morrySnow, zhangdong, lihangyu, zhangstar333, hui lai, Calvin Kirs, deardeng, Dongyang Li, Kaijie Chen, Xinyi Zou, minghong, meiyi, James / Jibing-Li, seawinde, abmdocrt, Yongqiang YANG, Sun Chenyang, wangbo, starocean999, Socrates / 苏小刚,Gavin Chou, 924060929, HappenLee, yiguolei, daidai, Lei Zhang, zhengyu, zy-kkk, zclllyybb /zclllhhjj, bobhan1, amory, zhiqiang, Jerry Hu, Xin Liao, Siyang Tang, LiBinfeng, Tiewei Fang, Luwei, huanghaibin, Qi Chen, TengJianPing, 谢健,Lightman, zhannngchen, koarz, xy720, kkop, HHoflittlefish777, xzj7019, Ashin Gau, lw112, plat1ko, shuke, yagagagaga, shee, zgxme, qiye, zfr95, slothever, Xujian Duan, Yulei-Yang, Jack, Kang, Lijia Liu, linrrarity, Petrichor, Thearas, Uniqueyou, dwdwqfwe, Refrain, catpineapple, smiletan, wudi, caiconghui, camby, zhangyuan, jakevin, Chester, Mingxi, Rijesh Kunhi Parambattu, admiring_xm, zxealous, XLPE, chunping, sparrow, xueweizhang, Adonis Ling, Jiwen liu, KassieZ, Liu Zhenlong, MoanasDaddyXu, Peyz, 神技圈子,133tosakarin, FreeOnePlus, Ryan19929, Yixuan Wang, htyoung, smallx, Butao Zhang, Ceng, GentleCold, GoGoWen, HonestManXin, Liqf, Luzhijing, Shuo Wang, Wen Zhenghu, Xr Ling, Zhiguo Wu, Zijie Lu, feifeifeimoon, heguanhui, toms, wudongliang, yangshijie, yongjinhou, yulihua, zhangm365, Amos Bird, AndersZ, Ganlin Zhao, Jeffrey, John Zhang, M1saka, SWEI, XueYuhai, Yao-MR, York Cao, caoliang-web, echo-dundun, huanghg1994, lide, lzy, nivane, nsivarajan, py023, vlt, wlong, zhaorongsheng, AlexYue, Arjun Anandkumar, Arnout Engelen, Benjaminwei, DayuanX, DogDu, DuRipeng, Emmanuel Ferdman, Fangyuan Deng, Guangdong Liu, HB, He xueyu, Hongkun Xu, Hu Yanjun, JinYang, KeeProMise, Muhammet Sakarya, Nya~, On-Work-Song, Shane, Stalary, StarryVerse, TsukiokaKogane, Udit Chaudhary, Xin Li, XnY-wei, Xu Chen, XuJianxu, XuPengfei, Yijia Su, ZhenchaoXu, cat-with-cat, elon-X, gnehil, hongyu guo, ivin, jw-sun, koi, liuzhenwei, msridhar78, noixcn, nsn_huang, peterylh, shouchengShen, spaces-x, wangchuang, wangjing, wangqt, wubiao, xuchenhao, xyf, yanmingfu, yi wang, z404289981, zjj, zzwwhh, İsmail Tosun, 赵硕