性能测试背后的优化
早期版本的 Apache Doris 是一个面向在线数据分析处理的系统,主要处理的场景是报表分析和聚合数据分析,最典型的查询是多表 JOIN 以及 GROUP BY 聚合查询。在 2.X 版本中实现了基于倒排索引的文本检索功能,引入了 Variant 数据类型来高效处理 JSON。在 3.X 版本中引入了存算分离特性使得 Apache Doris 可以利用对象存储极大降低存储成本,而 4.X 版本则是通过引入向量索引使得 Apache Doris 正式迈入 AI 时代,利用向量搜索与文本搜索提供的混合搜索能力,Doris 将会成为企业的 AI 数据分析核心平台。这里我们会介绍 Doris 在 4.X 版本中是如何实现向量索引的,以及为了使其性能追上并达到业界先进水平,Doris 做了哪些工作。
我们把向量索引的实现分为两个大部分,第一个部分是索引阶段,索引阶段需要解决的问题是:1. 数据分片;2. 高效构建高质量索引;3. 索引管理。第二个部分则是查询阶段,查询阶段只有一个核心目标,如何提升查询性能,这其中我们会面临很多问题,比如如何最大程度消除重复计算与多余的磁盘IO,如何优化并发性能等等。
索引阶段
索引阶段的性能和索引的超参数强相关,如果需要一个更高的索引质量,那么势必会导致索引时间变长,得益于 Apache Doris 在数据导入路径上的优化,Doris 可以在保持高质量索引的同时提高导入的性能。
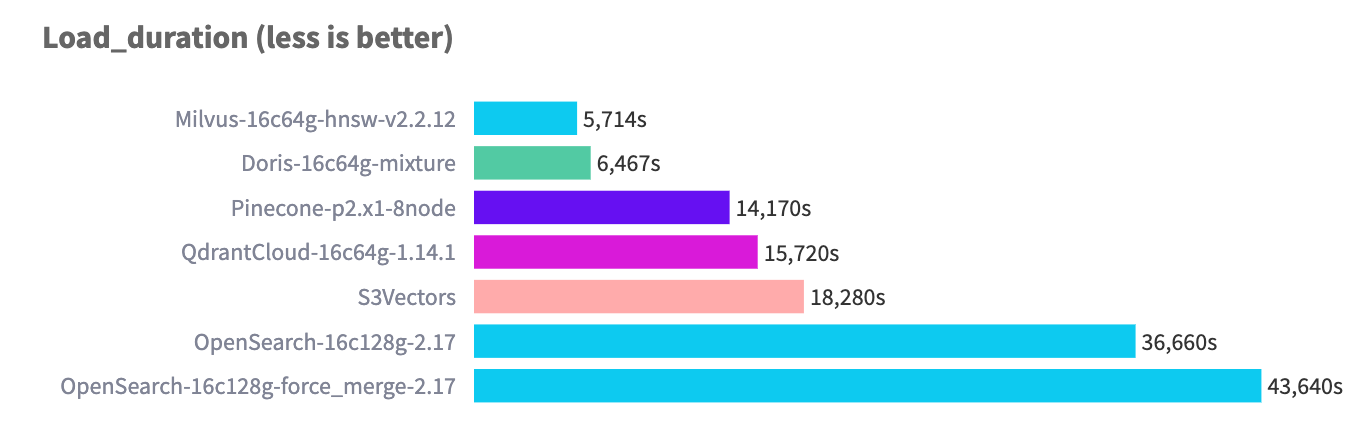
在 768 维 10M 行的数据规模上进行测试,Apache Doris 的导入性能处于业界先进水平
多层级分片
Apache Doris 的内表天然是分布式表。用户在查询或导入时仅感知到一张逻辑表(Table),而 Doris 内核会依据表定义自动创建满足数量要求的物理表(Tablet),并在导入过程中按分区键与分桶键将数据路由到对应 BE 的 tablet。多个 tablet 共同组成用户看到的 table。每次导入都会形成一个导入事务,并在对应的 tablet 上生成一个 rowset(用于版本控制的逻辑单位)。每个 rowset 下包含若干个 segment,真正承载数据的是 segment,ANN 索引也作用于 segment 粒度。
向量索引(如 HNSW)依赖多个关键超参数,这些参数直接决定索引质量与查询性能,并通常在固定数据规模下才能达到理想效果。Apache Doris 的多层级分片将“索引参数”与“整表数据规模”解耦:用户无需因数据总量增长而重建索引,只需关注每批次的导入规模与相应参数设置。 基于我们的测试,HNSW 索引在不同批次规模下的经验参数如下:
| batch_size | max_degree | ef_construction | ef_search | recall@100 |
|---|---|---|---|---|
| 250000 | 100 | 200 | 50 | 89% |
| 250000 | 100 | 200 | 100 | 93% |
| 250000 | 100 | 200 | 150 | 95% |
| 250000 | 100 | 200 | 200 | 98% |
| 500000 | 120 | 240 | 50 | 91% |
| 500000 | 120 | 240 | 100 | 94% |
| 500000 | 120 | 240 | 150 | 96% |
| 500000 | 120 | 240 | 200 | 99% |
| 1000000 | 150 | 300 | 50 | 90% |
| 1000000 | 150 | 300 | 100 | 93% |
| 1000000 | 150 | 300 | 150 | 96% |
| 1000000 | 150 | 300 | 200 | 98% |
换言之,用户只需聚焦“每一批次的导入数据量”,并据此选择合适的索引参数,即可在保证索引质量的同时获得稳定的查询表现。
高性能索引构建
并行高质量索引构建
Apache Doris 采用“双层并行”加速索引构建:一方面通过多台 BE 节点实现集群级并行;另一方面在每台 BE 内,对同一批数据分组进行多线程并行的距离计算,以提升索引数据结构的构建速度。在“快”的同时,Doris 通过内存赞批提升索引质量:当总向量数固定但分批过细、频繁追加索引时,图结构容易稀疏、召回率下降。例如对 768D10M 的向量,分 10 次构建索引可达约 99% 召回,若改为分 100 次则可能降至约 95%。通过内存赞批,在相同超参数下可更好地平衡内存占用与图质量,避免因过度分批导致的质量劣化。
SIMD
ANN 索引构建的核心成本在大规模距离计算,属于典型 CPU 密集型任务。Apache Doris 将这部分计算集中在 BE 节点,相关实现均以 C++ 编写,并充分利用 Faiss 的自动与手动向量化优化。以 L2 距离为例,Faiss 通过编译器辅导宏触发自动向量化,代码示例如下:
FAISS_PRAGMA_IMPRECISE_FUNCTION_BEGIN
float fvec_L2sqr(const float* x, const float* y, size_t d) {
size_t i;
float res = 0;
FAISS_PRAGMA_IMPRECISE_LOOP
for (i = 0; i < d; i++) {
const float tmp = x[i] - y[i];
res += tmp * tmp;
}
return res;
}
FAISS_PRAGMA_IMPRECISE_FUNCTION_END
上述 FAISS_PRAGMA_IMPRECISE_* 宏可引导编译器进行自动向量化:
#define FAISS_PRAGMA_IMPRECISE_LOOP \
_Pragma("clang loop vectorize(enable) interleave(enable)")
同时,Faiss 在 #ifdef SSE3/AVX2/AVX512F 条件编译块中使用 _mm*/_mm256*/_mm512* 指令进行显式向量化;结合模板 ElementOpL2/ElementOpIP 与维度特化 fvec_op_ny_D{1,2,4,8,12},实现:
- 批量处理多条样本(如 8/16),并通过寄存器内矩阵转置提升访问连续性;
- 使用 FMA 指令(如
_mm512_fmadd_ps)合并乘加以减少指令数; - 通过水平求和(horizontal sum)快速得到标量结果;
- 以 masked 分支处理非 4/8/16 对齐的尾元素。 这些优化有效压缩距离计算的指令与访存开销,显著提升索引构建吞吐。
查询阶段
搜索场景对延迟极为敏感。在千万级数据量与高并发查询的场景下,通常需要将 P99 延迟控制在 500 ms 以内。这对 Doris 的优化器、执行引擎以及索引实现都提出了更高要求。开箱即用的测试表明,Apache Doris 的查询性能已达到业界主流专用向量数据库的水平。下图展示了 Apache Doris 与其他具备向量搜索能力的数据库在 Performance768D10M 数据集上的对比;其他数据库数据来自 Zilliz 开源的 VectorDBBench 框架。
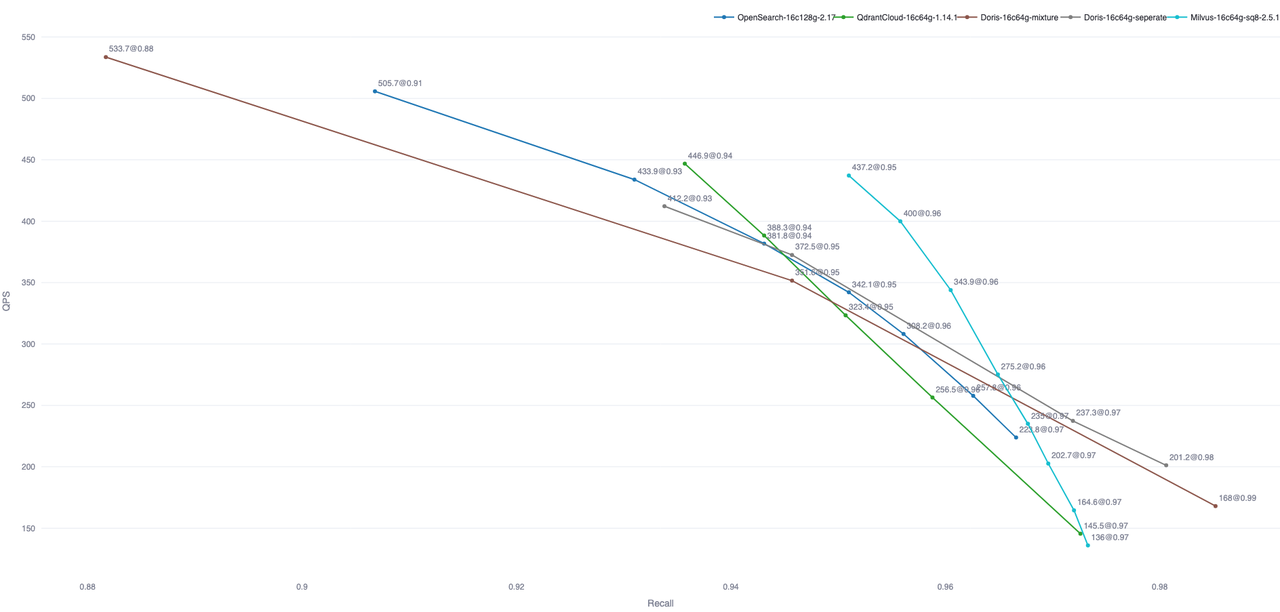
注:图中仅包含部分数据库的开箱测试结果。OpenSearch 与 Elastic Cloud 可通过优化索引文件数量进一步提升查询性能。
Prepare Statement
在传统执行路径中,Doris 会对每条 SQL 执行完整优化流程(语法解析、语义分析、RBO、CBO)。这在通用 OLAP 场景必不可少,但在搜索等简单且高度重复的查询模式中会产生明显的额外开销。为此,Doris 4.0 扩展了 Prepare Statement,使其不仅支持点查,也适用于包含向量检索在内的所有 SQL 类型。核心思路如下:
- 分离编译与执行
- Prepare 阶段一次性完成解析、语义与优化,生成可复用的逻辑计划(Logical Plan)。
- Execute 阶段仅绑定实参并直接执行已生成的计划,完全跳过优化器。
- 计划缓存(Plan Cache)
- 按 SQL 指纹(normalized SQL + schema version)判断计划是否可复用。
- 参数值不同但结构一致时仍可直接复用,避免重复优化。
- Schema Version 校验
- 执行时校验表结构版本,确保计划正确性。
- schema 未变化 → 直接复用;已变化 → 自动失效并重新 Prepare。
- 跳过优化器带来显著加速
- Execute 不再运行 RBO/CBO,优化器耗时几乎被完全消除。
- 在向量检索这类模板化查询中,Prepare 可显著降低端到端延迟。
Index Only Scan
Apache Doris 的向量索引采用外挂方式。外挂索引便于管理与异步构建,但也带来性能挑战:如何避免重复计算与多余 IO。ANN 索引除返回命中行号外,还可返回向量间距离。为高效利用这些额外信息,执行引擎在 Scan 算子阶段对距离相关表达式进行“提前短路”。Doris 通过“虚拟列”机制自动完成该短路,并以 Ann Index Only Scan 完全消除与距离计算相关的读 IO。 在朴素流程中,Scan 将谓词下推至索引,索引返回行号;随后 Scan 按行号读取数据页(Data Page),再计算表达式并向上返回 N 行结果。
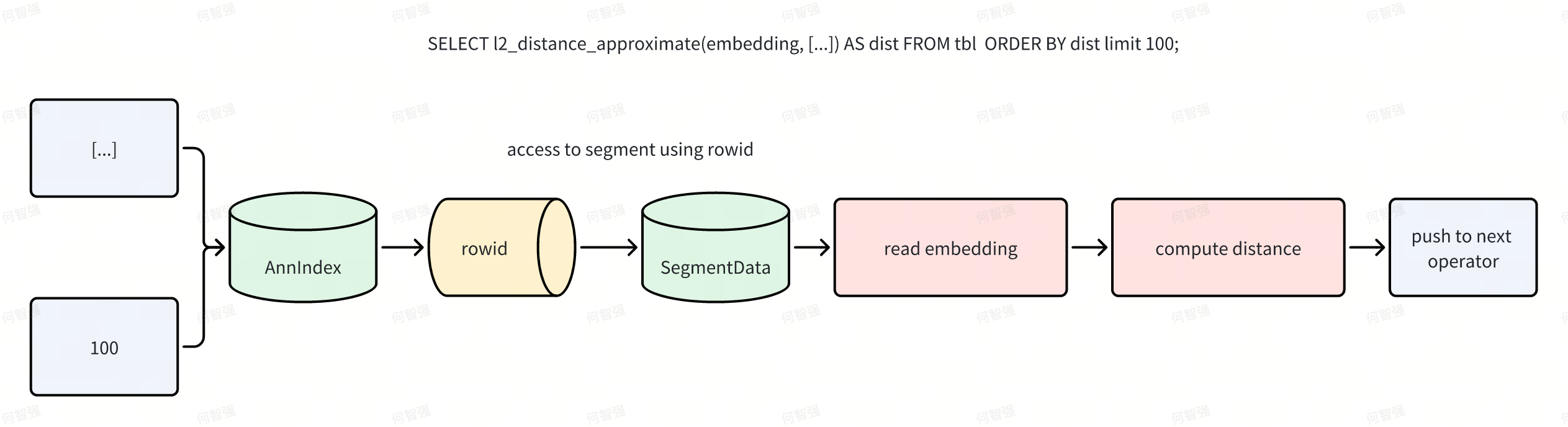
应用 Index Only Scan 后,流程变为:
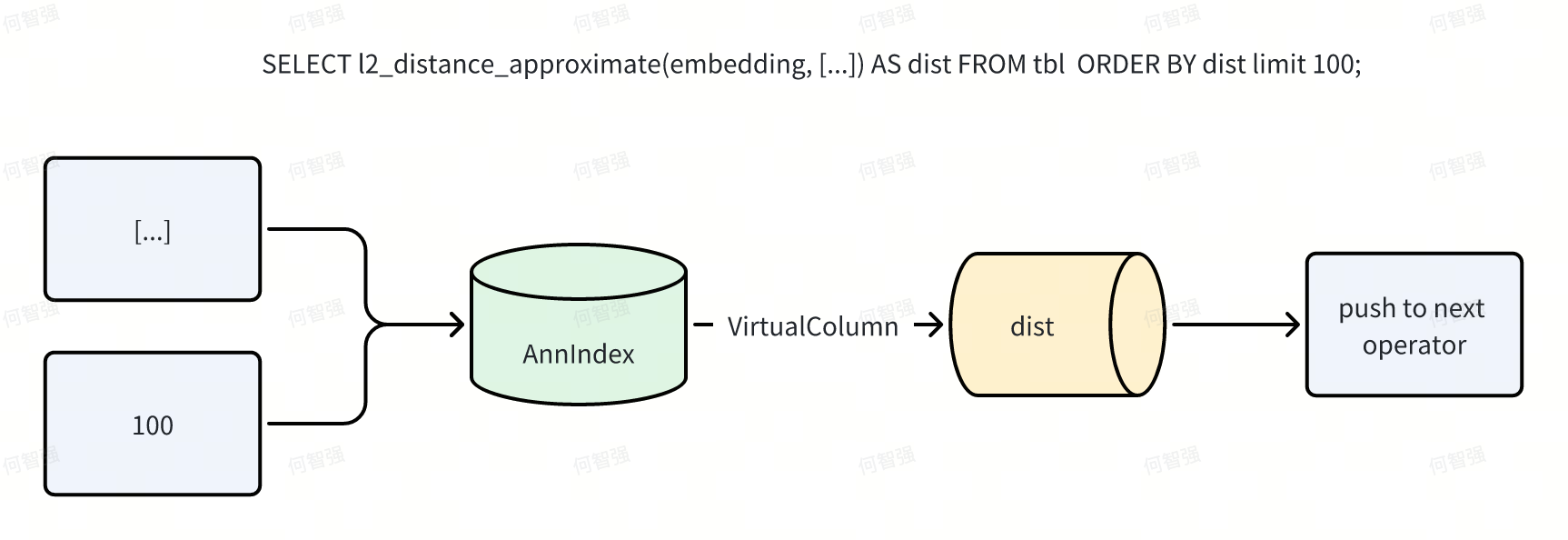
例如 SELECT l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100;,执行过程将不再触发数据文件 IO。
除 Ann TopN Search 外,支持索引加速的 Range Search 与复合检索(Compound Search)也采用类似优化。Range Search 较 TopN 更复杂:不同比较方式决定索引是否能返回 dist。以下梳理与 Ann Index Only Scan 相关的查询类型及其是否可被 Index Scan 优化:
-- Sql1
-- Range + proj
-- Ann 索引可以返回 dist,所以 dist 不需要再次计算
-- 同时 virtual column for cse 的优化避免了 proj 里面的 dist 计算
-- IndexScan: True
select id, dist(embedding, [...]) from tbl where dist <= 10;
-- Sql2
-- Range + no-proj
-- Ann 索引可以返回 dist,所以 dist 不需要再次计算
-- IndexScan: True
select id from tbl where dist <= 10 order by id limit N;
-- Sql3
-- Range + proj + no-dist-from index
-- Ann 索引无法返回 dist(索引只能更新 rowid map)
-- 由于 proj 里面要求返回 dist 因此 embedding 需要重读
-- IndexScan: False
select id, dist(embedding, [...]) from tbl where dist > 10;
-- Sql4
-- Range + proj + no-dist-from index
-- Ann 索引无法返回 dist(索引只能更新 rowid map)
-- 但是 proj 里面不需要 dist,因此 embedding 不需要重新读
-- IndexScan: True
select id from tbl where dist > 10;
-- Sql5
-- TopN
-- AnnIndex 返回 dist,virtual slot for cse 确保了索引的 dist 被上传到 proj
-- 因此不需要读 embedding 列
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl order by dist(embedding, [...]) asc limit N;
-- Sql6
-- TopN + IndexFilter
-- 1. comment 列不需要读,inverted index scan 已经做了这个优化
-- 2. embedding 列不需要读,原因与 sql5 一样
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql7
-- TopN + Range
-- IndexScan:True,原因是 Sql1 与 Sql5 组合
select id[, dist(embedding, [...])] from tbl where dist(embedding, [...]) > 10 order by dist(embedding, [...]) limit N;
-- Sql8
-- TopN + Range + IndexFilter
-- INdexScan:True,原因是 Sql7 与 Sql6 组合
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql9
-- TopN + Range + CommonFilter
-- 这里重点: 1. dist < 10 而不是 dist > 10; 2. common filter 没有直接读 embedding,而是读的 dist
-- Ann index 可以返回 dist,virtual slot ref for cse 确保了所有对 dist 的读都是同一个列
-- 此时虽然 ann topn 无法 apply,理论上 embedding 列依然全程不需要物化
-- 但是实际中,依然还是会物化 embedding,因为目前判断某个列是否可以 skip reading,是靠判断这个列上的谓词是否还有残留,common filter 本身无法被消除,所以现在代码上是会判断需要物化的。
-- 这个优化点ROI不高,因此不做了
-- IndexScan: False
select id[,dist(embedding, [...])] from tbl where where comment match_any 'olap' and dist(embedding, [...]) < 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql10
-- Sql9 的变种,dist < 10 变成了 dist > 10,此时 index 无法返回 embedding
-- 因此为了计算 abs(dist(embedding, [...]) 需要物化 embedding
-- IndexScan: False
select id[,dist(embedding, [...])] from tbl where where comment match_any 'olap' and dist(embedding, [...]) > 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql11
-- Sql9 的变种,abs(dist(embedding) + 10) > 10 变成了 array_size(embedding) > 10,区别在于 array_size 强制要求 embedding 的物化
-- 为了计算 array_size(embedding, [...]) 需要物化 embedding
-- IndexScan: False
select id[,dist(embedding, [...])] from tbl where where comment match_any 'olap' and dist(embedding, [...]) < 10 AND array_size(embedding) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
虚拟列优化公共子表达式
Index Only Scan 主要解决 IO 问题,避免了对 embedding 的大量随机读。为进一步消除重复计算,Doris 在计算层引入“虚拟列”机制,将索引返回的 dist 以列形式传递给表达式执行器。 虚拟列的设计要点:
- 引入表达式节点
VirtualSlotRef; - 引入列迭代器
VirtualColumnIterator。
VirtualSlotRef 表示“计算时生成”的特殊列,由某个表达式物化且可被多个表达式共享,仅首次使用时计算一次,从而消除 Projection 与谓词中的公共子表达式(CSE)重复计算。VirtualColumnIterator 用于将索引返回的距离物化到表达式,避免重复的距离函数计算。该机制最初用于 ANN 相关查询的 CSE 消除,随后扩展至通用的 Projection + Scan + Filter 组合。基于 ClickBench 数据集,以下查询统计从 Google 获得最多点击的 20 个网站:
set experimental_enable_virtual_slot_for_cse=true;
SELECT counterid,
COUNT(*) AS hit_count,
COUNT(DISTINCT userid) AS unique_users
FROM hits
WHERE ( UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.COM'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.RU'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) LIKE '%GOOGLE%' )
AND ( LENGTH(regexp_extract(referer, '^https?://([^/]+)', 1)) > 3
OR regexp_extract(referer, '^https?://([^/]+)', 1) != ''
OR regexp_extract(referer, '^https?://([^/]+)', 1) IS NOT NULL )
AND eventdate = '2013-07-15'
GROUP BY counterid
HAVING hit_count > 100
ORDER BY hit_count DESC
LIMIT 20;
核心表达式 regexp_extract(referer, '^https?://([^/]+)', 1) 为 CPU 密集型且被多处复用。启用虚拟列优化(set experimental_enable_virtual_slot_for_cse=true;)后:
- 开启优化:0.57 s
- 关闭优化:1.50 s
端到端性能提升约 3 倍。
Scan 并行度优化
Doris 针对 Ann TopN Search 重构了 Scan 并行策略。原策略按“行数”决定并行度(默认 2,097,152 行对应 1 个 Scan Task)。由于 segment 基于 size 创建,高维向量列会使单 segment 行数远低于该阈值,导致一个 Scan Task 内出现多个 segment 串行扫描、进而影响性能。Doris 改为“严格按 segment 创建 Scan Task”,提升索引分析阶段的并行度;由于 Ann TopN Search 的过滤率极高(只返回 N 行),回表阶段即便串行也不影响整体性能。以 SIFT 1M 为例:set optimize_index_scan_parallelism=true;开启后 TopN 串行查询耗时由 230 ms 降至 50 ms。
此外,4.0 引入“动态并行度调整”:每轮调度前根据 Scan 线程池压力动态决定可提交的任务数;压力大则减并行、资源空闲则增并行,以在串行与高并发场景间兼顾资源利用率与调度开销。
全局 TopN 延迟物化
典型的 Ann TopN 查询包含两阶段:
- Scan 算子通过索引获取各 segment 的 TopN 距离;
- 全局排序节点对各 segment 的 TopN 进行合并排序,得到最终 TopN。
若 projection 返回多列或包含大列(如 String),阶段一从每个 segment 读取的 N 行可能造成大量磁盘 IO,且在阶段二的全局排序中被丢弃(非最终 TopN)。Doris 通过“全局 TopN 延迟物化”最大限度减少阶段一读取量。
以 SELECT id, l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100; 为例:阶段一每个 segment 通过 Ann Index Only Scan + 虚拟列仅输出 100 个 dist 及其 rowid;若共有 M 个 segment,阶段二对 100 * M 个 dist 做全局排序得到最终 TopN 及其 rowid,最后 Materialize 算子依据这些 rowid 在对应 tablet/rowset/segment 上物化所需列。