Financial data warehousing: fast, secure, and highly available with Apache Doris
This is a whole-journey guide for Apache Doris users, especially those from the financial sector which requires a high level of data security and availability. If you don't know how to build a real-time data pipeline and make the most of the Apache Doris functionalities, start with this post and you will be loaded with inspiration after reading.
This is the best practice of a non-banking payment service provider that serves over 25 million retailers and processes data from 40 million end devices. Data sources include MySQL, Oracle, and MongoDB. They were using Apache Hive as an offline data warehouse but feeling the need to add a real-time data processing pipeline. After introducing Apache Doris, they increase their data ingestion speed by 25 times, ETL performance by 312 times, and query execution speed by 10~15 times.
In this post, you will learn how to integrate Apache Doris into your data architecture, including how to arrange data inside Doris, how to ingest data into it, and how to enable efficient data updates. Plus, you will learn about the enterprise features that Apache Doris provides to guarantee data security, system stability, and service availability.
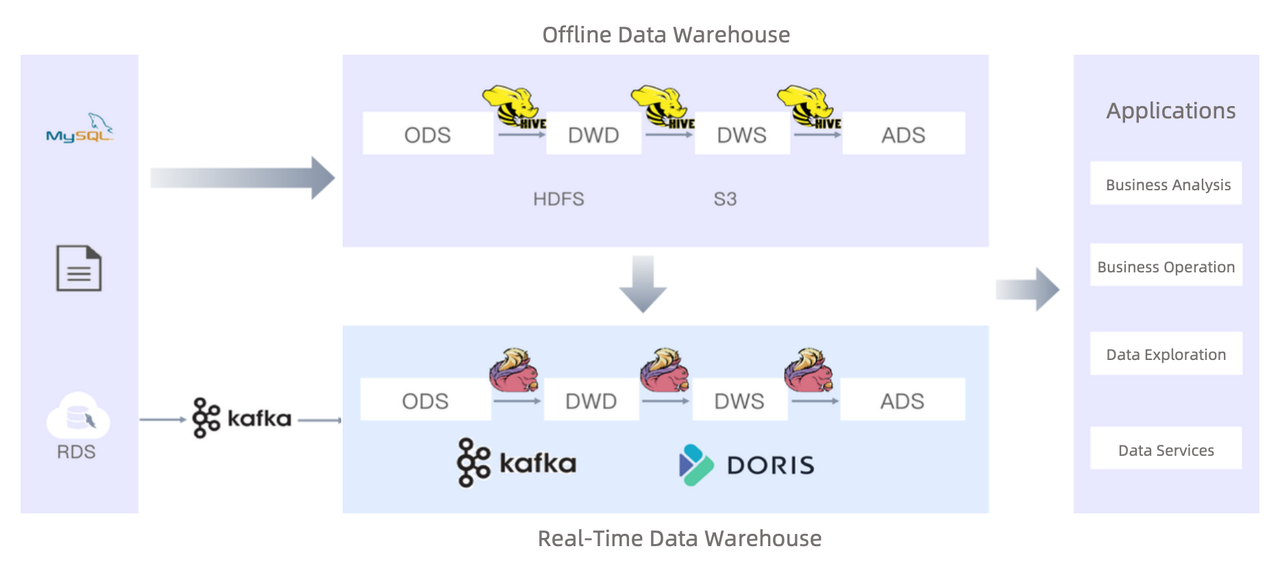
Building a real-time data warehouse with Apache Doris
Choice of data models
Apache Doris arranges data with three data models. The main difference between these models lies in whether or how they aggregate data.
- Duplicate Key model: for detailed data queries. It supports ad-hoc queries of any dimension.
- Unique Key model: for use cases with data uniqueness constraints. It supports precise deduplication, multi-stream upserts, and partial column updates.
- Aggregate Key model: for data reporting. It accelerates data reporting by pre-aggregating data.
The financial user adopts different data models in different data warehouse layers:
- ODS - Duplicate Key model: As a payment service provider, the user receives a million settlement data every day. Since the settlement cycle can span a whole year, the relevant data needs to be kept intact for a year. Thus, the proper way is to put it in the Duplicate Key model, which does not perform any data aggregations. An exception is that some data is prone to constant changes, like order status from retailers. Such data should be put into the Unique Key model so that the newly updated record of the same retailer ID or order ID will always replace the old one.
- DWD & DWS - Unique Key model: Data in the DWD and DWS layers are further abstracted, but it is all put in the Unique Key model so that the settlement data can be automatically updated.
- ADS - Aggregate Key model: Data is highly abstracted in this layer. It is pre-aggregated to mitigate the computation load of downstream analytics.
Partitioning and bucketing strategies
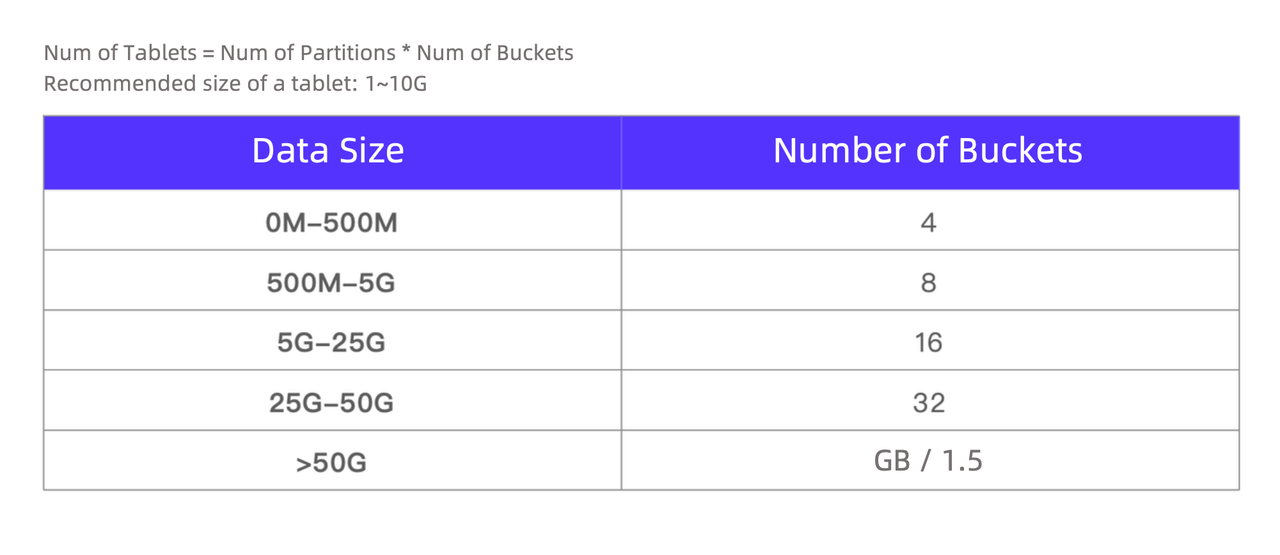
The idea of partitioning and bucketing is to "cut" data into smaller pieces to increase data processing speed. The key is to set an appropriate number of data partitions and buckets. Based on their use case, the user tailors the bucketing field and bucket number to each table. For example, they often need to query the dimensional data of different retailers from the retailer flat table, so they specify the retailer ID column as the bucketing field, and list the recommended bucket number for various data sizes.
Multi-source data migration
In the adoption of Apache Doris, the user had to migrate all local data from their branches into Doris, which was when they found out their branches were using different databases and had data files of very different formats, so the migration could be a mess.
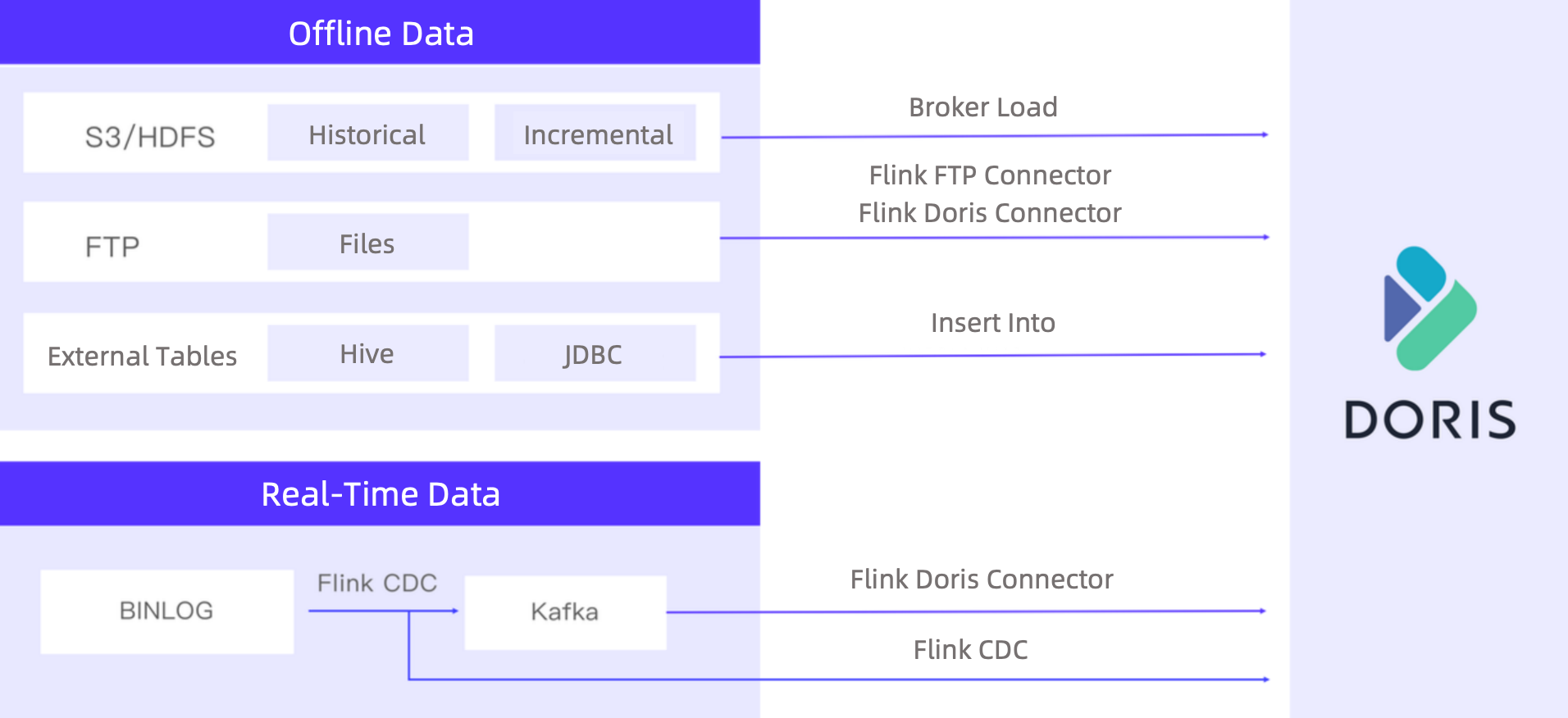
Luckily, Apache Doris supports a rich collection of data integration methods for both real-time data streaming and offline data import.
- Real-time data streaming: Apache Doris fetches MySQL Binlogs in real time. Part of them is written into Doris directly via Flink CDC, while the high-volume ones are synchronized into Kafka for peak shaving, and then written into Doris via the Flink-Doris-Connector.
- Offline data import: This includes more diversified data sources and data formats. Historical data and incremental data from S3 and HDFS will be ingested into Doris via the Broker Load method, data from Hive or JDBC will be synchronized to Doris via the Insert Into method, and files will be loaded to Doris via the Flink-Doris-Connector and Flink FTP Connector. (FTP is how the user transfers files across systems internally, so they developed the Flink-FTP-Connector to support the complicated data formats and multiple newline characters in data.)
Full data ingestion and incremental data ingestion
To ensure business continuity and data accuracy, the user figures out the following ways to ingest full data and incremental data:
- Full data ingestion: Create a temporary table of the target schema in Doris, ingest full data into the temporary table, and then use the
ALTER TABLE t1 REPLACE WITH TABLE t2statement for atomic replacement of the regular table with the temporary table. This method prevents interruptions to queries on the frontend.
alter table ${DB_NAME}.${TBL_NAME} drop partition IF EXISTS p${P_DOWN_DATE};
ALTER TABLE ${DB_NAME}.${TBL_NAME} ADD PARTITION IF NOT EXISTS p${P_DOWN_DATE} VALUES [('${P_DOWN_DATE}'), ('${P_UP_DATE}'));
LOAD LABEL ${TBL_NAME}_${load_timestamp} ...
- Incremental data ingestion: Create a new data partition to accommodate incremental data.
Offline data processing
The user has moved their offline data processing workload to Apache Doris and thus increased execution speed by 5 times.
- Before: The old Hive-based offline data warehouse used the TEZ execution engine to process 30 million new data records every day. With 2TB computation resources, the whole pipeline took 2.5 hours.
- After: Apache Doris finishes the same tasks within only 30 minutes and consumes only 1TB. Script execution takes only 10 seconds instead of 8 minutes.
Enterprise features for financial players
Multi-tenant resource isolation
This is required because it often happens that the same piece of data is requested by multiple teams or business systems. These tasks can lead to resource preemption and thus performance decrease and system instability.
Resource limit for different workloads
The user classifies their analytics workloads into four types and sets a resource limit for each of them. In particular, they have four different types of Doris accounts and set a limit on the CPU and memory resources for each type of account.

In this way, when one tenant requires excessive resources, it will only compromise its own efficiency but not affect other tenants.
Resource tag-based isolation
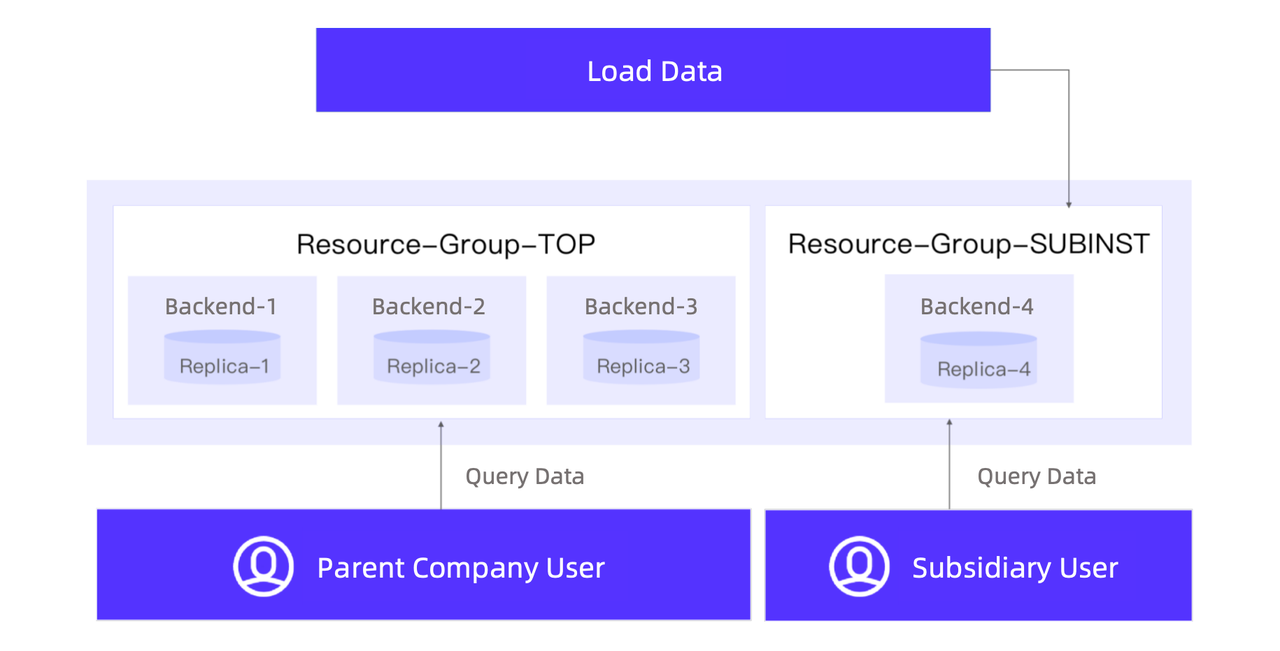
For data security under the parent-subsidiary company hierarchy, the user has set isolated resource groups for the subsidiaries. Data of each subsidiary is stored in its own resource group with three replicas, while data of the parent company is stored with four replicas: three in the parent company resource group, and the other one in the subsidiary resource group. Thus, when an employee from a subsidiary requests data from the parent company, the query will only executed in the subsidiary resource group. Specifically, they take these steps:
Workload group
The resource tag-based isolation plan ensures isolation on a physical level, but as Apache Doris developers, we want to further optimize resource utilization and pursue more fine-grained resource isolation. For these purposes, we released the Workload Group feature in Apache Doris 2.0.
The Workload Group mechanism relates queries to workload groups, which limit the share of CPU and memory resources of the backend nodes that a query can use. When cluster resources are in short supply, the biggest queries will stop execution. On the contrary, when there are plenty of available cluster resources and a workload group requires more resources than the limit, it will get assigned with the idle resources proportionately.
The user is actively planning their transition to the Workload Group plan and utilizing the task prioritizing mechanism and query queue feature to organize the execution order.
Fine-grained user privilege management
For regulation and compliance reasons, this payment service provider implements strict privilege control to make sure that everyone only has access to what they are supposed to access. This is how they do it:
- User privilege setting: System users of different subsidiaries or with different business needs are granted different data access privileges.
- Privilege control over databases, tables, and rows: The
ROW POLICYmechanism of Apache Doris makes these operations easy. - Privilege control over columns: This is done by creating views.

Cluster stability guarantee
- Circuit Breaking: From time to time, system users might input faulty SQL, causing excessive resource consumption. A circuit-breaking mechanism is in place for that. It will promptly stop these resource-intensive queries and prevent interruption to the system.
- Data ingestion concurrency control: The user has a frequent need to integrate historical data into their data platform. That involves a lot of data modification tasks and might stress the cluster. To solve that, they turn on the Merge-on-Write mode in the Unique Key model, enable Vertical Compaction and Segment Compaction, and tune the data compaction parameters to control data ingestion concurrency.
- Network traffic control: Considering their two clusters in different cities, they employ Quality of Service (QoS) strategies tailored to different scenarios for precise network isolation and ensuring network quality and stability.
- Monitoring and alerting: The user has integrated Doris with their internal monitoring and alerting platform so any detected issues will be notified via their messaging software and email in real time.
Cross-cluster replication
Disaster recovery is crucial for the financial industry. The user leverages the Cross-Cluster Replication (CCR) capability and builds a dual-cluster solution. As the primary cluster undertakes all the queries, the major business data is also synchronized into the backup cluster and updated in real time, so that in the case of service downtime in the primary cluster, the backup cluster will take over swiftly and ensure business continuity.
Conclusion
We appreciate the user for their active communication with us along the way and are glad to see so many Apache Doris features fit in their needs. They are also planning on exploring federated query, compute-storage separation, and auto maintenance with Apache Doris. We look forward to more best practice and feedback from them.