Another lifesaver for data engineers: Apache Doris Job Scheduler for task automation
Job scheduling is an important part of data management as it enables regular data updates and cleanups. In a data platform, it is often undertaken by workflow orchestration tools like Apache Airflow and Apache Dolphinscheduler. However, adding another component to the data architecture also means investing extra resources for management and maintenance. That's why Apache Doris 2.1.0 introduces a built-in Job Scheduler. It is strategically more tailored to Apache Doris, and brings higher scheduling flexibility and architectural simplicity.
The Doris Job Scheduler triggers the pre-defined operations at specific time points or intervals, thus allowing for efficient and reliable task automation. Its key capabilities include:
-
Efficiency: It adopts the TimeWheel algorithm to ensure that the triggering of tasks is precise to the second.
-
Flexibility: It supports both one-time jobs and regular jobs. For the latter, users can define the start/end time, and intervals of minutes, hours, days, or weeks.
-
Execution thread pool and processing queue: It is supported by a Disruptor-based single-producer, multi-consumer model to avoid task execution overload.
-
Traceability: It keeps track of the latest task execution records (configurable), which are queryable by a simple command.
-
Availability: Like Apache Doris itself, the Doris Job Scheduler is easily recoverable and highly available.
Syntax & examples
Syntax description
A valid job statement consists of the following elements:
-
CREATE JOB: Specifies the job name as a unique identifier. -
The
ON SCHEDULEclause: Specifies the type, trigger time, and frequency of the job.-
AT timestamp: This is used to specify a one-time job.AT CURRENT_TIMESTAMPmeans that the job will run immediately upon creation. -
EVERY: This is used to specify a regular job. You can define the execution frequency of the job. The interval can be measured in weeks, days, hours, and minutes.- The
EVERYclause supports an optionalSTARTSclause with a timestamp to define the start time of the recurring schedule.CURRENT_TIMESTAMPcan be used. It also supports an optionalENDSclause to specify the end time for the job.
- The
-
-
The
DOclause defines the action to be performed when the job is executed. At this time, the only supported operation is INSERT.CREATE
JOB
job_name
ON SCHEDULE schedule
[COMMENT 'string']
DO execute_sql;
schedule: {
AT timestamp
| EVERY interval
[STARTS timestamp ]
[ENDS timestamp ]
}
interval:
quantity { WEEK |DAY | HOUR | MINUTE
}
Example:
CREATE JOB my_job ON SCHEDULE EVERY 1 MINUTE DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2;The above statement creates a job named
my_job, which is to load data fromdb2.tbl2todb1.tbl1every minute.
More examples
Create a one-time job: Load data from db2.tbl2 to db1.tbl1 at 2025-01-01 00:00:00.
CREATE JOB my_job ON SCHEDULE AT '2025-01-01 00:00:00' DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2;
Create a regular job without specifying the end time: Load data from db2.tbl2 to db1.tbl1 once a day starting from 2025-01-01 00:00:00.
CREATE JOB my_job ON SCHEDULE EVERY 1 DAY STARTS '2025-01-01 00:00:00' DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2 WHERE create_time >= days_add(now(),-1);
Create a regular job within a specified period: Load data from db2.tbl2 to db1.tbl1 once a day, beginning at 2025-01-01 00:00:00 and finishing at 2026-01-01 00:10:00.
CREATE JOB my_job ON SCHEDULER EVERY 1 DAY STARTS '2025-01-01 00:00:00' ENDS '2026-01-01 00:10:00' DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2 create_time >= days_add(now(),-1);
Asynchronous execution: Because jobs are executed in an asynchronous manner in Doris. Tasks that require asynchronous execution, such as insert into select, can be implemented by a job.
For example, to asynchronously execute data loading from db2.tbl2 to db1.tbl1, simply create a one-time job for it and schedule it at current_timestamp.
CREATE JOB my_job ON SCHEDULE AT current_timestamp DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2;
Auto data synchronization
The combination of the Job Scheduler and the Multi-Catalog feature of Apache Doris is an efficient way to implement regular data synchronization across data sources.
This is useful in many cases, such as for an e-commerce user who regularly needs to load business data from MySQL to Doris for analysis.
Example: To filter consumers by total consumption amount, last visit time, sex, and city in the table below, and import the query results to Doris regularly.
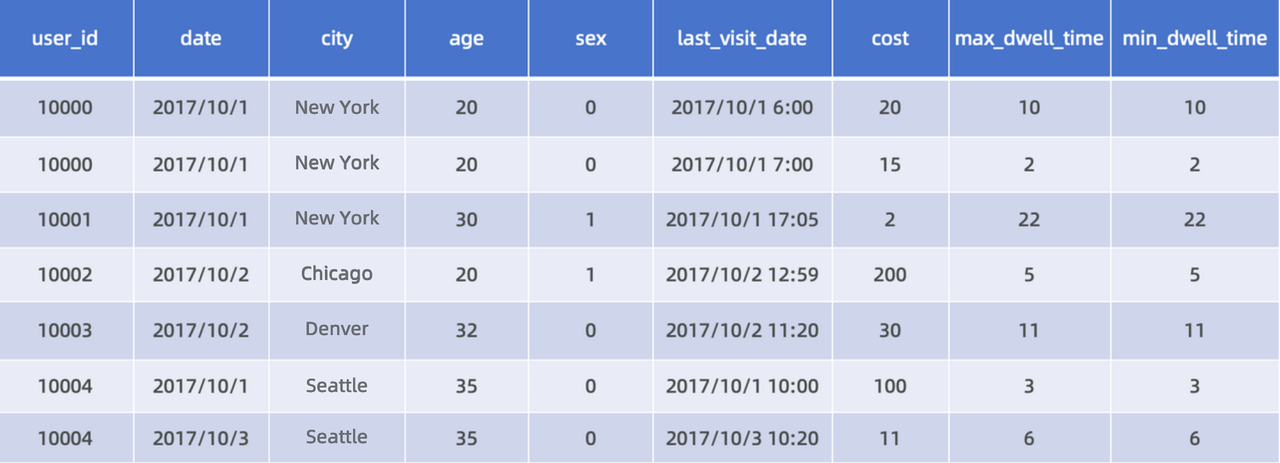
Step 1: Create a table in Doris
CREATE TABLE IF NOT EXISTS user_activity
(
`user_id` LARGEINT NOT NULL COMMENT "User ID",
`date` DATE NOT NULL COMMENT "Time of data import",
`city` VARCHAR(20) COMMENT "User city",
`age` SMALLINT COMMENT "User age",
`sex` TINYINT COMMENT "User sex",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "Time of user's last visit",
`cost` BIGINT SUM DEFAULT "0" COMMENT "User's total consumption amount",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "Maximum dwell time of user",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "Minimum dwell time of user"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
Step 2: Create a catalog in Doris to map to the data in MySQL
CREATE CATALOG activity PROPERTIES (
"type"="jdbc",
"user"="root",
"jdbc_url" = "jdbc:mysql://127.0.0.1:9734/user?useSSL=false",
"driver_url" = "mysql-connector-java-5.1.49.jar",
"driver_class" = "com.mysql.jdbc.Driver"
);
Step 3: Ingest data from MySQL to Doris. Leverage the catalog mechanism and the Insert Into method for full data ingestion. (We recommend that such operations be executed during low-traffic hours to minimize potential service disruptions.)
-
One-time job: Schedule a one-time full-scale data loading that starts at 2024-8-10 03:00:00.
CREATE JOB one_time_load_job
ON SCHEDULE
AT '2024-8-10 03:00:00'
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity -
Regular job: Create a regular job to update data periodically.
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 DAY
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity where create_time >= days_add(now(),-1)
Technical design & implementation
Efficient scheduling often comes at the cost of significant resource consumption, and high-precision scheduling is even more resource-intensive. To implement job scheduling, some people rely on the built-in scheduling capabilities of Java, while others employ job scheduling libraries. But what if we want higher precision and lower memory usage than these solutions can reach? For that, the Doris makers combine the TimingWheel algorithm with the Disruptor framework to achieve second-level job scheduling.
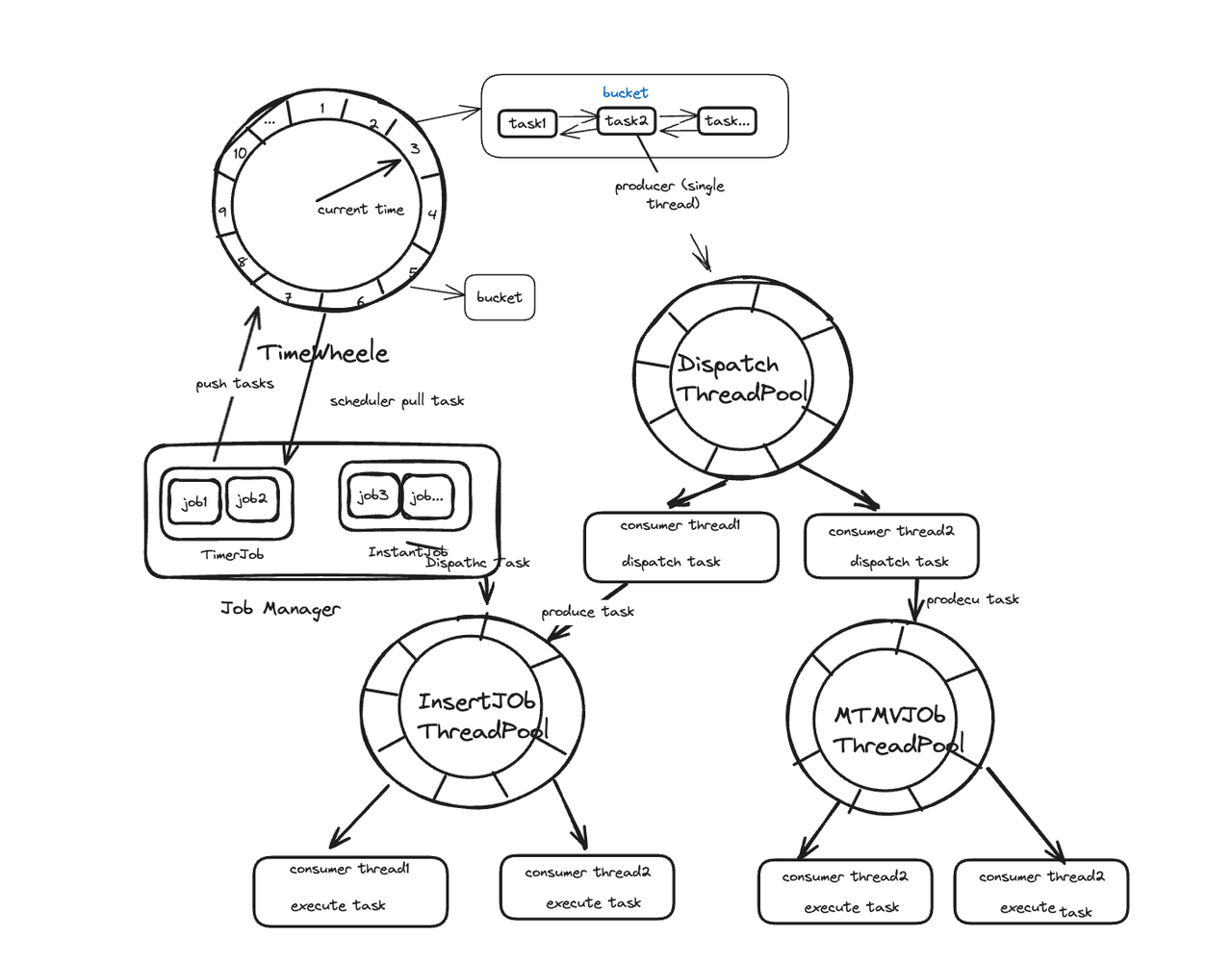
To implement the TimingWheel algorithm, we leverage the HashedWheelTimer in Netty. The Job Manager puts tasks every 10 minutes (by default) in the TimeWheel for scheduling. In order to ensure efficient task triggering and avoid high resource usage, we adopt a Disruptor-based single-producer, multi-consumer model. The TimeWheel only triggers tasks but does not execute jobs directly. Tasks that need to be triggered upon expiration will be put into a Dispatch thread and distributed to an appropriate execution thread pool. Tasks that need to be executed immediately will be directly submitted to the corresponding execution thread pool.
This is how we improve processing efficiency by reducing unnecessary traversal: For one-time tasks, their definition will be removed after execution. For recurring tasks, the system events in the TimeWheel will periodically fetch the next round of execution tasks. This helps to avoid the accumulation of tasks in a single bucket.
In addition, for transactional tasks, the Job Scheduler can ensure data consistency and integrity by the transaction association and transaction callback mechanisms.
Applicable scenarios
The Doris Job Scheduler is a Swiss Army Knife. It is not only useful in ETL and data lake analytics as we mentioned, but also critical for the implementation of asynchronous materialized views. An asynchronous materialized view is a pre-computed result set. Unlike normal materialized views, it can be built on multiple tables. Thus, as you can imagine, changes in any of the source tables will lead to the need for updates in the asynchronous materialized view. That's why we apply the job scheduling mechanism for periodic data refreshing in asynchronous materialized views, which is low-maintenance and also ensures data consistency.
Where are we going with the Doris Job Scheduler? The Apache Doris developer community is looking at:
-
Displaying the distribution of tasks executed in different time slots on the WebUI.
-
DAG jobs. This will allow data warehouse task orchestration within Apache Doris, which will unlock many possibilities when it is combined with the Multi-Catalog feature.
-
Support for more operations such as UPDATE and DELETE.