From Elasticsearch to Apache Doris: upgrading an observability platform
Observability platforms are akin to the immune system. Just like immune cells are everywhere in human bodies, an observability platform patrols every corner of your devices, components, and architectures, identifying any potential threats and proactively mitigating them. However, I might have gone too far with that metaphor, because till these days, we have never invented a system as sophisticated as the human body, but we can always make advancements.
The key to upgrading an observability platform is to increase data processing speed and reduce costs. This is based on two reasons:
- The faster you can identify abnormalities from your data, the more you can contain the potential damage.
- An observability platform needs to store a sea of data, and low storage cost is the only way to make that sustainable.
This post is about how GuanceDB, an observability platform, makes progress in these two aspects by replacing Elasticsearch with Apache Doris as its query and storage engine. The result is 70% less storage costs and 200%~400% data query performance.
GuanceDB
GuanceDB is an all-around observability solution. It provides services including data analytics, data visualization, monitoring and alerting, and security inspection. From GuanceDB, users can have an understanding of their objects, network performance, applications, user experience, system availability, etc.
From the standpoint of a data pipeline, GuanceDB can be divided into two parts: data ingestion and data analysis. I will get to them one by one.
Data integration
For data integration, GuanceDB uses its self-made tool called DataKit. It is an all-in-one data collector that extracts from different end devices, business systems, middleware, and data infrastructure. It can also preprocess data and relate it with metadata. It provides extensive support for data, from logs, and time series metrics, to data of distributed tracing, security events, and user behaviors from mobile APPs and web browsers. To cater to diverse needs across multiple scenarios, it ensures compatibility with various open-source probes and collectors as well as data sources of custom formats.
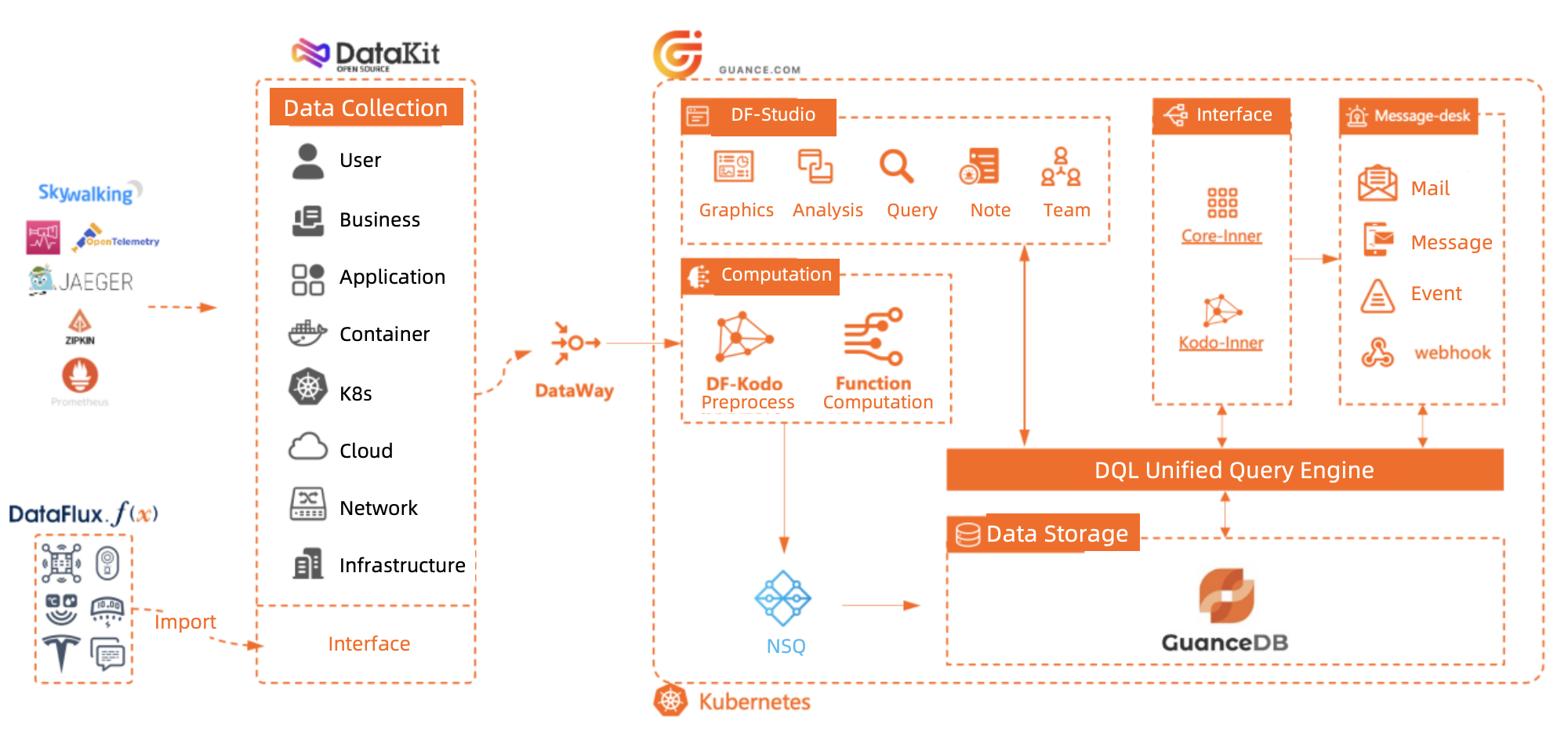
Query & storage engine
Data collected by DataKit, goes through the core computation layer and arrive in GuanceDB, which is a multil-model database that combines various database technologies. It consists of the query engine layer and the storage engine layer. By decoupling the query engine and the storage engine, it enables pluggable and interchangeable architecture.
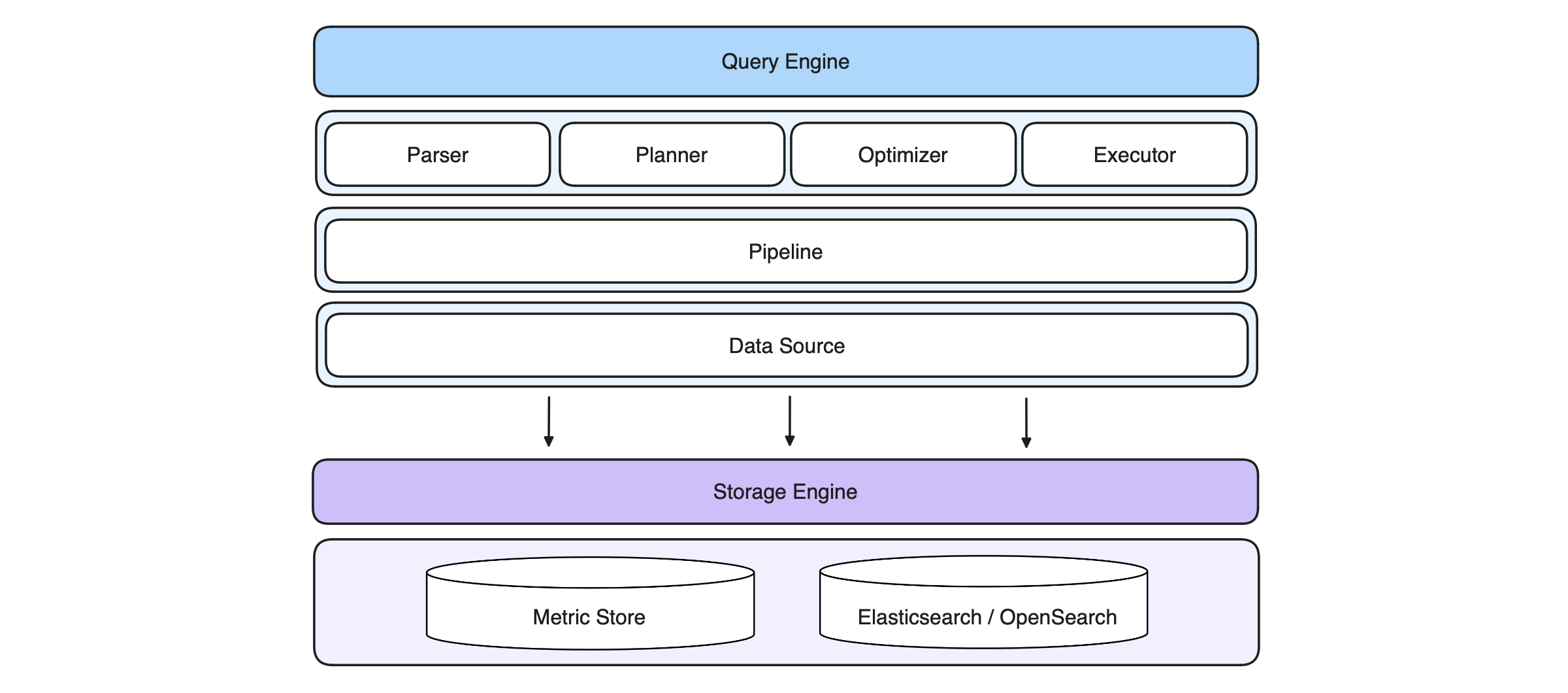
For time series data, they built Metric Store, which is a self-developed storage engine based on VictoriaMetrics. For logs, they integrate Elasticsearch and OpenSearch. GuanceDB is performant in this architecture, while Elasticsearch demonstrates room for improvement:
- Data writing: Elasticsearch consumes a big share of CPU and memory resources. It is not only costly but also disruptive to query execution.
- Schemaless support: Elasticsearch provides schemaless support by Dynamic Mapping, but that's not enough to handle large amounts of user-defined fields. In this case, it can lead to field type conflict and thus data loss.
- Data aggregation: Large aggregation tasks often trigger a timeout error in Elasticsearch.
So this is where the upgrade happens. GuanceDB tried and replaced Elasticsearch with Apache Doris.
DQL
In the GuanceDB observability platform, almost all queries involve timestamp filtering. Meanwhile, most data aggregations need to be performed within specified time windows. Additionally, there is a need to perform rollups of time series data on individual sequences within a time window. Expressing these semantics using SQL often requires nested subqueries, resulting in complex and cumbersome statements.
That's why GuanceDB developed their own Data Query Language (DQL). With simplified syntax elements and computing functions optimized for observability use cases, this DQL can query metrics, logs, object data, and data from distributed tracing.
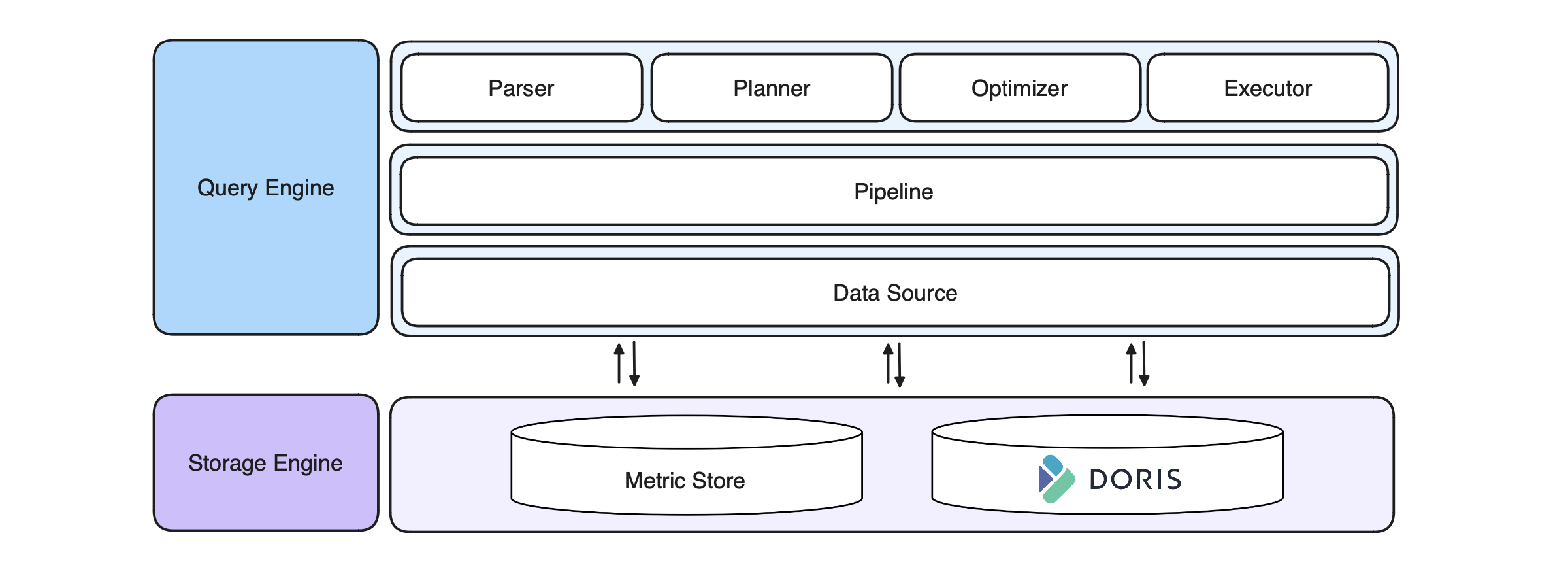
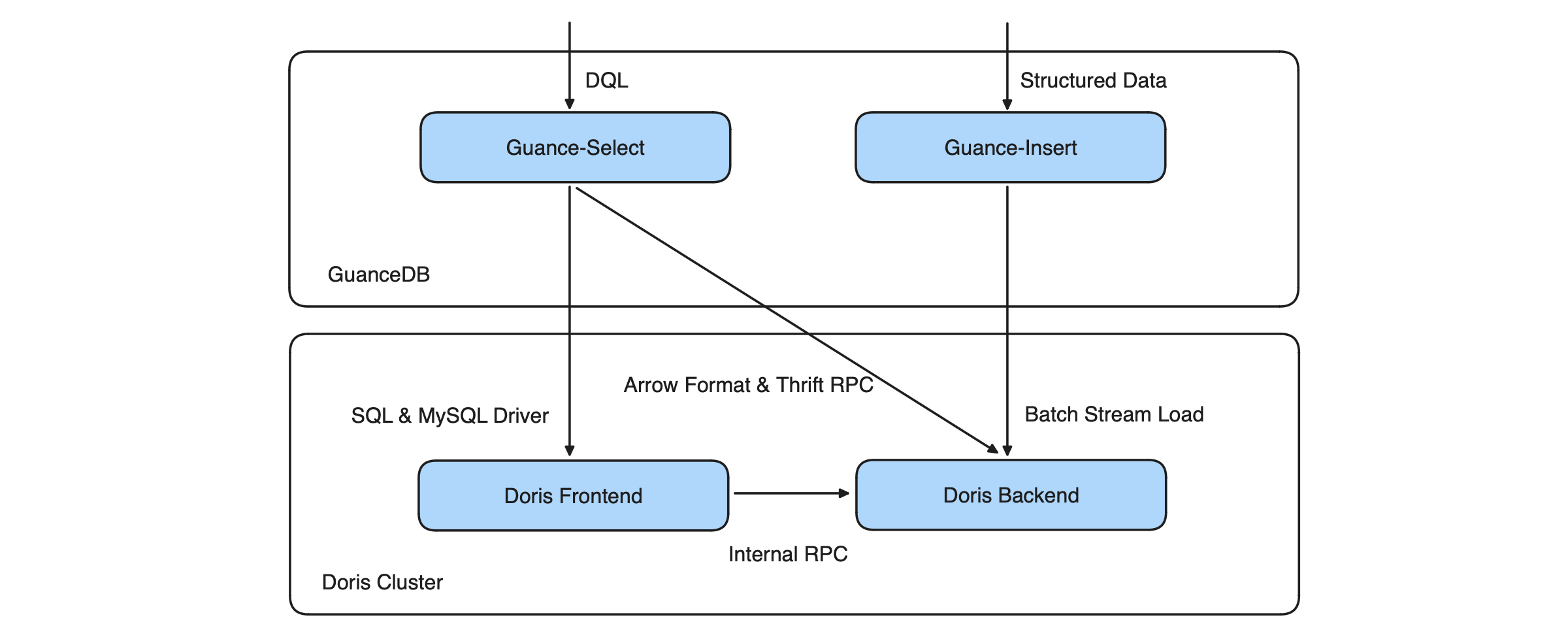
This is how DQL works together with Apache Doris. GuanceDB has found a way to make full use of the analytic power of Doris, while complementing its SQL functionalities.
As is shown below, Guance-Insert is the data writing component, while Guance-Select is the DQL query engine.
- Guance-Insert: It allows data of different tenants to be accumulated in different batches, and strikes a balance between writing throughput and writing latency. When logs are generated in large volumes, it can maintain a low data latency of 2~3 seconds.
- Guance-Select: For query execution, if the query SQL semantics or function is supported in Doris, Guance-Select will push the query down to the Doris Frontend for computation; if not, it will go for a fallback option: acquire columnar data in Arrow format via the Thrift RPC interface, and then finish computation in Guance-Select. The catch is that it cannot push the computation logic down to Doris Backend, so it can be slightly slower than executing queries in Doris Frontend.
Observations
Storage cost 70% down, query speed 300% up
Previously, with Elasticsearch clusters, they used 20 cloud virtual machines (16vCPU 64GB) and had independent index writing services (that's another 20 cloud virtual machines). Now with Apache Doris, they only need 13 cloud virtual machines of the same configuration in total, representing a 67% cost reduction. This is contributed by three capabilities of Apache Doris:
- High writing throughput: Under a consistent writing throughput of 1GB/s, Doris maintains a CPU usage of less than 20%. That equals 2.6 cloud virtual machines. With low CPU usage, the system is more stable and better prepared for sudden writing peaks.
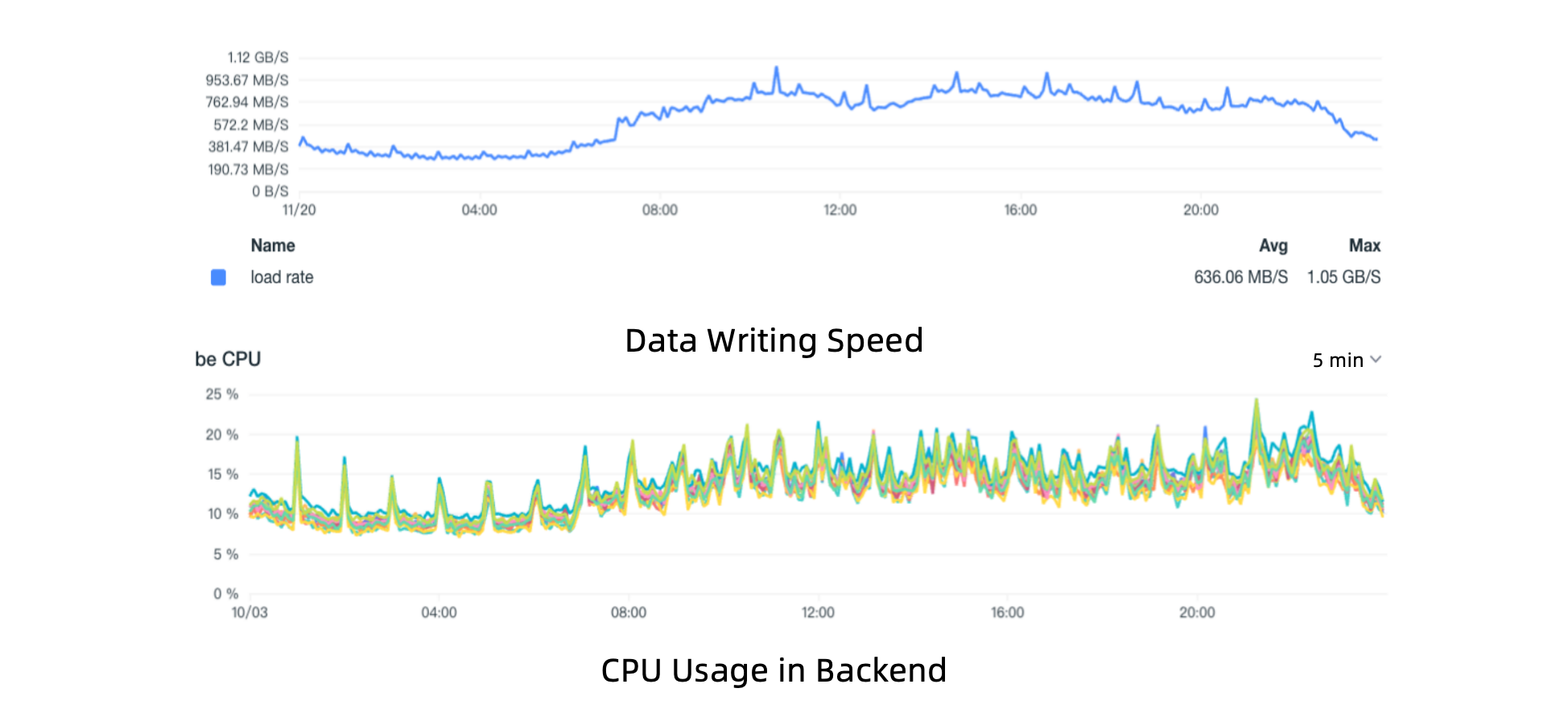
- High data compression ratio: Doris utilizes the ZSTD compression algorithm on top of columnar storage. It can realize a compression ratio of 8:1. Compared to 1.5:1 in Elasticsearch, Doris can reduce storage costs by around 80%.
- Tiered storage: Doris allows a more cost-effective way to store data: to put hot data in local disks and cold data object storage. Once the storage policy is set, Doris can automatically manage the "cooldown" process of hot data and move cold data to object storage. Such data lifecycle is transparent to the data application layer so it is user-friendly. Also, Doris speeds up cold data queries by local cache.
With lower storage costs, Doris does not compromise query performance. It doubles the execution speed of queries that return a single row and those that return a result set. For aggregation queries without sampling, Doris runs at 4 times the speed of Elasticsearch.
To sum up, Apache Doris achieves 2~4 times the query performance of Elasticsearch with only 1/3 of the storage cost it consumes.
Inverted index for full-text search
Inverted index is the magic potion for log analytics because it can considerably increase full-text search performance and reduce query overheads.
It is especially useful in these scenarios:
- Full-text search by
MATCH_ALL,MATCH_ANY, andMATCH_PHRASE.MATCH_PHRASEin combination with inverted index is the alternative to the Elasticsearch full-text search functionality. - Equivalence queries (=, ! =, IN), range queries (>, >=, <, <=), and support for numerics, datetime, and strings.
CREATE TABLE httplog
(
`ts` DATETIME,
`clientip` VARCHAR(20),
`request` TEXT,
INDEX idx_ip (`clientip`) USING INVERTED,
INDEX idx_req (`request`) USING INVERTED PROPERTIES("parser" = "english")
)
DUPLICATE KEY(`ts`)
...
-- Retrieve the latest 10 records of Client IP "8.8.8.8"
SELECT * FROM httplog WHERE clientip = '8.8.8.8' ORDER BY ts DESC LIMIT 10;
-- Retrieve the latest 10 records with "error" or "404" in the "request" field
SELECT * FROM httplog WHERE request MATCH_ANY 'error 404' ORDER BY ts DESC LIMIT 10;
-- Retrieve the latest 10 records with "image" and "faq" in the "request" field
SELECT * FROM httplog WHERE request MATCH_ALL 'image faq' ORDER BY ts DESC LIMIT 10;
-- Retrieve the latest 10 records with "query error" in the "request" field
SELECT * FROM httplog WHERE request MATCH_PHRASE 'query error' ORDER BY ts DESC LIMIT 10;
As a powerful accelerator for full-text searches, inverted index in Doris is flexible because we witness the need for on-demand adjustments. In Elasticsearch, indexes are fixed upon creation, so there needs to be good planning of which fields need to be indexed, otherwise, any changes to the index will require a complete rewrite.
In contrast, Doris allows for dynamic indexing. You can add inverted index to a field during runtime and it will take effect immediately. You can also decide which data partitions to create indexes on.
A new data type for dynamic schema change
By nature, an observability platform requires support for dynamic schema, because the data it collects is prone to changes. Every click by a user on the webpage might add a new metric to the database.
Looking around the database landscape, you will find that static schema is the norm. Some databases take a step further. For example, Elasticsearch realizes dynamic schema by mapping. However, this functionality can be easily interrupted by field type conflicts or unexpired historical fields.
The Doris solution for dynamic schema is a newly-introduced data type: Variant, and GuanceDB is among the first to try it out. (It will officially be available in Apache Doris V2.1.)
The Variant data type is the move of Doris to embrace semi-structured data analytics. It can solve a lot of the problems that often harass database users:
- JSON data storage: A Variant column in Doris can accommodate any legal JSON data, and can automatically recognize the subfields and data types.
- Schema explosion due to too many fields: The frequently occurring subfields will be stored in a column-oriented manner to facilitate analysis, while the less frequently seen subfields will be merged into the same column to streamline the data schema.
- Write failure due to data type conflicts: A Variant column allows different types of data in the same field, and applies different storage for different data types.
Difference between Variant and Dynamic Mapping
From a functional perspective, the biggest difference between Variant in Doris and Dynamic Mapping in Elasticsearch is that the scope of Dynamic Mapping extends throughout the entire lifecycle of the current table, while that of Variant can be limited to the current data partition.
For example, if a user has changed the business logic and renamed some Variant fields today, the old field name will remain on the partitions before today, but will not appear on the new partitions since tomorrow. So there is a lower risk of data type conflict.
In the case of field type conflicts in the same partition, the two fields will be changed to JSON type to avoid data error or data loss. For example, there are two status fields in the user's business system: One is strings, and the other is numerics, so in queries, the user can decide whether to query the string field, or the nuemric field, or both. (E.g. If you specify status = "ok" in the filters, the query will only be executed on the string field.)
From the users' perspective, they can use the Variant type as simply as other data types. They can add or remove Variant fields based on their business needs, and no extra syntax or annotation is required.
Currently, the Variant type requires extra type assertion, we plan to automate this process in future versions of Doris. GuanceDB is one step faster in this aspect. They have realized auto type assertion for their DQL queries. In most cases, type assertion is based on the actual data type of Variant fields. In some rare cases when there is a type conflict, the Variant fields will be upgraded to JSON fields, and then type assertion will be based on the semantics of operators in DQL queries.
Conclusion
GuanceDB's transition from Elasticsearch to Apache Doris showcases a big stride in improving data processing speed and reducing costs. For these purposes, Apache Doris has optimized itself in the two major aspects of data processing: data integration and data analysis. It has expanded its schemaless support to flexibly accommodate more data types, introduced features like inverted index and tiered storage to enable faster and more cost-effective queries. Evolution is an ongoing process. Apache Doris has never stopped improving itself. We have a lot of new features under development and the Doris community embrace any input and feedback.
Check Apache Doris GitHub repo
Find Apache Doris makers on Discord