Doris stream load principle analysis
Lead:
Stream Load, one of the most commonly used data import methods for Doris users, is a synchronous import method. It allows users to import data into Doris in batch through HTTP access and returns the results of data import. The user can not only directly judge whether the data import is successful through the return body of the HTTP request, but also query the results of historical tasks by executing query SQL on the client.
The Doris import (Load) function is to import the user's original data into the Doris table. And Doris realizes a unified streaming import framework at the bottom. On this basis, Doris provides a very rich import mode to adapt to different data sources and data import requirements. Stream Load is one of the most commonly used data import methods for Doris users. It is a synchronous import method that allows users to import data in CSV format or JSON format into Doris in batch through HTTP access and return the results of data import. User can directly judge whether the data import is successful through the return body of the HTTP request, and can query the results of historical tasks by executing query SQL on the client. In addition, Doris also provides the operation audit function for Stream Load, which can audit the historical Stream Load task information through the audit log. The implementation principle of Stream Load will be deeply analyzed from the aspects of execution process, transaction management, implementation of import plan, data writing and operation audit of Stream Load.
1 Implementation Process
The user submits the HTTP request of Stream Load to the FE, and the FE will forward the data import request to a BE node through HTTP Redirect, which will be the Coordinator of this Stream Load task. In this process, the FE node receiving the request only provides forwarding service. The BE node as the Coordinator is actually responsible for the entire import job, such as sending transaction requests to the Master FE, obtaining import execution plans from the FE, receiving real-time data, distributing data to other Executor BE nodes, and returning results to the user after data import. The user can also submit the HTTP request of Stream Load directly to a specified BE node, and the node will act as the Coordinator of this Stream Load task. During the Stream Load process, the Executor BE node is responsible for writing data to the storage layer.
In the Coordinator BE, all HTTP requests, including Stream Load requests, are processed through a thread pool. A Stream Load task is uniquely identified by the imported Label. The principle block diagram of Stream Load is shown in Figure 1.
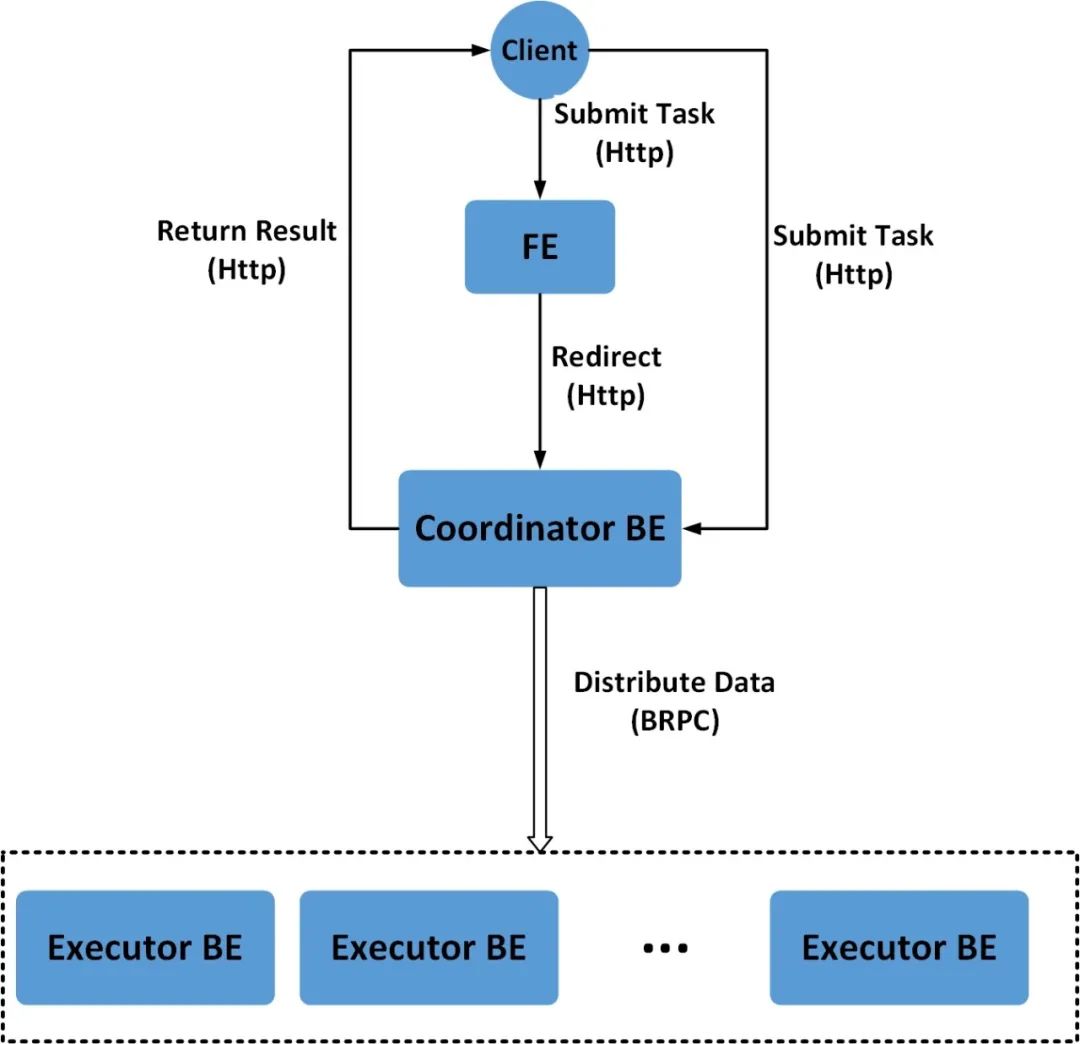
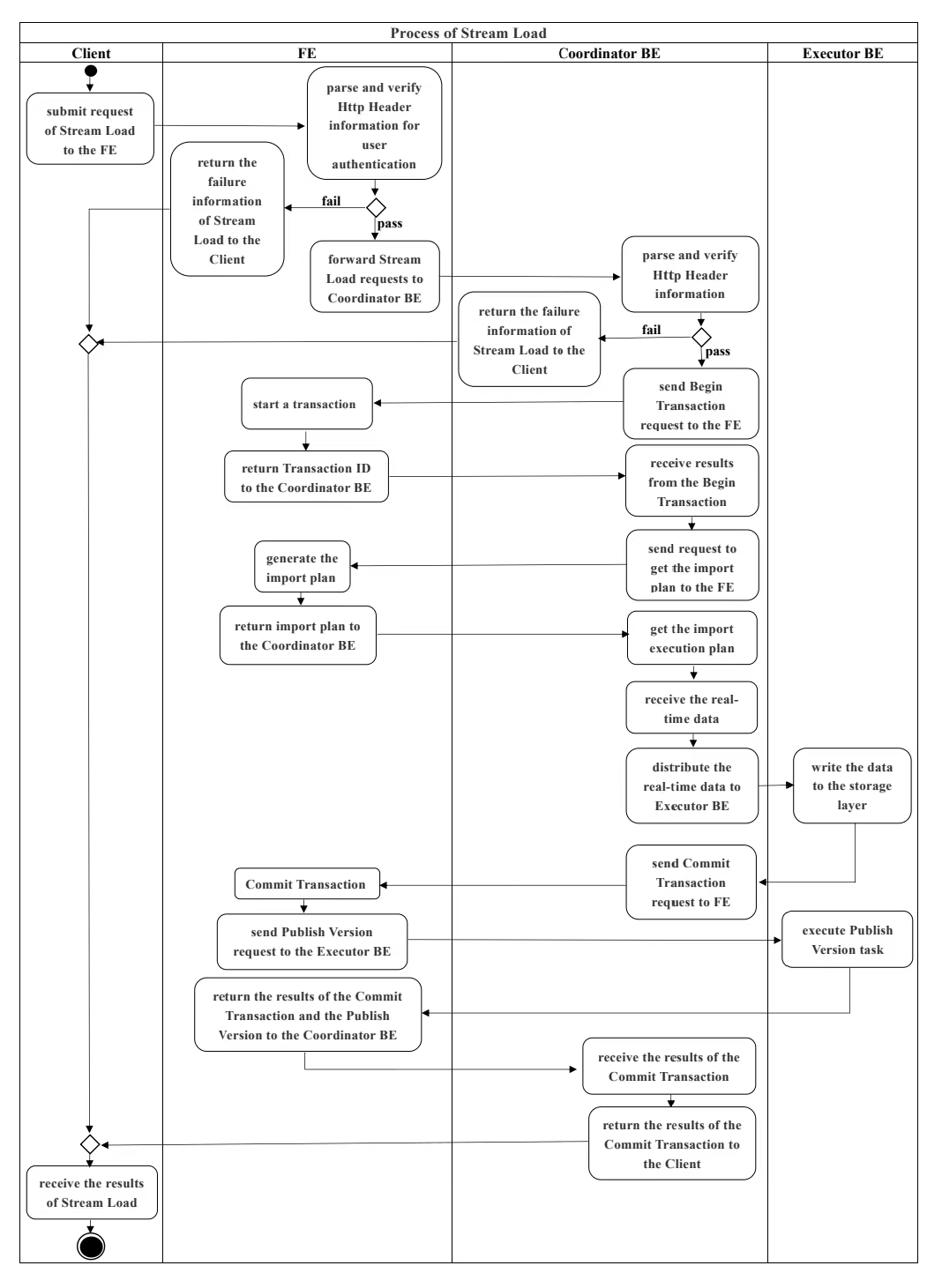
The complete execution process of Stream Load is shown in Figure 2:
(1)The user submits the HTTP request of Stream Load to the FE (the user can also directly submit the HTTP request of Stream Load to the Coordinator BE).
(2)FE, after receiving the Stream Load request submitted by the user, will perform HTTP Header parsing (including the library, table, Label and other information imported by parsing data), and then perform user authentication. If the HTTP Header is successfully resolved and the user authentication passes, the FE will forward the HTTP request of Stream Load to a BE node, which will be the Coordinator of this Stream Load. Otherwise, the FE will directly return the failure information of Stream Load to the user.
(3)After receiving the HTTP request from Stream Load, the Coordinator BE will first perform HTTP Header parsing and data verification, including the file format of the parsed data, the size of the data body, the HTTP timeout, and user authentication. If the Header data verification fails, the Stream Load failure information will be directly returned to the user.
(4)After the HTTP Header data verification is passed, the Coordinator BE will send a Begin Transaction request to the FE through Thrift RPC.
(5)After the FE receives the Begin Transaction request sent by the Coordinator BE, it will start a transaction and return the Transaction ID to the Coordinator BE.
(6)After the Coordinator BE receives the Begin Transaction success information, it will send a request to get the import plan to the FE through Thrift RPC.
(7)After receiving the request for obtaining the import plan sent by the Coordinator BE, the FE will generate the import plan for the Stream Load task and return it to the Coordinator BE.
(8)After receiving the import plan, the Coordinator BE starts to execute the import plan, including receiving the real-time data from HTTP and distributing the real-time data to other Executor BE through BRPC.
(9)After receiving the real-time data distributed by the Coordinator BE, the Executor BE is responsible for writing the data to the storage layer.
(10)After the Executor BE completes data writing, the Coordinator BE sends a Commit Transaction request to the FE through Thrift RPC.
(11)After receiving the Commit Transaction request sent by the Coordinator BE, the FE will commit transaction, send the Publish Version task to the Executor BE, and wait for the Executor BE to execute the Publish Version.
(12)The Executor BE asynchronously executes the Publish Version to change the Rowset generated by data import into a visible data version.
(13)After the Publish Version completes normally or the execution timeout, the FE returns the results of the Commit Transaction and the Publish Version to the Coordinator BE.
(14)The Coordinator BE returns the final result of Stream Load to the user.
2 Transaction Management
Doris ensures the atomicity of data import through Transaction. One Stream Load task corresponds to one transaction. The FE is responsible for the transaction management of Stream Load. The FE receives the Thrift RPC transaction request sent by the Coordinator BE node through the FrontendService. Transaction request types include Begin Transaction, Commit Transaction and Rollback Transaction. The transaction states of Doris include PREPARE, COMMITTED, VISIBLE, and ABORTED. The status flow process of the Stream Load transaction is shown in Figure 3.

The Coordinator BE node will send a Begin Transaction request to the FE before data import. The FE will check whether the label requested by the Begin Transaction already exists. If the label does not exist in the system, it will open a new transaction for the current label, assign a Transaction ID to the transaction, and set the transaction status to PREPARE, then returns the Transaction ID and the success information of the Begin Transaction to the Coordinator BE. Otherwise, this transaction may be a repeated data import. The FE returns the Begin Transaction failure message to the Coordinator BE, and the Stream Load task exits.
After the data is written in all Executor BE nodes, the Coordinator BE node will send a Commit Transaction request to the FE. After receiving the Commit Transaction request, the FE will execute the Commit Transaction and Publish Version operations. First, the FE will judge whether the number of replicas of data successfully written by each Tablet exceeds half of the total number of replicas of the tablet. If the number of replicas of data successfully written by each Tablet exceeds half of the total number of replicas of the Tablet (most of them are successful), the Commit Transaction is successful and the transaction status is set to COMMITTED; Otherwise, the Commit Transaction failure information is returned to the Coordinator BE. The COMMITTED status indicates that the data has been written successfully, but the data is not visible. You need to continue to execute the Publish Version task. After that, the transaction cannot be rolled back.
The FE will have a separate thread to execute the Publish Version on the Transaction with successful Commit. When the Publish Version is executed, the FE will send the Publish Version request to all Executor BE nodes related to the Transaction through Thrift RPC. The Publish Version task is executed asynchronously on each Executor BE node, and the Rowset generated by data import is changed into a visible data version. When all the Publish Version tasks on the Executor BE are successfully executed, the FE will set the transaction status to VISIBLE, and return the Commit Transaction and Publish Version success information to the Coordinator BE. When some Publish Version tasks fail, the FE will repeatedly issue a Publish Version request to the Executor BE node until the previously failed Publish Version task succeeds. If the transaction status has not been set to VISIBLE after a certain timeout period, the FE will return to the Coordinator BE the information that the Commit Transaction was successful but the Publish Version timed out (note that at this time, the data is still written successfully, but it is still invisible, and the user needs to wait for the transaction status to finally become VISIBLE).
When obtaining the import plan from the FE fails, executing data import fails, or Commit Transaction fails, the Coordinator BE node will send a Rollback Transaction request to the FE to execute transaction rollback. After receiving the transaction rollback request, the FE will set the transaction status to ABORTED, and send a Clear Transaction request to the Executor BE through Thrift RPC. The Clear Transaction task is asynchronously executed at the BE node, marking the Rowset generated by data import as unavailable. These Rowset will be deleted from the BE later. Transactions with COMMITTED status (transactions with Commit Transaction succeeded but Publish Version timed out) cannot be rolled back.
3 Execution of the import plan
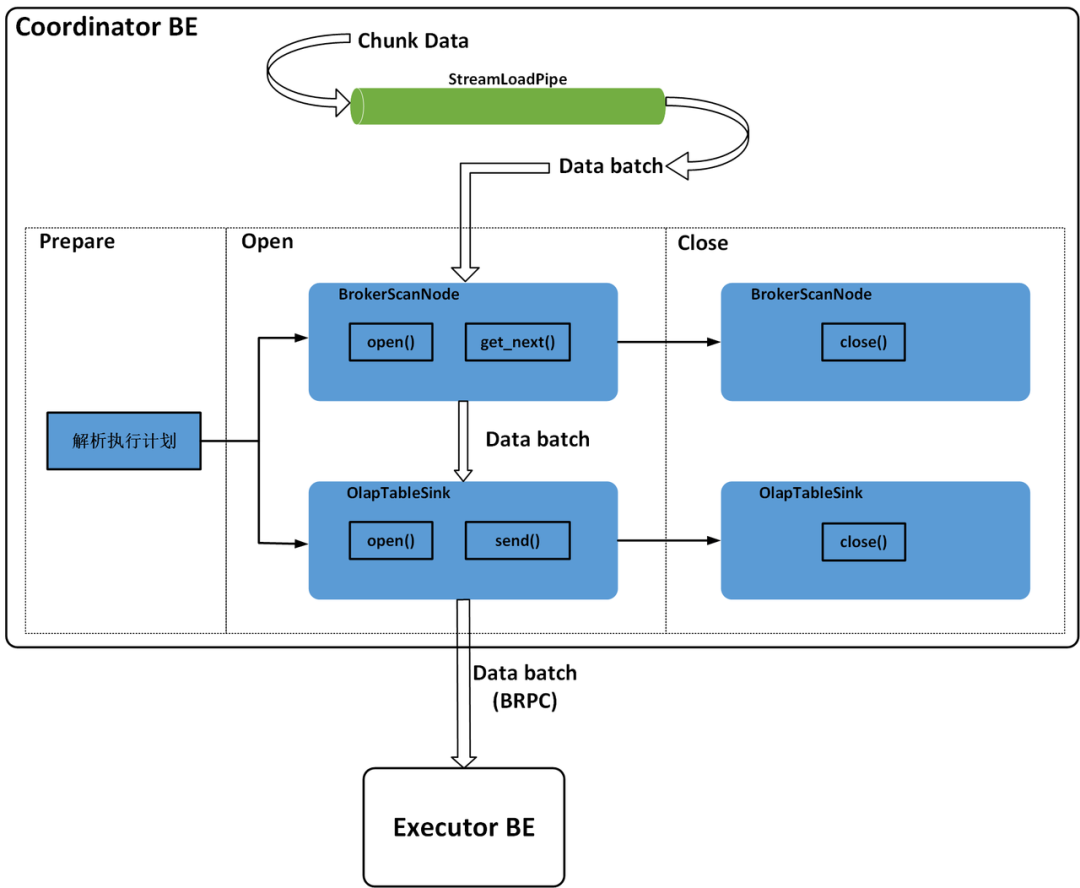
In Doris BE, all execution plans are managed by FragmentMgr, and the execution of each import plan is managed by PlanFragmentExecutor. After the BE obtains the import execution plan from the FE, it will submit the import plan to the thread pool of FragmentMgr for execution. The import execution plan of Stream Load has only one Fragment, including one BrokerScanNode and one OlapTableSink. BrokerScanNode is responsible for reading streaming data in real time and converting the data lines in CSV format or JSON format to the Tuple format of Doris. OlapTableSink is responsible for sending real-time data to the corresponding Executor BE node. The Executor BE node corresponding to each data row is determined by which BE the Tablet where the data row is stored. The Partition and Tablet where the data row is stored can be determined according to the PartitionKey and DistributionKey of the data row. The BE node on which each Tablet and its replica are stored has been determined when the Table or Partition is created.
After importing the execution plan and submitting it to the thread pool of FragmentMgr, the Stream Load thread will receive the real-time data transmitted through HTTP in chunks and write it to the StreamLoadPipe. The BrokerScanNode will read the real-time data in batches from the StreamLoadPipe. OlapTableSink will send the batch data read by the BrokerScanNode to the Executor BE through BRPC for data writing. After all real-time data is written to the StreamLoadPipe, the Stream Load thread will wait for the import plan to finish.
The PlanFragmentExecutor executes a specific import plan process, which consists of three stages: Prepare, Open, and Close. In the Prepare stage, the import execution plan from the FE is mainly analyzed; In the Open stage, BrokerScanNode and OlapTableSink will be opened. BrokerScanNode is responsible for reading the real-time data of one Batch at a time, and OlapTableSink is responsible for calling BRPC to send the data of each Batch to other Executor BE nodes; In the Close stage, it is responsible for waiting for the data import to end and closing the BrokerScanNode and OlapTableSink. The import execution plan of Stream Load is shown in Figure 4.
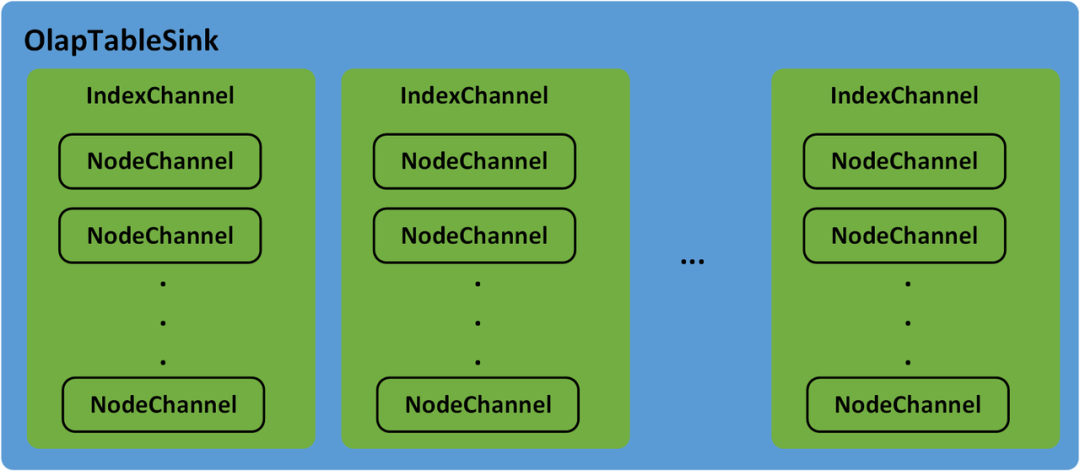
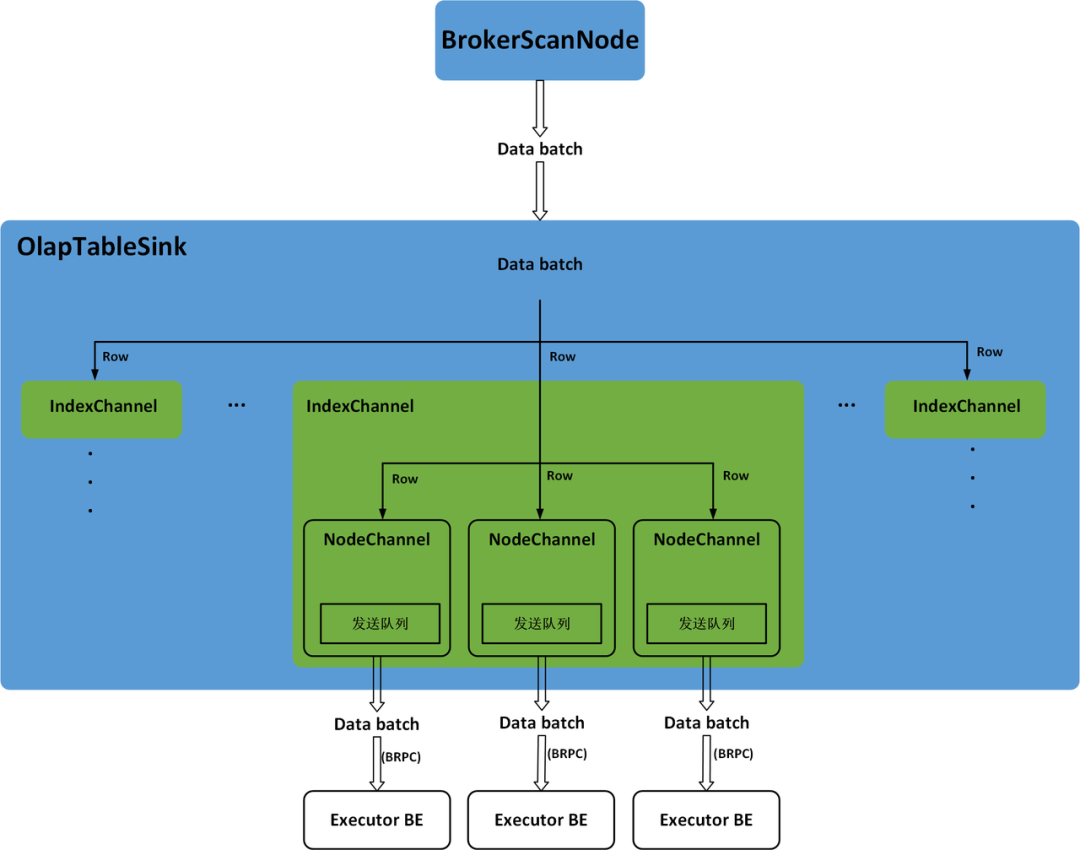
OlapTableSink is responsible for the data distribution of the Stream Load task. Tables in Doris may have Rollup or Materialized view. Each Table and its Rollup and Materialized view are called an Index. In the process of data distribution, the IndexChannel will maintain a data distribution channel of the Index. The Tablet under the Index may have multiple replicas and are distributed on different BE nodes. The NodeChannel will maintain the data distribution channel of an Executor BE node under the IndexChannel. Therefore, the OlapTableSink contains multiple IndexChannel, and each NodeChannel contains multiple NodeChannel, as shown in Figure 5.
When OlapTableSink distributes data, it will read the data Batch obtained by BrokerScanNode row by row, and add the data row to the IndexChannel of each Index. The Partition and Tablet of the data row can be determined according to the PartitionKey and DistributionKey, and then the corresponding Tablet of the data row in other Index can be calculated according to the order of the Tablet in the Partition. Each Tablet may have multiple replicas distributed on different BE nodes. Therefore, in the IndexChannel, each data row will be added to the NodeChannel corresponding to each replica of its Tablet. Each NodeChannel has a send queue. When the new data rows in NodeChannel accumulate to a certain size, they will be added to the send queue as a data Batch. There will be a fixed thread in OlapTableSink to train each NodeChannel under each IndexChannel in turn, and call BRPC to send a data Batch in the sending queue to the corresponding Executor BE. The data distribution process of the Stream Load task is shown in Figure 6.
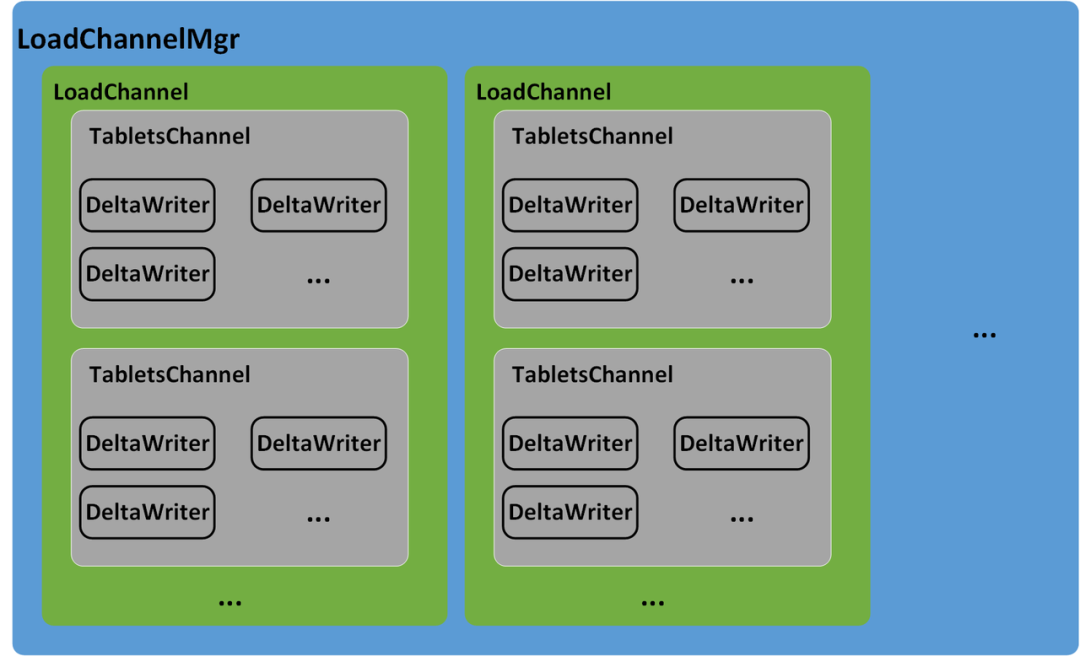
4 Data Write
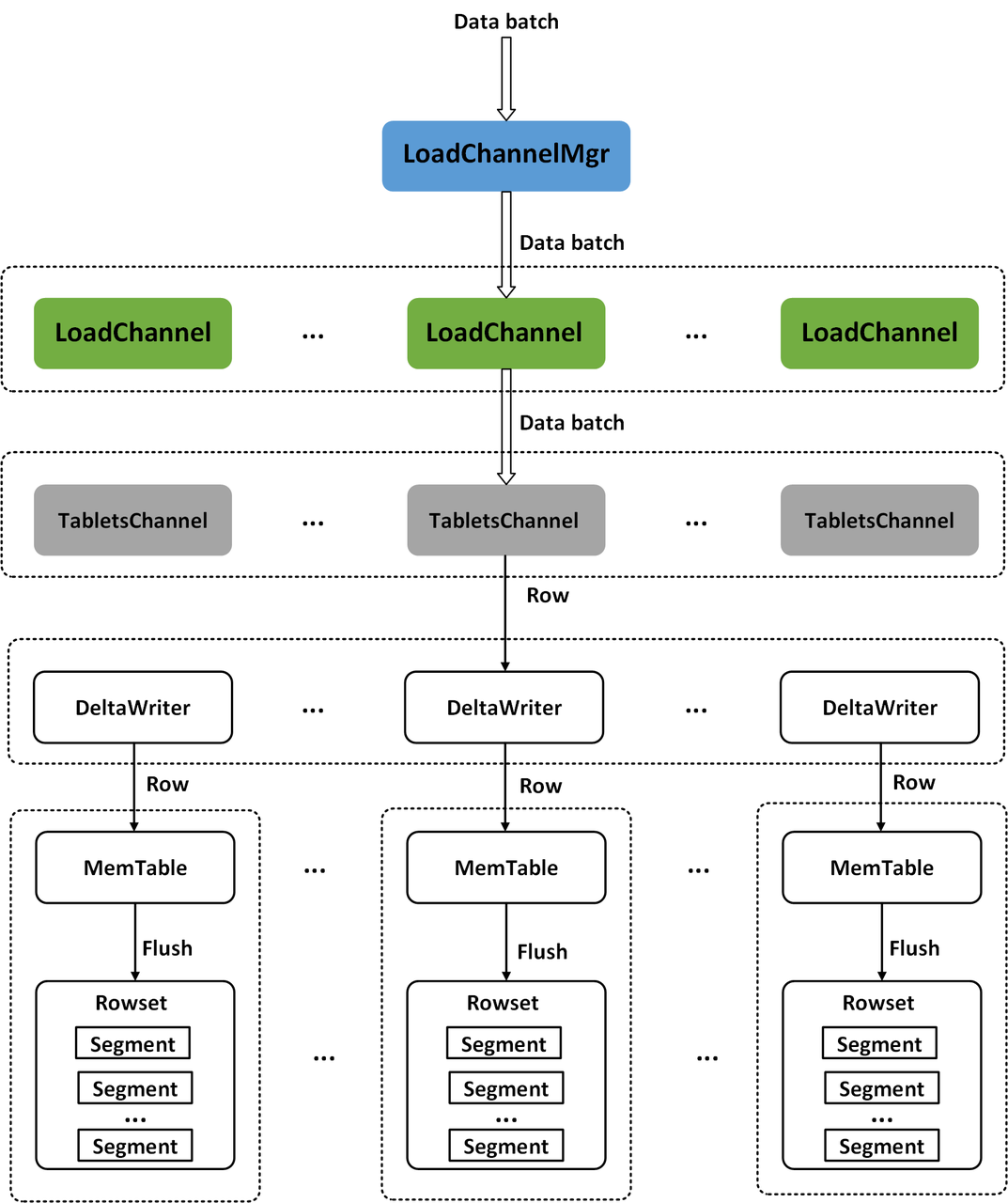
After receiving the data Batch sent by the Coordinator BE, the BRPC server of the Executor BE will submit the data writing task to the thread pool for asynchronous execution. In Doris BE, data is written to the storage layer in a hierarchical manner. Each Stream Load task corresponds to a LoadChannel on each Executor BE. The LoadChannel maintains the data writing channel of a Stream Load task and is responsible for the data writing of a Stream Load task on the current Executor BE node, LoadChannel can write the data of a Stream Load task in the current BE node to the storage layer in batches until the Stream Load task is completed. Each LoadChannel is uniquely identified by the load ID, and all LoadChannel on the BE node are managed by LoadChannelMgr. The Table corresponding to a Stream Load task may have multiple Index. Each Index corresponds to a TabletsChannel, which is uniquely identified by the Index ID. Therefore, there will be multiple TabletsChannel under each LoadChannel. The TabletsChannel maintains an Index data writing channel, which is responsible for managing the data writing of all the Tablet under the Index. The TabletsChannel will read the data Batch row by row and write it to the corresponding Tablet through the DeltaWriter. The DeltaWriter maintains a data writing channel of a Tablet, which is uniquely identified by the Tablet ID. it is responsible for receiving the data import of a single Tablet and writing the data into the MemTable corresponding to the tablet. When the MemTable is full, the data in the MemTable will be flushed to the disk and Segment files will be generated. MemTable adopts the data structure of SkipList to temporarily store the data in memory. SkipList will sort the data rows according to the Key of Schema. In addition, if the data model is Aggregate or Unique, MemTable will aggregate data rows with the same Key. The data write channel of the Stream Load task is shown in Figure 7.
The Flush operation of MemTable is performed asynchronously by MemtableFlushExecutor. After the MemTable Flush task is submitted to the thread pool, a new MemTable will be generated to receive the subsequent data writing of the current Tablet. When the MemtableFlushExecutor performs data Flush, the RowsetWriter will read out all the data in the MemTable and write out multiple Segment files through the SegmentWriter. The size of each Segment file is no more than 256MB. For a Tablet, each Stream Load task will generate a newRowset. The generated Rowset can contain multiple Segment files. The data writing process of the Stream Load task is shown in Figure 8.
The TxnManager on the Executor BE node is responsible for transaction management of Tablet level data import. When the Delta Writer is initialized, the PrepareTransaction will be executed to add the data write transaction of the corresponding Tablet in the current Stream Load task to the TxnManager for management. When the data write Tablet is completed and the DeltaWriter is closed, the Commit Transaction will be executed to add the new Rowset generated by the data import to the TxnManager for management. Note that the TxnManager here is only responsible for the transactions on a single BE, while the transaction management in the FE is responsible for the overall import of transactions.
After the data import is completed, when the Executor BE executes the Publish Version task issued by the FE, it will execute the Publish Transaction to change the new Rowset generated by the data import into a visible version, and delete the data writing task of the corresponding Tablet in the current Stream Load task from the TxnManager. This means that the data writing transaction of the Tablet in the current Stream Load task ends.
5 Stream Load Operation Audit
Doris adds the operation audit function to Stream Load. After each Stream Load task is completed and the results are returned to the user, the Coordinator BE will persistently store the detailed information of this Stream Load task on the local RocksDB. The Master FE periodically pulls the information of the completed Stream Load task from each BE node of the cluster through Thrift RPC, pulls a batch of Stream Load operation records from one BE node at a time, and writes the pulled Stream Load task information into the audit log (fe.audit.log). Each Stream Load task information stored on the BE will be set with an expiration time (TTL), and the expired Stream Load task information will be deleted when RocksDB executes the Compaction. The user can audit the historical Stream Load task information through the FE audit log.
When the FE writes the pulled Stream Load task information into the Audit log, it will keep a copy in the memory. In order to prevent memory expansion, a fixed number of Stream Load task information will be kept in the memory. As the subsequent data pulling continues, the early Stream Load task information will be gradually eliminated from the FE memory. The user can query the latest Stream Load task information by executing the SHOW STREAM LOAD command at the client.
Summary
In this paper, the implementation principle of Stream Load is deeply analyzed from the aspects of execution process, transaction management, implementation of import plan, data writing and operation audit of Stream Load. Stream Load is one of the most commonly used data import methods for Doris users. It is a synchronous import method that allows users to import data into Doris in batch through HTTP access and return the results of data import. The user can not only directly judge whether the data import is successful through the return body of the HTTP request, but also query the results of historical tasks by executing query SQL on the client. Otherwise, Doris also provides the result audit function for Stream Load, which can audit the historical Stream Load task information through the audit log.