What Is LLM Observability? Metrics, Tools, and How It Works in AI Systems
What Is LLM Observability?
LLM observability is the ability to understand, monitor, and debug how a large language model behaves in a real-world application.
In practice, it focuses on making LLM systems more transparent by capturing what the model sees, what it produces, and how it arrives at those outputs across a full interaction.
It typically includes:
- tracing LLM calls and multi-step workflows
- monitoring inputs (prompts, context) and outputs
- evaluating response quality and correctness
- tracking latency, token usage, and cost
- analyzing how system components (e.g., retrieval, tools) influence results
Unlike traditional monitoring, which focuses on system health (such as uptime or error rates), LLM observability focuses on model behavior and decision outcomes.
This distinction is important because LLM systems are not purely deterministic. Observability is not just about detecting failures—it is about understanding why a response was generated, whether it was appropriate, and how it could be improved.
In modern AI applications, LLM observability often spans the entire pipeline, including prompt construction, retrieval (in RAG systems), model inference, and post-processing. This broader scope helps teams debug issues such as hallucinations, irrelevant answers, or inconsistent behavior.
Why LLM Observability Matters (Beyond Traditional Monitoring)
LLM systems are fundamentally harder to monitor than traditional software systems.
The main reasons include:
- Non-deterministic outputs: The same input can produce different responses, making issues difficult to reproduce and debug.
- Prompt-driven behavior: Small changes in prompts or context can lead to large differences in output, even when the underlying model remains the same.
- Hidden reasoning (black-box models): Most LLMs do not expose internal reasoning processes, so developers must rely on indirect signals to understand behavior.
- Multi-step pipelines (RAG and agents): Many systems involve retrieval, tool usage, or chained model calls, where failures can originate from multiple points.
As a result, traditional monitoring signals—such as latency, uptime, or error rates—provide only a partial view of system performance.
LLM observability is designed to address this gap by providing visibility into how inputs are transformed into outputs across the entire system.
It helps answer questions such as:
- Why did the model generate this response?
- Was the retrieved context relevant?
- Is the issue caused by the prompt, the model, or the data?
- How does output quality change over time?
In practice, this deeper visibility is essential for:
- debugging hallucinations and incorrect answers
- improving prompt and system design
- maintaining consistent user experience
- controlling cost and performance at scale
Without observability, LLM systems can appear to work while silently degrading in quality or reliability. With observability, teams can move from reactive debugging to systematic improvement.
What to Monitor in LLM Systems (Key Signals)
The most important signals in LLM observability include both system-level metrics and model-specific signals that reflect how the LLM behaves in real-world usage.
In practice, effective observability focuses not just on whether the system is running, but whether it is producing useful, reliable, and cost-efficient outputs.
Input and Prompt Monitoring
Tracking prompts and user inputs helps identify issues at the very beginning of the pipeline.
This includes:
- prompt injection or unsafe inputs
- unclear or poorly structured prompts
- unexpected user behavior patterns
Because LLM outputs are highly sensitive to input phrasing, even small changes in prompts can lead to significantly different results. Monitoring inputs is often the fastest way to diagnose inconsistent behavior.
Output Quality and Evaluation
Evaluating outputs is one of the most important—and most challenging—parts of LLM observability.
Common evaluation dimensions include:
- relevance (does the answer match the question?)
- correctness (is the information accurate?)
- consistency (does the model behave predictably?)
- safety (does the output avoid harmful or biased content?)
In practice, most systems combine:
- automated evaluation (e.g., scoring, heuristics)
- human review or feedback loops
Since many LLM tasks are open-ended, output quality cannot be captured by a single metric and often requires context-aware evaluation.
Latency and Cost
LLM systems often introduce a new category of operational constraints: cost per request.
Key signals include:
- response time (end-to-end latency)
- token usage (input and output tokens)
- cost per query or per user
Monitoring these signals is essential not only for performance optimization but also for maintaining sustainable system design at scale.
In many cases, improving latency or reducing token usage can have a direct impact on both user experience and infrastructure cost.
Retrieval Quality (RAG Systems)
In systems that use Retrieval-Augmented Generation (RAG), many failures originate from the retrieval step rather than the model itself.
Important signals include:
- whether relevant documents are retrieved
- how well retrieved context matches the user query
- whether the model actually uses the retrieved information
Poor retrieval can lead to hallucinations or irrelevant answers, even when the underlying model performs well. This is why retrieval monitoring is a critical part of LLM observability. In systems that rely heavily on retrieval, analyzing retrieval logs and query patterns becomes critical. This often requires systems capable of handling large volumes of structured and semi-structured data, where analytical databases such as Apache Doris may be used to support query analysis and debugging workflows.
Errors, Failures, and Edge Cases
LLM failures often look different from traditional system errors.
Instead of explicit crashes, issues may appear as:
- incomplete or vague responses
- hallucinated or fabricated information
- incorrect tool usage in agent systems
- unexpected or off-topic outputs
These edge cases are often harder to detect because they may not trigger standard error signals. Observability systems therefore need to capture both explicit failures and subtle quality degradations.
A Practical Insight
No single metric can fully capture LLM performance.
Most production systems rely on a combination of:
- quantitative metrics (latency, token usage, error rates)
- qualitative evaluation (human feedback, relevance scoring)
- system-level signals (retrieval quality, workflow traces)
Effective LLM observability is not about tracking more metrics—it is about tracking the right signals and understanding how they interact.
How LLM Observability Works (System-Level View)
In a modern AI system, observability is not a single component—it spans the entire pipeline.
A typical LLM-powered workflow looks like this:
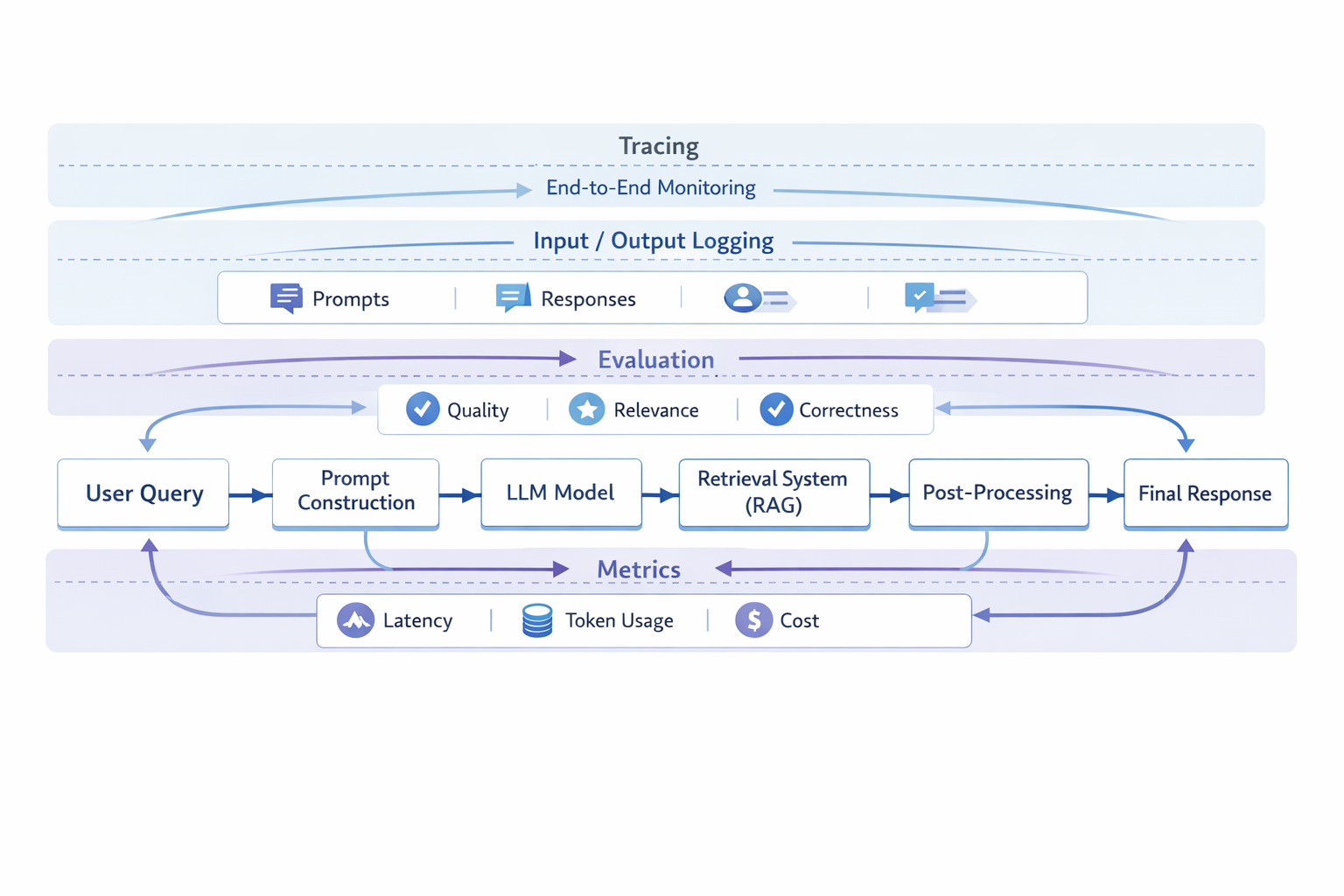
Observability works by capturing signals at each step of this pipeline.
For example:
- tracing how a request flows through multiple components
- capturing prompts and generated outputs
- logging retrieval results and context
- measuring latency and token usage
- evaluating output quality
This allows teams to reconstruct what happened during a specific interaction and identify where issues originate—whether in the prompt, retrieval step, or model response.
In practice, observability data is often analyzed across many interactions, helping identify recurring failure patterns, performance bottlenecks, or cost inefficiencies.
LLM Observability vs Monitoring vs AI Observability
These terms are often used interchangeably, but they represent different levels of system visibility and serve different purposes in practice.
At a high level:
- Monitoring focuses on detecting issues through metrics and alerts
- Observability focuses on understanding system behavior
- LLM observability focuses specifically on how language models behave in real-world applications
- AI observability covers broader machine learning systems beyond just LLMs
The main differences include:
| Concept | Focus |
|---|---|
| Monitoring | Tracks system metrics such as latency, uptime, and errors |
| Observability | Provides deeper insight into system behavior using logs, traces, and metrics |
| LLM Observability | Focuses on prompts, outputs, and model behavior in LLM systems |
| AI Observability | Covers broader machine learning systems, including training and inference |
A Practical Way to Think About the Differences
A useful way to understand the relationship between these concepts is:
- Monitoring tells you when something is wrong
- Observability helps you understand why it is wrong
- LLM observability explains how the model contributed to the problem
- AI observability provides a broader view across all ML systems
These layers are not mutually exclusive—they are often used together in production systems.
Common Challenges in LLM Observability
In practice, implementing LLM observability is far from trivial.
Unlike traditional systems, many issues in LLM applications are not clearly defined as “failures,” which makes them harder to detect and diagnose.
Key challenges include:
Evaluating subjective outputs
Many LLM responses do not have a single correct answer. A response can be technically correct but still irrelevant, incomplete, or poorly phrased. This makes evaluation highly context-dependent and difficult to standardize.
Lack of ground truth
In many use cases—such as open-ended Q&A or conversational systems—there is no definitive reference answer. As a result, it can be difficult to measure accuracy or track improvements over time.
High cost of logging and storage
Capturing prompts, outputs, traces, and intermediate steps at scale can quickly become expensive. Teams often need to balance observability depth with storage and processing costs.
Debugging multi-step pipelines
Modern LLM systems often include retrieval (RAG), tools, or chained model calls. When something goes wrong, the root cause may lie in any part of the pipeline, making debugging more complex.
Noisy signals (false positives)
Metrics do not always reflect real user experience. For example, a response may pass automated evaluation but still be unhelpful to users, or vice versa.
A common pattern is that collecting observability data is relatively easy, but interpreting it correctly—and turning it into actionable improvements—is significantly harder.
LLM Observability Tools (And How to Choose)
LLM observability tools generally fall into a few categories, each addressing a different part of the problem.
Tracing-focused tools
These tools capture how requests flow through the system, including prompts, model calls, and intermediate steps. They are useful for debugging workflows and understanding execution paths.
Evaluation-focused tools
These tools focus on measuring output quality using automated scoring, benchmarks, or human feedback. They help assess whether the system is producing useful and accurate results.
Full-stack observability platforms
These platforms combine tracing, evaluation, and monitoring, providing a more complete view of system behavior across the entire pipeline.
Choosing the right approach depends on several factors:
- the complexity of the application (simple chat vs multi-step AI systems)
- whether the system includes RAG or agents
- the need for real-time monitoring versus offline analysis
- scalability, data volume, and cost constraints
In practice, many production systems use a combination of tools rather than relying on a single solution.
A useful way to think about this is that tracing helps you understand what happened, evaluation helps you understand how good the result was, and monitoring helps you track system performance over time.
Best Practices for LLM Monitoring and Observability
Common best practices include:
Start with tracing before optimization
Before improving performance or quality, it is important to understand how the system behaves end-to-end. Tracing provides the foundation for identifying bottlenecks and failure points.
Evaluate outputs, not just system metrics
Latency and cost are important, but they do not reflect whether the system is actually useful. Output quality—relevance, correctness, and clarity—should be treated as a first-class signal.
Combine automated and human evaluation
Automated metrics can scale, but they may miss subtle issues in language quality. Human feedback helps capture real-world usefulness and edge cases.
Monitor retrieval in RAG systems
In many cases, issues attributed to the model are actually caused by poor retrieval. Monitoring retrieval quality is essential for diagnosing these problems.
Design for cost visibility early
Token usage and infrastructure costs can increase rapidly as usage grows. Tracking cost-related metrics early helps prevent unexpected scaling issues.
In practice, effective observability is not about collecting more data, but about focusing on the signals that directly impact system behavior and user experience.
The Future of LLM Observability
LLM observability is evolving as AI systems become more complex and move into production environments.
Several trends are emerging:
Agent observability
As AI agents become more common, observability is expanding to cover multi-step reasoning, tool usage, and decision chains rather than single model calls.
Real-time evaluation
Systems are shifting from offline analysis to continuous, real-time feedback, allowing faster iteration and adaptation.
AI-native monitoring approaches
New approaches are being developed specifically for generative AI workloads, where traditional monitoring methods are not sufficient.
Feedback-driven improvement loops
User interactions, feedback signals, and evaluation results are increasingly used to continuously improve prompts, retrieval strategies, and system behavior.
Overall, LLM observability is increasingly becoming an important part of how AI systems are designed, operated, and improved over time.
FAQ
Why is observability critical for LLMs?
LLM observability helps control costs, reduce the risk of hallucinations or harmful outputs, and continuously improve prompt quality and system performance.
What are traces in LLM observability?
Traces record the full sequence of events in an LLM system—from user input to final output—including prompt construction, retrieval steps, API calls, and model responses. They are essential for debugging and understanding system behavior.