The application of Apache Doris in NIO

Guide: The topic of this sharing is the application of Apache Doris in NIO, which mainly includes the following topics:
- Introduction about NIO
- The Development of OLAP in NIO
- Apache Doris-the Unified OLAP Data warehouse
- Best Practice of Apache Doris on CDP Architecture
- Summery and Benefits
Author:Huaidong Tang, Data Team Leader, NIO INC
About NIO
NIO Inc. (NYSE: NIO)is a leading company in the premium smart electric vehicle market. Founded in November 2014, NIO designs, develops, jointly manufactures and sells premium smart electric vehicles, driving innovations in autonomous driving, digital technologies, electric powertrains and batteries.
Recently, NIO planned to enter the U.S. market alongside other western markets by the end of 2025. The company has already established a U.S. headquarters in San Jose, California, where they started hiring people.
The Architecture Evolution of OLAP in NIO
The architectural evolution of OLAP in NIO took several steps for years.
1. Introduced Apache Druid
At that time, there were not so many OLAP storage and query engines to choose from. The more common ones were Apache Druid and Apache Kylin. There are 2 reasons why we didn't choose Kylin.
-
The most suitable and optimal storage at the bottom of Kylin is HBase and adding it would increase the cost of operation and maintenance.
-
Kylin's precalculation involves various dimensions and indicators. Too many dimensions and indicators would cause great pressure on storage.
We prefer Druid because we used to be users and are familiar with it. Apache Druid has obvious advantages. It supports real-time and offline data import, columnar storage, high concurrency, and high query efficiency. But it has downsides as well:
-
Standard protocols such as JDBC are not used
-
The capability of JOIN is weak
-
Significant performance downhill when performing dedeplication
-
High in operation and maintenance costs, different components have separate installation methods and different dependencies; Data import needs extra integration with Hadoop and the dependencies of JAR packages
2. Introduced TiDB
TiDB is a mature datawarehouse focused on OLTP+OLAP, which also has distinctive advantages and disadvantages:
Advantage:
-
OLTP database, can be updated friendly
-
Supports detailed and aggregated query, which can handle dashboard statistical reports or query of detailed data at the same time
-
Supports standard SQL, which has low cost of use
-
Low operation and maintenance cost
Disadvantages:
-
It is not an independent OLAP. TiFlash relies on OLTP and will increase storage. Its OLAP ability is insufficient
-
The overall performance should be measured separately by each scene
3. Introduced Apache Doris
Since 2021, we have officially introduced Apache Doris. In the process of selection, we are most concerned about various factors such as product performance, SQL protocol, system compatibility, learning and operation and maintenance costs. After deep research and detailed comparison of the following systems, we came to the following conclusions:
Apache Doris, whose advantages fully meet our demands:
-
Supports high concurrent query (what we concerned most)
-
Supports both real-time and offline data
-
Supports detailed and aggregated query
-
UNIQ model can be updated
-
The ability of Materialized View can greatly speed up query efficiency
-
Fully compatible with the MySQL protocol and the cost of development is relatively low
-
The performance fully meets our requirements
-
Lower operation and maintenance costs
Moreover, there is another competitor, Clickhouse. Its stand-alone performance is extremely strong, but its disadvantages are hard to accept:
-
In some cases, its multi-table JOIN is weak
-
Relatively low in concurrency
-
High operation and maintenance costs
With multiple good performances, Apache Doris outstands Druid and TiDB. Meanwhile Clickhouse did not fit well in our business, which lead us to Apache Doris.
Apache Doris-the Unified OLAP Datawarehouse
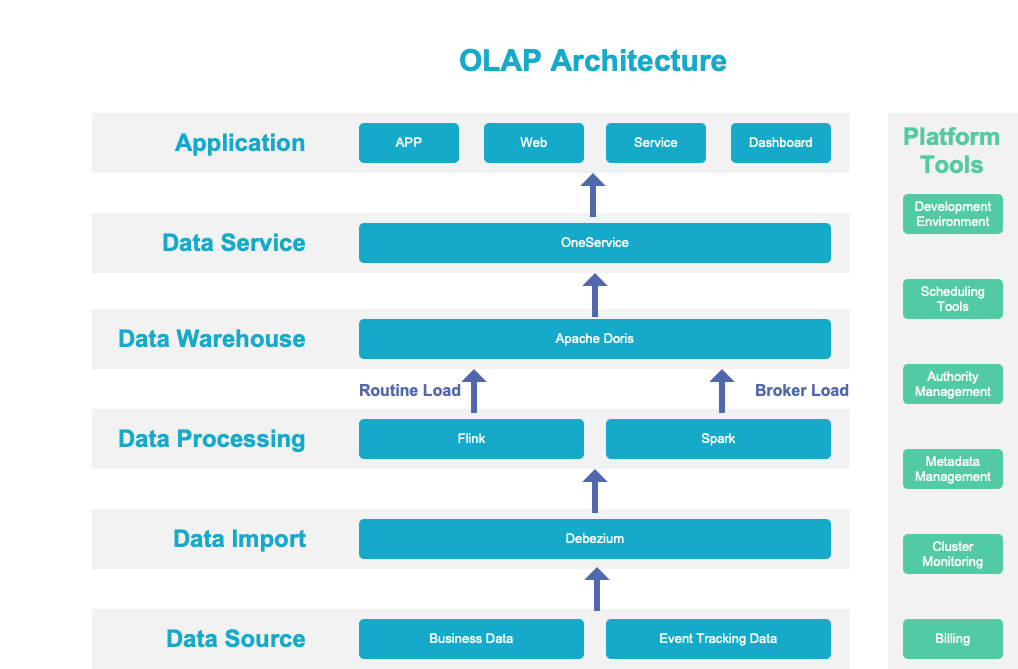
This diagram basically describes our OLAP Architecuture, including data source, data import, data processing, data warehouse, data service and application.
1. Data Source
In NIO, the data source not only refers to database, but also event tracking data, device data, vehicle data, etc. The data will be ingested into the big data platform.
2. Data Import
For business data, you can trigger CDC and convert it into a data stream, store it in Kafka, and then perform stream processing. Some data that can only be passed in batches will directly enter our distributed storage.
3. Data Processing
We took the Lambda architecture rather than stream-batch integration.
Our own business determines that our Lambda architecture should be divided into two paths: offline and real-time:
-
Some data is streamed.
-
Some data can be stored in the data stream, and some historical data will not be stored in Kafka.
-
Some data requires high precision in some circumstances. In order to ensure the accuracy of the data, an offline pipeline will recalculate and refresh the entire data.
4. Data Warehouse
From data processing to the data warehouse, we did not adopt Flink or Spark Doris Connector. We use Routine Load to connect Apache Doris and Flink, and Broker Load to connect Doris and Spark. The data generated in batches by Spark will be backed up to Hive for further use in other scenarios. In this way, each calculation is used for multiple scenarios at the same time, which greatly improves the efficiency. It also works for Flink.
5. Data Service
What behind Doris is One Service. By registering the data source or flexible configuration, the API with flow and authority control is automatically generated, which greatly improves flexibility. And with the k8s serverless solution, the entire service is much more flexible.
6. Application
In the application layer, we mainly deploy some reporting applications and other services.
We mainly have two types of scenarios:
-
User-oriented , which is similar to the Internet, contains a data dashboard and data indicators.
-
Car-oriented , car data enters Doris in this way. After certain aggregation, the volume of Doris data is about billions. But the overall performance can still meet our requirements.
Best Practice of Apache Doris on CDP Architecture
1. CDP Architecture
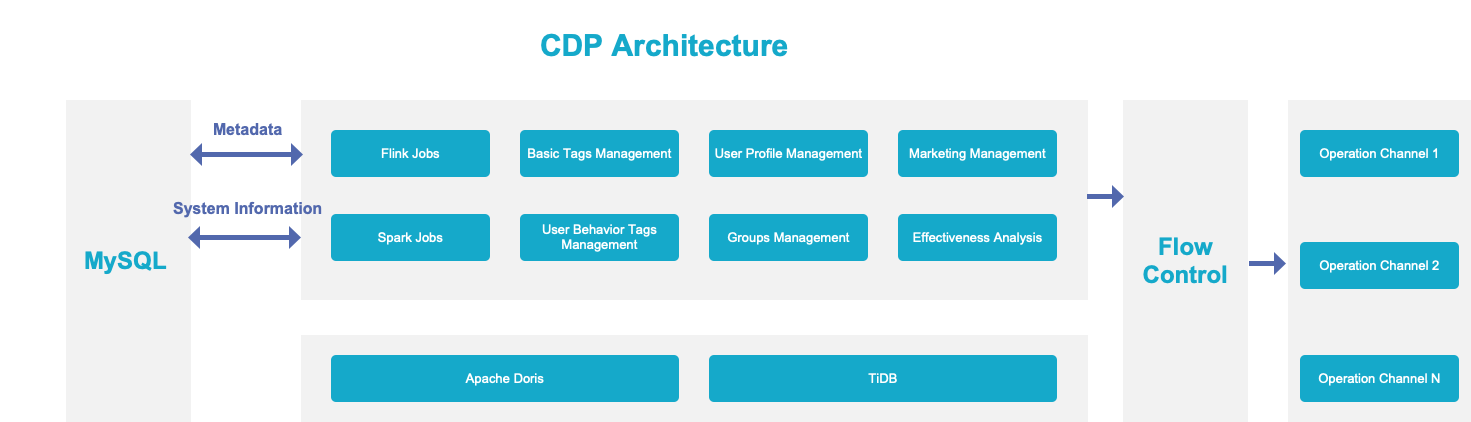
Next, let me introduce Doris' practice on the operating platform. This is what happens in our real business. Nowadays, Internet companies will make their own CDP, which includes several modules:
-
Tags , which is the most basic part.
-
Target , based on tags, select people according to some certain logic.
-
Insight , aiming at a group of people, clarify the distribution and characteristics of the group.
-
Touch , use methods such as text messages, phone calls, voices, APP notifications, IM, etc. to reach users, and cooperate with flow control.
-
Effect analysis, to improve the integrity of the operation platform, with action, effect and feedback.
Doris plays the most important role here, including: tags storage, groups storage, and effect analysis.
Tags are divided into basic tags and basic data of user behavior. We can flexibly customize other tags based on those facts. From the perspective of time effectiveness, tags are also divided into real-time tags and offline tags.
2. Considerations for CDP Storage Selection
We took five dimensions into account when we select CDP storage.
(1) Unification of Offline and Real-time
As mentioned earlier, there are offline tags and real-time tags. Currently we are close to quasi-real-time. For some data, quasi-real-time is good enough to meet our needs. A large number of tags are still offline tags. The methods used are Doris's Routine Load and Broker Load.
| Scenes | Requirements | Apache Doris's Function |
|---|---|---|
| Real-time tags | Real-time data updates | Routine Load |
| Offline tags | Highly efficient batch import | Broker Load |
| Unification of offline and real-time | Unification of offline and real-time data storage | Routine Load and Broker Load update different columns of the same table |
In addition, on the same table, the update frequency of different columns is also different. For example, we need to update the user's identity in real time because the user's identity changes all the time. T+1's update does not meet our needs. Some tags are offline, such as the user's gender, age and other basic tags, T+1 update is sufficient to meet our standards. The maintenance cost caused by putting the tags of basic users on the same table is very low. When customizing tags later, the number of tables will be greatly reduced, which benefits the overall performance.
(2) Efficient Targets
When users tags are done, is time to target right group of people. The target is to filter out all the people who meet the conditions according to different combinations of tags. At this time, there will be queries with different combinations of tag conditions. There was an obvious improvement when Apache Doris upgraded to vectorization.
| Scenes | Requirements | Apache Doris's Function |
|---|---|---|
| Complex Condition Targets | Highly efficient combination of tags | Optimization of SIMD |
(3) Efficient Polymerization
The user insights and effect analysis statistics mentioned above require statistical analysis of the data, which is not a simple thing of obtaining tags by user ID. The amount of data read and query efficiency have a great impact on the distribution of our tags, the distribution of groups, and the statistics of effect analysis. Apache Doris helps a lot:
-
Data Partition. We shard the data by time order and the analysis and statistics will greatly reduce the amount of data, which can greatly speed up the efficiency of query and analysis.
-
Node aggregation. Then we collect them for unified aggregation.
-
Vectorization. The vectorization execution engine has significant performance improvement.
| Scenes | Requirements | Apache Doris's Function |
|---|---|---|
| Distribution of Tags Values | The distribution values of all tags need to be updated every day. Fast and efficient statistics are required | Data partition lessens data transfer and calculation |
| Distribution of Groups | Same as Above | Unified storage and calculation, each node aggregates first |
| Statistics for Performance Analysis | Same as Above | Speed up SIMD |
(4) Multi-table Association
Our CDP might be different from common CDP scenarios in the industry, because common CDP tags in some scenarios are estimated in advance and no custom tags, which leaves the flexibility to users who use CDP to customize tags themselves. The underlying data is scattered in different database tables. If you want to create a custom tag, you must associate the tables.
A very important reason we chose Doris is the ability to associate multiple tables. Through performance tests, Apache Doris is able to meet our requirements. And Doris provides users with powerful capabilities because tags are dynamic.
| Scenes | Requirements | Apache Doris's Function |
|---|---|---|
| Distributed Characteristics of the Population | The distribution of statistical groups under a certain characteristic | Table Association |
| Single Tag | Display tags |
(5) Query Federation
Whether the user is successfully reached or not will be recorded in TiDB. Notifications during operations may only affect user experience. If a transaction is involved, such as gift cards or coupons, the task execution must be done without repetition. TiDB is more suitable for this OLTP scenario.
But for effect analysis, it is necessary to understand the extent to which the operation plan is implemented, whether the goal is achieved and its distribution. It is necessary to combine task execution and group selection for analysis, which requires the query association between Doris and TiDB.
The size of the tag is probably small, so we would like to save it into Elasticsearch. However, it proves us wrong later.
| Scenes | Requirements | Apache Doris's Function |
|---|---|---|
| Effect Analysis Associated with Execution Details | Doris query associated with TiDB | Query Association with other databases |
| Group Tags Associated with Behavior Aggregation | Doris query associated with Elasticsearch |
Summery and Benefits
-
bitmap. Our volume are not big enough to test its full efficiency. If the volume reaches a certain level, using bitmap might have a good performance improvement. For example, when calculating UV , bitmap aggregation can be considered if the full set of Ids is greater than 50 million.
-
The performance is good when Elasticsearch single-table query is associated with Doris.
-
Better to update columns in batches. In order to reduce the number of tables and improve the performance of the JOIN table, the table designed should be as streamlined as possible and aggregated as much as possible. However, fields of the same type may have different update frequencies. Some fields need to be updated at daily level, while others may need to be updated at hourly level. Updating a column alone is an important requirement. The solution from Apache Doris is to use REPLACE_IF_NOT_NULL. Note: It is impossible to replace the original non-null value with null. You can replace all nulls with meaningful default values, such as unknown.
-
Online Services. Apache Doris serves online and offline scenarios at the same time, which requires high resource isolation.