New milestone: Apache Doris 2.0.0 just released
We are more than excited to announce that, after six months of coding, testing, and fine-tuning, Apache Doris 2.0.0 is now production-ready. Special thanks to the 275 committers who altogether contributed over 4100 optimizations and fixes to the project.
This new version highlights:
- 10 times faster data queries
- Enhanced log analytic and federated query capabilities
- More efficient data writing and updates
- Improved multi-tenant and resource isolation mechanisms
- Progresses in elastic scaling of resources and storage-compute separation
- Enterprise-facing features for higher usability
Download: https://doris.apache.org/download
GitHub source code: https://github.com/apache/doris/releases/tag/2.0.0-rc04
A 10 Times Performance Increase
In SSB-Flat and TPC-H benchmarking, Apache Doris 2.0.0 delivered over 10-time faster query performance compared to an early version of Apache Doris.
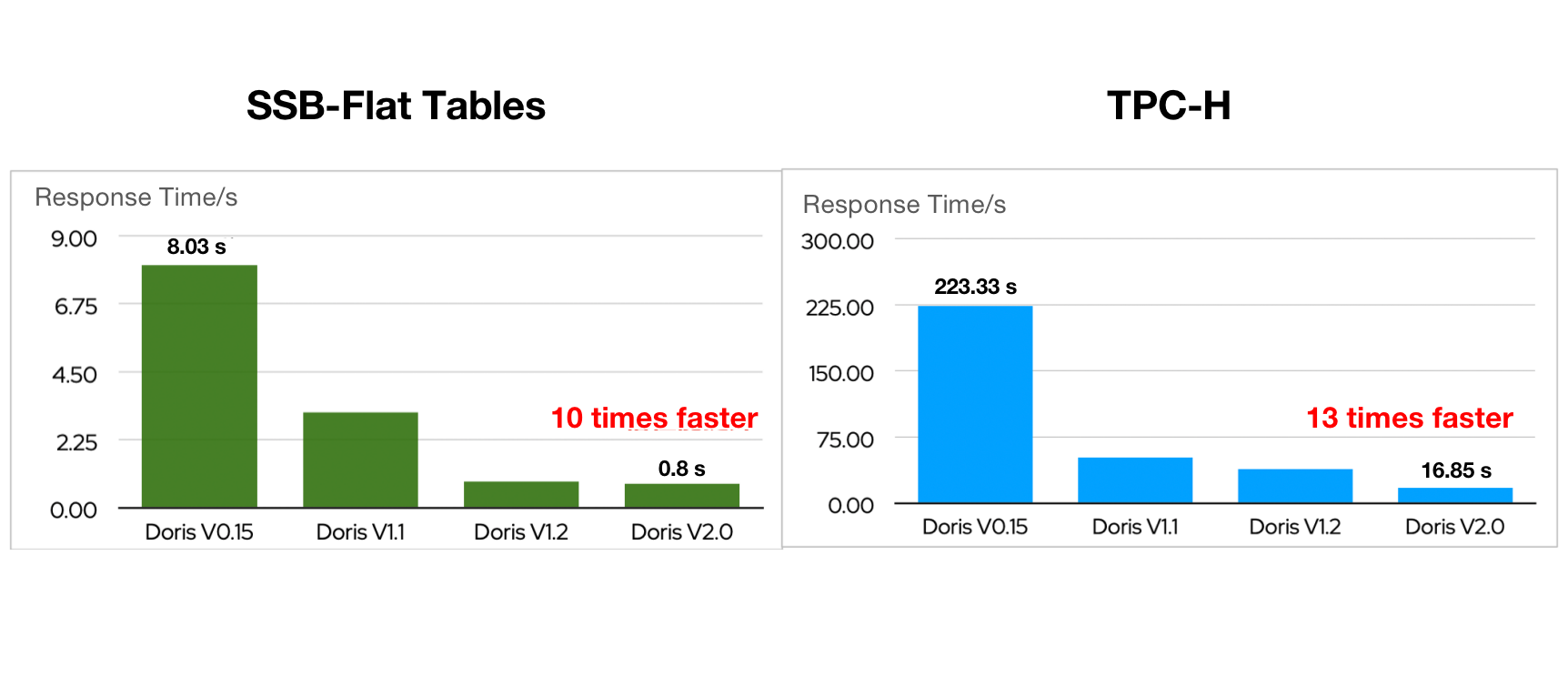
This is realized by the introduction of a smarter query optimizer, inverted index, a parallel execution model, and a series of new functionalities to support high-concurrency point queries.
A smarter query optimizer
The brand new query optimizer, Nereids, has a richer statistical base and adopts the Cascades framework. It is capable of self-tuning in most query scenarios and supports all 99 SQLs in TPC-DS, so users can expect high performance without any fine-tuning or SQL rewriting.
TPC-H tests showed that Nereids, with no human intervention, outperformed the old query optimizer by a wide margin. Over 100 users have tried Apache Doris 2.0.0 in their production environment and the vast majority of them reported huge speedups in query execution.
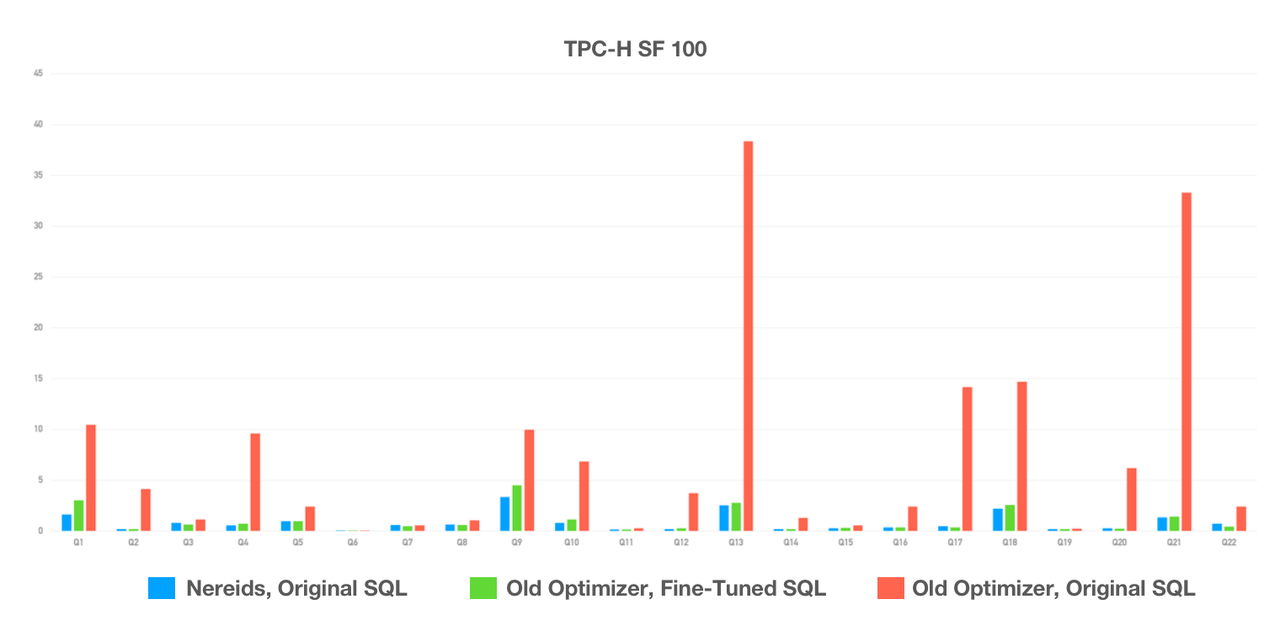
Doc: https://doris.apache.org/docs/dev/query-acceleration/nereids/
Nereids is enabled by default in Apache Doris 2.0.0: SET enable_nereids_planner=true. Nereids collects statistical data by calling the Analyze command.
Inverted Index
In Apache Doris 2.0.0, we introduced inverted index to better support fuzzy keyword search, equivalence queries, and range queries.
A smartphone manufacturer tested Apache Doris 2.0.0 in their user behavior analysis scenarios. With inverted index enabled, v2.0.0 was able to finish the queries within milliseconds and maintain stable performance as the query concurrency level went up. In this case, it is 5 to 90 times faster than its old version.
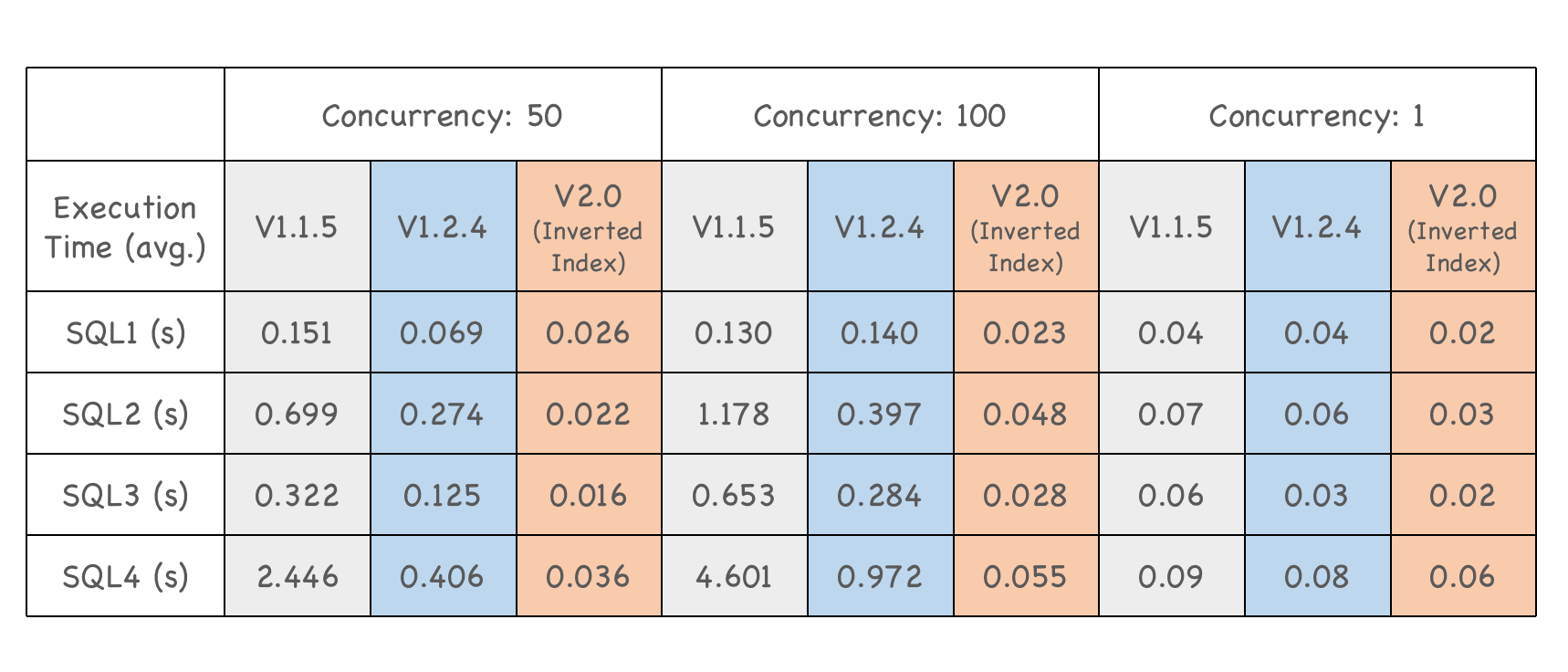
20 times higher concurrency capability
In scenarios like e-commerce order queries and express tracking, a huge number of end data users search for a certain data record simultaneously. These are what we call high-concurrency point queries, which can bring huge pressure on the system. A traditional solution is to introduce Key-Value stores like Apache HBase for such queries, and Redis as a cache layer to ease the burden, but that means redundant storage and higher maintenance costs.
For a column-oriented DBMS like Apache Doris, the I/O usage of point queries will be multiplied. We need neater execution. Thus, on the basis of columnar storage, we added row storage format and row cache to increase row reading efficiency, short-circuit plans to speed up data retrieval, and prepared statements to reduce frontend overheads.
After these optimizations, Apache Doris 2.0 reached a concurrency level of 30,000 QPS per node on YCSB on a 16 Core 64G cloud server with 4×1T hard drives, representing an improvement of 20 times compared to its older version. This makes Apache Doris a good alternative to HBase in high-concurrency scenarios, so that users don't need to endure extra maintenance costs and redundant storage brought by complicated tech stacks.
Read more: https://doris.apache.org/blog/How-We-Increased-Database-Query-Concurrency-by-20-Times
A self-adaptive parallel execution model
Apache 2.0 brought in a Pipeline execution model for higher efficiency and stability in hybrid analytic workloads. In this model, the execution of queries is driven by data. The blocking operators in all query execution processes are split into pipelines. Whether a pipeline gets an execution thread depends on whether its relevant data is ready. This enables asynchronous blocking operations and more flexible system resource management. Also, this improves CPU efficiency as the system doesn't have to create and destroy threads that much.
Doc: https://doris.apache.org/docs/dev/query-acceleration/pipeline-execution-engine/
How to enable the Pipeline execution model
- The Pipeline execution engine is enabled by default in Apache Doris 2.0:
Set enable_pipeline_engine = true. parallel_pipeline_task_numrepresents the number of pipeline tasks that are parallelly executed in SQL queries. The default value of it is0, which means Apache Doris will automatically set the concurrency level to half the number of CPUs in each backend node. Users can change this value as they need it.- For those who are upgrading to Apache Doris 2.0 from an older version, it is recommended to set the value of
parallel_pipeline_task_numto that ofparallel_fragment_exec_instance_numin the old version.
A Unified Platform for Multiple Analytic Workloads
Apache Doris has been pushing its boundaries. Starting as an OLAP engine for reporting, it is now a data warehouse capable of ETL/ELT and more. Version 2.0 is making advancements in its log analysis and data lakehousing capabilities.
A 10 times more cost-effective log analysis solution
Apache Doris 2.0.0 provides native support for semi-structured data. In addition to JSON and Array, it now supports a complex data type: Map. Based on Light Schema Change, it also supports Schema Evolution, which means you can adjust the schema as your business changes. You can add or delete fields and indexes, and change the data types for fields. As we introduced inverted index and a high-performance text analysis algorithm into it, it can execute full-text search and dimensional analysis of logs more efficiently. With faster data writing and query speed and lower storage cost, it is 10 times more cost-effective than the common log analytic solution within the industry.
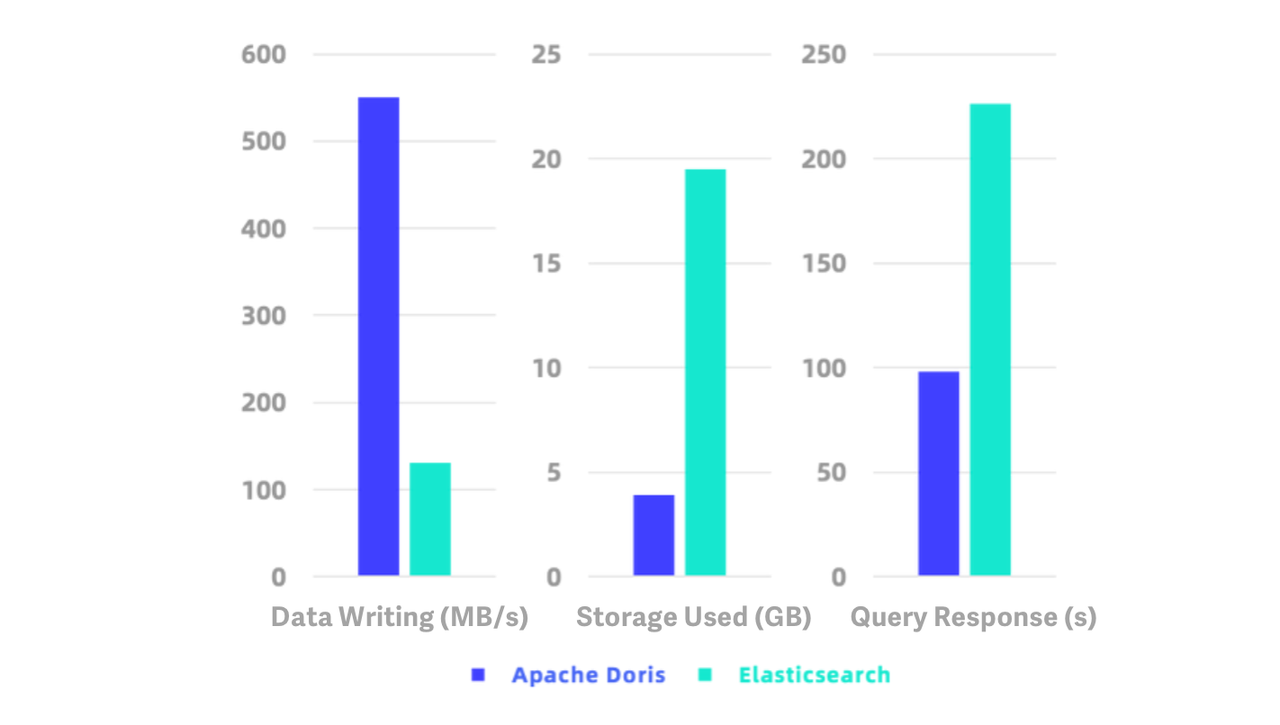
Enhanced data lakehousing capabilities
In Apache Doris 1.2, we introduced Multi-Catalog to allow for auto-mapping and auto-synchronization of data from heterogeneous sources. In version 2.0.0, we extended the list of data sources supported and optimized Doris for based on users' needs in production environment.
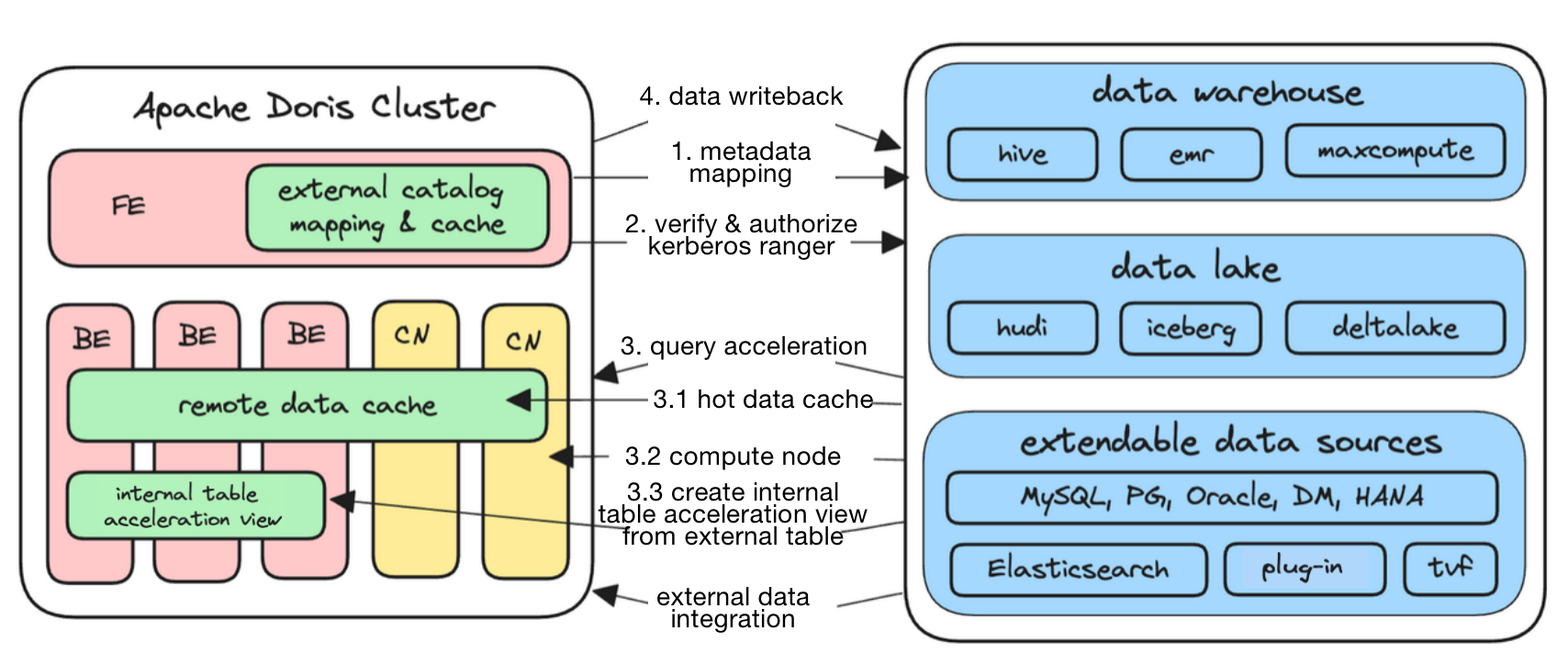
Apache Doris 2.0.0 supports dozens of data sources including Hive, Hudi, Iceberg, Paimon, MaxCompute, Elasticsearch, Trino, ClickHouse, and almost all open lakehouse formats. It also supports snapshot queries on Hudi Copy-on-Write tables and read optimized queries on Hudi Merge-on-Read tables. It allows for authorization of Hive Catalog using Apache Ranger, so users can reuse their existing privilege control system. Besides, it supports extensible authorization plug-ins to enable user-defined authorization methods for any catalog.
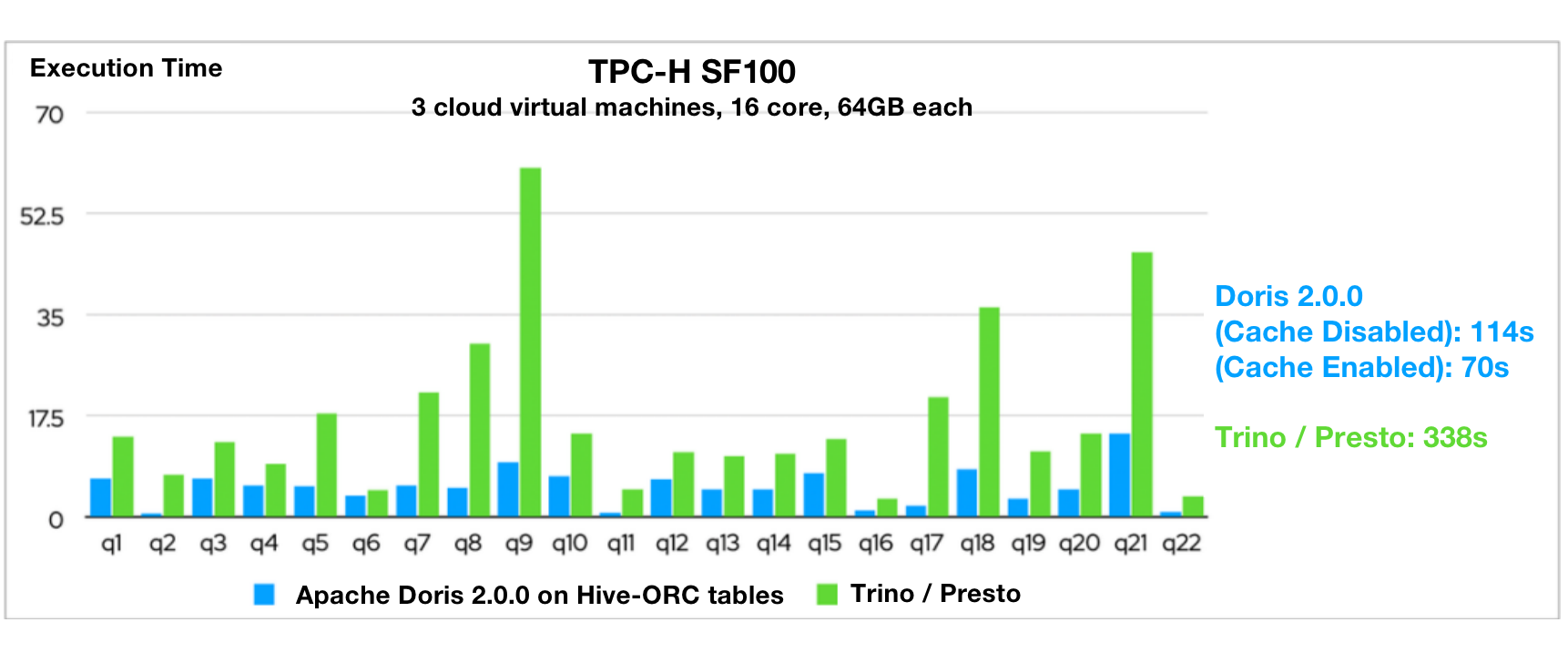
TPC-H benchmark tests showed that Apache Doris 2.0.0 is 3~5 times faster than Presto/Trino in queries on Hive tables. This is realized by all-around optimizations (in small file reading, flat table reading, local file cache, ORC/Parquet file reading, Compute Nodes, and information collection of external tables) finished in this development cycle and the distributed execution framework, vectorized execution engine, and query optimizer of Apache Doris.
All this gives Apache Doris 2.0.0 an edge in data lakehousing scenarios. With Doris, you can do incremental or overall synchronization of multiple upstream data sources in one place, and expect much higher data query performance than other query engines. The processed data can be written back to the sources or provided for downstream systems. In this way, you can make Apache Doris your unified data analytic gateway.
Efficient Data Update
Data update is important in real-time analysis, since users want to always be accessible to the latest data, and be able to update data flexibly, such as updating a row or just a few columns, batching updating or deleting their specified data, or even overwriting a whole data partition.
Efficient data updating has been another hill to climb in data analysis. Apache Hive only supports updates on the partition level, while Hudi and Iceberg do better in low-frequency batch updates instead of real-time updates due to their Merge-on-Read and Copy-on-Write implementations.
As for data updating, Apache Doris 2.0.0 is capable of:
- Faster data writing: In the pressure tests with an online payment platform, under 20 concurrent data writing tasks, Doris reached a writing throughput of 300,000 records per second and maintained stability throughout the over 10-hour continuous writing process.
- Partial column update: Older versions of Doris implements partial column update by
replace_if_not_nullin the Aggregate Key model. In 2.0.0, we enable partial column updates in the Unique Key model. That means you can directly write data from multiple source tables into a flat table, without having to concatenate them into one output stream using Flink before writing. This method avoids a complicated processing pipeline and the extra resource consumption. You can simply specify the columns you need to update. - Conditional update and deletion: In addition to the simple Update and Delete operations, we realize complicated conditional updates and deletes operations on the basis of Merge-on-Write.
Faster, Stabler, and Smarter Data Writing
Higher speed in data writing
As part of our continuing effort to strengthen the real-time analytic capability of Apache Doris, we have improved the end-to-end real-time data writing capability of version 2.0.0. Benchmark tests reported higher throughput in various writing methods:
- Stream Load, TPC-H 144G lineitem table, 48-bucket Duplicate table, triple-replica writing: throughput increased by 100%
- Stream Load, TPC-H 144G lineitem table, 48-bucket Unique Key table, triple-replica writing: throughput increased by 200%
- Insert Into Select, TPC-H 144G lineitem table, 48-bucket Duplicate table: throughput increased by 50%
- Insert Into Select, TPC-H 144G lineitem table, 48-bucket Unique Key table: throughput increased by 150%
Greater stability in high-concurrency data writing
The sources of system instability often includes small file merging, write amplification, and the consequential disk I/O and CPU overheads. Hence, we introduced Vertical Compaction and Segment Compaction in version 2.0.0 to eliminate OOM errors in compaction and avoid the generation of too many segment files during data writing. After such improvements, Apache Doris can write data 50% faster while using only 10% of the memory that it previously used.
Read more: https://doris.apache.org/blog/Understanding-Data-Compaction-in-3-Minutes/
Auto-synchronization of table schema
The latest Flink-Doris-Connector allows users to synchronize an entire database (such as MySQL and Oracle) to Apache Doris by one simple step. According to our test results, one single synchronization task can support the real-time concurrent writing of thousands of tables. Users no longer need to go through a complicated synchronization procedure because Apache Doris has automated the process. Changes in the upstream data schema will be automatically captured and dynamically updated to Apache Doris in a seamless manner.
Read more: https://doris.apache.org/blog/Auto-Synchronization-of-an-Entire-MySQL-Database-for-Data-Analysis
A New Multi-Tenant Resource Isolation Solution
The purpose of multi-tenant resource isolation is to avoid resource preemption in the case of heavy loads. For that sake, older versions of Apache Doris adopted a hard isolation plan featured by Resource Group: Backend nodes of the same Doris cluster would be tagged, and those of the same tag formed a Resource Group. As data was ingested into the database, different data replicas would be written into different Resource Groups, which will be responsible for different workloads. For example, data reading and writing will be conducted on different data tablets, so as to realize read-write separation. Similarly, you can also put online and offline business on different Resource Groups.
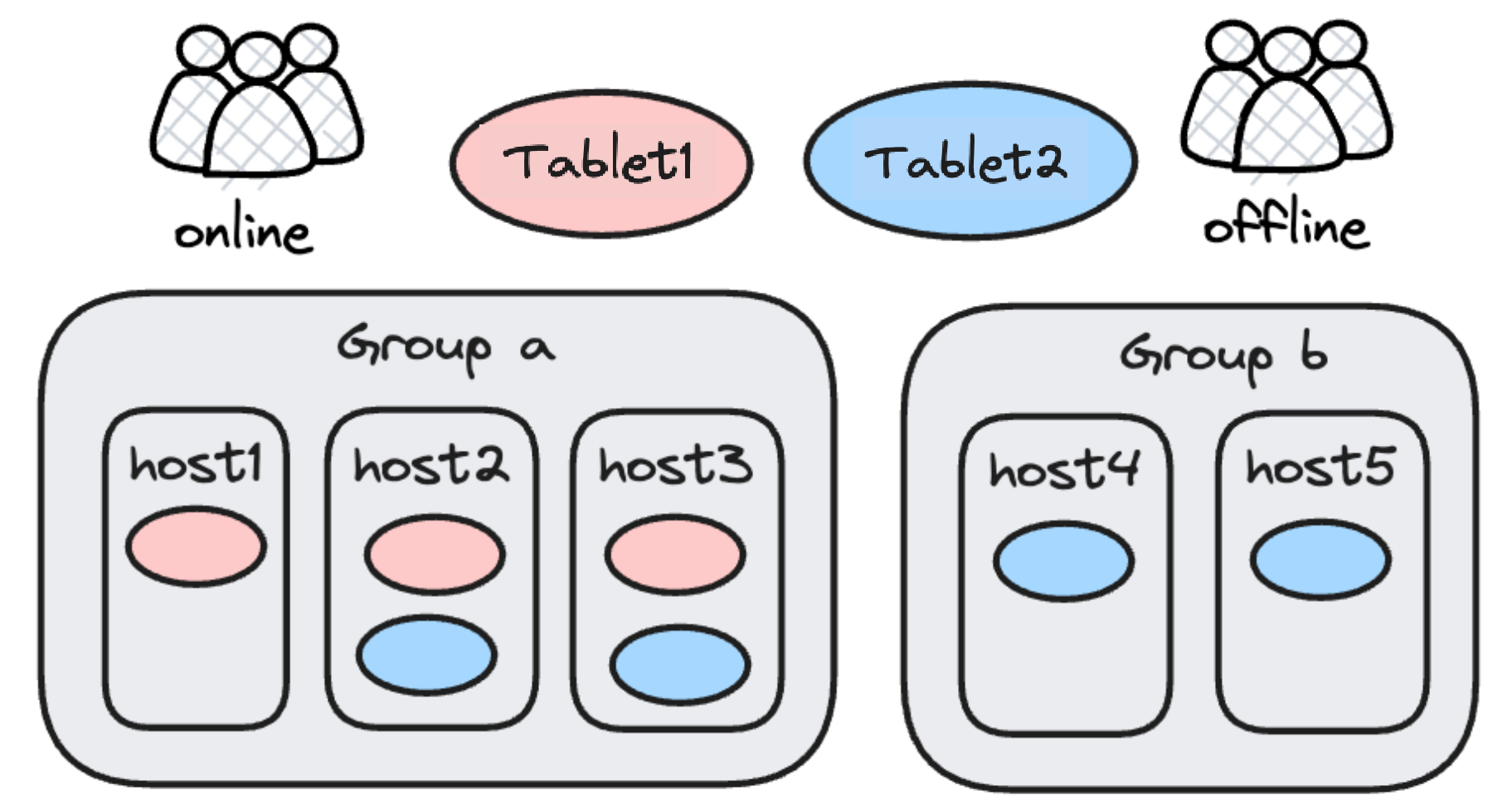
This is an effective solution, but in practice, it happens that some Resource Groups are heavily occupied while others are idle. We want a more flexible way to reduce vacancy rate of resources. Thus, in 2.0.0, we introduce Workload Group resource soft limit.
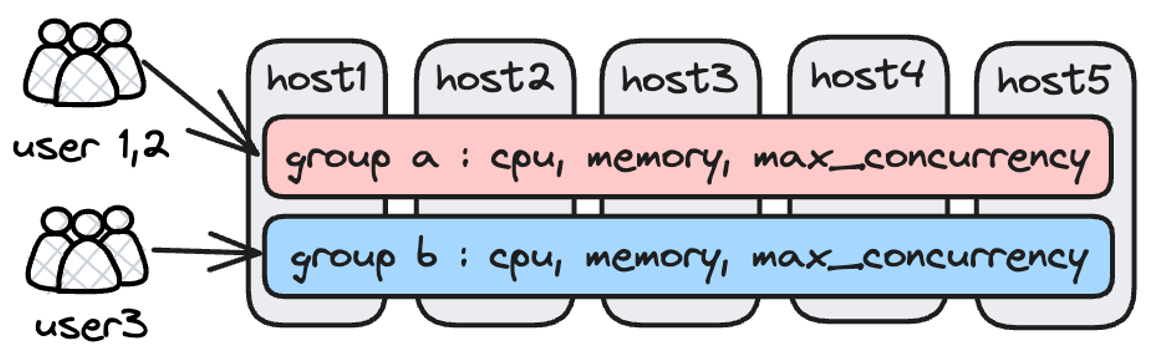
The idea is to divide workloads into groups to allow for flexible management of CPU and memory resources. Apache Doris associates a query with a Workload Group, and limits the percentage of CPU and memory that a single query can use on a backend node. The memory soft limit can be configured and enabled by the user.
When there is a cluster resource shortage, the system will kill the largest memory-consuming query tasks; when there are sufficient cluster resources, once a Workload Group uses more resources than expected, the idle cluster resources will be shared among all the Workload Groups to give full play to the system memory and ensure stable execution of queries. You can also prioritize the Workload Groups in terms of resource allocation. In other words, you can decide which tasks can be assigned with adequate resources and which not.
Meanwhile, we introduced Query Queue in 2.0.0. Upon Workload Group creation, you can set a maximum query number for a query queue. Queries beyond that limit will wait for execution in the queue. This is to reduce system burden under heavy workloads.
Elastic Scaling and Storage-Compute Separation
When it comes to computation and storage resources, what do users want?
- Elastic scaling of computation resources: Scale up resources quickly in peak times to increase efficiency and scale down in valley times to reduce costs.
- Lower storage costs: Use low-cost storage media and separate storage from computation.
- Separation of workloads: Isolate the computation resources of different workloads to avoid preemption.
- Unified management of data: Simply manage catalogs and data in one place.
To separate storage and computation is a way to realize elastic scaling of resources, but it demands more efforts in maintaining storage stability, which determines the stability and continuity of OLAP services. To ensure storage stability, we introduced mechanisms including cache management, computation resource management, and garbage collection.
In this respect, we divide our users into three groups after investigation:
- Users with no need for resource scaling
- Users requiring resource scaling, low storage costs, and workload separation from Apache Doris
- Users who already have a stable large-scale storage system and thus require an advanced compute-storage-separated architecture for efficient resource scaling
Apache Doris 2.0 provides two solutions to address the needs of the first two types of users.
- Compute nodes. We introduced stateless compute nodes in version 2.0. Unlike the mix nodes, the compute nodes do not save any data and are not involved in workload balancing of data tablets during cluster scaling. Thus, they are able to quickly join the cluster and share the computing pressure during peak times. In addition, in data lakehouse analysis, these nodes will be the first ones to execute queries on remote storage (HDFS/S3) so there will be no resource competition between internal tables and external tables.
- Hot-cold data separation. Hot/cold data refers to data that is frequently/seldom accessed, respectively. Generally, it makes more sense to store cold data in low-cost storage. Older versions of Apache Doris support lifecycle management of table partitions: As hot data cooled down, it would be moved from SSD to HDD. However, data was stored with multiple replicas on HDD, which was still a waste. Now, in Apache Doris 2.0, cold data can be stored in object storage, which is even cheaper and allows single-copy storage. That reduces the storage costs by 70% and cuts down the computation and network overheads that come with storage.
For neater separate of computation and storage, the VeloDB team is going to contribute the Cloud Compute-Storage-Separation solution to the Apache Doris project. The performance and stability of it has stood the test of hundreds of companies in their production environment. The merging of code will be finished by October this year, and all Apache Doris users will be able to get an early taste of it in September.
Enhanced Usability
Apache Doris 2.0.0 also highlights some enterprise-facing functionalities.
Support for Kubernetes Deployment
Older versions of Apache Doris communicate based on IP, so any host failure in Kubernetes deployment that causes a POD IP drift will lead to cluster unavailability. Now, version 2.0 supports FQDN. That means the failed Doris nodes can recover automatically without human intervention, which lays the foundation for Kubernetes deployment and elastic scaling.
Support for Cross-Cluster Replication (CCR)
Apache Doris 2.0.0 supports cross-cluster replication (CCR). Data changes at the database/table level in the source cluster will be synchronized to the target cluster. You can choose to replicate the incremental data or the overall data.
It also supports synchronization of DDL, which means DDL statements executed by the source cluster can also by automatically replicated to the target cluster.
It is simple to configure and use CCR in Doris. Leveraging this functionality, you can implement read-write separation and multi-datacenter replication
This feature allows for higher availability of data, read/write workload separation, and cross-data-center replication more efficiently.
Behavior Change
- Use rolling upgrade from 1.2-ITS to 2.0.0, and restart upgrade from preview versions of 2.0 to 2.0.0;
- The new query optimizer (Nereids) is enabled by default:
enable_nereids_planner=true; - All non-vectorized code has been removed from the system, so the
enable_vectorized_engineparameter no long works; - A new parameter
enable_single_replica_compactionhas been added; - datev2, datetimev2, and decimalv3 are the default data types in table creation; datav1, datetimev1, and decimalv2 are not supported in table creation;
- decimalv3 is the default data type for JDBC and Iceberg Catalog;
- A new data type
AGG_STATEhas been added; - The cluster column has been removed from backend tables;
- For better compatibility with BI tools, datev2 and datetimev2 are displayed as date and datetime when
show create table; - max_openfiles and swaps checks are added to the backend startup script so inappropriate system configuration might lead to backend failure;
- Password-free login is not allowed when accessing frontend on localhost;
- If there is a Multi-Catalog in the system, by default, only data of the internal catalog will be displayed when querying information schema;
- A limit has been imposed on the depth of the expression tree. The default value is 200;
- The single quote in the return value of array string has been changed to double quote;
- The Doris processes are renamed to DorisFE and DorisBE.
Embarking on the 2.0.0 Journey
To make Apache Doris 2.0.0 production-ready, we invited hundreds of enterprise users to engage in the testing and optimized it for better performance, stability, and usability. In the next phase, we will continue responding to user needs with agile release planning. We plan to launch 2.0.1 in late August and 2.0.2 in September, as we keep fixing bugs and adding new features. We also plan to release an early version of 2.1 in September to bring a few long-requested capabilities to you. For example, in Doris 2.1, the Variant data type will better serve the schema-free analytic needs of semi-structured data; the multi-table materialized views will be able to simplify the data scheduling and processing link while speeding up queries; more and neater data ingestion methods will be added and nested composite data types will be realized.
If you have any questions or ideas when investigating, testing, and deploying Apache Doris, please find us on Discord. Our developers will be happy to hear them and provide targeted support.