Best practice in Kwai: Apache Doris on Elasticsearch
Author: Xiang He, Head Developer of Big Data, Commercialization Team of Kwai

1.1 Kwai
Kwai(HKG:1024) is a social network for short videos and trends. Discover funny short videos, contribute to the virtual community with recordings, videos of your life, playing daily challenges or likes the best memes and videos. Share your life with short videos and choose from dozens of magical effects and filters for them.
1.2 Kwai's Commercial Report Engine
Kwai’s commercial report engine provides advertisers with real-time query service for multi-dimensional analysis reports. And it also provides query service for multi-dimensional analysis reports for internal users. The engine is committed to dealing with high-performance, high-concurrency, and high-stability query problems in multi-dimensional analysis report cases.
2 Previous Architecture
2.1 Background
Traditional OLAP engines deal with multi-dimensional analysis in a more pre-modeled way, by building a data cube (Cube) to perform operations such as Drill-down, Roll-up, Slice, and Dice and Pivot. Modern OLAP analysis introduces the idea of a relational model, representing data in two-dimensional relational tables. In the modeling process, usually there are two modeling methods. One is to ingest the data of multiple tables into one wide table through Join; the other is to use the star schema, divide the data into fact table and dim-table. And then Join them when querying. Both options have some pros and cons:
Wide table:
Taking the idea of exchanging space for time. The primary key of the dim-table is the unique ID to fill all dimensions, and multiple dimension data is stored in redundant storage. Its advantage is that it is convenient to query, unnecessary to associate additional dim-tables, which is way better. The disadvantage is that if there is a change in dimension data, the entire table needs to be refreshed, which is bad for high-frequency Update.
Star Schema:
Dimension data is completely separated from fact data. Dimension data is often stored in a dedicated engine (such as MySQL, Elasticsearch, etc.). When querying, dimension data is associated with the primary key. The advantage is that changes in dimension data do not affect fact data, which can support high-frequency Update operations. The disadvantage is that the query logic is relatively more complex, and multi-table Join may lead to performance loss.
2.2 Requirement for an OLAP Engine
In Kwai’s business, the commercial reports engine supports the real-time query of the advertising effect for advertisers. When building the report engine, we expect to meet the following requirements:
- Immersive data: the original data of a single table increases by ten billion every day
- High QPS in Query: thousand-level QPS on average
- High stability requirements: SLA level of 99.9999 %
Most importantly, due to frequent changes in dimension data, dim-tables need to support Update operations up to thousand-level QPS and further support requirements such as fuzzy matching and word segmentation retrieval. Based on the above requirements, we chose star schema and built a report engine architecture with Apache Druid and Elasticsearch.
2.3 Previous Architecture: Based on Apache Druid
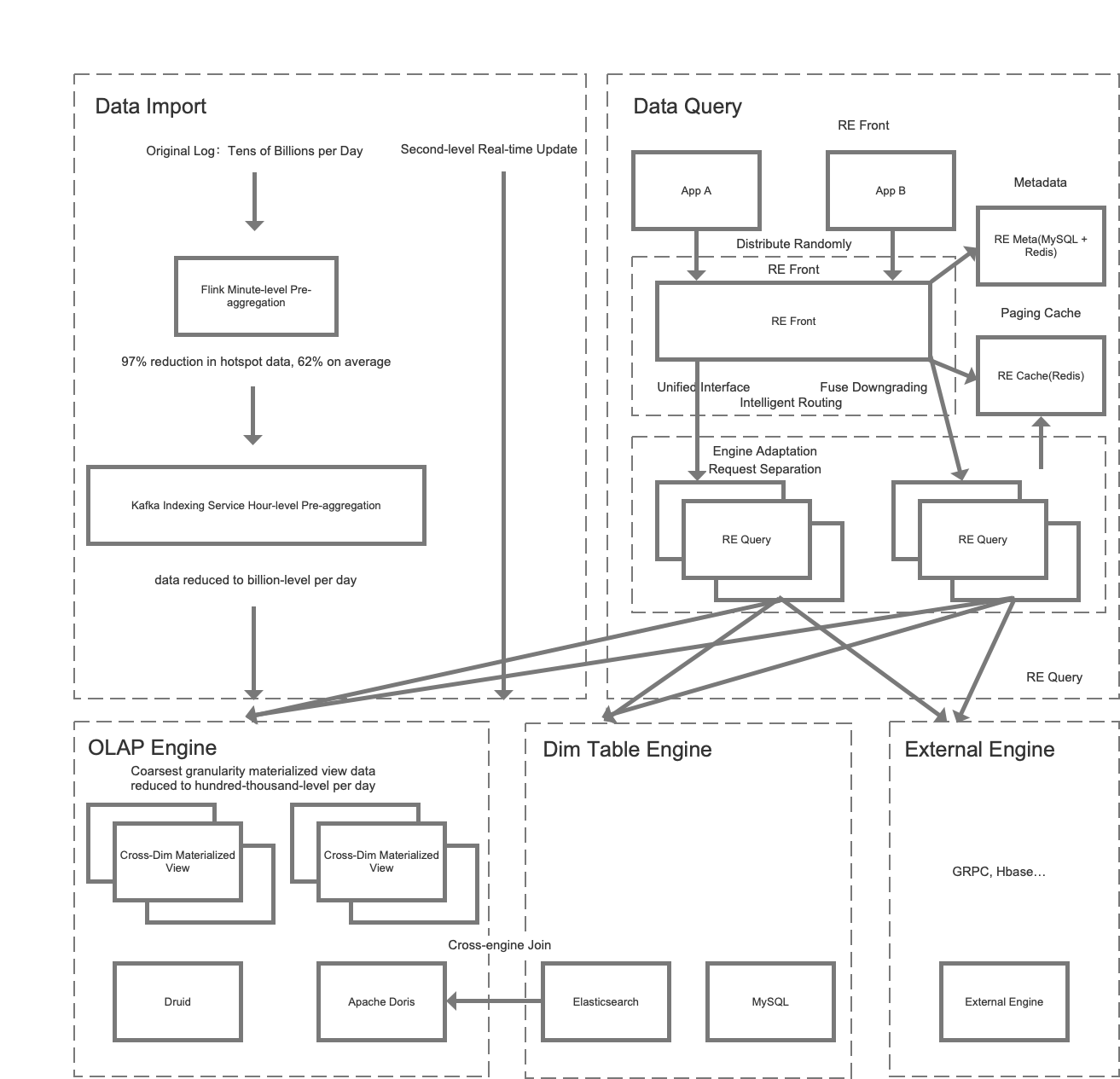
We chose the combination of Elasticsearch and Apache Druid. In data import, we use Flink to pre-aggregate the data at minute-evel, and use Kafka to pre-aggregate the data at hour-level. In data query, the application initiates a query request through RE Front API, and Re Query initiates queries to the dim-table engine (Elasticsearch and MySQL) and the extension engine respectively.
Druid is a timing-based query engine that supports real-time data ingestion and is used to store and query large amounts of fact data. We adopt Elasticseach based on those concerns:
- High update frequency, QPS is around 1000
- Support word segmentation and fuzzy search, which is suitable for Kwai
- Supports high-level dim-table data, which can be directly qualified without adopting sub-database and sub-table just like MySQL database
- Supports data synchronization monitoring, and has check and recovery services as well
2.4 Engine of the Reports
The report engine can be divided into two layers: REFront and REQuery. REMeta is an independent metadata management module. The report engine implements MEMJoin inside REQuery. It supports associative query between fact data in Druid and dimension data in Elasticsearch. And it also provides virtual cube query for upper-layer business, avoiding the explosion of complex cross-engine management and query logic.
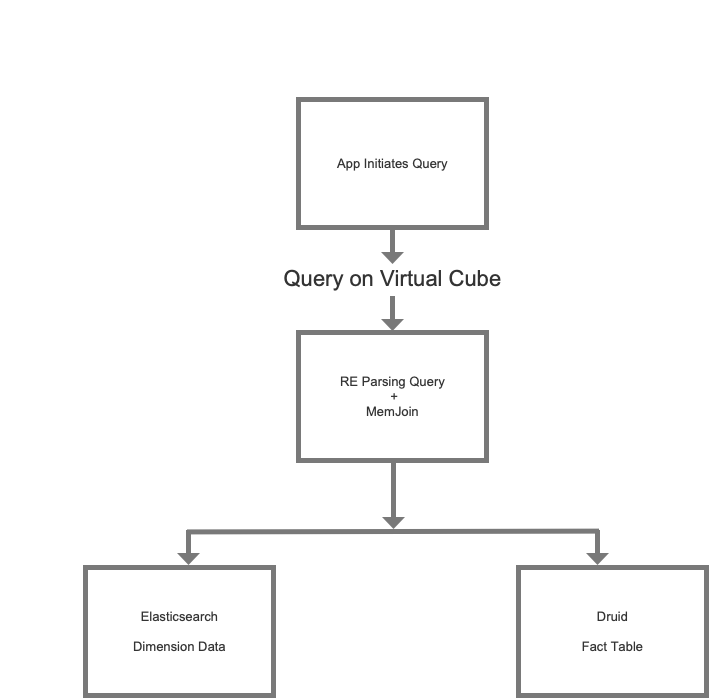
3 New Architecture Based on Apache Doris
3.1 Problems Remained
First, we came across a problem when we build the report engine. Mem Join is single-machine with serial execution. When the amount of data pulled from Elasticsearch exceeds 100,000 at a single time, the response time is close to 10s, and the user experience is poor. Moreover, using a single node to execute large-scale data Join will consume a lot of memory, causing Full GC.
Second, Druid's Lookup Join function is not so perfect, which is a big problem, and it cannot fully meet our business needs.
3.2 Database Research
So we conducted a survey on popular OLAP databases in the industry, the most representative of which are Apache Doris and Clickhouse. We found out that Apache Doris is more capable of Join between large and wide tables. ClickHouse can support Broadcast memory-based Join, but the performance is not good for the Join between large and wide tables with a large data volume. Both Doris and Clickhouse support detailed data storage, but the capability for concurrency of Clickhouse is low. On the contrary, Doris supports high-concurrency and low-latency query services, and a single machine supports up to thousands of QPS. When the concurrency increases, horizontal expansion of FE and BE can be supported. However, Clickhouse's data import is not able to support Transaction SQL, which cannot realize Exactly-once semantics and has limited ablility for standard SQL. In contrast, Doris provides Transaction SQL and atomicity for data import. Doris itself can ensure that messages in Kafka are not lost or re-subscribed, which is to say, Exactly-Once semantics is supported. ClickHouse has high learning cost, high operation and maintenance costs, and weak in distribution. The fact that it requires more customization and deeper technical strength is another problem. Doris is different. There are only two core components, FE and BE, and there are fewer external dependencies. We also found that because Doris is closer to the MySQL protocol, it is more convenient than Clickhouse and the cost of migration is not so large. In terms of horizontal expansion, Doris' expansion and contraction can also achieve self-balancing, which is much better than that of Clickhouse.
From this point of view, Doris can better improve the performance of Join and is much better in other aspects such as migration cost, horizontal expansion, and concurrency. However, Elasticsearch has inherent advantages in high-frequency Update.
It would be an ideal solution to deal with high-frequency Update and Join performance at the same time by building engines through Doris on Elasticsearch.
3.3 Good Choice: Doris on Elasticsearch
What is the query performance of Doris on Elasticsearch?
First of all, Apache Doris is a real-time analytical database based on MPP architecture, with strong performance and strong horizontal expansion capability. Doris on Elasticsearch takes advantage on this capability and does a lot of query optimization. Secondly, after integrating Elasticsearch, we have also made a lot of optimizations to the query:
- Shard-level concurrency
- Automatic adaptation of row and column scanning, priority to column scanning
- Sequential read, terminated early
- Two-phase query becomes one-phase query
- Broadcast Join is especially friendly for small batch data
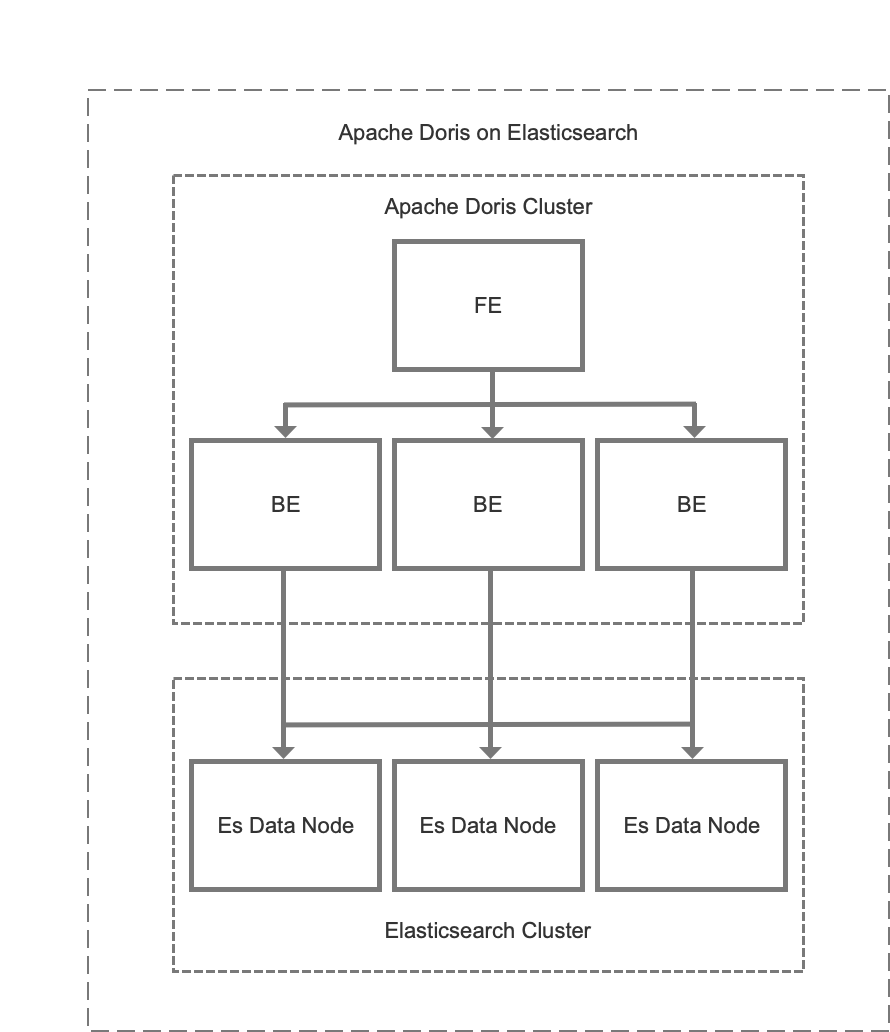
3.4 Doris on Elasticsearch
3.4.1 Data Link Upgrade
The upgrade of the data link is relatively simple. In the first step, in Doris we build a new Olap table and configure the materialized view. Second, the routine load is initiated based on the Kafka topic of the previous fact data, and then real-time data is ingested. The third step is to ingest offline data from Hive's broker load. The last step is to create an Elasticsearch external table through Doris.
3.4.2 Upgrades of the Report Engine
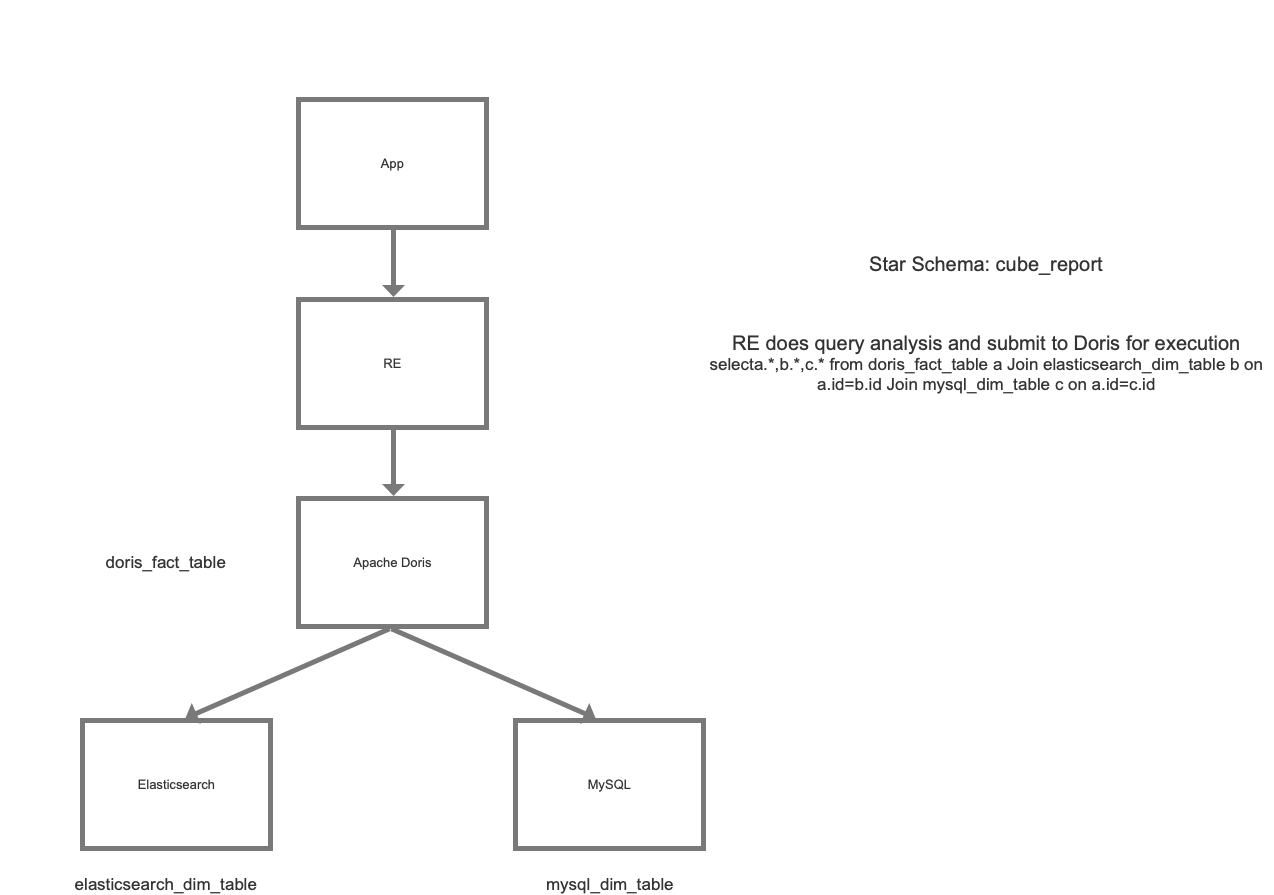
Note: The MySQL dim-table associated above is based on future planning. Currently, Elasticsearch is mainly used as the dim-table engine
Report Engine Adaptation
- Generate virtual cube table based on Doris's star schema
- Adapt to cube table query analysis, intelligent Push-down
- Gray Release
4 Online Performance
4.1 Fact Table Query Performance Comparison
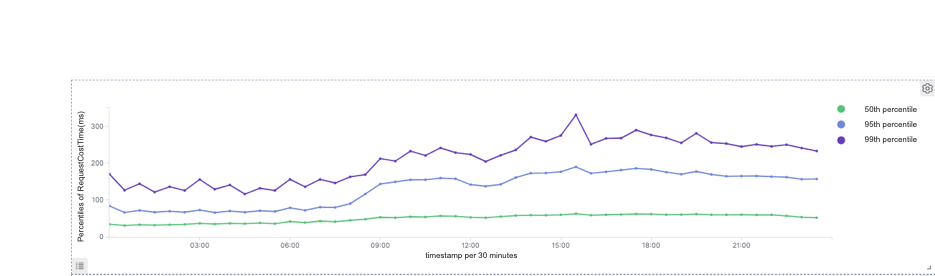
Druid
Doris
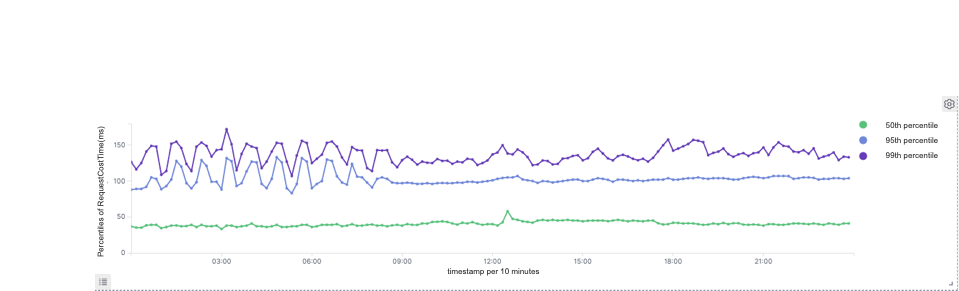
99th percentile of response time: Druid: 270ms, Doris: 150ms and which is reduced by 45%
4.2 Comparison of Cube Table Query Performance in Join
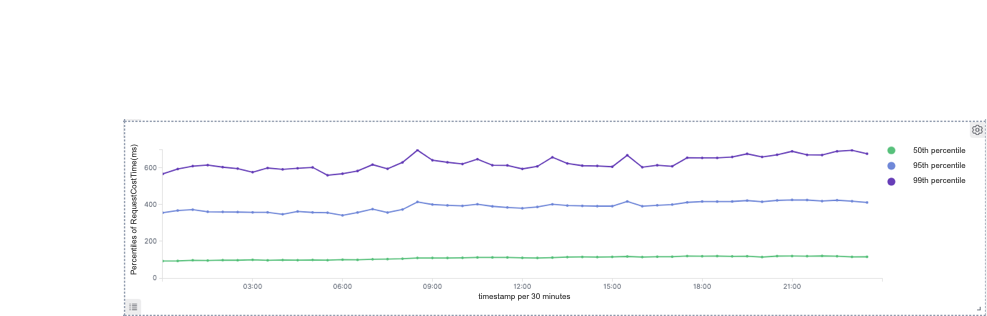
Druid
Doris
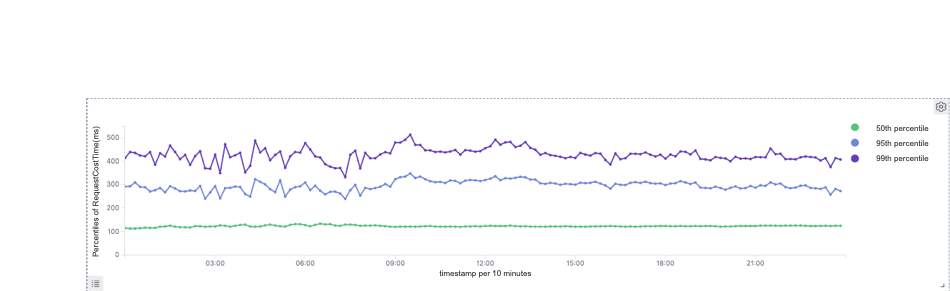
99th percentile of response time: Druid: 660ms, Doris: 440ms and which is reduced by 33%
4.3 Benefits
- The overall time consumption of 99 percentile is reduced by about 35%
- Resource saving about 50%
- Remove the complex logic of MemJoin from the report engine; Realize through DO(in the case of large query: dim-table results exceed 100,000, performance improvement exceeds 10 times, 10s to 1s)
- Richer query semantics (Mem Join is relatively simple and does not support complex queries)
5 Summary and Plans
In Kwai's commercial business, Join queries between dimension data and fact data is very common. After using Doris, query becomes simple. We only need to synchronize the fact table and dim-table on a daily basis and Join while querying. By replacing Druid and Clickhouse with Doris, Doris basically covers all scenarios when we use Druid. In this way, Kwai's commercial report engine greatly improves the aggregation and analysis capabilities of massive data. During the use of Apache Doris, we also found some unexpected benefits: For example, the import method of Routine Load and Broker Load is relatively simple, which improves the query speed; The data occupation is greatly reduced; Doris supports the MySQL protocol, which is much easier for data analyst to fetch data and make charts.
Although the Doris on Elasticsearch has fully meet our requirement, Elasticsearch external table still requires manual creation. However, Apache Doris recently released the latest version V1.2.0. The new version has added Multi-Catlog, which provides the ability to seamlessly access external table sources such as Hive, Elasticsearch, Hudi, and Iceberg. Users can connect to external tables through the CREATE CATALOG command, and Doris will automatically map the library and table information of the external dable. In this way, we don't need to manually create the Elasticsearch external tables to complete the mapping in the future, which greatly saves us time and cost of development and improves the efficiency of research and development. The power of other new functions such as Vectorization and Ligt Schema Change also gives us new expectations for Apache Doris. Bless Apache Doris!
Contact Us
Apache Doris Website:http://doris.apache.org
Github:https://github.com/apache/doris
Dev Email:dev@doris.apache.org