Introduction to Apache Doris: a next-generation real-time data warehouse
What is Apache Doris?
Apache Doris is an open-source real-time data warehouse. It can collect data from various data sources, including relational databases (MySQL, PostgreSQL, SQL Server, Oracle, etc.), logs, and time series data from IoT devices. It is capable of reporting, ad-hoc analysis, federated queries, and log analysis, so it can be used to support dashboarding, self-service BI, A/B testing, user behavior analysis and the like.
Apache Doris supports both batch import and stream writing. It can be well integrated with Apache Spark, Apache Hive, Apache Flink, Airbyte, DBT, and Fivetran. It can also connect to data lakes such as Apache Hive, Apache Hudi, Apache Iceberg, Delta Lake, and Apache Paimon.
Performance
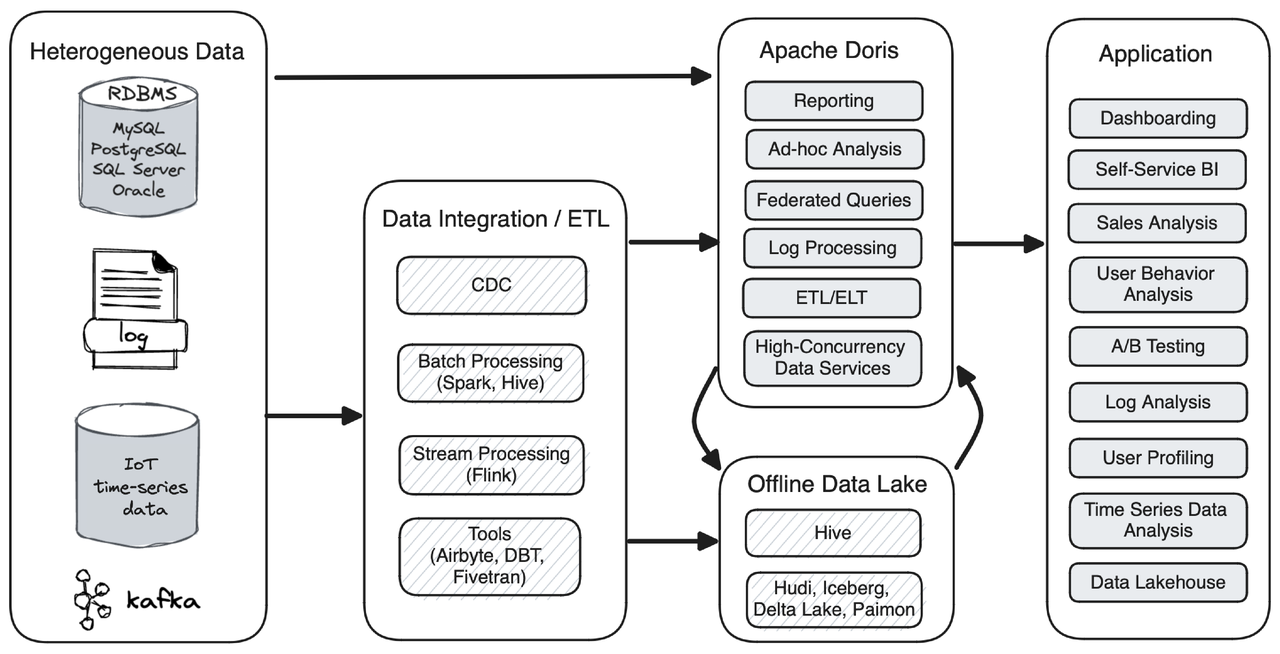
As a real-time OLAP engine, Apache Doris hasn a competitive edge in query speed. According to the TPC-H and SSB-Flat benchmarking results, Doris can deliver much faster performance than Presto, Greenplum, and ClickHouse.
As for its self-volution, it has increased its query speed by over 10 times in the past two years, both in complex queries and flat table analysis.
Architectural Design
Behind the fast speed of Apache Doris is the architectural design, features, and mechanisms that contribute to the performance of Doris.
First of all, Apache Doris has a cost-based optimizer (CBO) that can figure out the most efficient execution plan for complicated big queries. It has a fully vectorized execution engine so it can reduce virtual function calls and cache misses. It is MPP-based (Massively Parallel Processing) so it can give full play to the user's machines and cores. In Doris, query execution is data-driven, which means whether a query gets executed is determined by whether its relevant data is ready, and this enables more efficient use of CPUs.
Fast Point Queries for A Column-Oriented Database
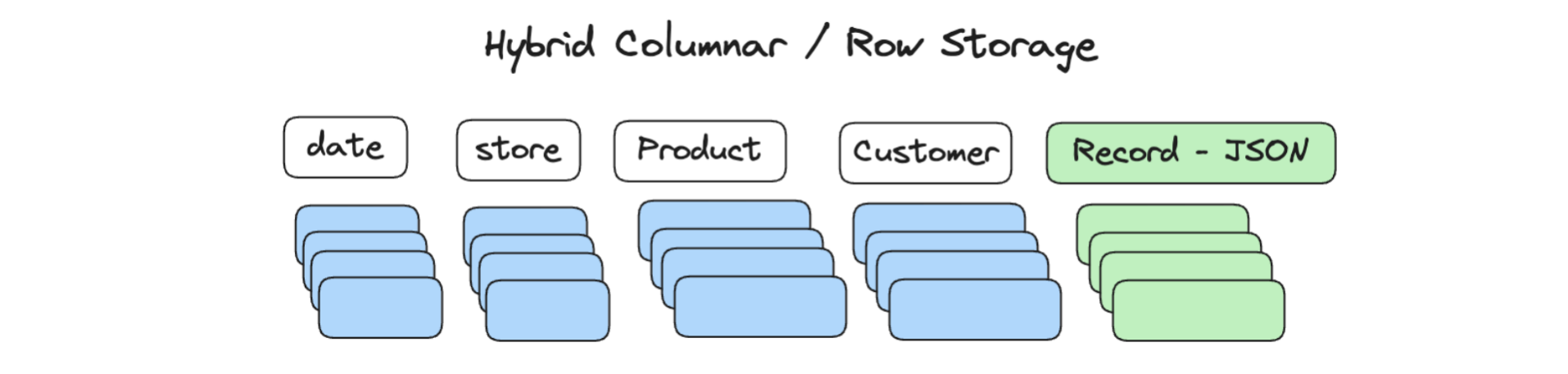
Apache Doris is a column-oriented database so it can make data compression and data sharding easier and faster. But this might not be suitable for cases such as customer-facing services. In these cases, a data platform will have to handle requests from a large number of users concurrently (these are called "high-concurrency point queries"), and having a columnar storage engine will amplify I/O operations per second, especially when data is arranged in flat tables.
To fix that, Apache Doris enables hybrid storage, which means to have row storage and columnar storage at the same time.
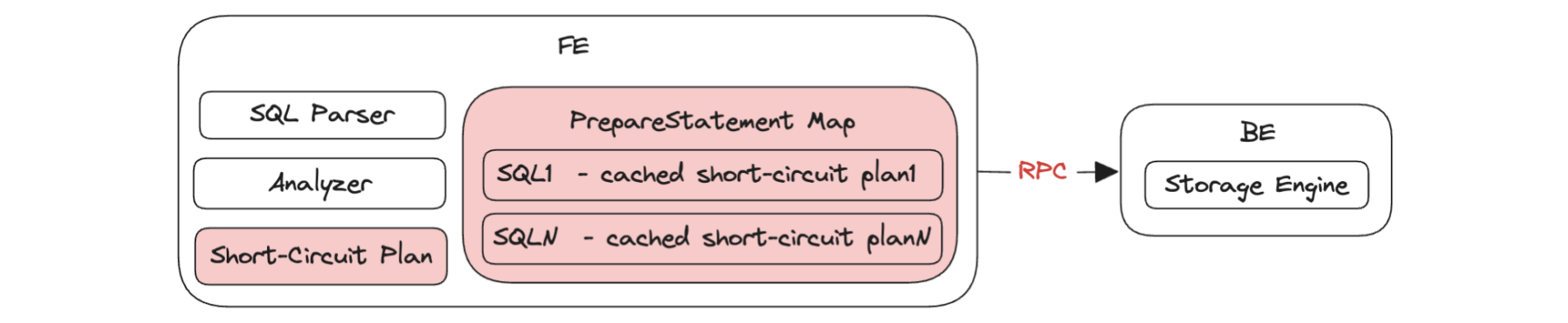
In addition, since point queries are all simple queries, it will be unnecessary and wasteful to call out the query planner, so Doris executes a short circuit plan for them to reduce overhead.
Another big source of overheads in high-concurrency point queries is SQL parsing. For that, Doris has prepared statements. The idea is to pre-compute the SQL statement and cache them, so they can be reused for similar queries.
Data Ingestion
Apache Doris provides a range of methods for data ingestion.
Real-Time stream writing:
- Stream Load: You can apply this method to write local files or data streams via HTTP. It is linearly scalable and can reach a throughput of 10 million records per second in some use cases.
- Flink-Doris-Connector: With built-in Flink CDC, this Connector ingests data from OLTP databases to Doris. So far, we have realized auto-synchronization of data from MySQL and Oracle to Doris.
- Routine Load: This is to subscribe data from Kafka message queues.
- Insert Into: This is especially useful when you try to do ETL in Doris internally, like writing data from one Doris table to another.
Batch writing:
- Spark Load: With this method, you can leverage Spark resources to pre-process data from HDFS and object storage before writing to Doris.
- Broker Load: This supports HDFS and S3 protocol.
insert into <internal table> select from <external table>: This simple statement allows you to connect Doris to various storage systems, data lakes, and databases.
Data Update
For data updates, what Apache Doris has to offer is that, it supports both Merge on Read and Merge on Write, the former for low-frequency batch updates and the latter for real-time writing. With Merge on Write, the latest data will be ready by the time you execute queries, and that's why it can improve your query speed by 5 to 10 times compared to Merge on Read.
From an implementation perspective, these are a few common data update operations, and Doris supports them all:
- Upsert: to replace or update a whole row
- Partial column update: to update just a few columns in a row
- Conditional updating: to filter out some data by combining a few conditions in order to replace or delete it
- Insert Overwrite: to rewrite a table or partition
In some cases, data updates happen concurrently, which means there is numerous new data coming in and trying to modify the existing data record, so the updating order matters a lot. That's why Doris allows you to decide the order, either by the order of transaction commit or that of the sequence column (something that you specify in the table in advance). Doris also supports data deletion based on the specified predicate, and that's how conditional updating is done.
Service Availability & Data Reliability
Apart from fast performance in queries and data ingestion, Apache Doris also provides service availability guarantee, and this is how:
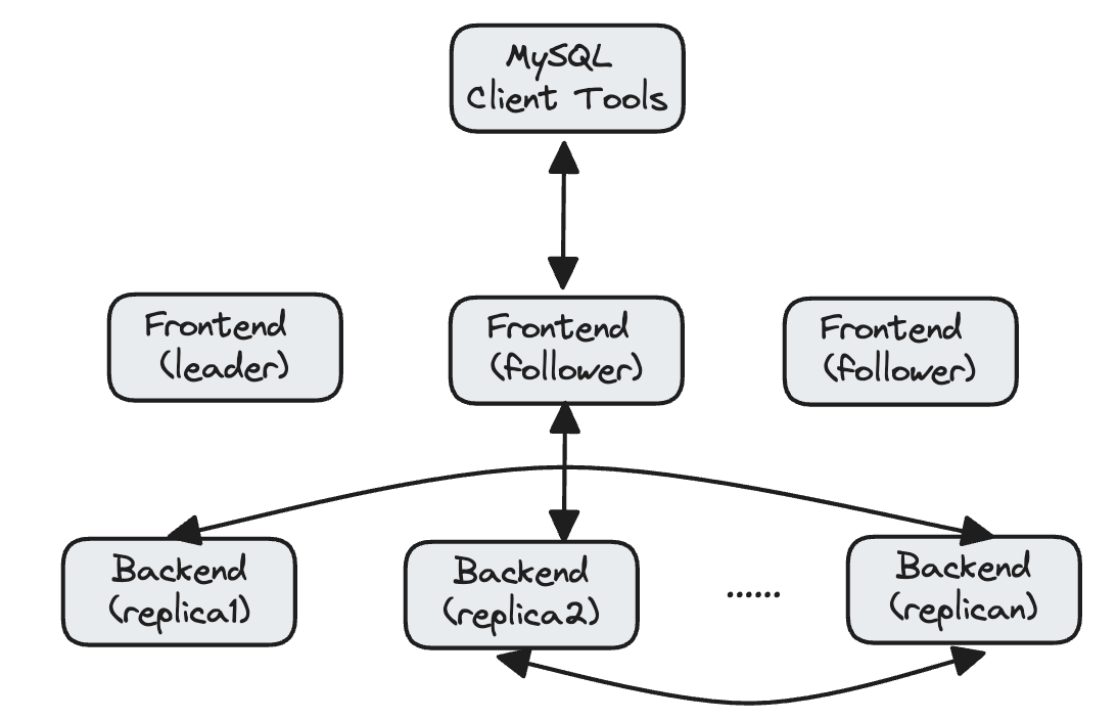
Architecturally, Doris has two processes: frontend and backend. Both of them are easily scalable. The frontend nodes manage the clusters, metadata and handle user requests; the backend nodes execute the queries and are capable of auto data balancing and auto-restoration. It supports cluster upgrading and scaling to avoid interruption to services.
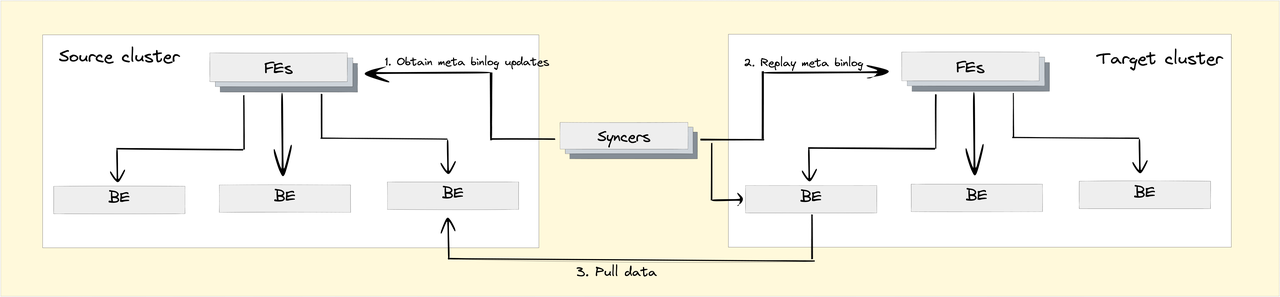
Cross Cluster Replication
Enterprise users, especially those in finance or e-commerce, will need to backup their clusters or their entire data center, just in case of force majeure. So Doris 2.0 provides Cross Cluster Replication (CCR). With CCR, users can do a lot:
- Disaster recovery: for quick restoration of data services
- Read-write separation: master cluster + slave cluster; one for reading, one for writing
- Isolated upgrade of clusters: For cluster scaling, CCR allows users to pre-create a backup cluster for a trial run so they can clear out the possible incompatibility issues and bugs.
Tests show that Doris CCR can reach a data latency of minutes. In the best case, it can reach the upper speed limit of the hardware environment.
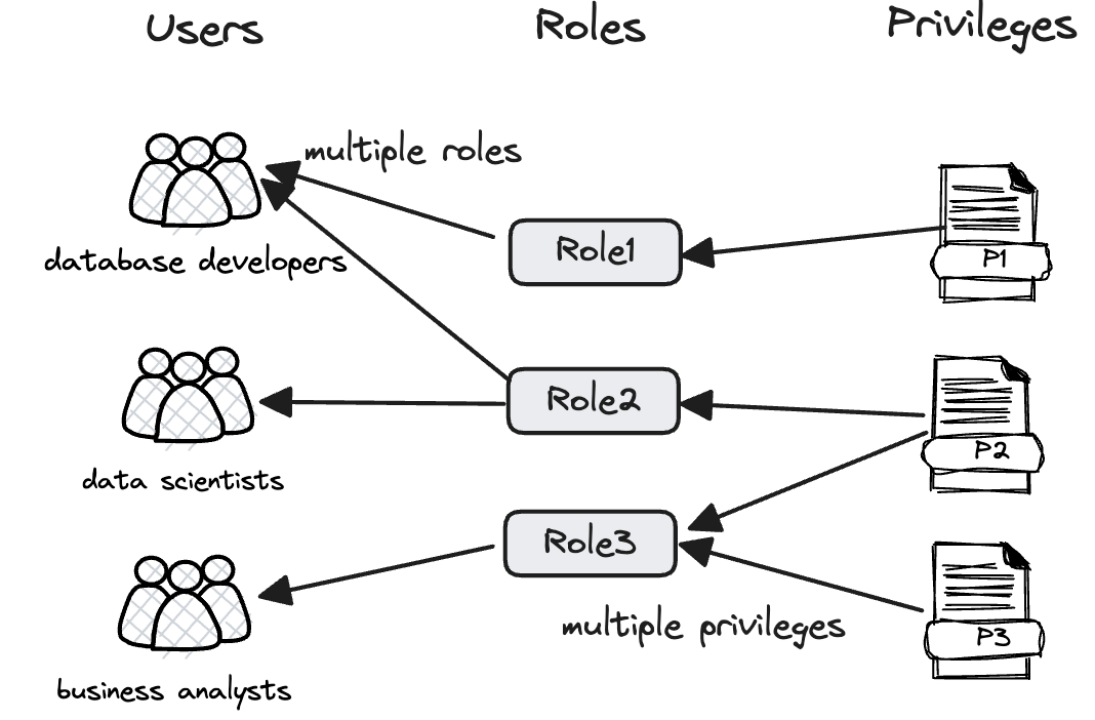
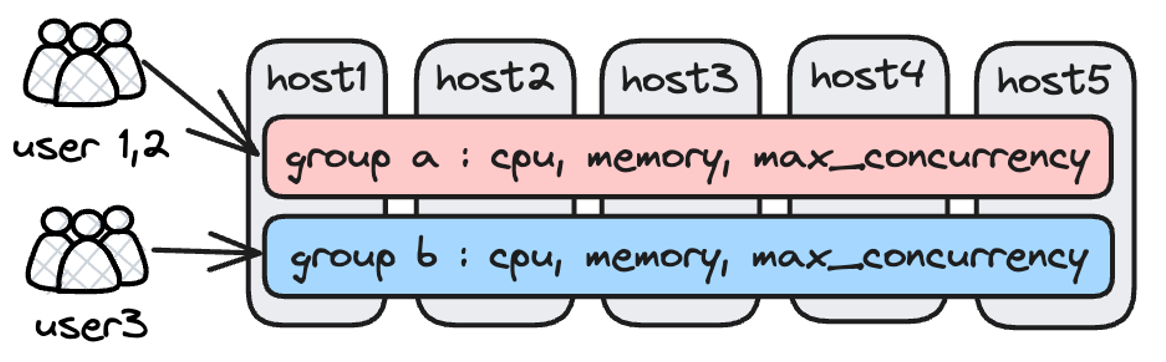
Multi-Tenant Management
Apache Doris has sophisticated Role-Based Access Control, and it allows fine-grained privilege control on the level of databases, tables, rows, and columns.
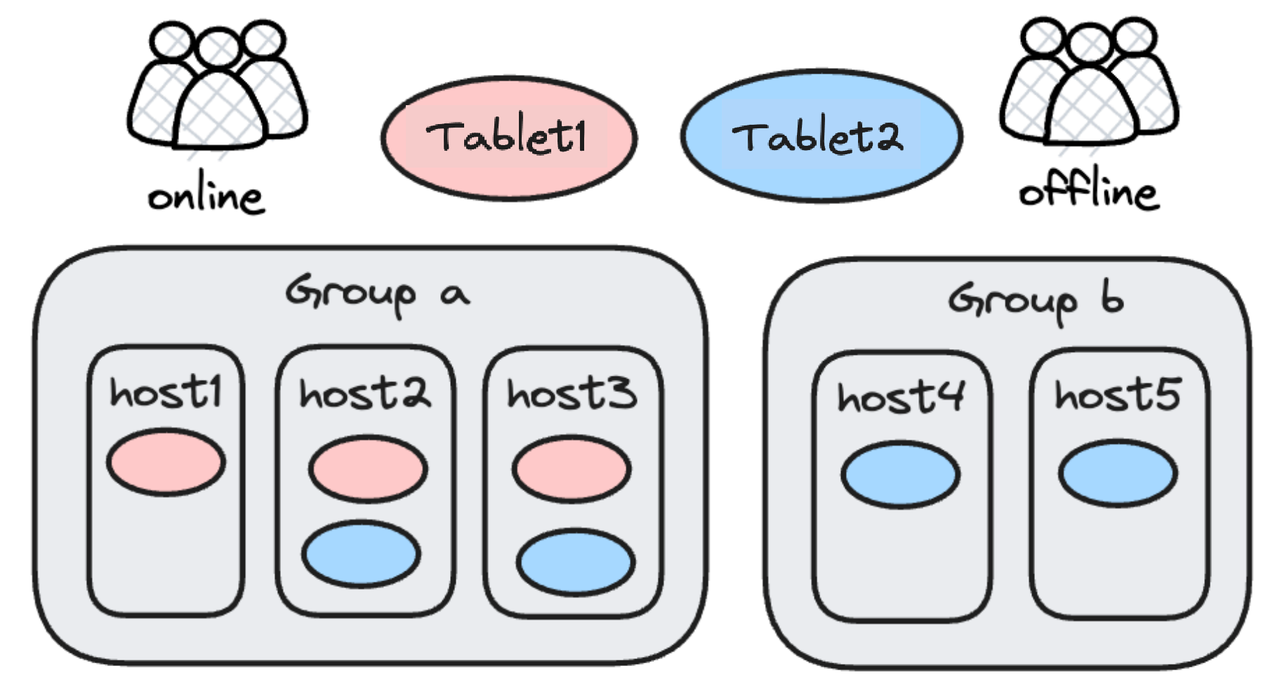
For resource isolation, Doris used to implement a hard isolation plan, which is to divide the backend nodes into resource groups, and assign the Resource Groups to different workloads. This is a hard isolation plan. It was simple and neat. But sometimes users can make the most out of their computing resource because some Resource Groups are idle.
Thus, instead of Resource Groups, Doris 2.0 introduces Workload Group. A soft limit is set for a Workload Group about how many resources it can use. When that soft limit is hit, and meanwhile there are some idle resources available. The idle resources will be shared across the workload groups. Users can also prioritize the workload groups in terms of their access to idle resources.
Easy to Use
As many capabilities as Apache Doris provides, it is also easy to use. It supports standard SQL and is compatible with MySQL protocol and most BI tools on the market.
Another effort that we've made to improve usability is a feature called Light Schema Change. This means if users need to add or delete some columns in a table, they just need to update the metadata in the frontend but don't have to modify all the data files. Light Schema Change can be done within milliseconds. It also allows changes to indexes and data type of columns. The combination of Light Schema Change and Flink-Doris-Connector means synchronization of upstream tables within milliseconds.
Semi-Structured Data Analysis
Common examples of semi-structure data include logs, observability data, and time series data. These cases require schema-free support, lower cost, and capabilities in multi-dimensional analysis and full-text search.
In text analysis, mostly, people use the LIKE operator, so we put a lot of effort into improving the performance of it, including pushing down the LIKE operator down to the storage layer (to reduce data scanning), and introducing the NGram Bloomfilter, the Hyperscan regex matching library, and the Volnitsky algorithm (for sub-string matching).
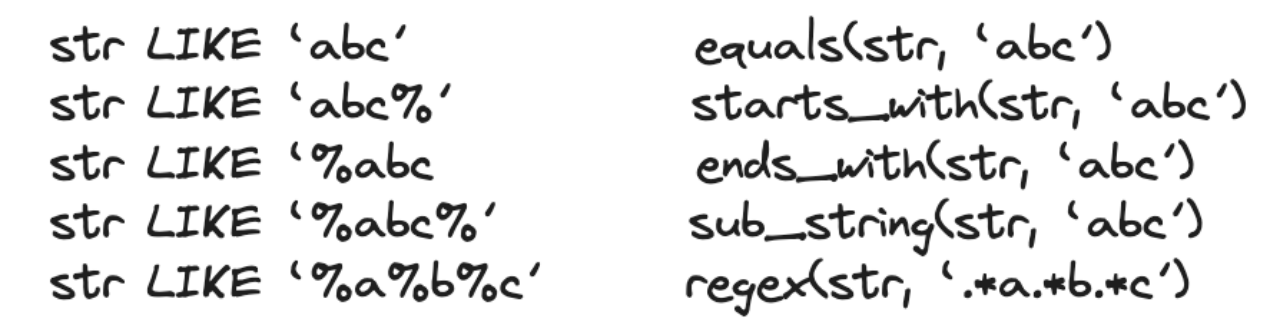
We have also introduced inverted index for text tokenization. It is a power tool for fuzzy keyword search, full-text search, equivalence queries, and range queries.
Data Lakehouse
For users to build a high-performing data lakehouse and a unified query gateway, Doris can map, cache, and auto-refresh the meta data from external sources. It supports Hive Metastore and almost all open data lakehouse formats. You can connect it to relational databases, Elasticsearch, and many other sources. And it allows you to reuse your own authentication systems, like Kerberos and Apache Ranger, on the external tables.
Benchmark results show that Apache Doris is 3~5 times faster than Trino in queries on Hive tables. It is the joint result of a few features:
- Efficient query engine
- Hot data caching mechanism
- Compute nodes
- Views in Doris
The Compute Nodes is a newly introduced solution in version 2.0 for data lakehousing. Unlike normal backend nodes, Compute Nodes are stateless and do not store any data. Neither are they involved in data balancing during cluster scaling. Thus, they can join the cluster flexibly and easily during computation peak times.
Also, Doris allows you to write the computation results of external tables into Doris to form a view. This is a similar thinking to Materialized Views: to trade space for speed. After a query on external tables is executed, the results can be put in Doris internally. When there are similar queries following up, the system can directly read the results of previous queries from Doris, and that speeds things up.
Tiered Storage
The main purpose of tiered storage is to save money. Tiered storage means to separate hot data and cold data into different storage, with hot data being the data that is frequently accessed and cold data that isn't. It allows users to put hot data in the quick but expensive disks (such as SSD and HDD), and cold data in object storage.
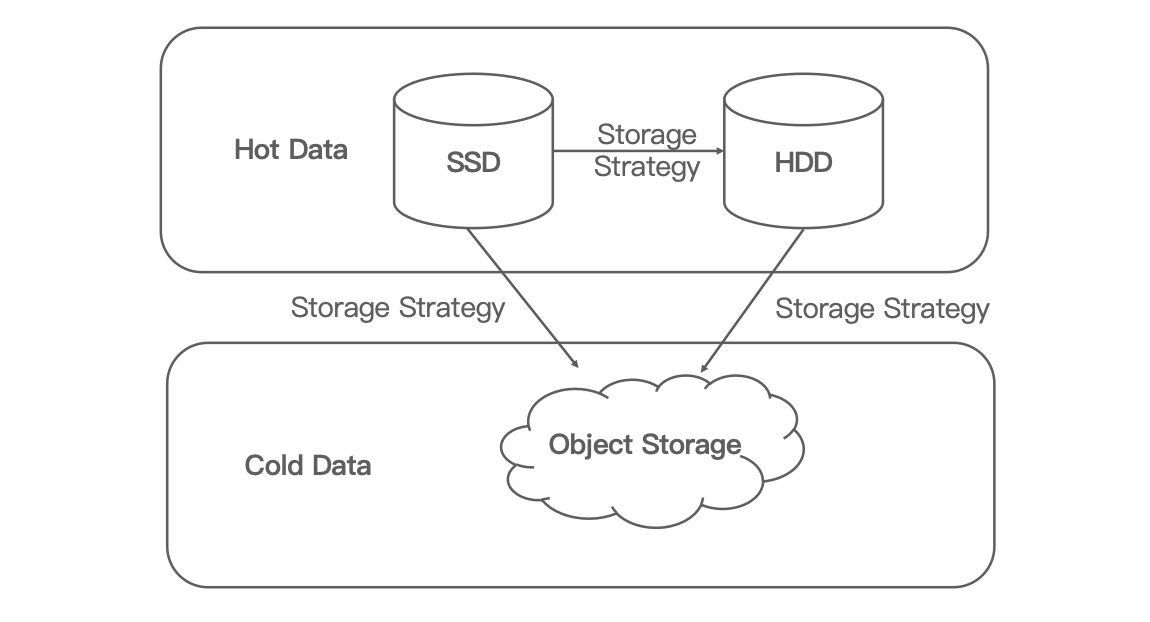
Roughly speaking, for a data asset consisting of 80% cold data, tiered storage will reduce your storage cost by 70%.
The Apache Doris Community
This is an overview of Apache Doris, an open-source real-time data warehouse. It is actively evolving with an agile release schedule, and the community embraces any questions, ideas, and feedback.