For entry-level data engineers: how to build a simple but solid data architecture
This article aims to provide reference for non-tech companies who are seeking to empower your business with data analytics. You will learn the basics about how to build an efficient and easy-to-use data system, and I will walk you through every aspect of it with a use case of Apache Doris, an MPP-based analytic data warehouse.
What You Need
This case is about a ticketing service provider who want a data platform that boasts quick processing, low maintenance costs, and ease of use, and I think they speak for the majority of entry-level database users.
A prominent feature of ticketing services is the periodic spikes in ticket orders, you know, before the shows go on. So from time to time, the company has a huge amount of new data rushing in and requires real-time processing of it, so they can make timely adjustments during the short sales window. But in other time, they don't want to spend too much energy and funds on maintaining the data system. Furthermore, for a beginner of digital operation who only require basic analytic functions, it is better to have a data architecture that is easy-to-grasp and user-friendly. After research and comparison, they came to the Apache Doris community and we help them build a Doris-based data architecture.
Simple Architecture
The building blocks of this architecture are simple. You only need Apache Flink and Apache Kafka for data ingestion, and Apache Doris as an analytic data warehouse.
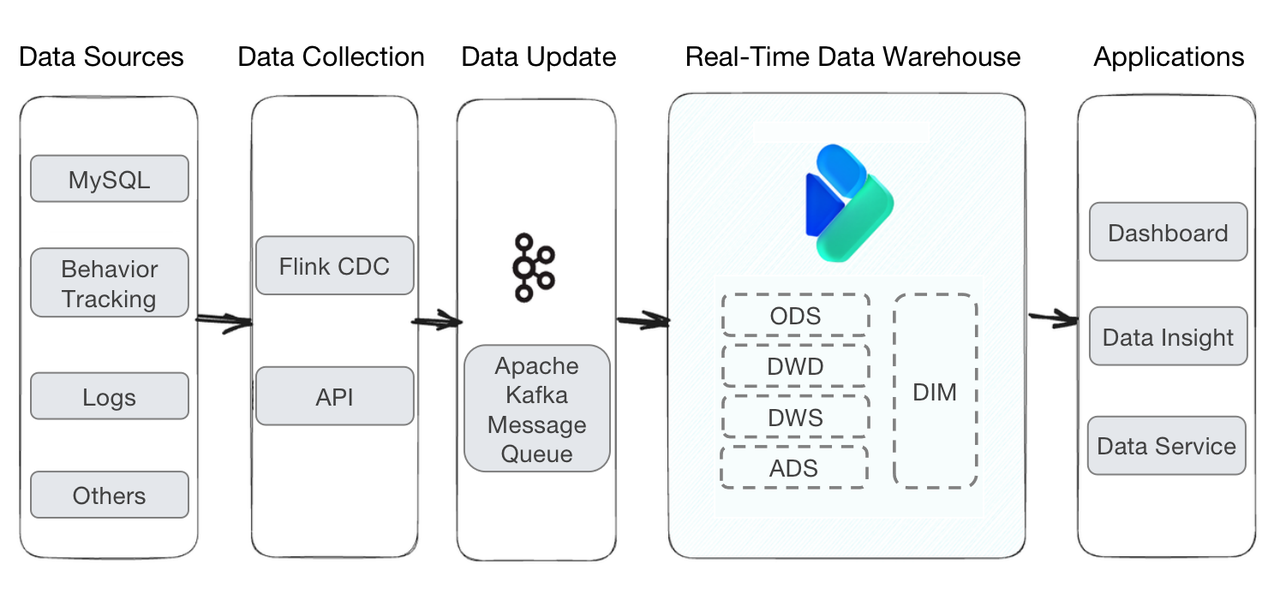
Connecting data sources to the data warehouse is simple, too. The key component, Apache Doris, supports various data loading methods to fit with different data sources. You can perform column mapping, transforming, and filtering during data loading to avoid duplicate collection of data. To ingest a table, users only need to add the table name to the configurations, instead of writing a script themselves.
Data Update
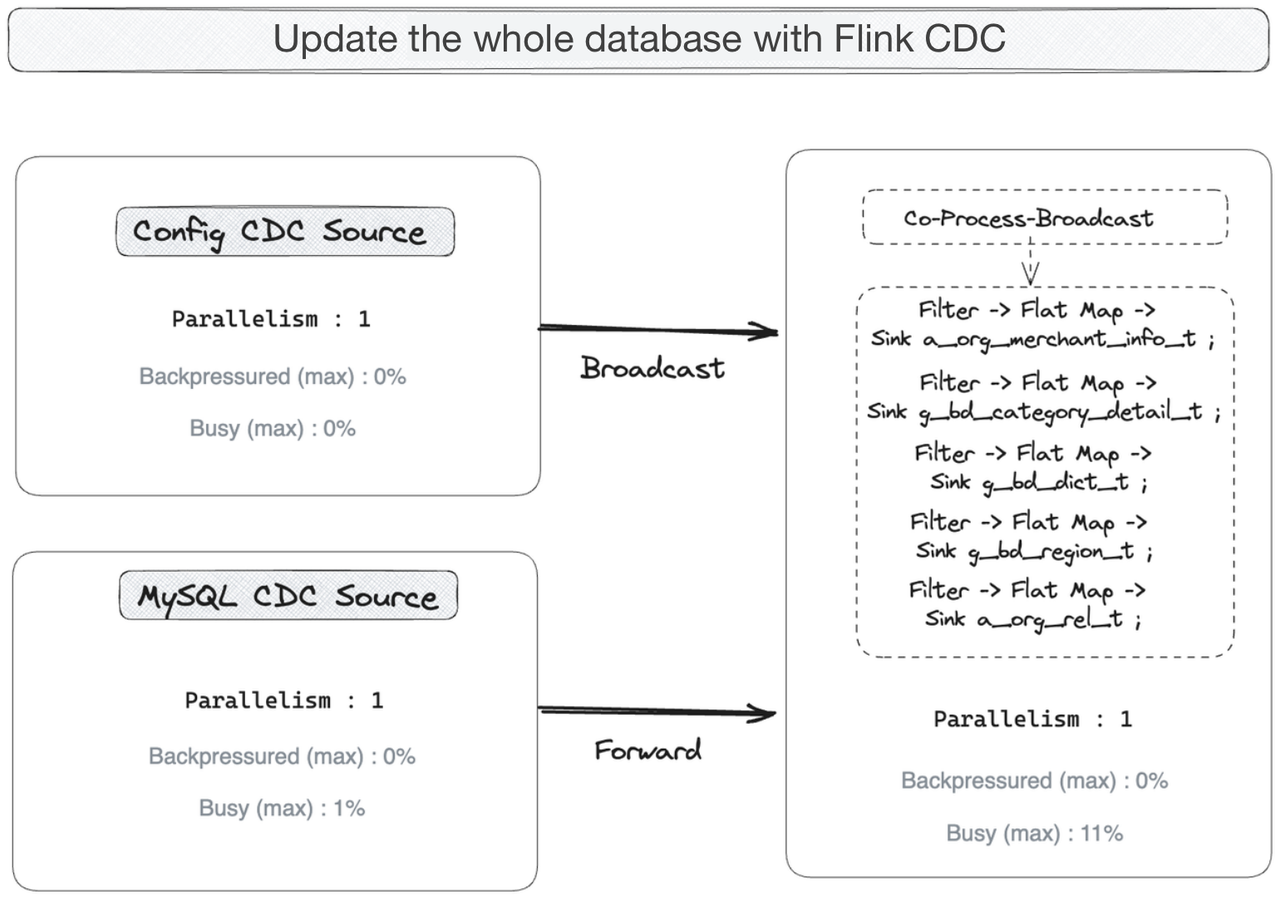
Flink CDC was found to be the optimal choice if you are looking for higher stability in data ingestion. It also allows you to update the dynamically changing tables in real time. The process includes the following steps:
- Configure Flink CDC for the source MySQL database, so that it allows dynamic updating of the table management configurations (which you can think of as the "metadata").
- Create two CDC jobs in Flink, one to capture the changed data (the Forward stream), the other to update the table management configurations (the Broadcast stream).
- Configure all tables of the source database at the Sink end (the output end of Flink CDC). When there is newly added table in the source database, the Broadcast stream will be triggered to update the table management configurations. (You just need to configure the tables, instead of "creating" the tables.)
Layering of Data Warehouse
Data flows from various sources into the data warehouse, where it is cleaned and organized before it is ready for queries and analysis. The data processing here is divided into five typical layers. Such layering simplifies the data cleaning process because it provides a clear division of labor and makes things easier to locate and comprehend.
- ODS: This is the prep zone of the data warehouse. The unprocessed original data is put in the Unique Key Model of Apache Doris, which can avoid duplication of data.
- DWD: This layer cleans, formats, and de-identifies data to produce fact tables. Every detailed data record is preserved. Data in this layer is also put into the Unique Key Model.
- DWS: This layer produces flat tables of a certain theme (order, user, etc.) based on data from the DWD layer.
- ADS: This layer auto-aggregates data, which is implemented by the Aggregate Key Model of Apache Doris.
- DIM: The DIM layer accommodates dimension data (in this case, data about the theaters, projects, and show sessions, etc.), which is used in combination with the order details.
After the original data goes through these layers, it is available for queries via one data export interface.
Reporting
Like many non-tech business, the ticketing service provider needs a data warehouse mainly for reporting. They derive trends and patterns from all kinds of data reports, and then figure out ways towards efficient management and sales increase. Specifically, this is the information they are observing in their reports:
- Statistical Reporting: These are the most frequently used reports, including sales reports by theater, distribution channel, sales representative, and show.
- Agile Reporting: These are reports developed for specific purposes, such as daily and weekly project data reports, sales summary reports, GMV reports, and settlement reports.
- Data Analysis: This involves data such as membership orders, attendance rates, and user portraits.
- Dashboarding: This is to visually display sales data.
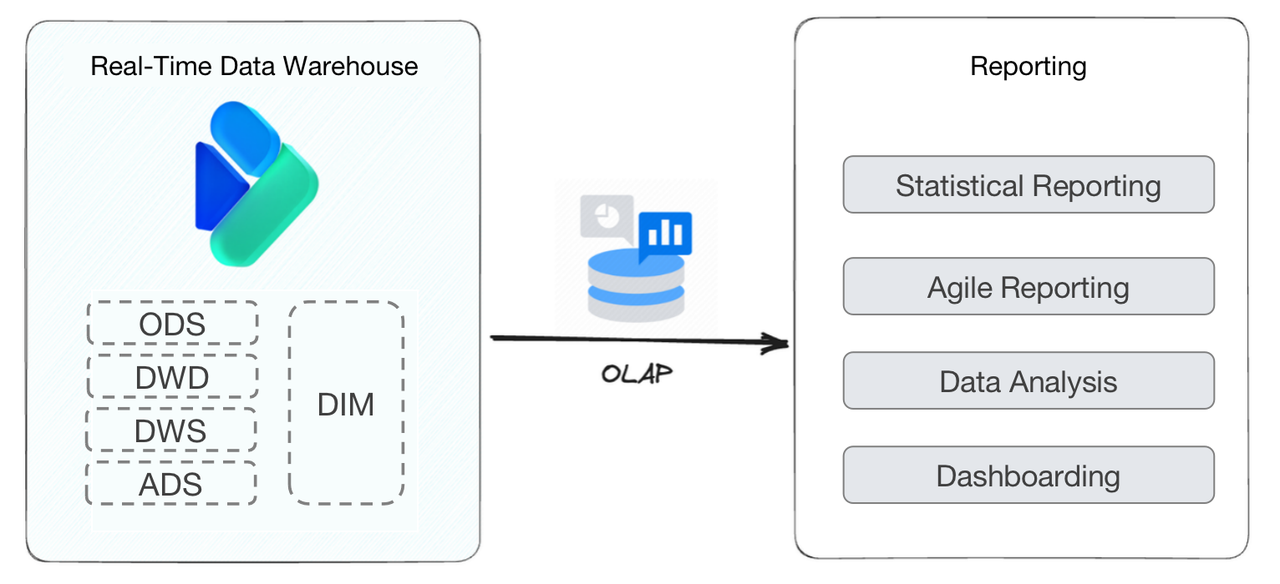
These are all entry-level tasks in data analytics. One of the biggest burdens for the data engineers was to quickly develop new reports as the internal analysts required. The Aggregate Key Model of Apache Doris is designed for this.
Quick aggregation to produce reports on demand
For example, supposing that analysts want a sales report by sales representatives, data engineers can produce that by simple configuration:
- Put the original data in the Aggregate Key Model
- Specify the sales representative ID column and the payment date column as the Key columns, and the order amount column as the Value column
Then, order amounts of the same sale representative within the specified period of time will be auto-aggregated. Bam! That's the report you need!
According to the user, this whole process only takes them 10~30 minutes, depending on the complexity of the report required. So the Aggregate Key Model largely releases data engineers from the pressure of report development.
Quick response to data queries
Most data analysts would just want their target data to be returned the second they need it. In this case, the user often leverages two capabilities of Apache Doris to realize quick query response.
Firstly, Apache Doris is famously fast in Join queries. So if you need to extract information across multiple tables, you are in good hands. Secondly, in data analysis, it often happens that analysts frequently input the same request. For example, they frequently want to check the sales data of different theaters. In this scenario, Apache Doris allows you to create a Materialized View, which means you pre-aggregate the sales data of each theater, and store this table in isolation from the original tables. In this way, every time you need to check the sales data by theater, the system directly goes to the Materialized View and reads data from there, instead of scanning the original table all over again. This can increase query speed by orders of magnitudes.
Conclusion
This is the overview of a simple data architecture and how it can provide the data services you need. It ensures data ingestion stability and quality with Flink CDC, and quick data analysis with Apache Doris. The deployment of this architecture is simple, too. If you plan for a data analytic upgrade for your business, you might refer to this case. If you need advice and help, you may join our community here.