部署 Prometheus 和 Grafana
本文介绍如何在 Kubernetes 上使用 Helm 部署 Prometheus 和 Grafana,并将其接入 Apache Doris 存算分离集群,实现指标采集、可视化与告警。Prometheus 负责拉取 FE/BE/Meta Service 暴露的 HTTP 与 bRPC 指标,Grafana 负责通过 Dashboard 呈现集群状态。
注:本文聚焦 Kubernetes 上 Helm + ServiceMonitor 的部署步骤;文中下载的 cloud 版 Dashboard 模板同样适用于非 Kubernetes 方式部署的存算分离集群。关于 Doris 监控架构、指标(metrics)格式、Dashboard 面板说明以及完整的模板下载入口,请参见 监控和报警。
适用场景
| 场景 | 说明 |
|---|---|
| 新集群上线 | 在 Doris 存算分离集群投入使用前完成监控接入,确保异常可被及时发现 |
| 日常运维 | 持续观察 FE/BE/Meta Service 的关键指标与节点资源使用情况 |
| 故障排查 | 通过历史指标、Dashboard 视图与告警快速定位性能或可用性问题 |
| 容量规划 | 基于节点与组件指标趋势评估扩容时机 |
前置条件
- 已具备一个可用的 Kubernetes 集群,并已配置好
kubectl。 - 已经使用 Doris Operator 在
default命名空间部署了一个存算分离集群(FE、BE/Compute Group、Meta Service 三类组件已就绪)。 - 节点能够访问公网,可下载 Helm 安装脚本、Prometheus Community Charts 与 Grafana Dashboard JSON 文件。
- 具备在 Kubernetes 中创建命名空间、Helm Release、ServiceMonitor 等资源的权限。
部署流程总览
- 安装 Helm,并通过
kube-prometheus-stack一键部署 Prometheus、Grafana、Alertmanager。 - 配置 Prometheus
ServiceMonitor,让其能自动发现并采集 Doris 集群的 HTTP 与 bRPC 指标。 - 登录 Grafana,导入 Doris 官方 Dashboard,并按需补充节点监控面板。
第 1 步:部署 Helm、Prometheus 与 Grafana
1.1 安装 Helm
目的:在本地或运维节点安装 Helm 3,用于安装与管理 Kubernetes 上的监控组件。
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
1.2 添加 Prometheus Community Helm 仓库
目的:注册 kube-prometheus-stack Chart 所在的仓库,并刷新本地缓存。
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
1.3 部署 kube-prometheus-stack
目的:在独立的 monitoring 命名空间中部署 Prometheus、Grafana、Alertmanager 及相关 Operator。
# 创建命名空间
kubectl create namespace monitoring
# 部署 kube-prometheus-stack
helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring
1.4 检查 Pod 状态
目的:确认监控栈中的全部 Pod 处于 Running 状态后再进入下一步。
kubectl get pods -n monitoring
正常输出示例如下:
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 8 (5h28m ago) 4d23h
prometheus-grafana-7994c77c7-8nk7j 3/3 Running 12 (5h28m ago) 5d
prometheus-kube-prometheus-operator-5576477887-dgp8h 1/1 Running 4 (5h28m ago) 5d
prometheus-kube-state-metrics-77885ddddc-hldlw 1/1 Running 4 (5h28m ago) 4d23h
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 4h11m
prometheus-prometheus-node-exporter-2tl9s 1/1 Running 4 (5h28m ago) 4d23h
prometheus-prometheus-node-exporter-b58rd 1/1 Running 4 (5h28m ago) 4d23h
prometheus-prometheus-node-exporter-fqp6v 1/1 Running 4 (5h28m ago) 4d23h
第 2 步:配置 Prometheus 采集 Doris 指标
通过创建 ServiceMonitor,让 Prometheus Operator 自动发现位于 default 命名空间下、带有 app.doris.disaggregated.cluster=test-disaggregated-cluster 标签的 Doris Service,并按 FE、BE、Meta Service 三类分组采集指标。
2.1 准备 ServiceMonitor YAML
目的:声明采集目标、端点路径、采集周期,并通过 relabelings 将服务按角色打上统一的 group 标签,便于在 Dashboard 中过滤。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: doris-disaggregated-monitor
namespace: monitoring
labels:
release: prometheus
spec:
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app.doris.disaggregated.cluster: test-disaggregated-cluster
endpoints:
- port: http
path: /metrics
interval: 15s
relabelings:
# 1. 统一 job 名称
- action: replace
targetLabel: job
replacement: doris-cluster
# 2. 按 Service 名称后缀映射到组件分组:-cg1 -> be, -fe -> fe, -ms -> meta_service
- sourceLabels: [__meta_kubernetes_service_name]
regex: .*-cg1
replacement: be
targetLabel: group
- sourceLabels: [__meta_kubernetes_service_name]
regex: .*-fe
replacement: fe
targetLabel: group
- sourceLabels: [__meta_kubernetes_service_name]
regex: .*-ms
replacement: meta_service
targetLabel: group
- port: brpc-port
path: /brpc_metrics
interval: 15s
relabelings:
# 1. 统一 job 名称
- action: replace
targetLabel: job
replacement: doris-cluster
# 2. 按 Service 名称后缀映射到组件分组:-cg1 -> be, -fe -> fe, -ms -> meta_service
- sourceLabels: [__meta_kubernetes_service_name]
regex: .*-cg1
replacement: be
targetLabel: group
- sourceLabels: [__meta_kubernetes_service_name]
regex: .*-fe
replacement: fe
targetLabel: group
- sourceLabels: [__meta_kubernetes_service_name]
regex: .*-ms
replacement: meta_service
targetLabel: group
2.2 ServiceMonitor 关键字段说明
| 字段 | 取值 | 说明 |
|---|---|---|
metadata.namespace | monitoring | ServiceMonitor 必须与 Prometheus 实例位于同一命名空间 |
metadata.labels.release | prometheus | 与 Helm Release 名称保持一致,Prometheus Operator 据此发现 ServiceMonitor |
spec.namespaceSelector.matchNames | default | Doris 集群所在的命名空间,按实际情况调整 |
spec.selector.matchLabels | app.doris.disaggregated.cluster: test-disaggregated-cluster | 用于选中 Doris 存算分离集群的 Service,集群名按实际情况修改 |
endpoints[0].port | http | FE/BE/Meta Service 暴露 /metrics 的 HTTP 端口名 |
endpoints[1].port | brpc-port | BE 暴露 /brpc_metrics 的 bRPC 端口名 |
endpoints[*].interval | 15s | 抓取间隔,可按数据量与精度需求调整 |
relabelings 的 group 标签 | be / fe / meta_service | 通过 Service 名称后缀将指标划分到三类组件,用于 Dashboard 变量过滤 |
2.3 应用 YAML 并验证
目的:让 Prometheus Operator 检测到新的 ServiceMonitor 并刷新采集目标。
kubectl apply -f doris-monitor.yaml
在浏览器中访问 Prometheus(默认端口 9090,例如 http://your_ip:9090),打开 Status → Targets,确认 doris-cluster 下的 FE、BE、Meta Service 目标均处于 UP 状态。
第 3 步:配置 Grafana 与 Dashboard
3.1 登录 Grafana
目的:访问 kube-prometheus-stack 自带的 Grafana,并完成首次登录。
-
在浏览器中访问 Grafana(默认端口
3000,例如http://your_ip:3000)。 -
用户名为
admin,通过以下命令获取初始密码:kubectl get secret --namespace monitoring prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
3.2 导入 Doris Dashboard
目的:使用官方提供的 Dashboard JSON 文件可视化 Doris 集群指标。
-
下载官方 Dashboard 文件:Doris-Dashboard-Cloud.json
-
在 Grafana 中通过 Dashboards → New → Import 导入该 JSON 文件,并将数据源选择为已自带的 Prometheus。
-
在 Dashboard URL 后追加
&var-cluster_id=doris-cluster以匹配 ServiceMonitor 中设置的job名称,例如:http://your_ip:3000/d/3fFiWJ4mz456/doris-cloud-dashboard-overview?orgId=1&var-cluster_id=doris-cluster&refresh=5s
3.3 补充节点监控(可选)
目的:示例 JSON 文件未包含主机节点监控面板,可使用 Grafana 官方模板 1860 直接呈现 node-exporter 指标。
-
在 Grafana 中导入 Dashboard:
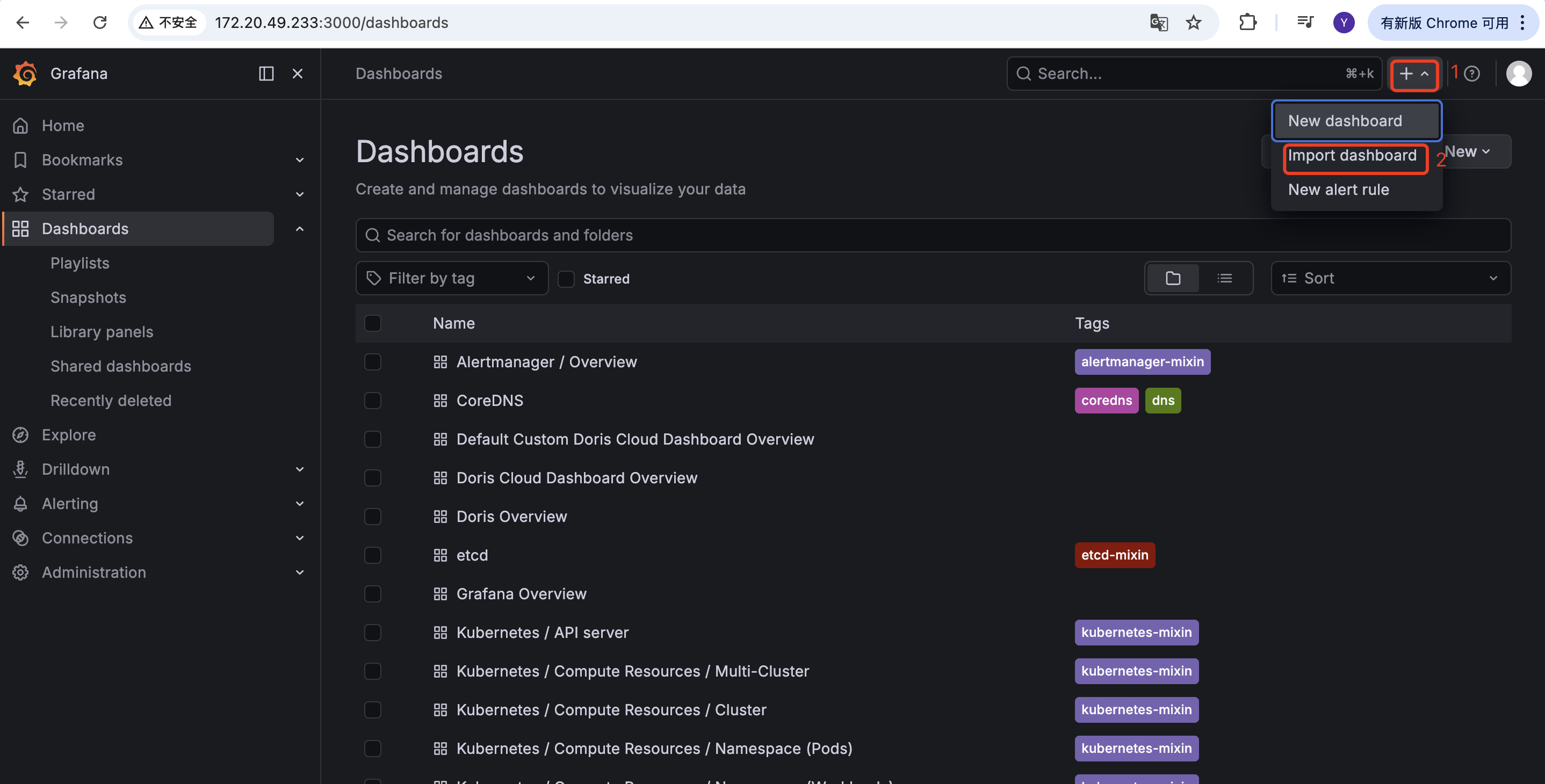
-
选择官方模板编号
1860: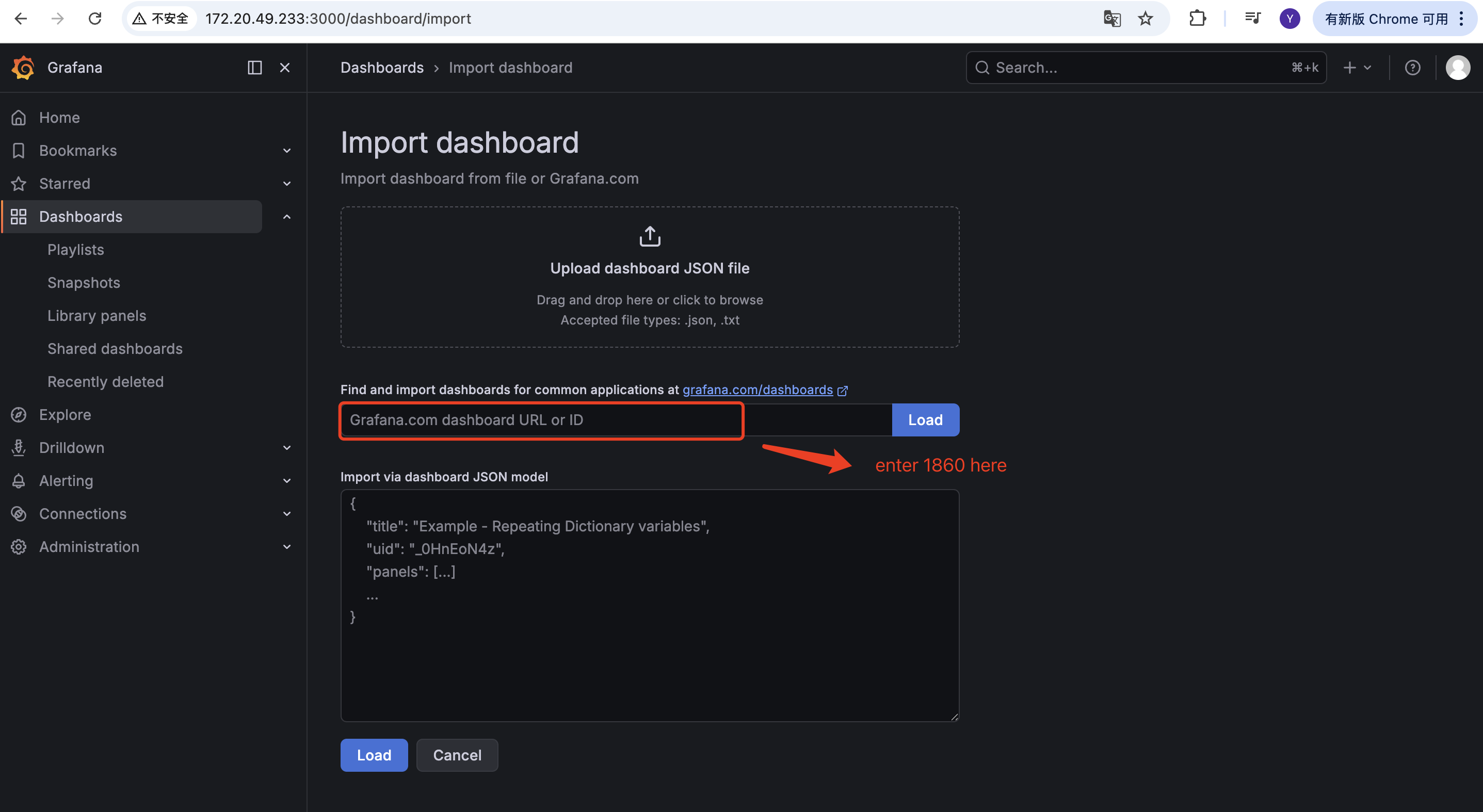
-
导入完成后即可查看节点指标:
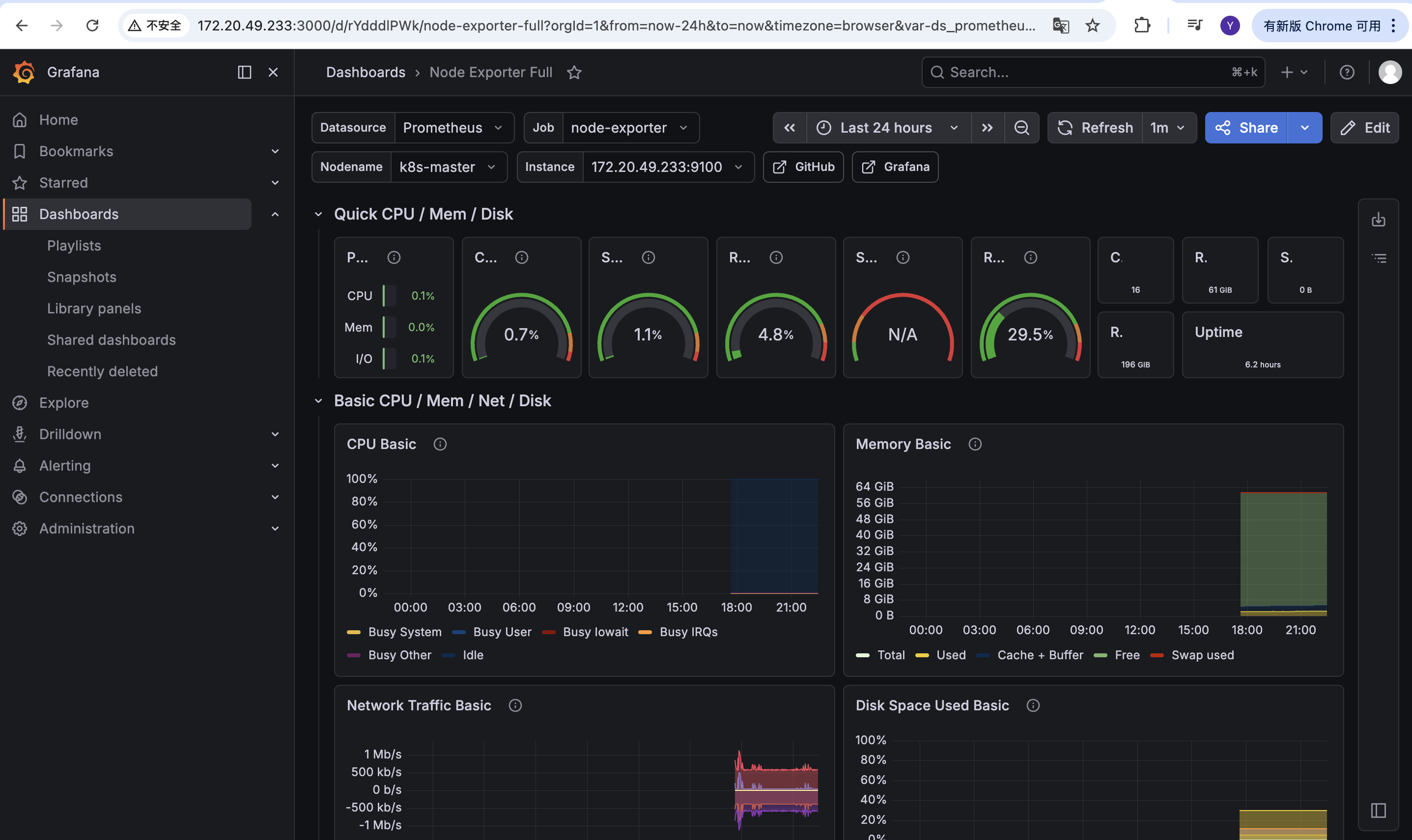
常见问题
| 问题 | 可能原因 | 处理方式 |
|---|---|---|
| Prometheus Targets 中看不到 Doris 目标 | ServiceMonitor 的 namespaceSelector 或 matchLabels 未匹配实际 Doris 集群;release 标签与 Helm Release 名称不一致 | 核对集群所在命名空间、Service 标签 app.doris.disaggregated.cluster,以及 ServiceMonitor 的 release 标签是否为 prometheus |
Targets 显示但状态为 DOWN | Pod 未就绪,或 http / brpc-port 端口与实际暴露的端口名不一致 | 使用 kubectl get svc -n default 与 kubectl describe pod 确认端口名称、就绪状态及容器内 /metrics、/brpc_metrics 可访问 |
| Grafana Dashboard 面板为空 | URL 中未带 var-cluster_id=doris-cluster,或 ServiceMonitor 的 job 名称被改动 | 检查 Dashboard URL 的 var-cluster_id 与 ServiceMonitor 中 job 标签是否同为 doris-cluster |
| 无法访问 Prometheus 的 9090 或 Grafana 的 3000 | Service 默认类型为 ClusterIP,外部不可达 | 通过 kubectl port-forward 转发,或将对应 Service 改为 NodePort / LoadBalancer |
获取 Grafana 密码命令报 NotFound | Helm Release 名称不是 prometheus,导致 Secret 名称不同 | 使用 kubectl get secret -n monitoring 查看实际的 Grafana Secret 名称,再替换命令中的 prometheus-grafana |