Less components, higher performance: Apache Doris instead of ClickHouse, MySQL, Presto, and HBase
This post is about building a unified OLAP platform. An insurance company tries to build a data warehouse that can undertake all their customer-facing, analyst-facing, and management-facing data analysis workloads. The main tasks include:
- Self-service insurance contract query: This is for insurance customers to check their contract details by their contract ID. It should also support filters such as coverage period, insurance types, and claim amount.
- Multi-dimensional analysis: Analysts develop their reports based on different data dimensions as they need, so they can extract insights to facilitate product innovation and their anti-fraud efforts.
- Dashboarding: This is to create visual overview of the insurance sales trends and the horizontal and vertical comparison of different metrics.
Component-Heavy Data Architecture
The user started with Lambda architecture, splitting their data pipeline into a batch processing link and a stream processing link. For real-time data streaming, they apply Flink CDC; for batch import, they incorporate Sqoop, Python, and DataX to build their own data integration tool named Hisen.
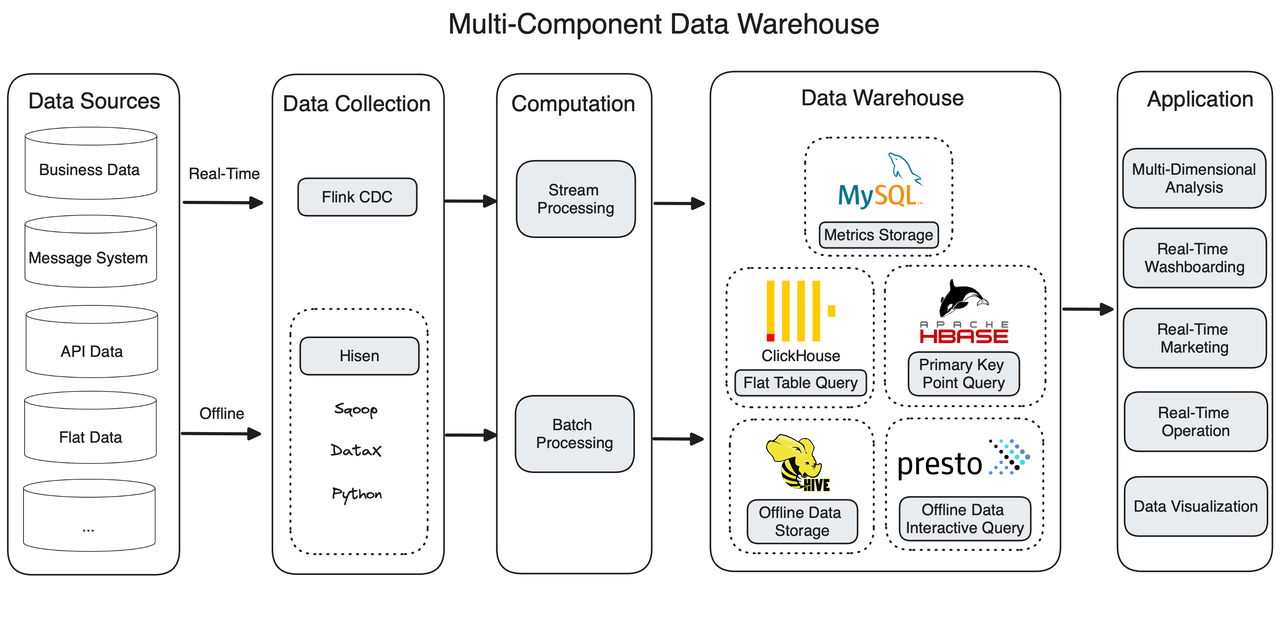
Then, the real-time and offline data meets in the data warehousing layer, which is made up of five components.
ClickHouse
The data warehouse is of flat table design and ClickHouse is superb in flat table reading. But as business evolves, things become challenging in two ways:
- To support cross-table joins and point queries, the user requires the star schema, but that's difficult to implement in ClickHouse.
- Changes in insurance contracts need to be updated in the data warehouse in real time. In ClickHouse, that is done by recreating a flat table to overwrite the old one, which is not fast enough.
MySQL
After calculation, data metrics are stored in MySQL, but as the data size grows, MySQL starts to struggle, with emerging problems like prolonged execution time and errors thrown.
Apache Hive + Presto
Hive is the main executor in the batch processing link. It can transform, aggregate, query offline data. Presto is a complement to Hive for interactive analysis.
Apache HBase
HBase undertakes primary key queries. It reads customer status from MySQL and Hive, including customer credits, coverage period, and sum insured. However, since HBase does not support secondary indexes, it has limited capability in reading non-primary key columns. Plus, as a NoSQL database, HBase does not support SQL statements.
The components have to work in conjunction to serve all needs, making the data warehouse too much to take care of. It is not easy to get started with because engineers must be trained on all these components. Also, the complexity of architecture adds to the risks of latency.
So the user tried to look for a tool that ticks more boxes in fulfilling their requirements. The first thing they need is real-time capabilities, including real-time writing, real-time updating, and real-time response to data queries. Secondly, they need more flexibility in data analysis to support customer-facing self-service queries, like multi-dimensional analysis, join queries of large tables, primary key indexes, roll-ups, and drill-downs. Then, for batch processing, they also want high throughput in data writing.
They eventually made up their mind with Apache Doris.
Replacing Four Components with Apache Doris
Apache Doris is capable of both real-time and offline data analysis, and it supports both high-throughput interactive analysis and high-concurrency point queries. That's why it can replace ClickHouse, MySQL, Presto, and Apache HBase and work as the unified query gateway for the entire data system.
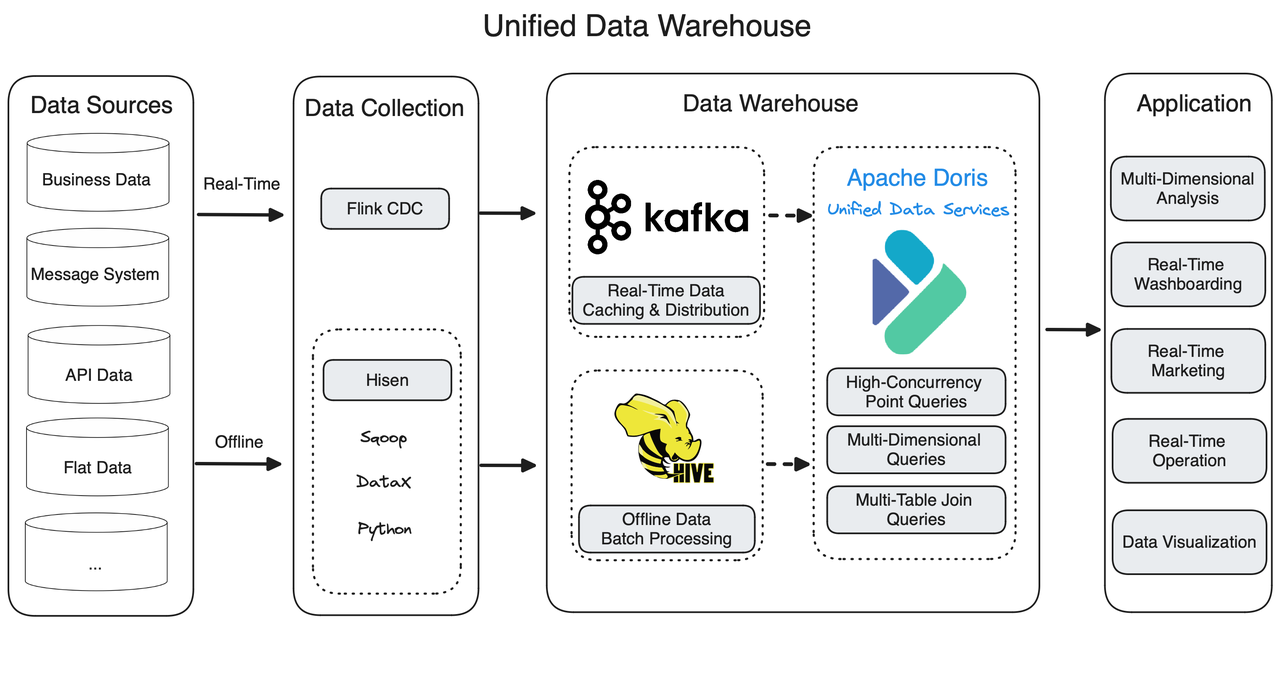
The improved data pipeline is a much cleaner Lambda architecture.
Apache Doris provides a wide range of data ingestion methods. It's quick in data writing. On top of this, it also implements Merge-on-Write to improve its performance on concurrent point queries.
Reduced Cost
The new architecture has reduced the user's cost in human efforts. For one thing, the much simpler data architecture leads to much easier maintenance; for another, developers no longer need to join the real-time and offline data in the data serving API.
The user can also save money with Doris because it supports tiered storage. It allows the user to put their huge amount of rarely accessed historical data in object storage, which is much cheaper to hoard data.
Higher Efficiency
Apache Doris can reach a QPS of 10,000s and respond to billions of point queries within milliseconds, so the customer-facing queries are easy for it to handle. Tiered storage that separates hot data from cold data also increases their query efficiency.
Service Availability
As a unified data warehouse for storage, computation, and data services, Apache Doris allows for easy disaster recovery. With less components, they don't have to worry about data loss or duplication.
An important guarantee of service availability for the user is the Cross-Cluster Replication (CCR) capability of Apache Doris. It can synchronize data from cluster to cluster within minutes or even seconds, and it implements two mechanisms to ensure data reliability:
- Binlog: This mechanism can automatically log the data changes and generate a LogID for each data modification operation. The incremental LogIDs make sure that data changes are traceable and orderly.
- Data persistence: In the case of system meltdown or emergencies, data will be put into disks.
A Deeper Look into Apache Doris
Apache Doris can replace the ClickHouse, MySQL, Presto, and HBase because it has a comprehensive collection of capabilities all along the data processing pipeline. In data ingestion, it enables low-latency real-time writing based on its support for Flink CDC and Merge-on-Write. It guarantees Exactly-Once writing by its Label mechanism and transactional loading. In data queries, it supports both Star Schema and flat table aggregation, so it can provide high performance in bother multi-table joins and large single table queries. It also provides various ways to speed up different queries, like inverted index for full-text search and range queries, short-circuit plan and prepared statements for point queries.