Apache Doris Summit Asia 2023: what can you expect from apache doris as a data warehouse?
When it is cranberry and pumpkin season, we had the unforgettable Apache Doris Summit Asia 2023 with our remarkable committers, users, and community partners, to honor what we have achieved in the past year, and provide a preview of where we are going next.
The past year marks a breakthrough of Apache Doris, an open-source real-time data warehouse that has just undergone an overall upgrade after long consistent incremental optimizations:
More
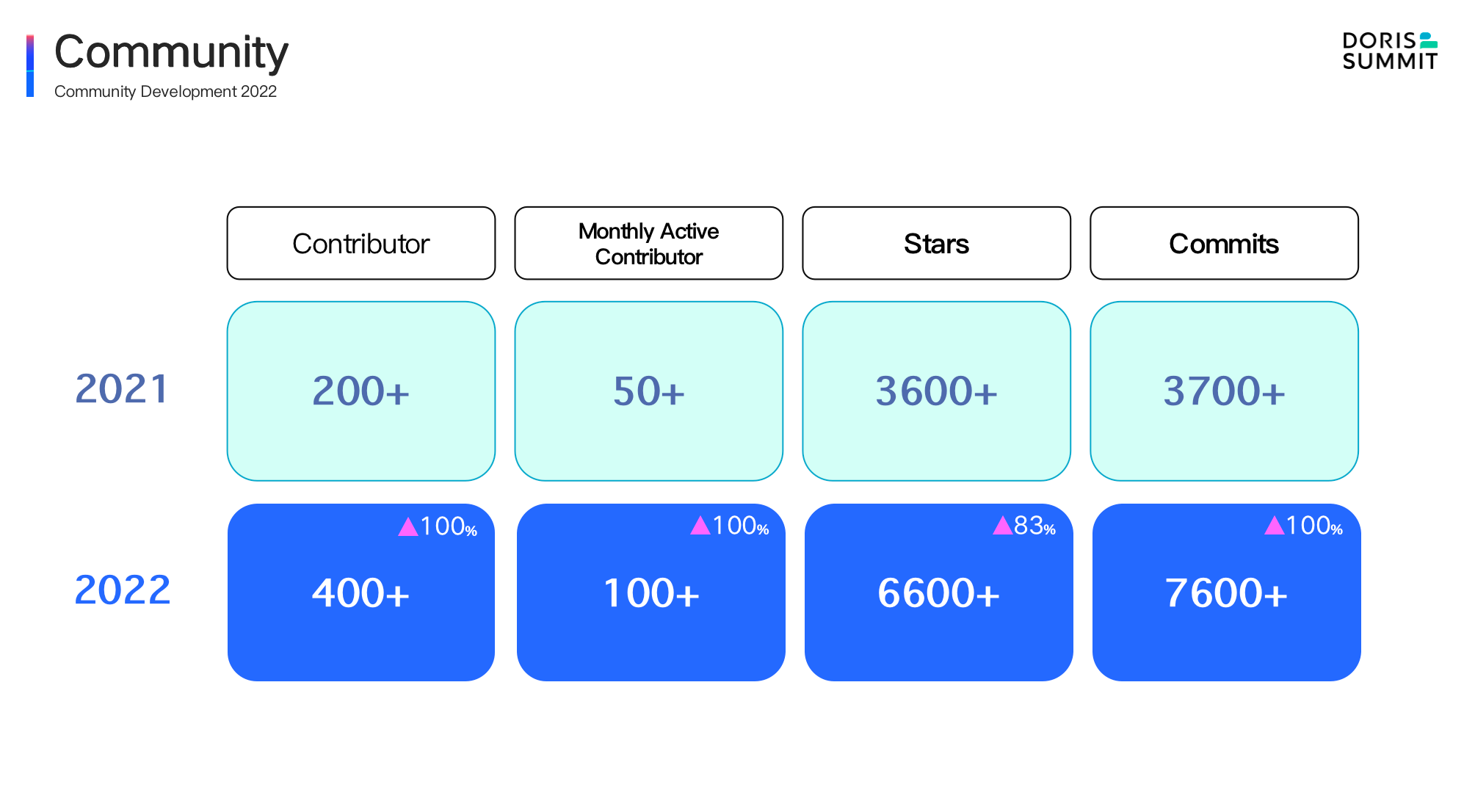
Thanks to the hard work of 275 committers, the Apache Doris 2.0 milestone has merged over 4100 pull requests, representing a 70% increase from version 1.2 last year and a 10-fold increase from 1.1.
Faster
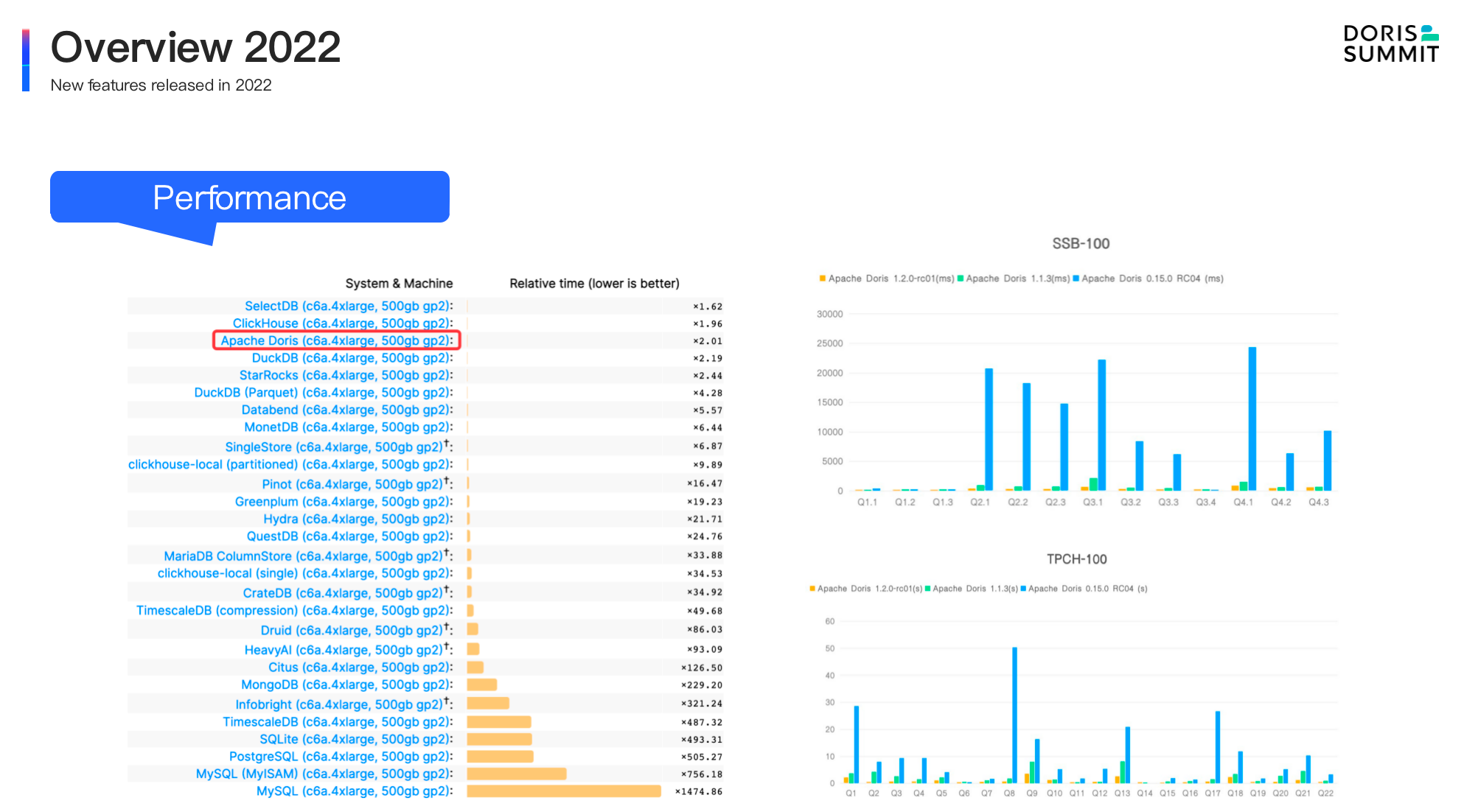
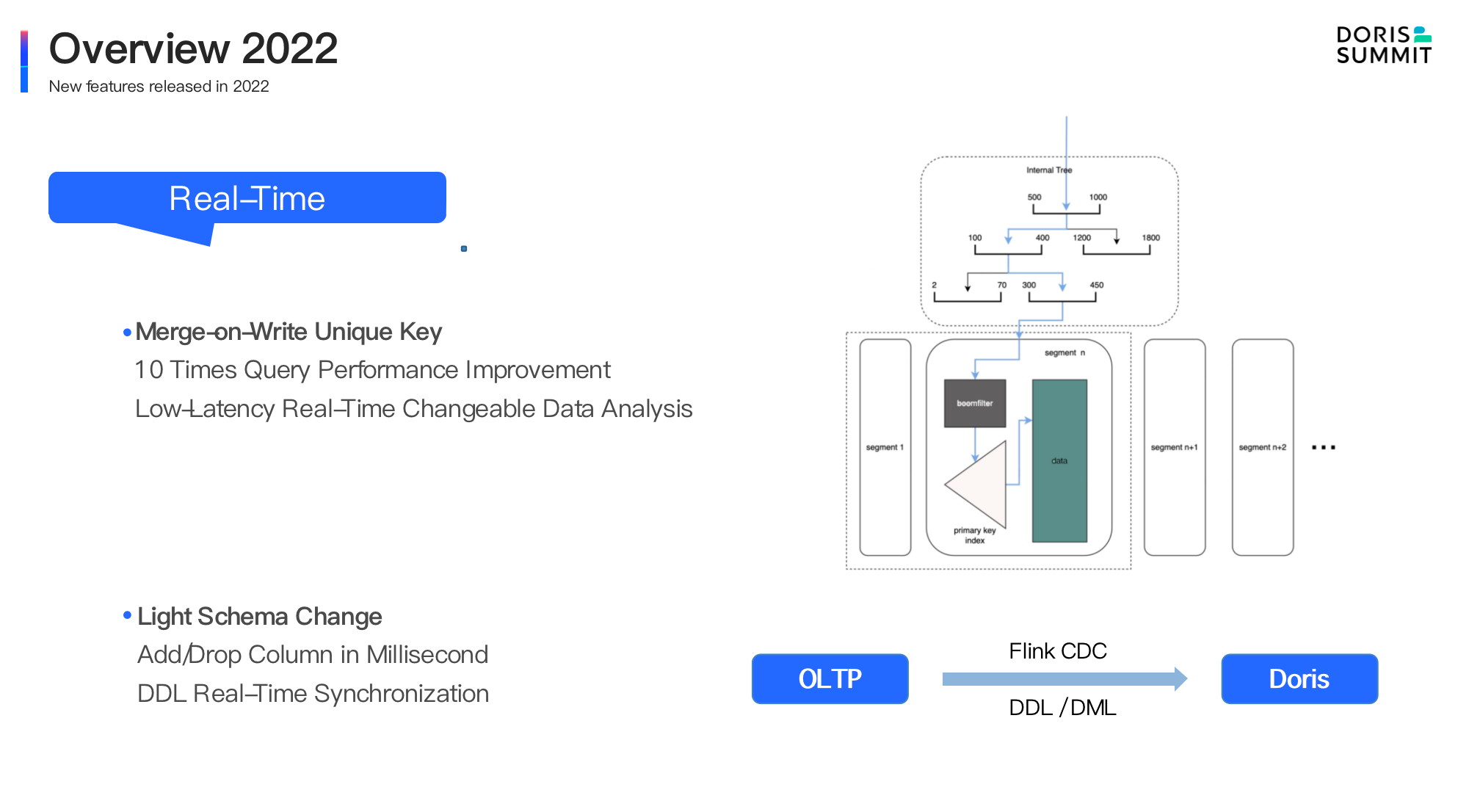
This year, Apache Doris has attained a 10-fold performance increase in blind benchmarking and single-table queries, a 13-fold increase in multi-table joins, and a 20-fold increase in concurrent point queries. The high query performance is supported by the smart design of Apache Doris, including a vectorized execution engine, Merge-on-Write mechanism, the Light Schema Change feature, a self-adaptive parallel execution model, and a new query optimizer.
Wider
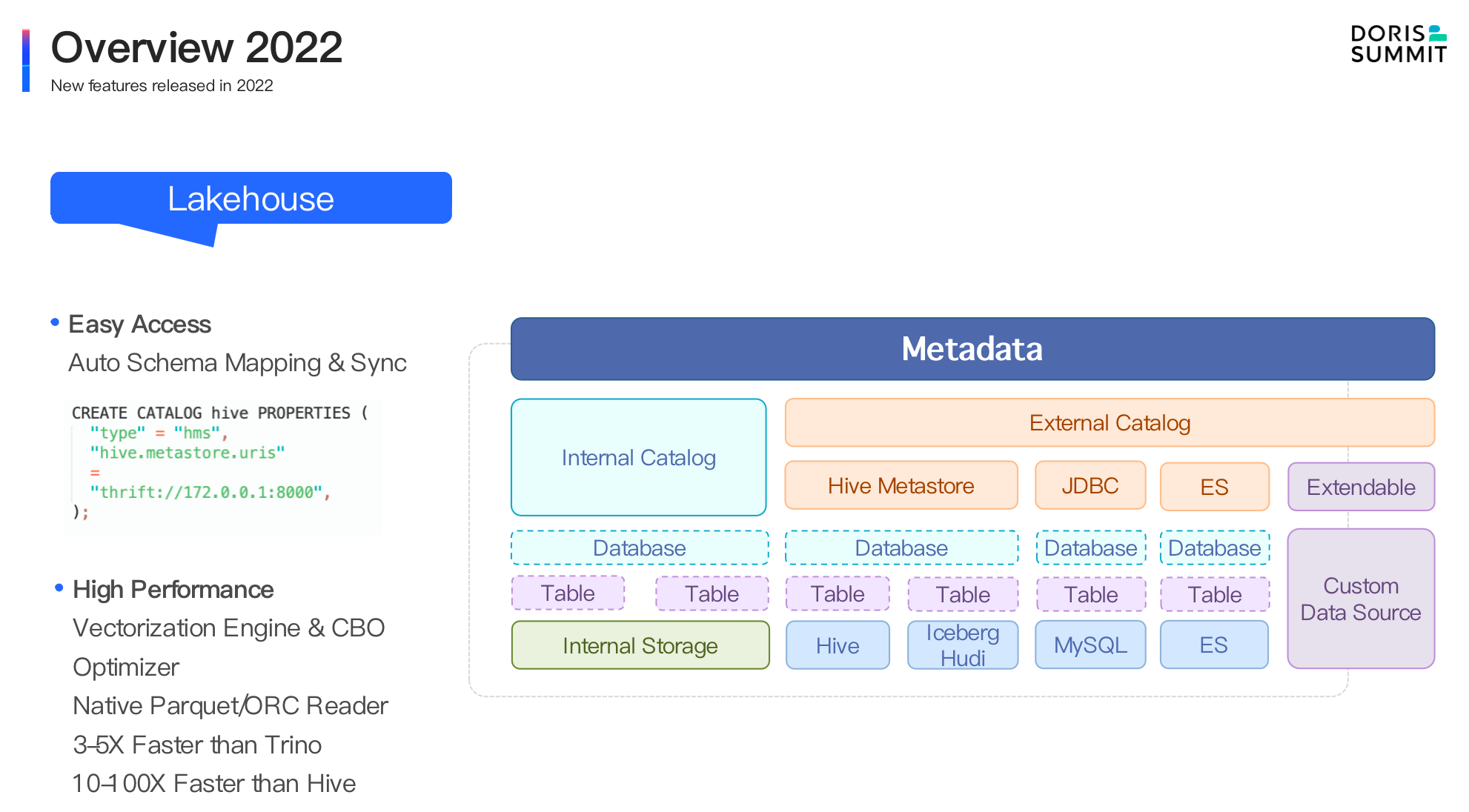
We have built Apache Doris into more than just a powerful OLAP engine but also a data warehouse for a wider range of use cases, including log analysis and high-concurrency data services. To expand the data warehousing capabilities of Apache Doris, we have introduced Multi-Catalog to connect Doris to a wide array of data sources.
One of the most active open source big data projects
Apache Doris has become one of the world's most active open-source big data projects in all aspects:
- It has hit 10K stars on GitHub, a year-on-year growth of 70%, and the momentum keeps going.
- The community has included almost 600 contributors and welcomes new faces every week.
- With 120 monthly active contributors, Apache Doris has become a more active project than Apache Spark, Elasticsearch, Trino, and Apache Druid.
- Over 160 pull requests are created every week. Meanwhile, we have established a mature code review pipeline, making sure that every pull request stands the test of 3000 use cases. This is how we guarantee stability in the midst of agile iteration.
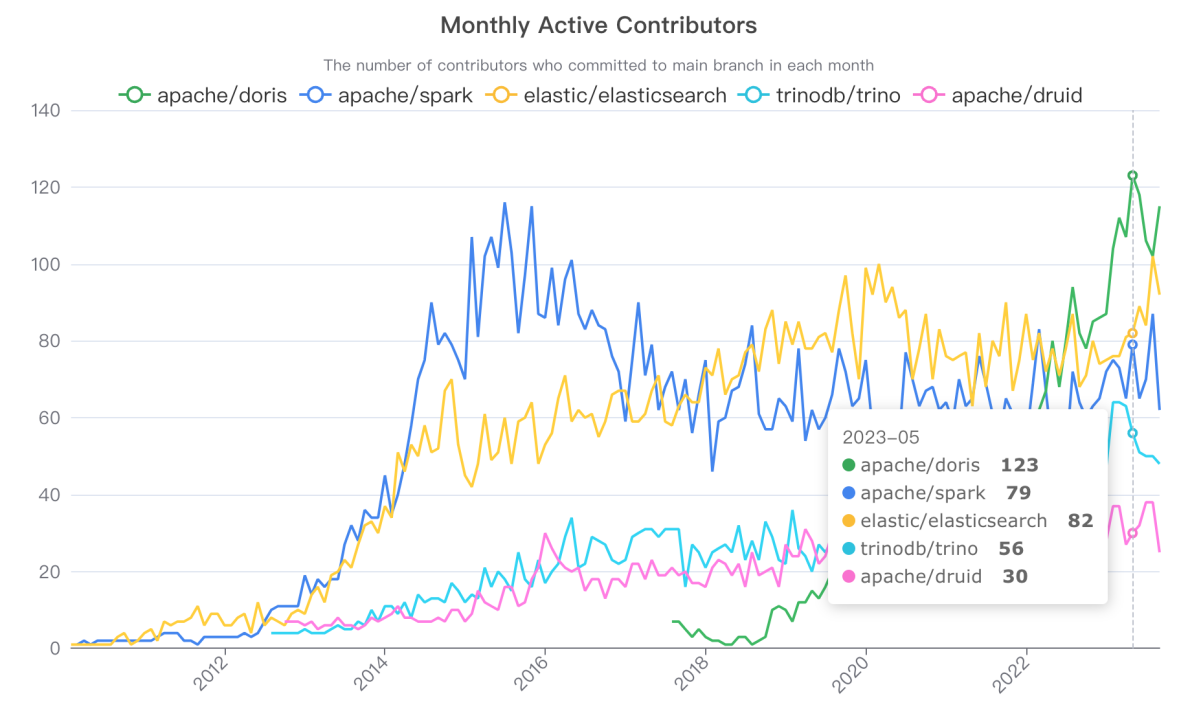
Along with such growth, we've also witnessed higher diversity among contributors. They are engineers from tech giants and database unicorns, like VeloDB, which is a commercial company with products based on Apache Doris. Many cloud service providers, including Alibaba Cloud, Tencent Cloud, Huawei Cloud, AWS and GCP (coming soon), have also jumped on the bandwagon and provided Doris-based data warehouse cloud hosting services.
Fast-expanding user base
Apache Doris now has a user base of over 30,000 data engineers from more than 4000 enterprises, including those from the tech sector, finance, telecom, manufacturing, logistics, and retail. The great majority of them keep in close touch with the Apache Doris developers, committing code, getting involved in tests, and sharing experience and feedback with the community.
Fruit that have been reaped
We aim to make Apache Doris the first choice for people in real-time data analysis. What we have done in the past year can be concluded in three keywords:
- Real-time: We have realized high-throughput real-time data writing and updates, as well as low query latency.
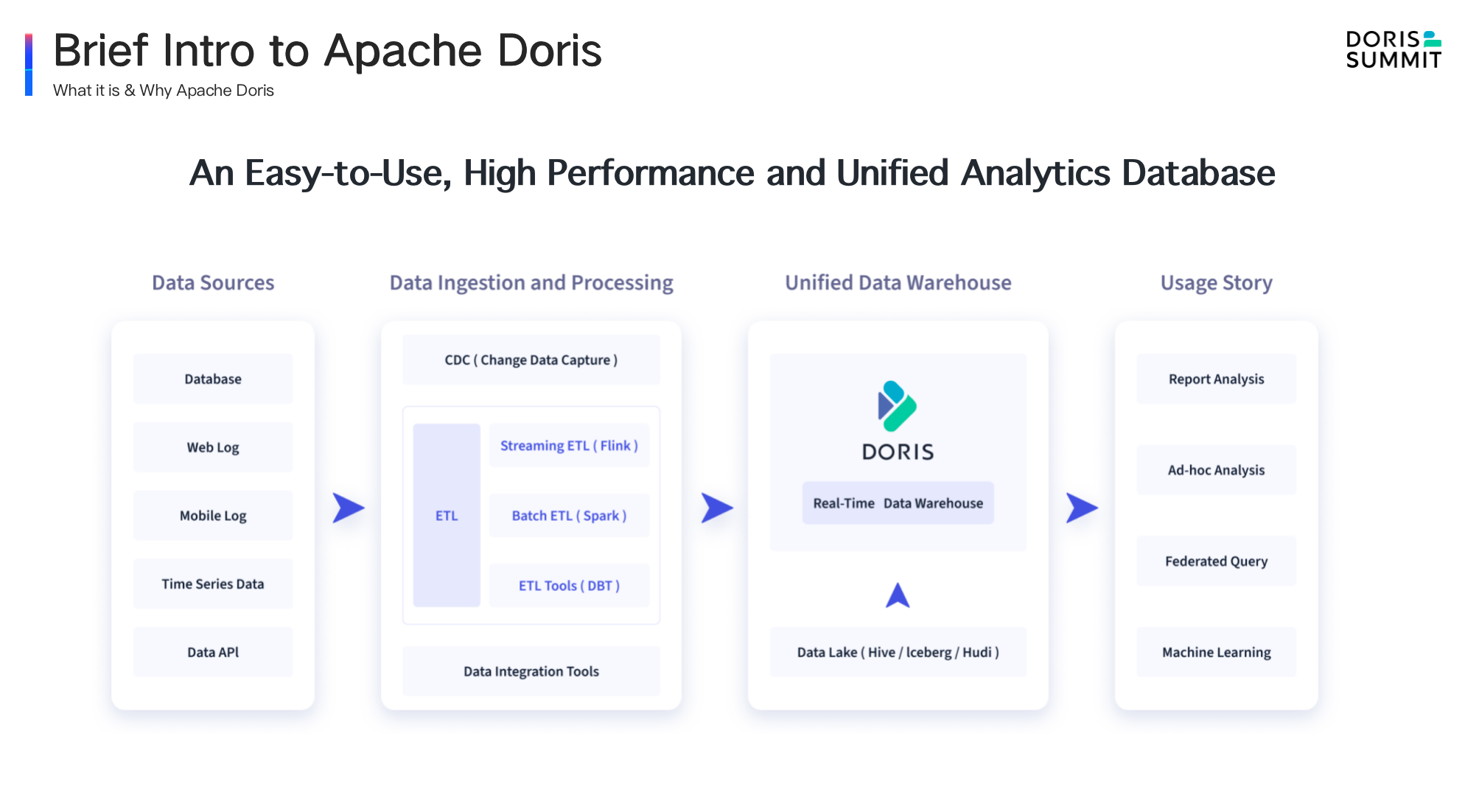
- Unified: As we've been trying to make Doris an all-in-one platform that can undertake most of the analytic workloads for users, we have expanded and enhanced the data lakehousing capabilities of Doris, enabled faster log analysis, faster ELT/ETL, and faster response to point queries.
- Cloud-native: This is a leap towards cloud infrastructure. Apache Doris can now be deployed and run on Kubernetes to reduce storage and computation costs.
Real-time response to queries
As is said, Apache Doris 2.0 delivers 10 times faster query speed than the previous versions, but what is the key accelerator behind such high performance? It is the cost-based query optimizer and the self-adaptive pipeline parallel execution model of Apache Doris.
In traditional data reporting, data is often arranged in flat tables. The idea of flat tables and pre-aggregated tables is to trade storage space for query speed. In these cases, the key to high performance is to accelerate data scanning and aggregation. However, since nowadays data analytic workloads involve more complex computations with more and larger batch processing, data engineers often have to fine-tune the database and rewrite the SQL before they can enjoy satisfactory query speeds. That's why we have refactored the the query optimizer in Apache Doris. The new query optimizer can figure out the most efficient query execution plan for a thousand-line SQL or a join query that relates dozens of tables, saving engineers lots of efforts.
Similarly, the new version of Doris has automated another engineering-intensive process: adjusting the compute instance execution concurrency in the backend. What bothered our users was that when queries of different sizes happened concurrently, these queries tended to fight for resources and thus required human intervention. To solve that, we have introduced a pipeline execution model. It automatically decides the execution concurrency for the current situation to make sure queries of all sizes are executed smoothly. As a result, Doris now has more efficient CPU usage and higher system stability during query execution.
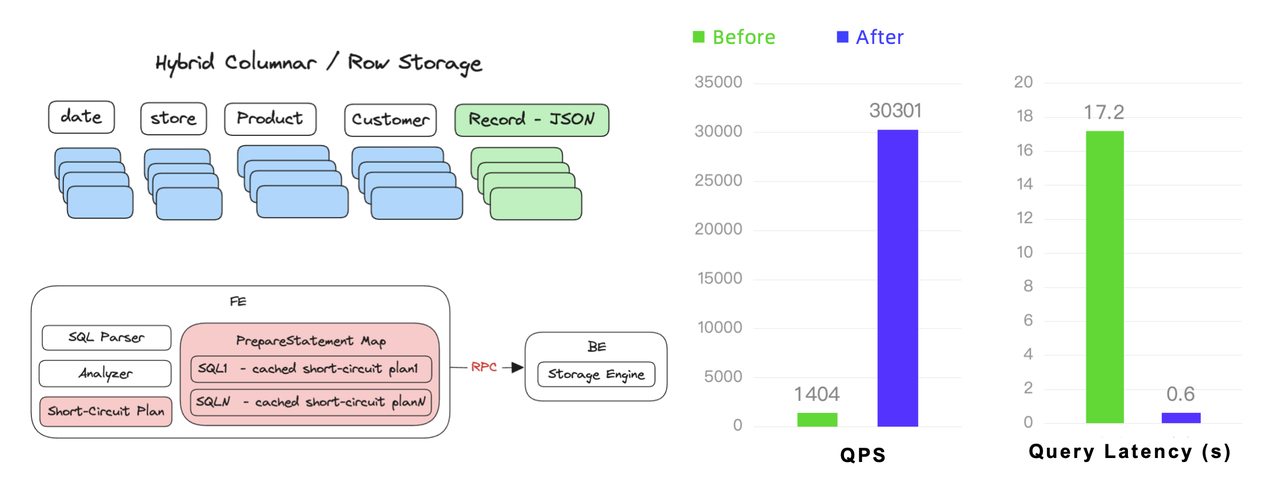
For high concurrency point queries, Apache Doris 2.0 reached a throughput of 30,000 QPS. It is a 20-fold improvement driven by optimizations in data storage, reading, and query execution. As a column-oriented DBMS, Apache Doris has relatively low row reading efficiency, so we have introduced ow/column hybrid storage and row cache to make up for that. We have also enabled the short circuit plan and prepared statements in Apache Doris. The former allows simple queries to skip the query planner for faster execution, and the latter allows users to reuse SQL for similar queries and thus reduce frontend overhead.
For multi-dimensional data analysis, we introduced inverted index to accelerate fuzzy keyword queries, equivalence queries, and range queries.
Real-time data writing and update
Data writing is another side of the real-time story, so we also spent great efforts improving the data ingestion speed of Apache Doris. After optimizations like Memtable parallel flushing and single-copy ingestion, Apache Doris is now 2~8 times faster in data writing.
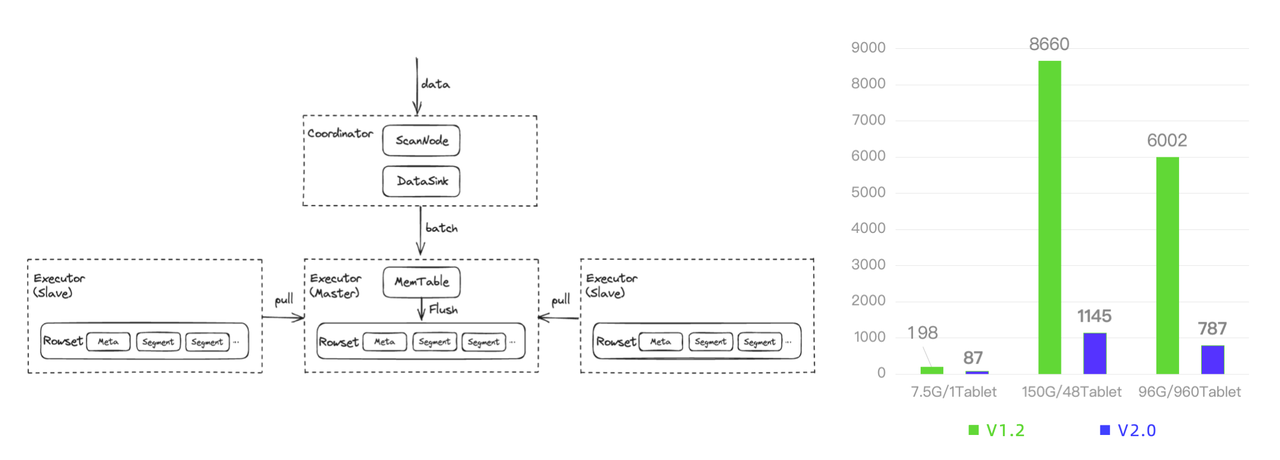
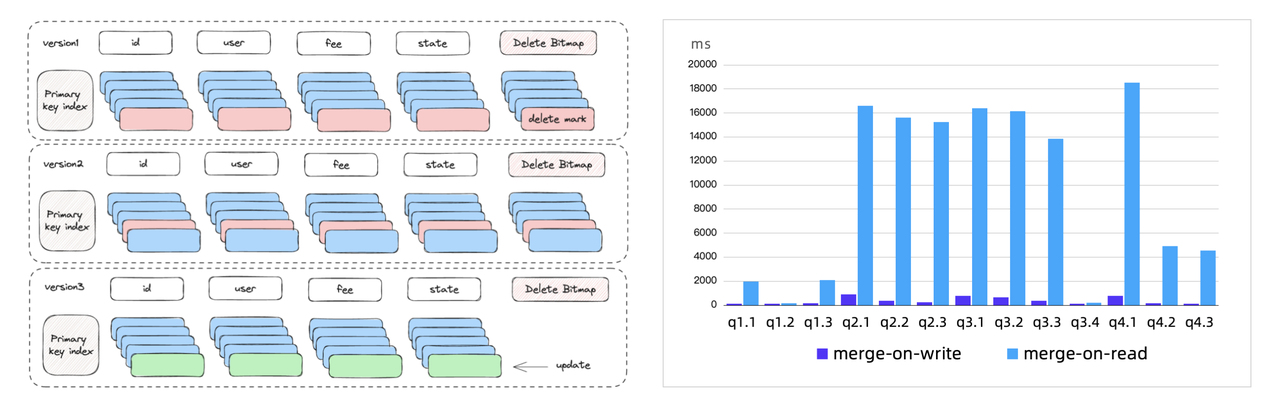
The Merge-on-Write mechanism has been upgraded in version 2.0. It enables an upsert throughput of nearly 1 million rows per second, and it now supports a wider range of updating operations, including partial column updates.
Support for more use cases
For data lakehousing, our last big move was to introduce Multi-Catalog for auto-mapping and auto-synchronization of heterogeneous data sources. In 2.0, we have further enhanced that. It now supports even more data sources, and it is also much faster in various production environments. With multi-catalog, users can ingest their multi-source data into Doris using the simple insert into select operation.
For log analysis, Doris 2.0 provides native support for semi-structured data, which can be arranged in data types like Json, Array, and Map. On the basis of Light Schema Change, it allows Schema Evolution. In addition to the foregoing inverted index, Doris 2.0 comes with a high-performance text analysis algorithm. Built on its large-size data writing and low-cost storage capabilities, Apache Doris is 10 times more cost-effective than the common log analytic solutions on the market.
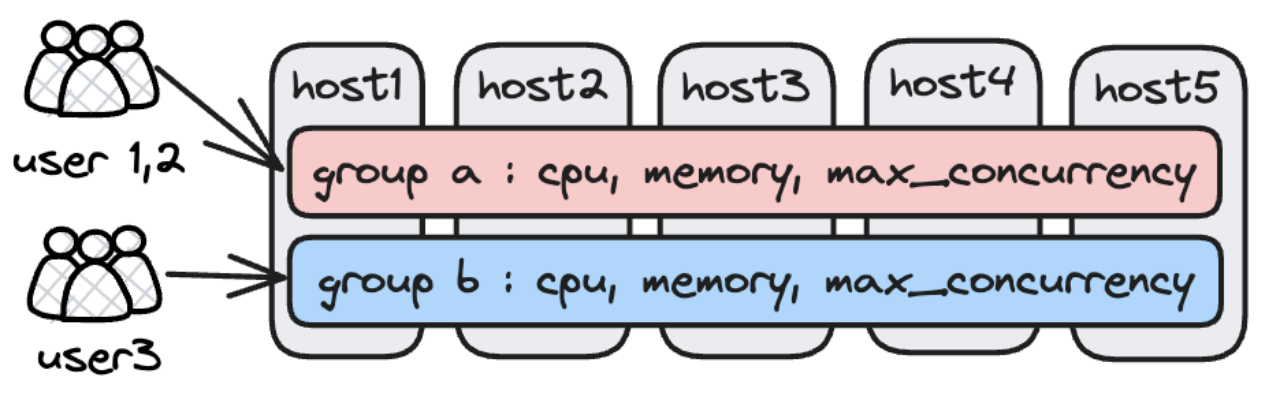
For different analytic workloads in one single cluster, the Doris solution to resource isolation is Workload Group. As the name implies, it is to divide various workloads into groups and thus allow more flexible use of memory and CPU resources. Users can limit the number of queries that a workload group can handle concurrently, so when there are too many query requests, the excessive ones will wait in a queue. This is a way to release system burden.
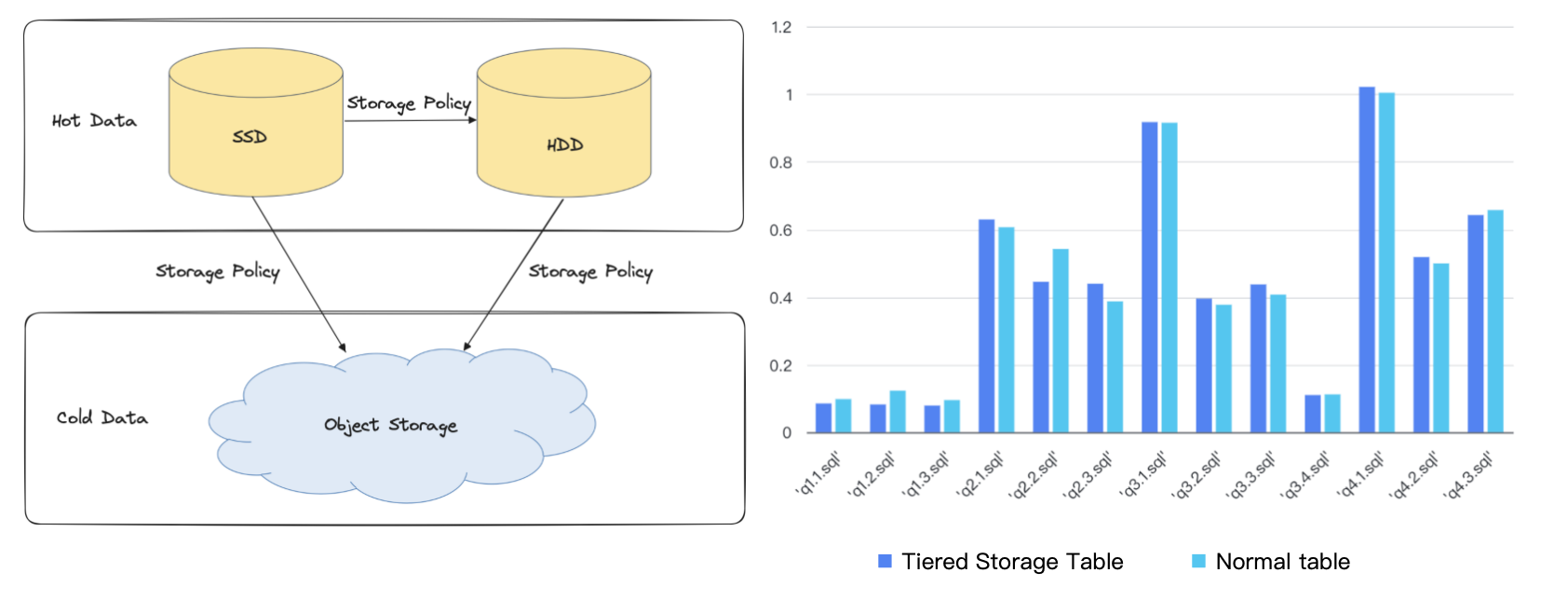
Low cost and high availability
Apache Doris provides tiered storage. The less frequently accessed data, namely, cold data, will be put into object storage to reduce costs. Moreover, since object storage only requires a single copy of data, the storage costs will be further cut by 2/3 compared to 3-replica storage. Calculation based on AWS pricing shows that tiered storage can save you 70% of your cloud disk expenditure.
To facilitate Kubernetes deployment, we have built a Kubernetes Operator. With it, users can easily deploy, scale, inspect, and maintain all Apache Doris nodes (frontends, backends, compute nodes, brokers) on Kubernetes. Compute node is a variant of backend nodes but it does not store any data, which is why it is a good fit for auto-scaling of clusters. During computation peaks, compute nodes can flexibly join the cluster and share the burden. Auto-scaling has been under active testing and will soon be released in upcoming versions of Apache Doris.
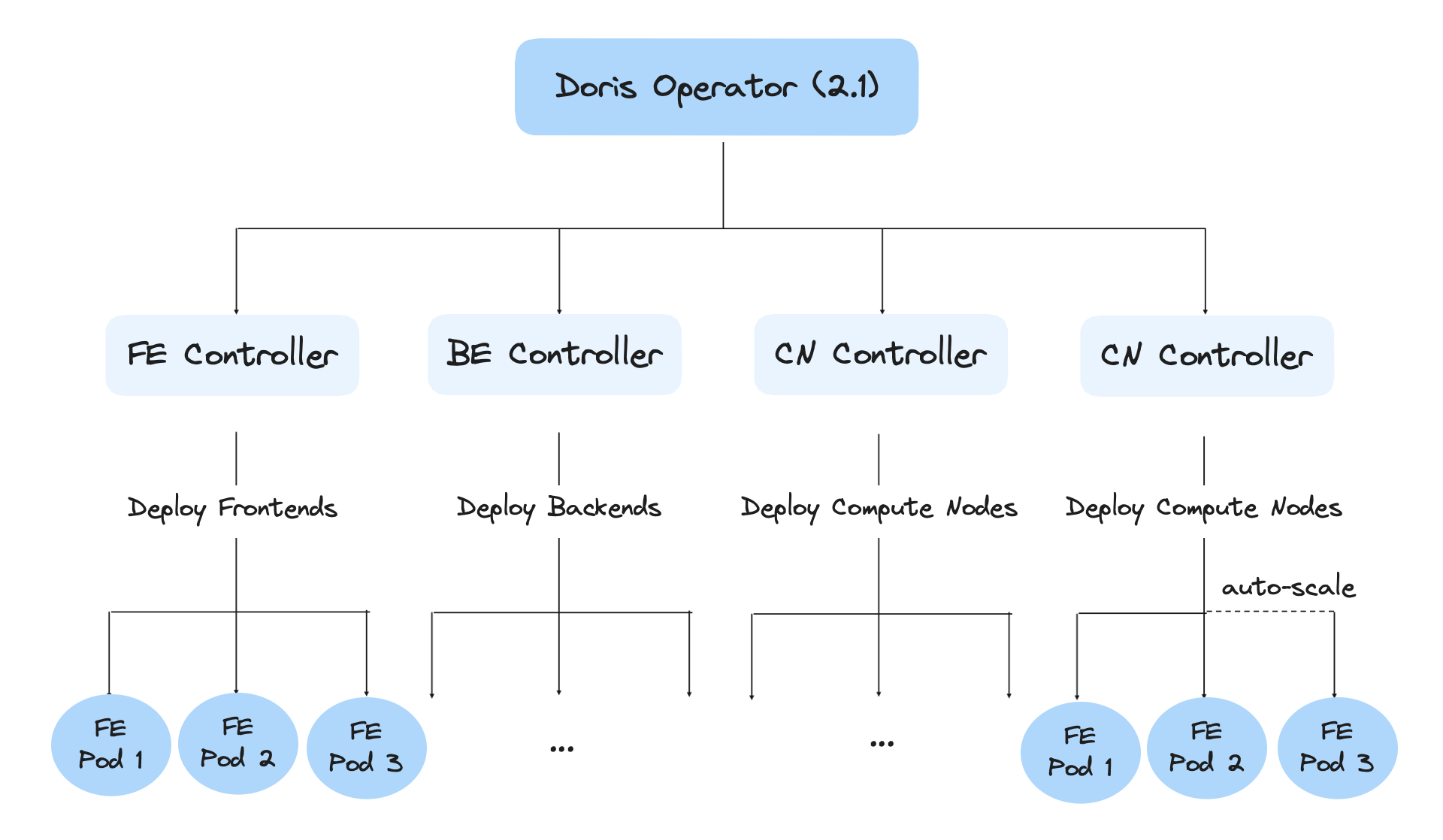
For service availability guarantee, Apache Doris 2.0 supports Cross-Cluster Replication (CCR). As a disaster recovery solution, it supports read-write separation and multi-data center backup.
Reach for the stars
In the foreseeable future, Apache Doris will go further on the aforementioned three directions: real-time, unified, and cloud-native.
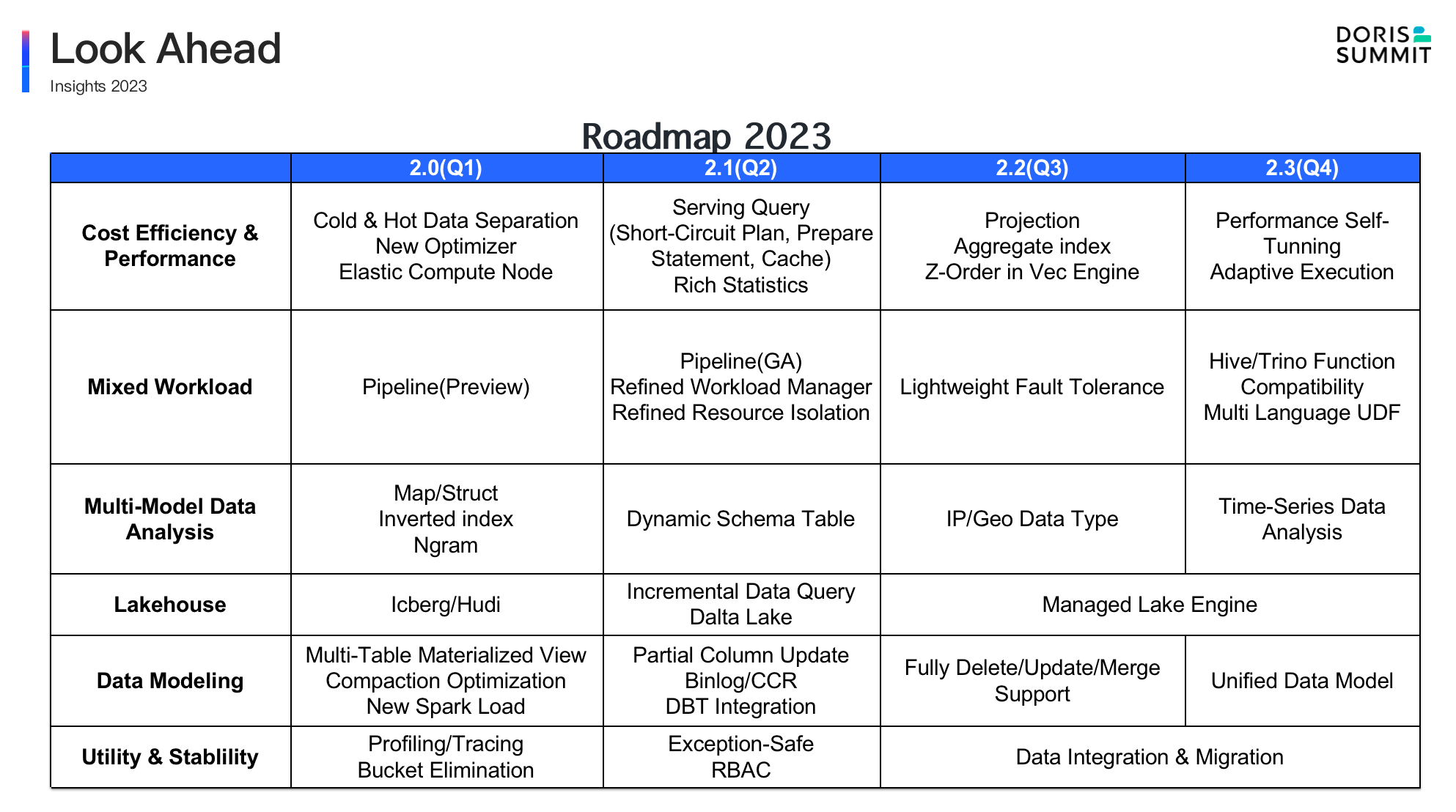
Get even faster
In the upcoming Apache Doris 2.1, the cost-based query optimizer (CBO) will be able to automatically collect execution statistics and provide support for hint syntax. It will also allow users to adjust the optimizing rules. To fully demonstrate the performance of our CBO, we will release a TPC-DS benchmark results.
In addition, Doris 2.1 will support multi-table materialized views and writing intermediate results to disks. Meanwhile, a Union All operator will be added to accelerate the ETL process in Apache Doris. That means users will experience higher performance and stability when processing large batches of data. You can also expect a new Join algorithm that can double the execution speed of multi-table join queries.
In terms of data writing, we try to make it simpler and more intuitive for you, and efforts will be made in three aspects.
- In future versions, data streams, local files, and those from relational databases or data lakes will all be put into relational tables, and they can all be written into Doris using the simple
insert intostatement. - We will simplify the data writing pipeline. Data writing will be implemented by the built-in job scheduling mechanism, so users won't need an extra data synchronization component.
- When there is frequent data writing, Doris will wait until the data accumulates into a sizable batch at the server end, so as to reduce the pressure caused by small file merging.
In terms of data updating, as the Merge-on-Write mechanism advances towards maturity, it will be enabled in Doris by default. Users will be able to flexibly update or modify any columns in tables as they want. Also, based on Merge-on-Write, we will build a one-size-fits-all data model, so users don't have to rack their brains choosing the right data model for various use cases.
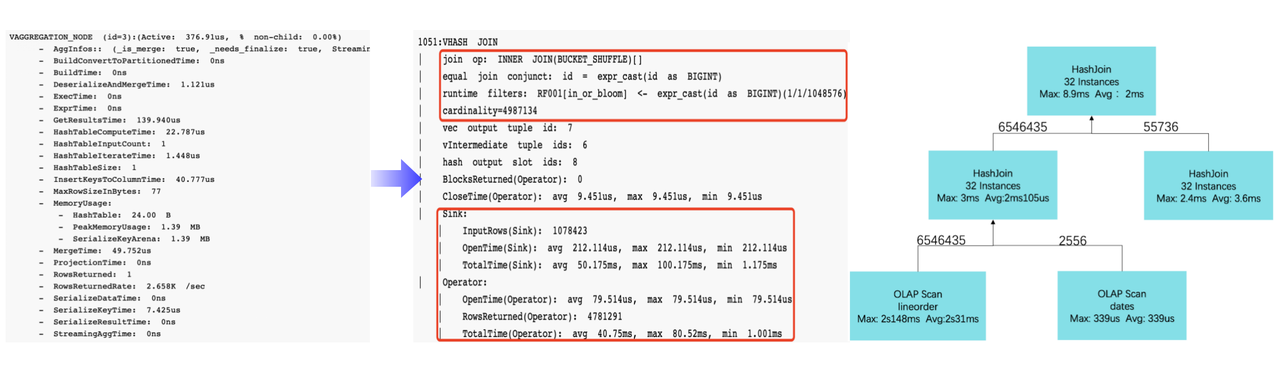
Apache Doris 2.1 will have enhanced observability. It will provide a brand new Profile for users to monitor operator execution, and visualize the query execution status with the aid of Doris Manager.
Support more analytic scenarios
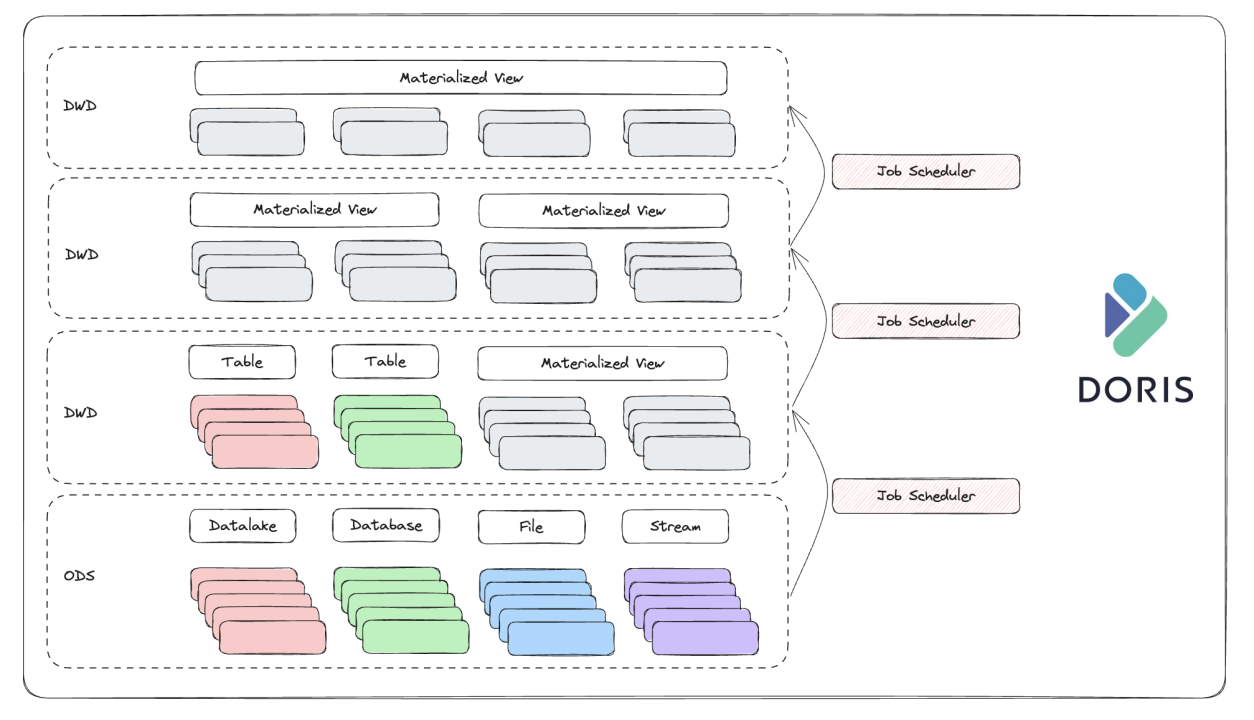
The above-mentioned multi-table materialized view and built-in job scheduling mechanism will also benefit the data lakehousing capability of Doris. From heterogeneous data sources to the data warehouse, users won't need a second component to do ETL and data warehouse layering.
In version 2.0, we support data writeback to JDBC sources, and we are going to expand that functionality to more data sources, including Apache Iceberg, Apache Hudi, Delta Lake and Apache Paimon.
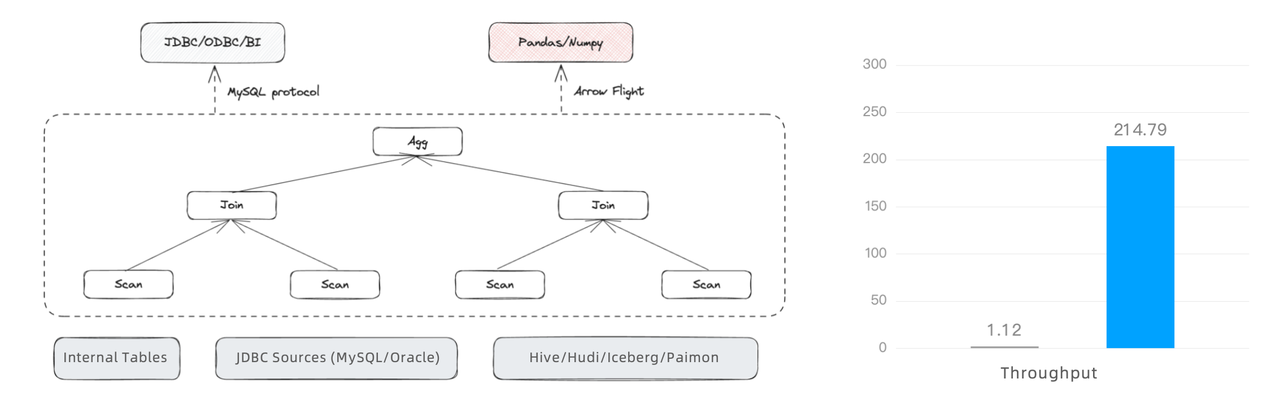
For data ingestion from data lakes, Apache Doris currently adopts the MySQL protocol. In large-scale data reading or data science use cases (like those involving Pandas), this might be a throughput bottleneck. Thus, what we are doing is introducing an Arrow Flight-based high-speed reading interface, which transfers data via the Doris backends directly. In our tests, the new interface delivers a writing throughput that is 100 times higher.
For log analysis, the inverted index will support more complicated data types, such as Array, Map, and GEO. We will also introduce a new data type named Variant to provide schema-free support. This means users can not only put Json data of any shapes and types in the table fields, but also easily handle schema changes without any DDL operations.

For workload management, we will enable higher flexibility. Users will be able to use SQL to create, manage, and allocate resources for their Workload Groups. We will continue to maximize resource utilization while ensuring resource isolation between workload groups.
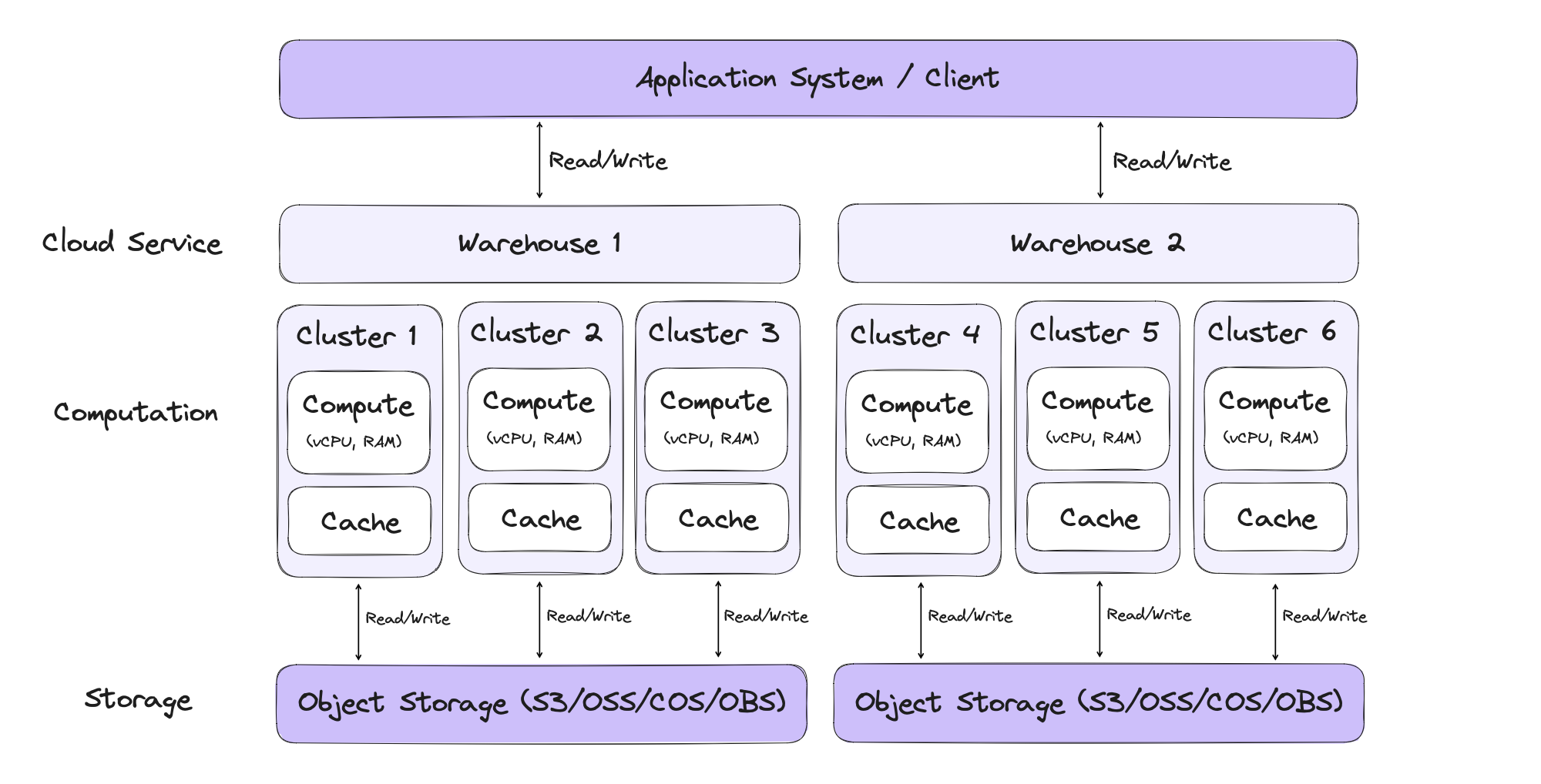
Cloud-nativeness and storage-compute separation
When Apache Doris 2.0 was released, we previewed the merging of the SelectDB Cloud storage-compute separation solution into the Apache Doris project. After some intense code refactoring and compatibility building, this functionality will be good and ready in Apache Doris 2.2, and users will be able to experience the elastic computation capability.
Stick to Innovation
As Apache Doris is on the ramp, we look back on its ten-year development and ask ourselves: what injects vitality to this great project and keep it vibrant for this long? The answer is, we have been working with innovators.
Back in the time when SQL on Hadoop gained currency, Apache Doris chose to stay outside the Hadoop ecosystem. It does not rely on HDFS for data storage, nor Zookeeper for distributed monitoring, but insists on providing high availability by its scalable processes. When the major databases on the market goes by their own syntaxes, Apache Doris adopts stand SQL and the MySQL protocol, in order to lower the threshold for users.
From the self-developed pre-aggregation storage engine, materialized views, and the MPP framework, to inverted index, row/column hybrid storage, Light Schema Change, Merge-on-Write, and the Variant data type, Apache Doris never stops breaking new ground to provide better performance and user experience, which is also what we are going to do next:
- We want to work with more open-source enthusiasts to make a difference to the world.
- We want to keep inspiring the data world by presenting more use cases.
- We want to provide more and better choices for users by collaborating with partners along the data pipeline and cloud service providers.
By choosing Apache Doris, you choose to stay in the heartbeat of innovation. The Apache Doris community awaits newcomers.