The Efficiency of the data warehouse greatly improved in LY Digital"
Guide: Established in 2015, LY Digital is a financial service platform for tourism industry under LY. Com. In 2020, LY Digital introduced Apache Doris to build a data warehouse because of its rich data import methods, excellent parallel computing capabilities, and low maintenance costs. This article describes the evolution of data warehouse in LY Digital and why we switch to Apache Doris. I hope you like it.
Author: XingWang, Lead Developer of LY Digital

1.1 About LY Digital
LY Digital is a tourism financial service platform under LY. Com. Formally established in 2015, LY Digital takes "Digital technology empowers the tourism industry." as its vision. At present, LY Digital's business covers financial services, consumer financial services, financial technology and digital technology. So far, more than 10 million users and 76 cities have enjoyed our services.
1.2 Requirements for Data Warehouse
- Dashboard: Needs dashboard for T+1 business, etc.
- Early Warning System: Needs risk control, anomaly capital management and traffic monitoring, etc.
- Business Analysis: Needs timely data query analysis and temporary data retrieval, etc.
- Finance: Needs liquidation and payment reconciliation.
2. Previous Data Warehouse
2.1 Architecture
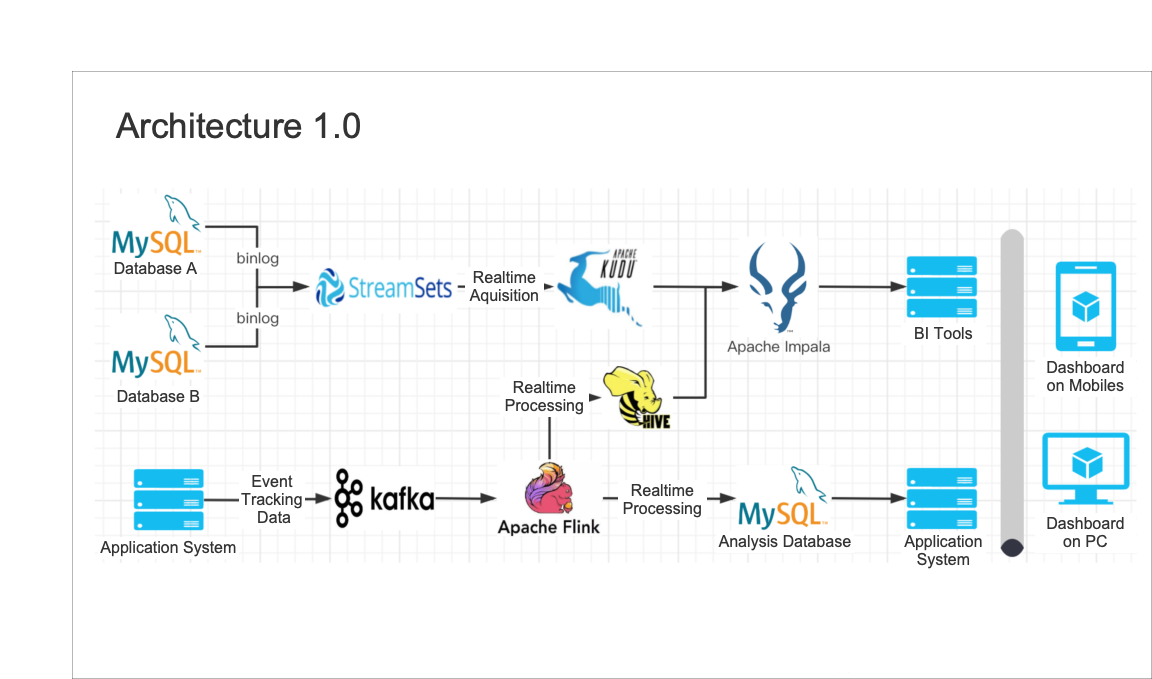
Our previous data warehouse adopted the combination of SteamSets and Apache Kudu, which was very popular in the past few years. In this architecture, Binlog is ingested into Apache Kudu after passing through StreamSets in real-time, and is finally queried and used through Apache Impala and visualization tools.
2.1.2 Downside
- The previous data warehouse has a sophisticated structure that consists of many components that interact with one another, which requires huge operation and maintenance costs.
- The previous data warehouse has a sophisticated structure that consists of many components that interact with one another, which requires huge operation and maintenance costs.
- Apache Kudu's performance in wide tables Join is not so good.
- SLA is not fully guaranteed because tenant isolation is not provided.
- Although SteamSets are equipped with early warning capabilities, job recovery capabilities are still poor. When configuring multiple tasks, the JVM consumes a lot, resulting in slow recovery.
3. New Data Warehouse
3.1 Research of Popular Data Warehouses
Due to so many shortcomings, we had to give up the previous data warehouse. In 2020, we conducted an in-depth research on the popular data warehouses in the market.
During the research, we focused on comparing Clickhouse and Apache Doris. ClickHouse has a high utilization rate of CPU, so it performs well in single-table query. But it does not perform well in multitable Joins and high QPS. On the other hand, Doris can not only support thousands of QPS per node. Thanks to the function of partitioning, it can also support high-concurrency queries at the QPS level of 10,000. Moreover, the horiziontal scaling in and out of ClickHouse are complex, which cannot be done automatically at present. Doris supports online dynamic scaling, and can be expanded horizontally according to the development of the business.
In the research, Apache Doris stood out. Doris's high-concurrency query capability is very attractive. Its dynamic scaling capabilities are also suitable for our flexible advertising business. So we chose Apache Doris for sure.
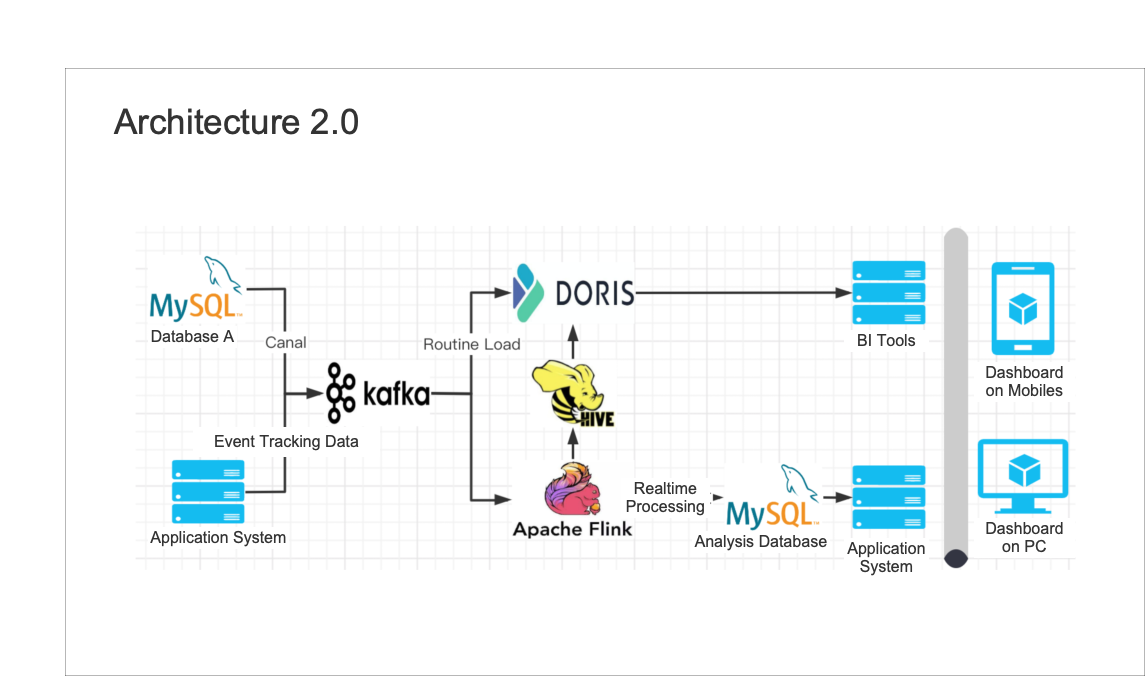
After introducing Apache Doris, we upgraded the entire data warehouse:
- We collect MySQL Binlog through Canal and then it is ingested into Kafka. Because Apache Doris is highly capatible with Kafka, we can easily use Routine Load to load and import data.
- We have made minor adjustments to the batch processing. For data stored in Hive, Apache Doris can ingest data from Hive through Broker Load. In this way, the data in batch processing can be directly ingested into Doris.
3.2 Why We Choose Doris
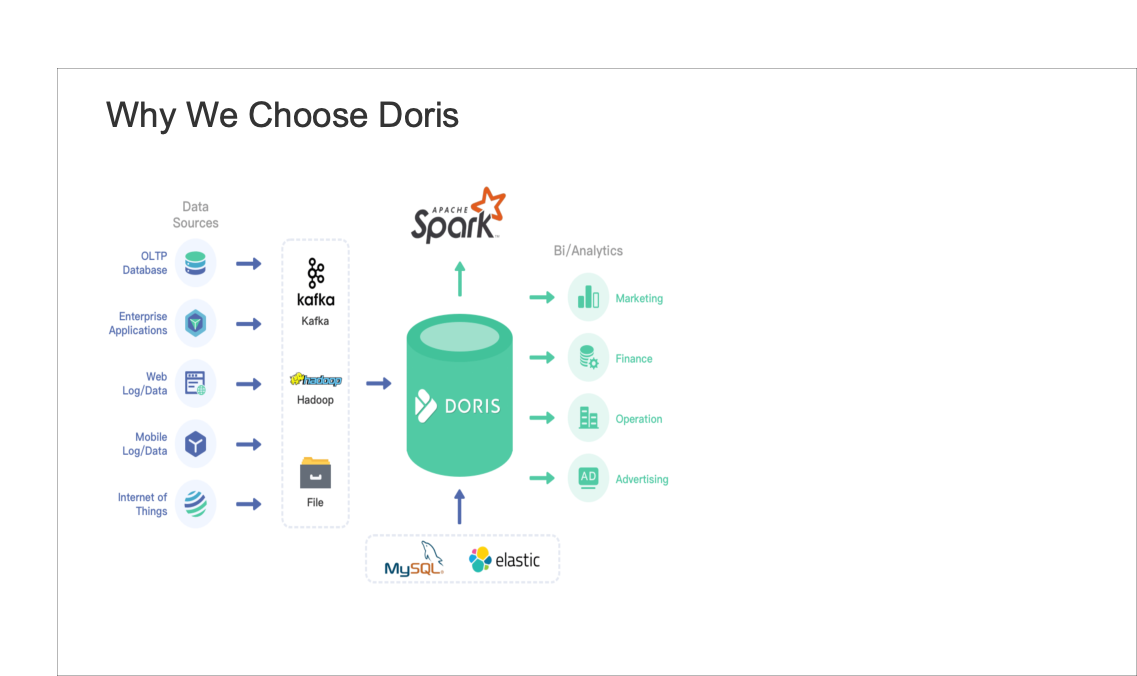
The overall performance of Apache Doris is impressive:
- Data access: It provides rich data import methods and can support the access of many types of data sources;
- Data connection: Doris supports JDBC and ODBC connections. And it can easily connect with BI tools. In addition, Doris uses the MySQL protocol for communication. Users can directly access Doris through various Client tools;
- SQL syntax: Doris adopts MySQL protocol and it is highly compatible with MySQL syntax, supporting standard SQL, and is low in learning costs for developers;
- MPP parallel computing: Doris provides excellent parallel computing capabilities and has obvious advantages in complex Join and wide table Join;
- Fully-completed documentation: Doris official documentation is very profound, which is friendly for new users.
3.3 Architecture of Real-time Processing
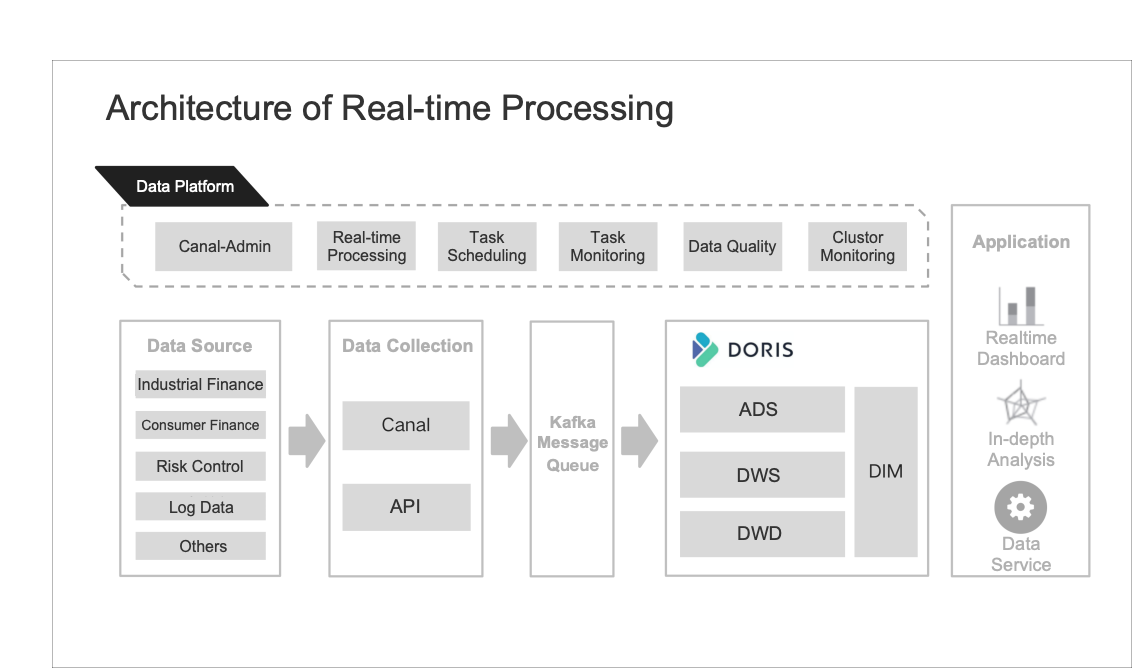
- Data source: In real-time processing, data sources come from business branches such as industrial finance, consumer finance, and risk control. They are all collected through Canal and API.
- Data collection: After data collection through Canal-Admin, Canal sends the data to Kafka message queue. After that, the data is ingested into the Doris through Routine Load.
- Inside Doris: The Doris cluster constitutes a three-level layer of the data warehouse, namely: the DWD layer with the Unique model, the DWS layer with the Aggregation model, and the ADS application layer.
- Data application: The data is applied in three aspects: real-time dashboard, data timeliness analysis and data service.
3.4 New Features
The data import method is simple and adopts 3 different import methods according to different scenarios:
- Routine Load: When we submit the Rountine Load task, there will be a process within Doris that consumes Kafka in real time, continuously reads data from Kafka and ingestes it into Doris.
- Broker Load: Offline data such as dim-tables and historical data are ingested into Doris in an orderly manner.
- Insert Into: Used for batch processing tasks, Insert into is responsible for processing data in the DWD layer
Doris' data model improves our development efficiency:
- The Unique model is used when accessing the DWD layer, which can effectively prevent repeated consumption of data.
- In Doris, aggregation supports 4 models, such as Sum, Replace, Min, and Max. In this way, it may reduce a large amount of SQL code, and no longer allow us to manually write Sum, Min, Max and other codes.
Doris query is efficient:
- It supports materialized view and Rollup materialized index. The bottom layer of the materialized view is similar to the concept of Cube and the precomputation process. As a way of exchanging space for time, special tables are generated at the bottom layer. In the query, materialized view maps to the tables and responds quickly.
4. Benefits of the New Data Warehouse
- Data access: In the previous architecture, the Kudu table needs to be created manually during the imports through SteamSets. Lack of tools, the entire process of creating tables and tasks takes 20-30 minutes. Nowadays, fast data access can be realized through the platform. The access process of each table has been shortened from the previous 20-30 minutes to the current 3-5 minutes, which is to say that the performance has been improved by 5-6 times.
- Data development: After using Doris, we can directly use the data models, such as Unique and Aggregation. The Duplicate model can well support logs, greatly speeding up the development process in ETL.
- Query analysis: The bottom layer of Doris has functions such as materialized view and Rollup materialized index. Moreover, Doris has made many optimizations for wide table associations, such as Runtime Filter and other Joins. Compared with Doris, Apache Kudu requires more complex optimization to be better used.
- Data report: It took 1-2 minutes to complete the rendering when we used Kudu to query before, but Doris responded in seconds or even milliseconds.
- Easy maintenance: Doris is not as complex as Hadoop. In March, our IDC was relocated, and 12 Doris virtual machines were all migrated within three days. The overall operation is relatively simple. In addition to physically moving the machine, FE's scaling only requires simple commands such as Add and Drop, which do not take a long time to do.
5. Look ahead
- Realize data access based on Flink CDC: At present, Flink CDC is not introduced, but Kafka through Canal instead. The development efficiency can be even faster if we use Flink CDC. Flink CDC still needs us to write a certain amount of code, which is not friendly for data analysts to use directly. We hope that data analysts only need to write simple SQL or directly operate. In the future planning, we plan to introduce Flink CDC.
- Keep up with the latest release: Now the latest version Apache Doris V1.2.0 has made great achievements in vectorization, multi-catalog, and light schema change. We will keep up with the community to upgrade the cluster and make full use of new features.
- Strengthen the construction of related systems: Our current index system management, such as report metadata, business metadata, and other management levels still need to be improved. Although we have data quality monitoring functions, it still needs to be strengthened and improved in automation.