最后于 更新
日志与 Trace 搜索
Discover 页面提供类似 Kibana Discover 的检索分析体验,并针对高性能日志分析进行了交互优化。
主要能力包括:
- 支持 SQL 与 Lucene 两种查询语法
- 从 Log 一键点击关联到 Trace
- 时间范围、过滤条件等交互式选择
- 提供表格与 JSON 两种结果视图
- 查看某条数据周围的数据方便上下文分析
- 字段值分布统计(Top 5 值及占比)
Discover 页面概览
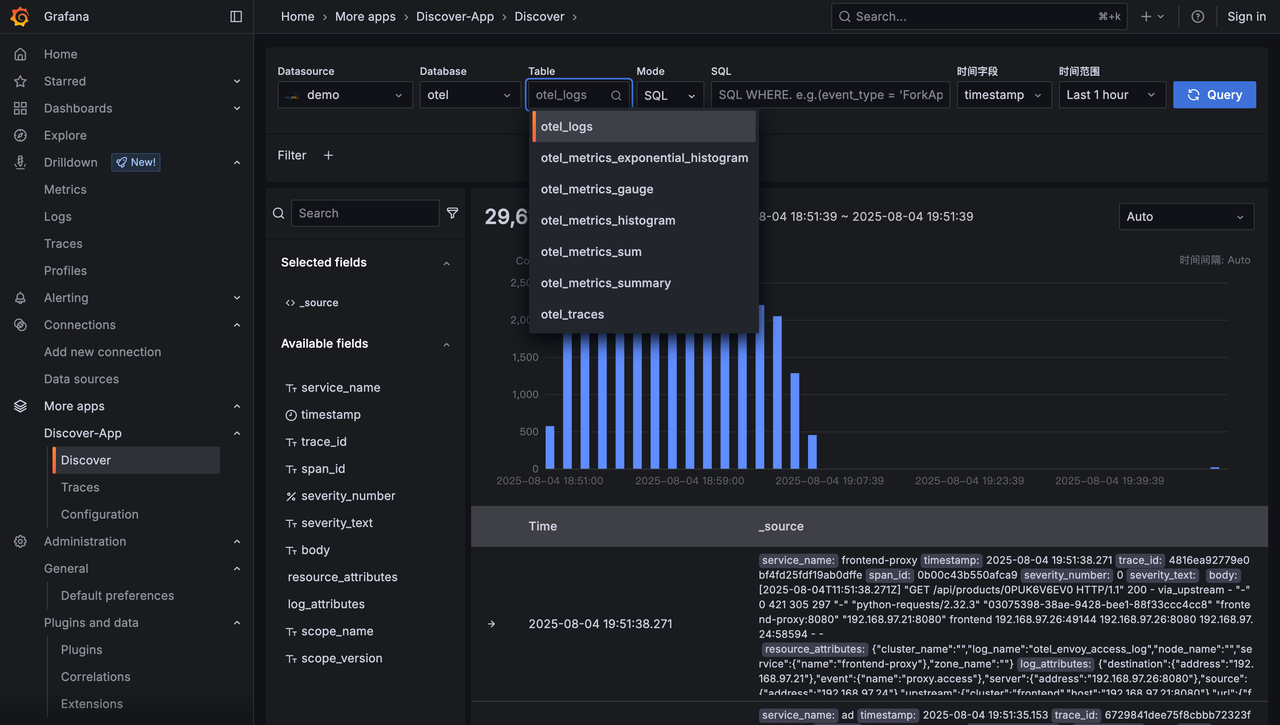
Discover 页面由四个核心区域组成:
1.查询输入区(顶部)
用于配置查询范围与编写查询语句,功能包括:
- 选择数据源
- 选择时间字段和时间范围
- 输入搜索条件,支持 SQL 和 Lucene 两种语法
2.时间趋势区(中部)
以直方图展示查询结果在时间维度上的分布,功能包括:
- 快速观察满足条件的数据量时间趋势图
- 框选时间区间选择查询的时间范围
3.明细数据区(底部)
展示查询结果的详细记录,并支持上下文探索,功能包括:
- 展示满足查询条件的最新数据明细,如果有 Trace ID 可以点击查看 Trace 详情
- 展开单条日志查看完整字段,支持表格和 JSON 两种形式
- 在表格形式中交互式生成过滤条件
- 查看某条数据的上下文
4.字段浏览区(左侧)
显示当前数据表的全部字段,并支持字段级探索。
功能包括:
- 选择需要展示在右侧明细数据区的字段,默认展示的 _source 是将所有字段
- 悬停查看字段 Top 5 高频值及占比
- 点击字段值上的 "+" 或 "-" 交互式生成过滤条件,自动同步到顶部查询栏。
查询输入
你可以在查询输入区通过下拉菜单选择数据源、库、表、时间字段和时间范围,数据源、库、表的默认值在配置页面中可以修改,时间字段默认是表中第一个 DATETIME 或 DATE 类型的字段。
搜索输入框支持 SQL 和 Lucene 两种语法,Lucene 语法在内部会被转换成 SQL WHERE 条件。支持的 Lucene 语法和 SQL 以及 Kibana 语法的对应关系如下表。
| 功能 | Doris App Lucene 语法 | Kibana | SQL WHERE 条件 | 说明 |
|---|---|---|---|---|
| 单个字段关键词匹配 | service_name:kafka | 相同 | service_name MATCH 'kafka' | 精确字段匹配,转换为 service_name MATCH_ANY 'kafka' |
| 所有字段关键词匹配 | error | 相同 | (service_name MATCH 'error') OR (scope_name MATCH 'error') | 在所有倒排索引字段中进行全文匹配,自动重写为多字段 MATCH_ANY |
| 单个字段短语匹配 | service_name:"kafka logs" | 相同 | service_name MATCH_PHRASE 'kafka logs' | 字段级短语匹配 |
| 所有字段短语匹配 | "kafka logs" | 相同 | service_name MATCH_PHRASE 'kafka logs') | 精确短语匹配,转换为 MATCH_PHRASE |
| 通配符 | kaf* | 相同 | ((service_name MATCH_PHRASE_PREFIX 'kaf') OR (scope_name MATCH_PHRASE_PREFIX 'kaf')) | 前后缀通配符,转换为 MATCH_PHRASE_PREFIX |
| 数值 / 时间范围 | duration:[100 TO 500] | 相同 | duration BETWEEN 100 AND 500 | 转换为 SQL BETWEEN |
| 无界范围 | duration:>500 | 相同 | duration > '500' | 转换为 SQL 比较运算 |
| 开闭区间 | {100 TO 200} | 相同 | 花括号表示开区间 | |
| AND 逻辑组合 | service_name:kafka AND status:failed | 相同 | (service_name MATCH 'kafka') AND (status MATCH 'failed') | 逻辑与组合 |
| OR 逻辑组合 | error OR warning | 相同 | 逻辑或组合 | |
| NOT 逻辑组合 | NOT kafka 或 -kafka | 相同 | NOT (service_name MATCH 'kafka') | 逻辑非组合 |
| 分组条件 | (service_name:kafka OR service_name:zookeeper) AND status:failed | 相同 | ((service_name MATCH 'kafka') OR (service_name MATCH 'zookeeper')) AND (status MATCH 'failed') | 支持复杂逻辑组合 |
Lucene 语法的关键点如下
- 基本语法是 field_name:match_condition
- "filed_name:" 指定对单个字段 filed_name 匹配后面的条件 match_condition,如果没有 "field_name:" 而只有 match_condition 则代表所有字段中任何一个字段匹配就算匹配(或关系)
- 匹配条件 match_condition 对文本有 3 种形式
- 双引号包围起来的条件代表短语匹配,需要同时匹配引号中的多个词且顺序与引号中一致
- 没有双引号包围的条件代表关键词匹配,只需要匹配引号中的任意一个词
- 星号代表通配符
- 匹配条件 match_condition 对数值和日期有 3 种形式
- 单个值代表等值匹配
- >, < 代表范围,与 SQL 类似
- 括号代表区间,中括号代表闭区间,花括号代表开区间
- 多组条件可以通过 AND OR NOT 进行逻辑组合,与 SQL 逻辑组合类似小括号可调整分组优先级
SQL 语法的关键点如下:
- MATCH 和 MATCH_ANY 对应 Lucene 关键词匹配,多个关键词中任意一个匹配即可,也就是 OR 关系
- MATCH_ALL 也是关键词匹配,多个关键词需要每一个都匹配,也就是 AND 关系
- MATCH_PHRASE 对应 Lucene 短语匹配,需要同时匹配多个词且顺序一致
- 等值查询、范围查询分别用通用的 = 和 >, <, BETWEEN
- 多组条件可以通过 AND OR NOT 进行逻辑组合,小括号可调整分组优先级
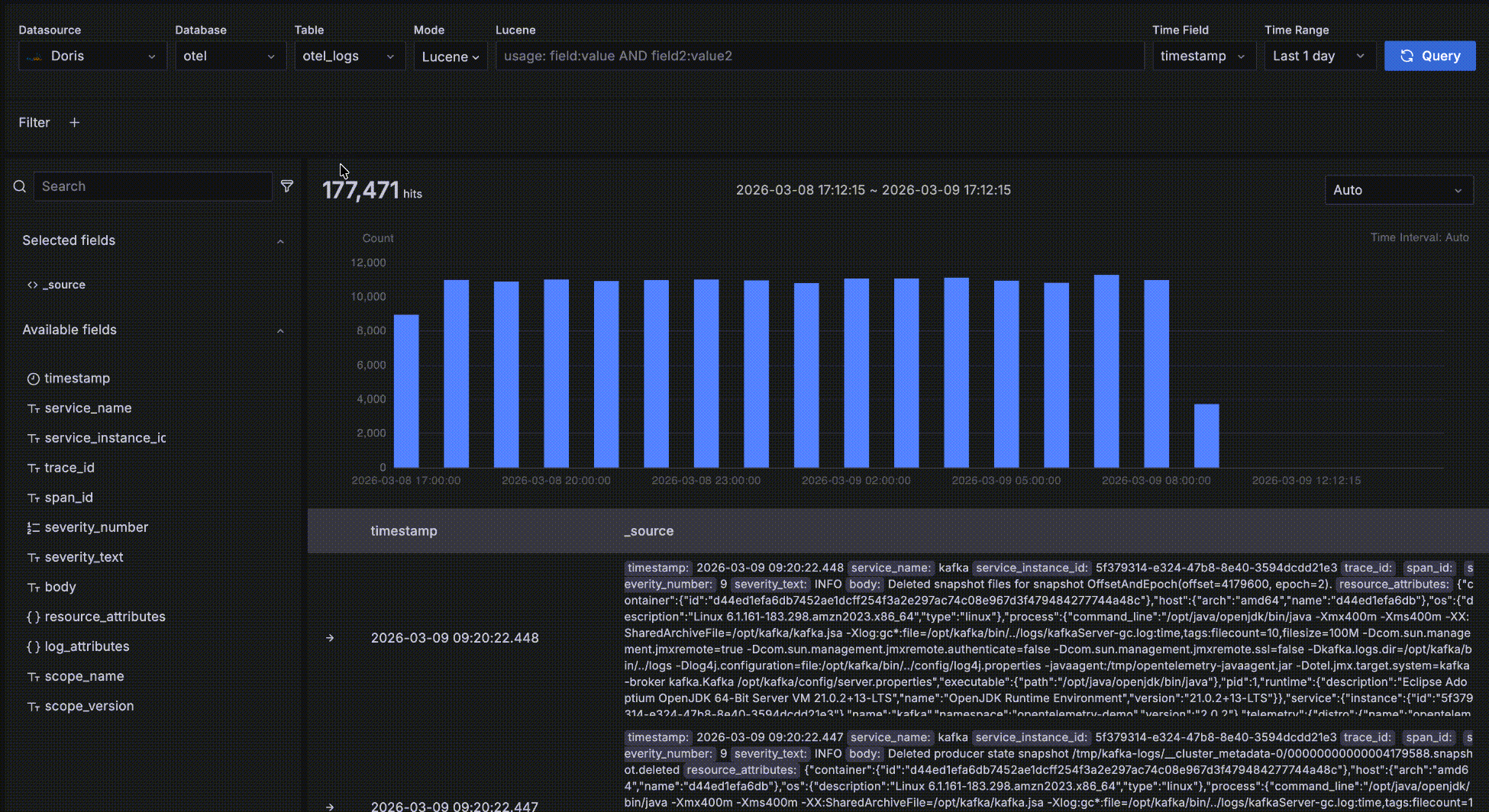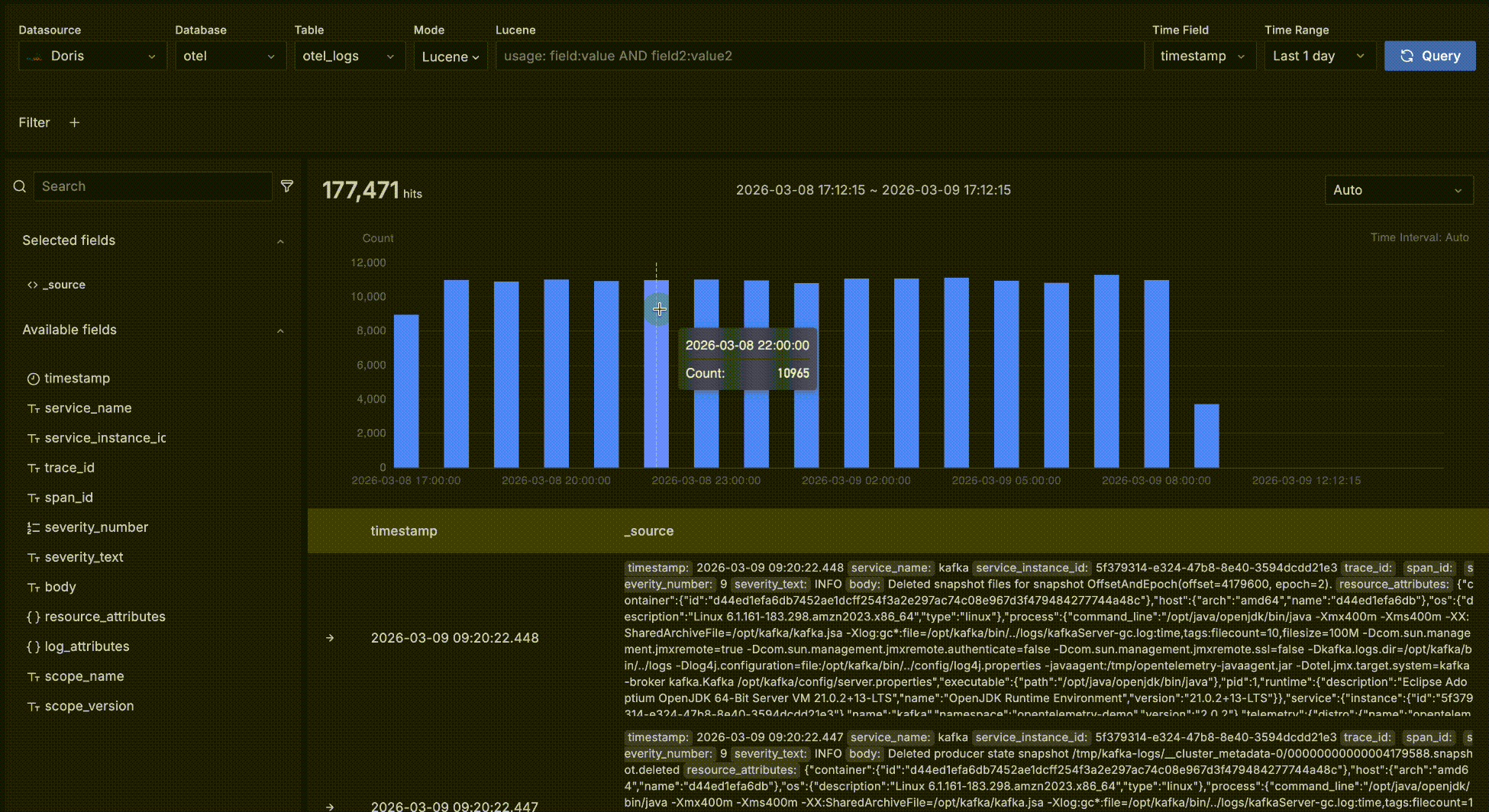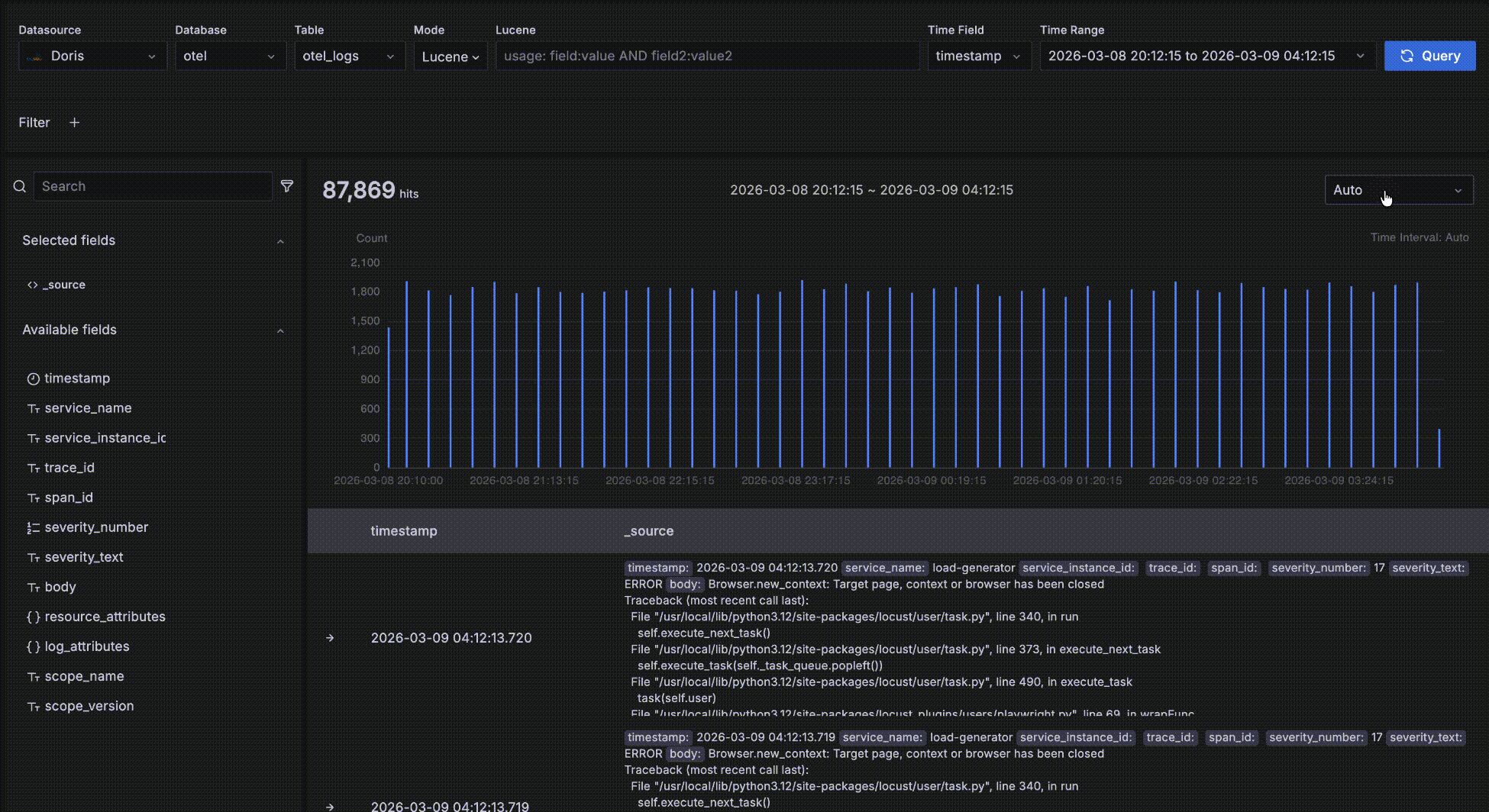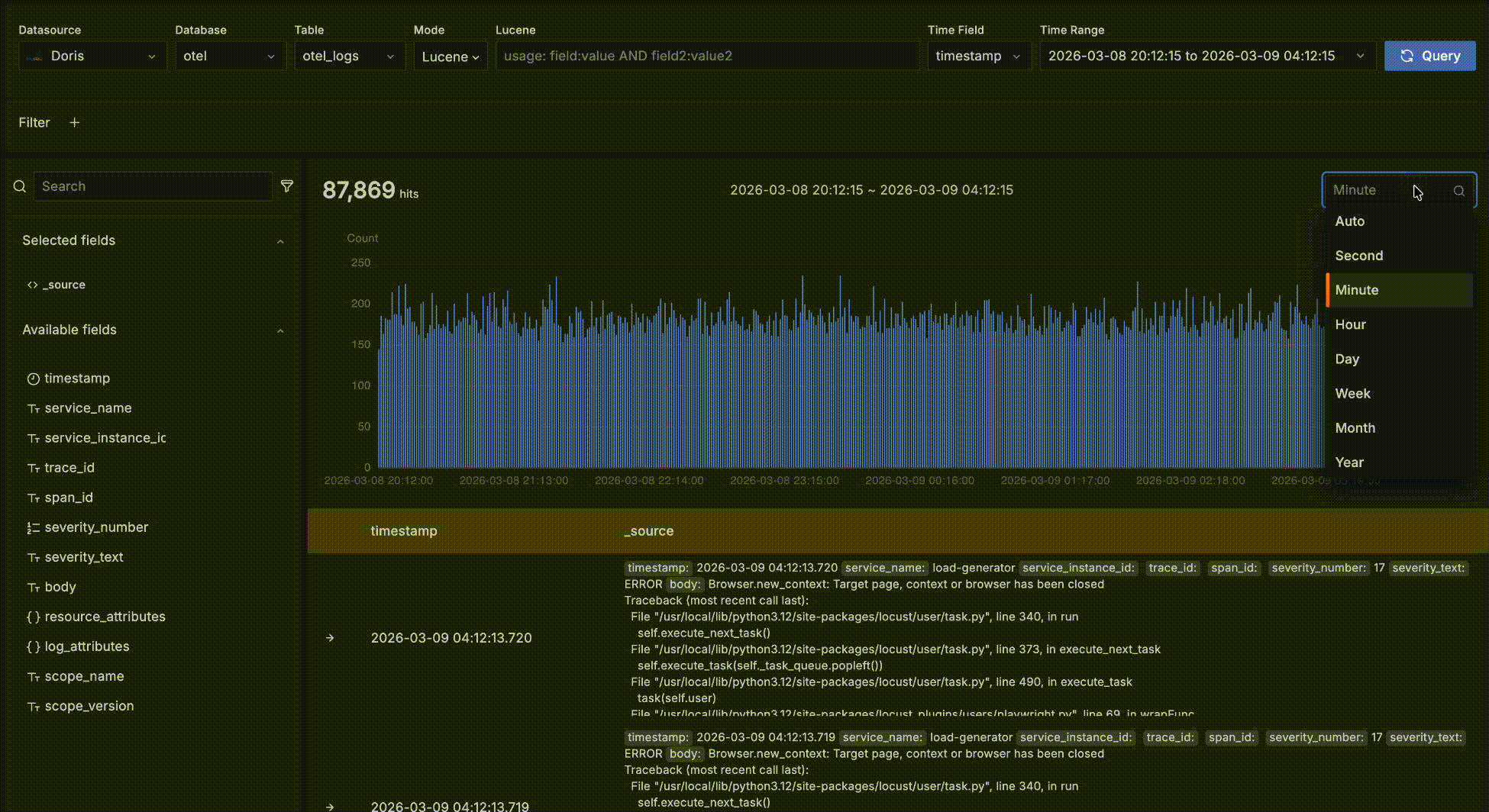
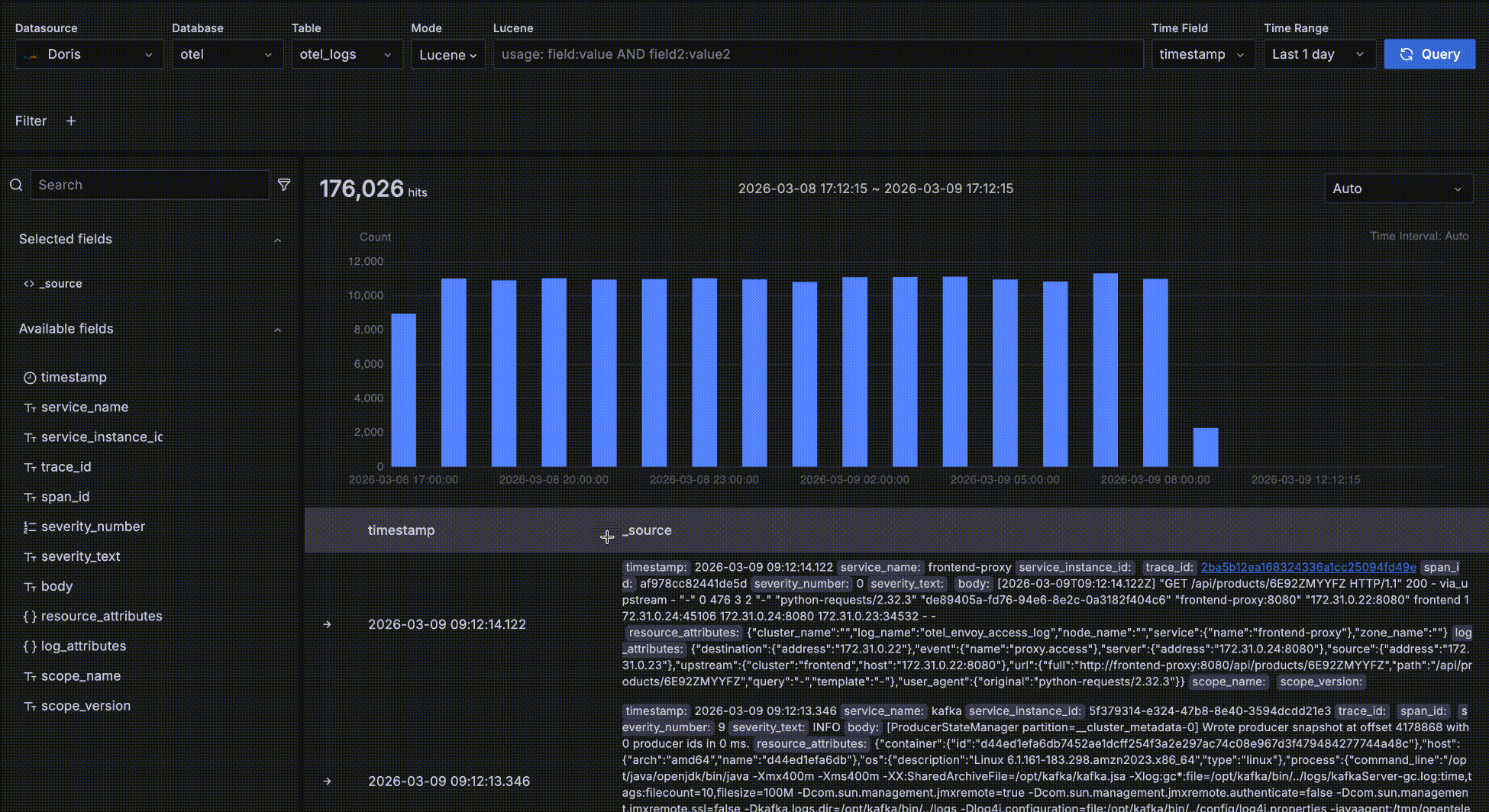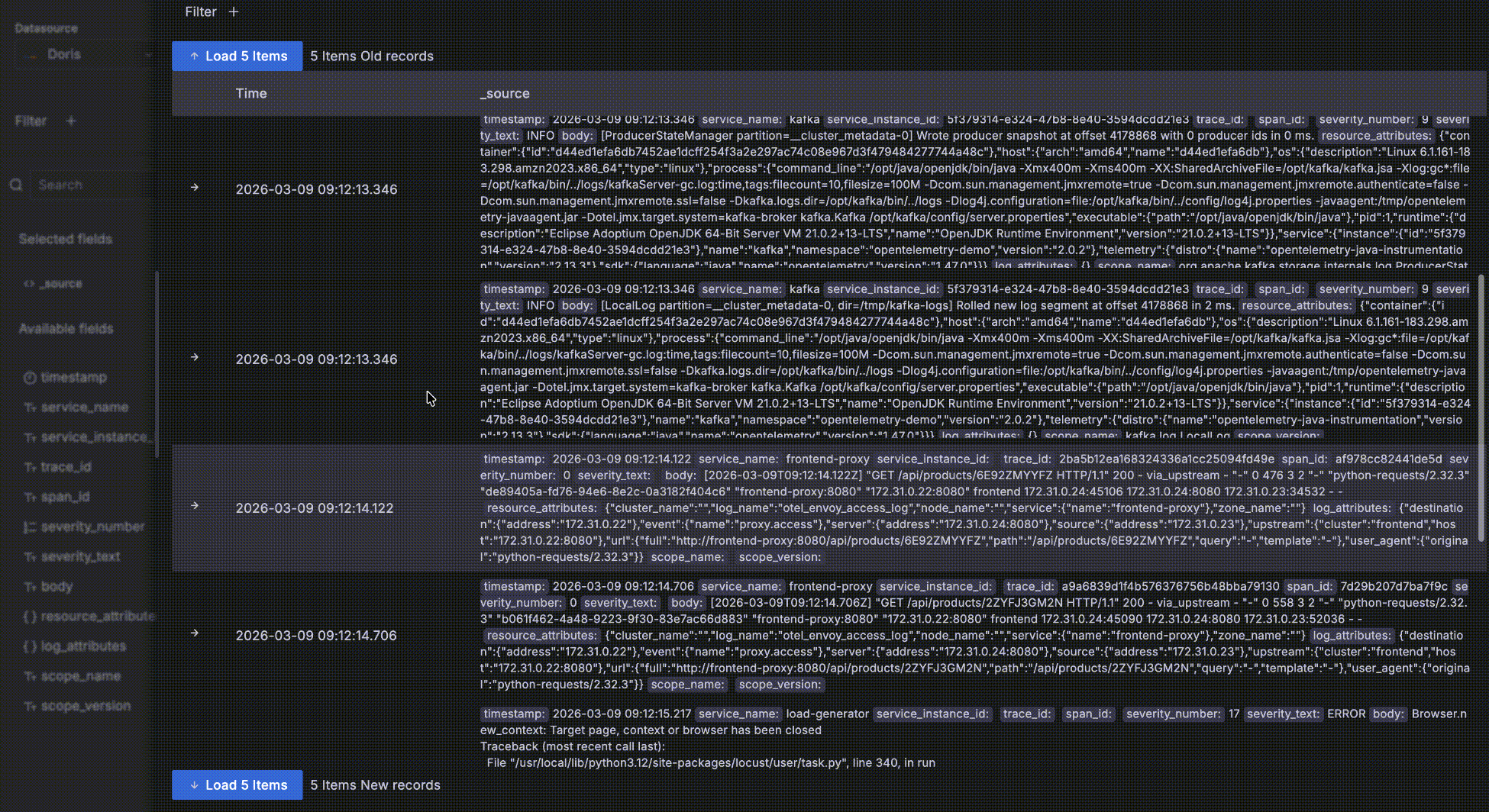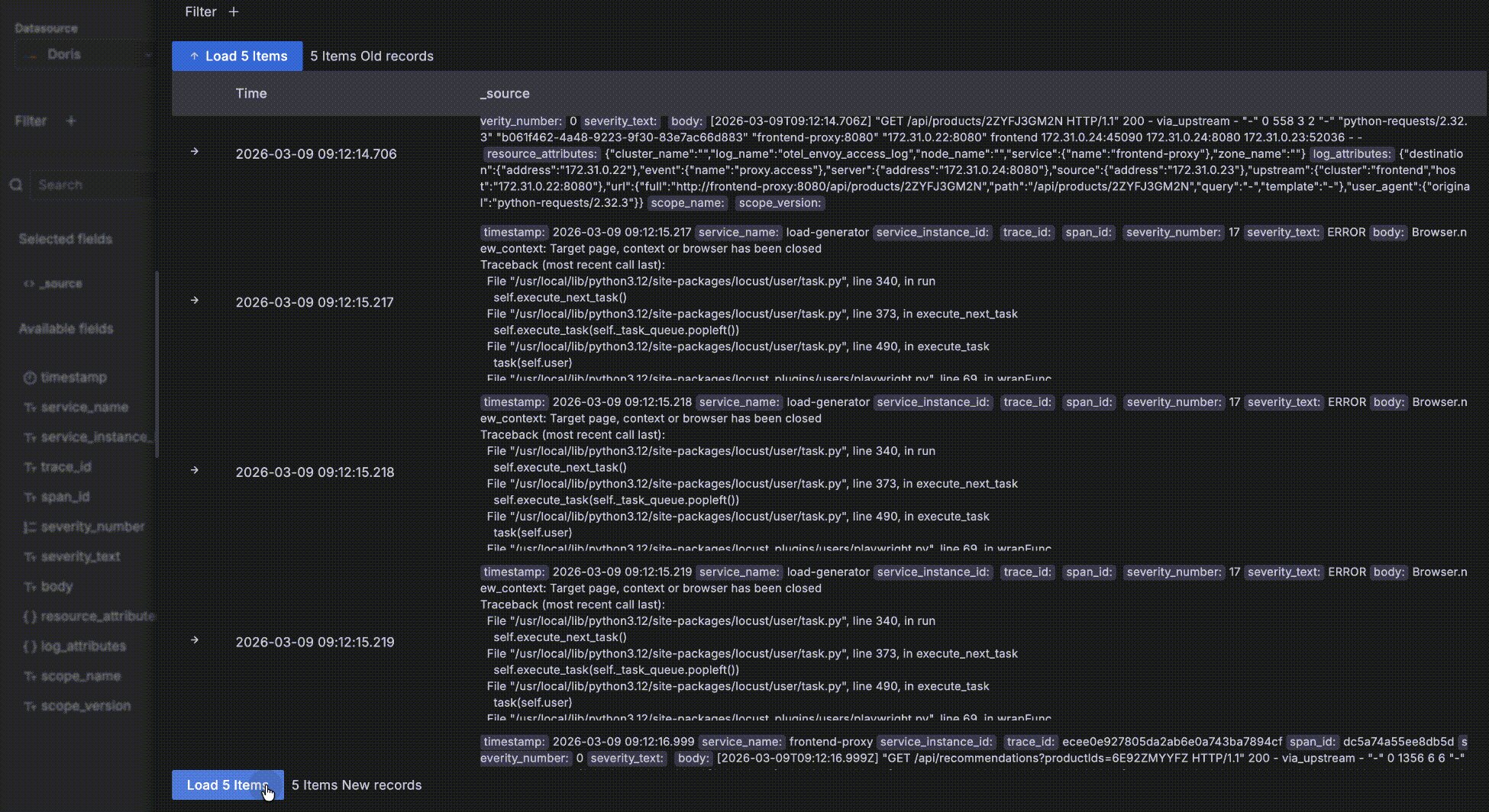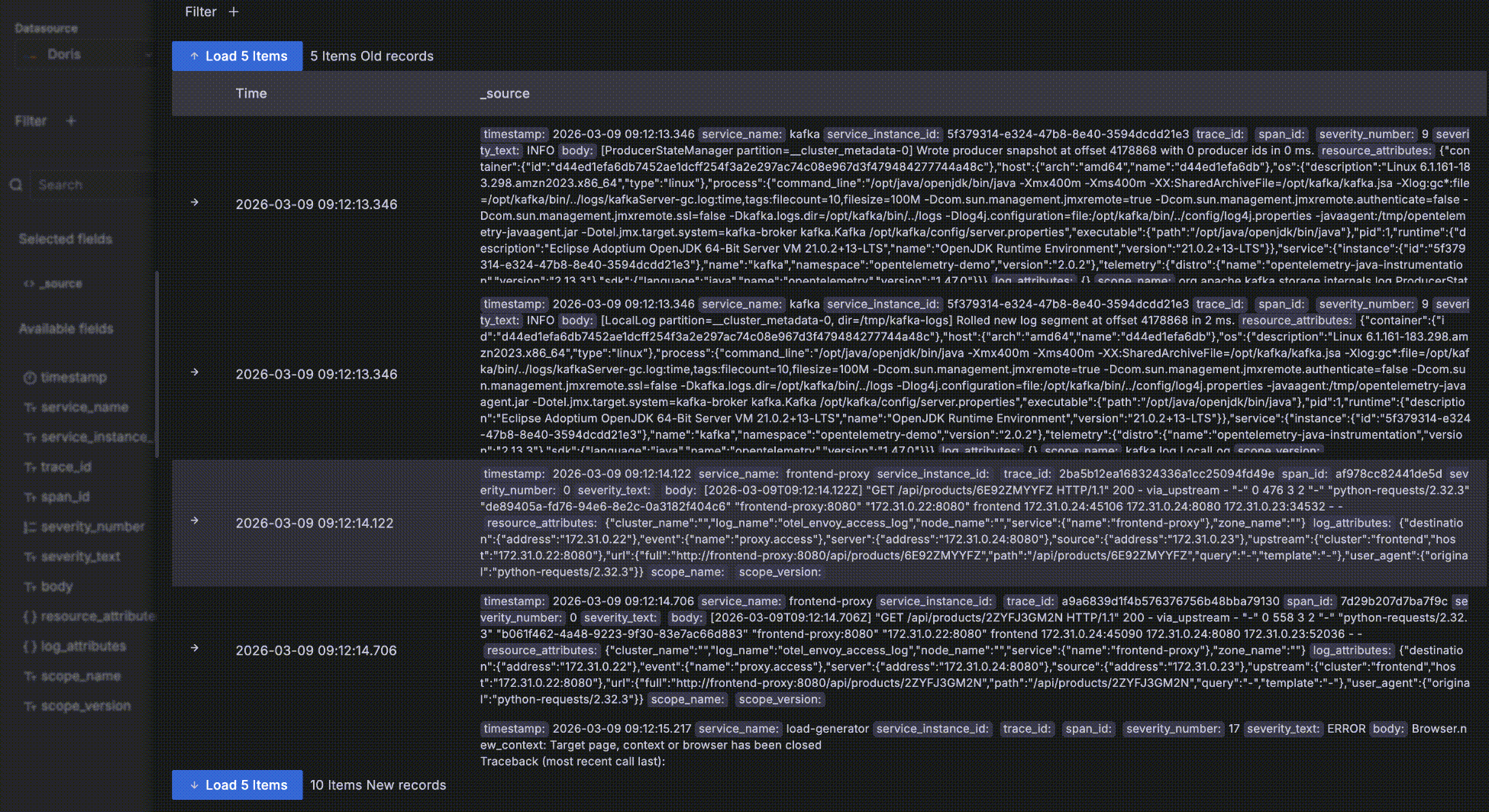
趋势数据
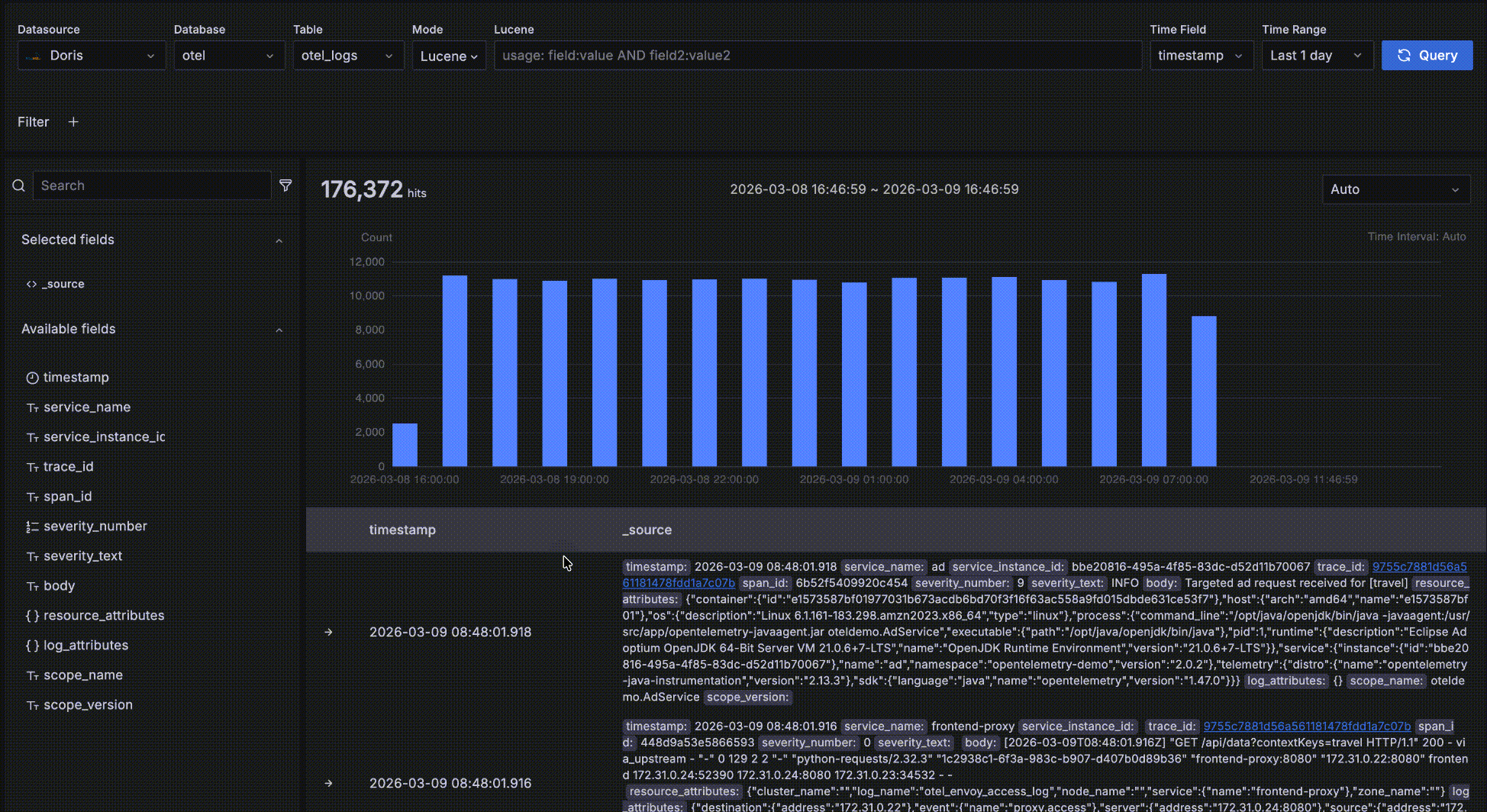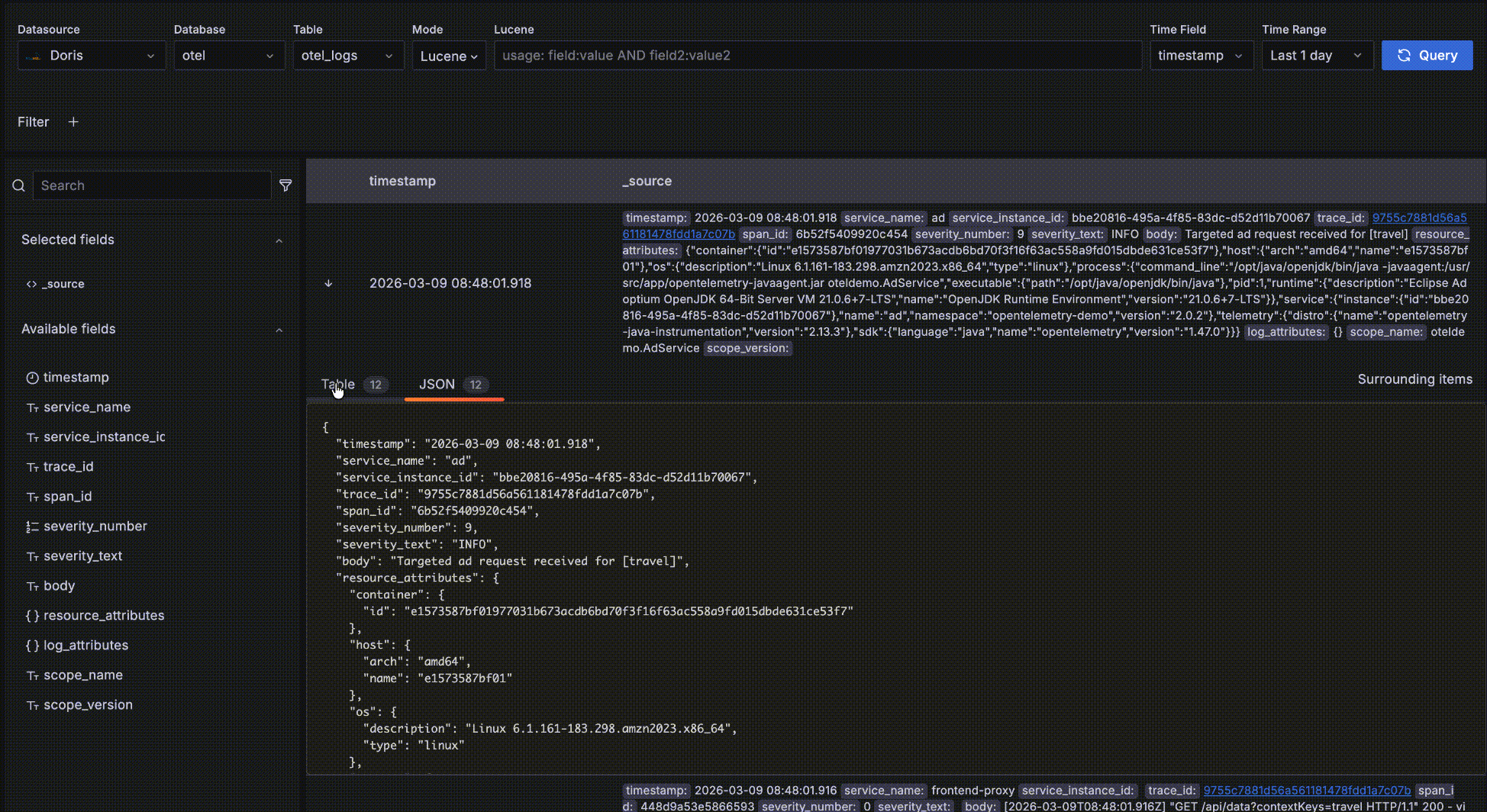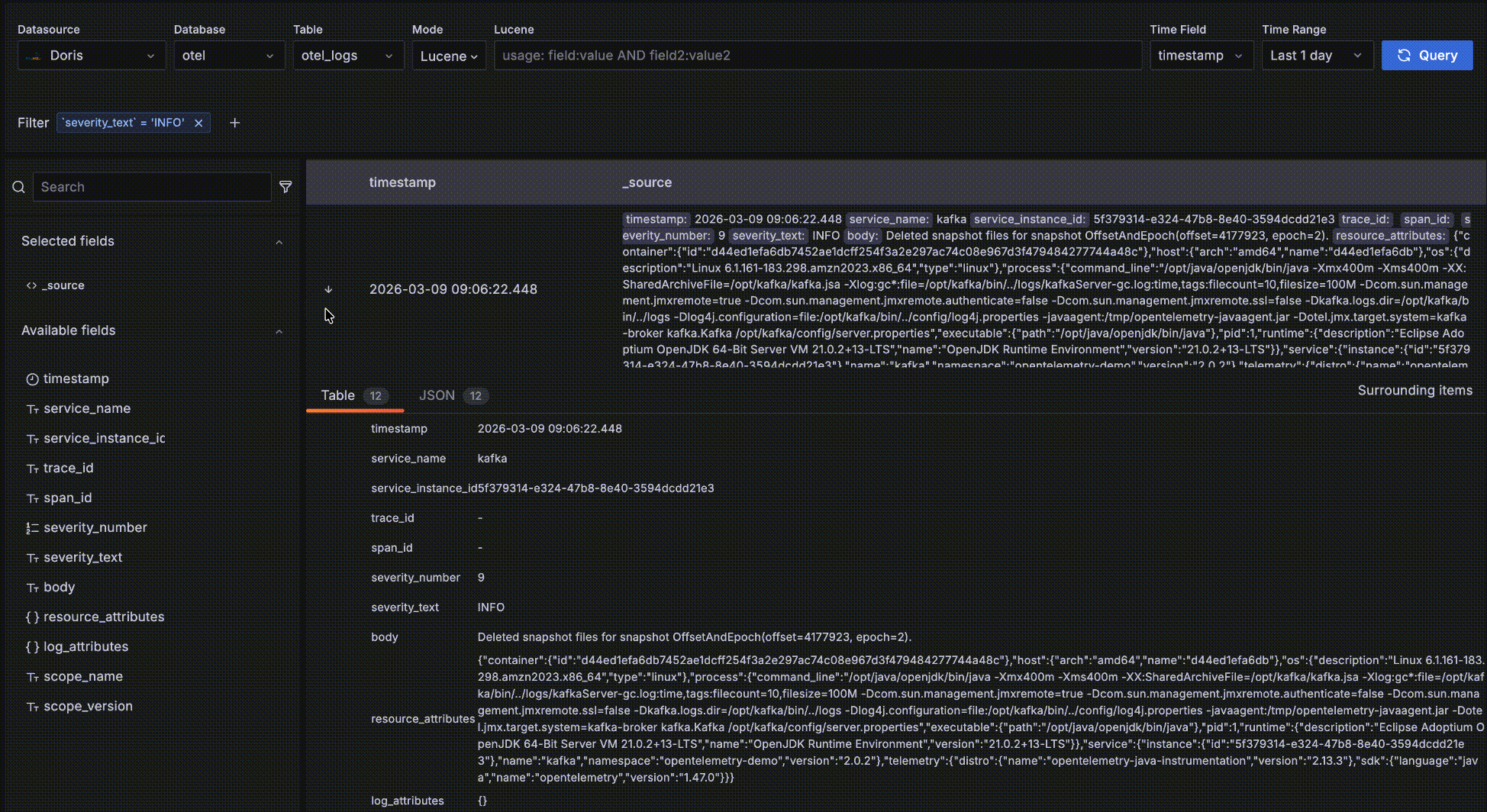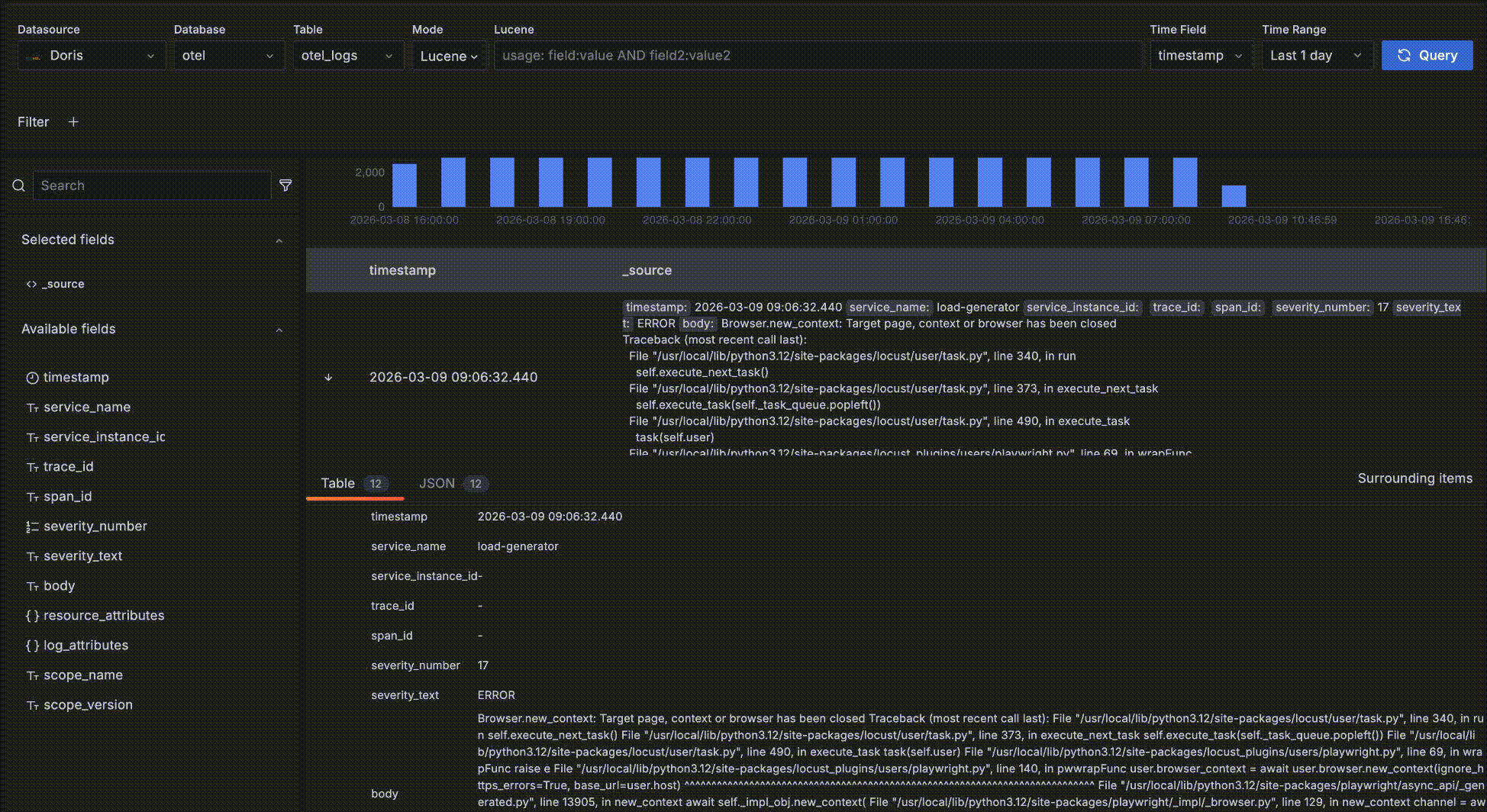
如下图所示,红色方框中的部分是趋势数据区,这个区域是为了方便查看满足条件的数据在不同时间段的数量和趋势,这个趋势图上有几个交互:
- 鼠标悬停在柱状图的柱子上,显示时间段的开始时间和这段时间内满足查询条件的数据量
- 鼠标在趋势图上框选,改变整个查询的时间范围
- 每个柱子的时间段长度默认是 Auto,自动根据整个时间范围缩放,你可以在下拉框中选择不同的粒度,比如秒、分、小时等。
明细数据
如下图所示,红色方框中的区域是明细数据区,展示满足查询条件的明细数据。
- 按照时间字段倒序排序,以便将最新数据显示在最上面。每页展示 50 条数据,可以翻页显示更多。默认展示两个字段:时间字段 和 _source,_source 是所有字段拼接起来的虚拟数据,每个字段以 key: value 形式展示,key 突出显示以便阅读。你可以定制在明细数据区展示哪些字段,在左侧的字段选择区的字段名上点击 "+" 即可将该字段加入右侧表格显示的列中,可以添加多个字段,也可以在右侧表格中点击 "x" 删除字段,当所有字段都删除后恢复到默认的 _source。
- 你可以点击最左边的 "->" 展开一条数据的明细,有 Table 和 JSON 两种形式方式,在 Table 形式下还可以点击字段旁边的 "+" 或则 "-" 交互式添加过滤条件,比如 "serverity_text=INFO"。
- 展开一条明细数据后,还可以点击 "Surrounding items" 查看这条数据的“上下文”,这条数据时间点周围的前后各 5条数据。需要注意的是这个功能常用在分析一个问题时查看一条日志前后的日志,因此会忽略时间之外的其他查询过滤条件,否则跟明细数据表格中的就没有区别了。当然,你还可以查看比前后 5条更多的上下文,也可以添加自己的过滤条件,比如限定在某一个 host 上。
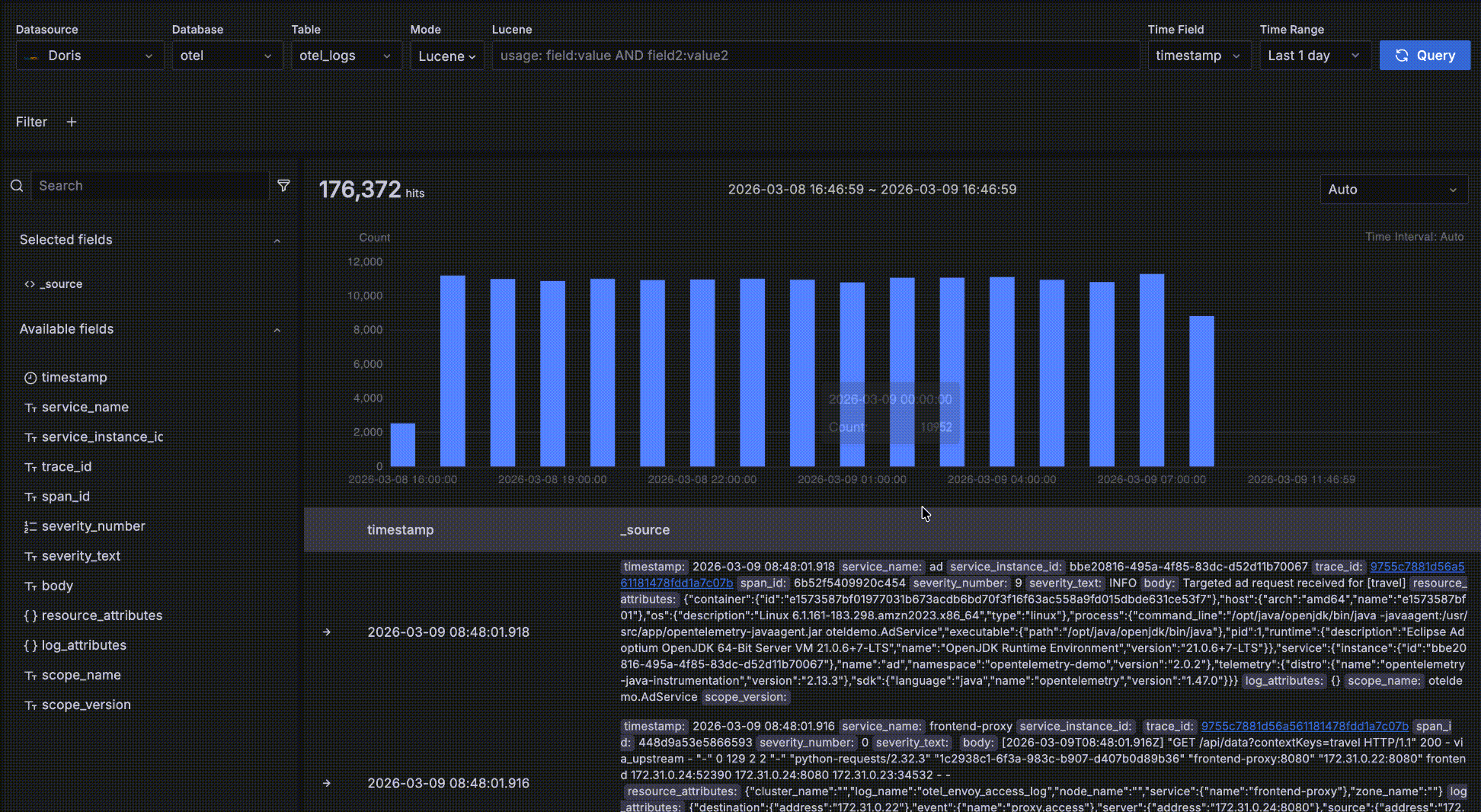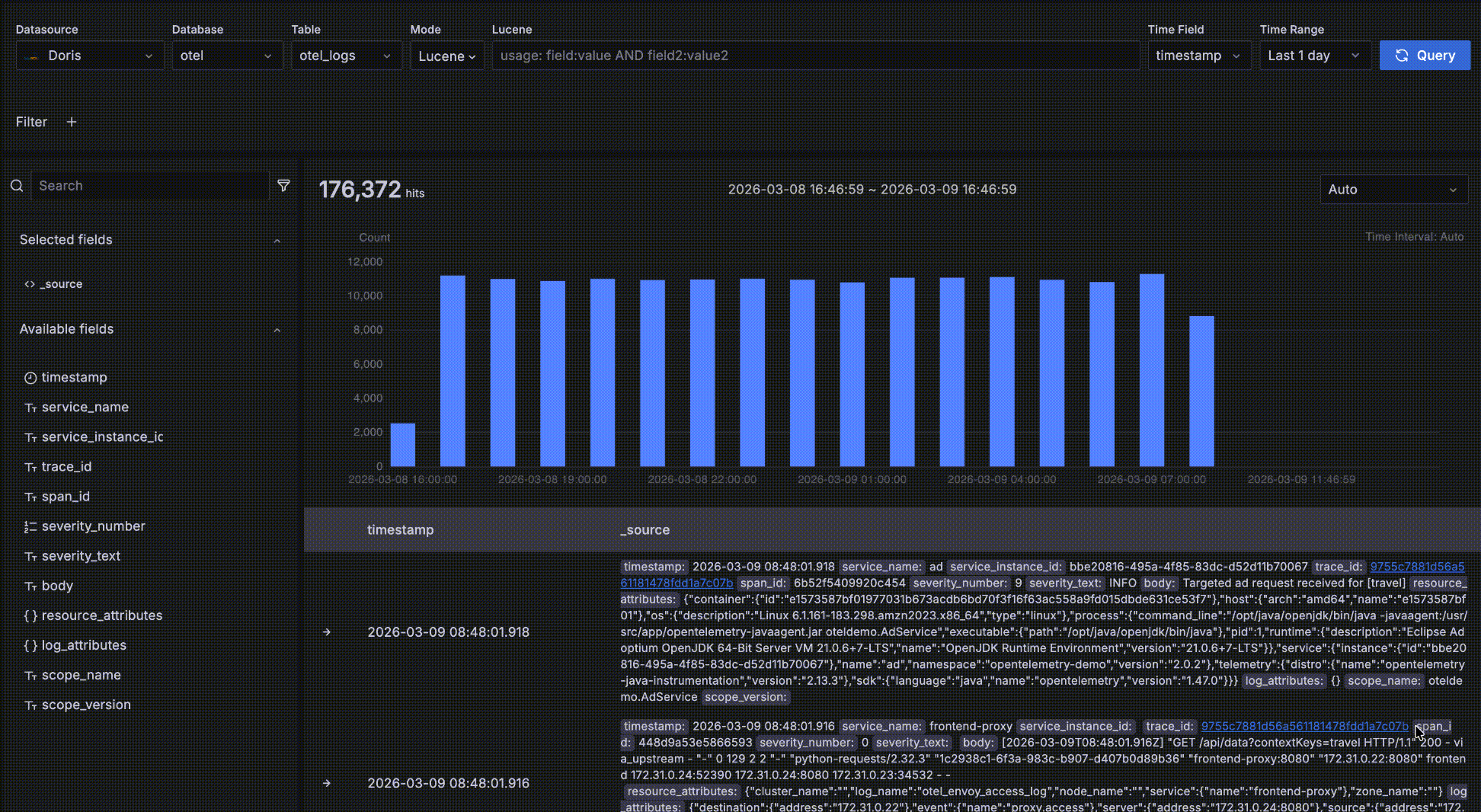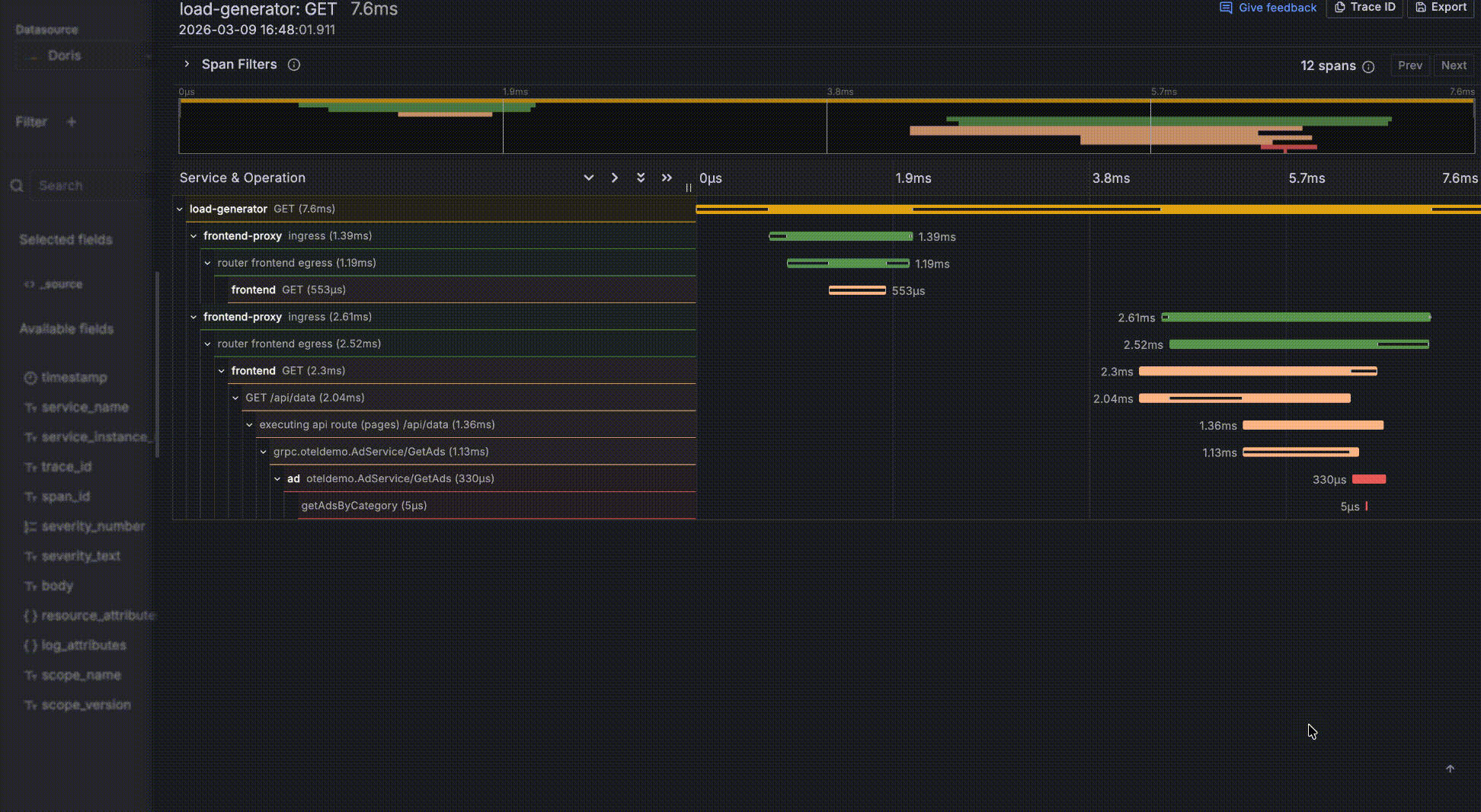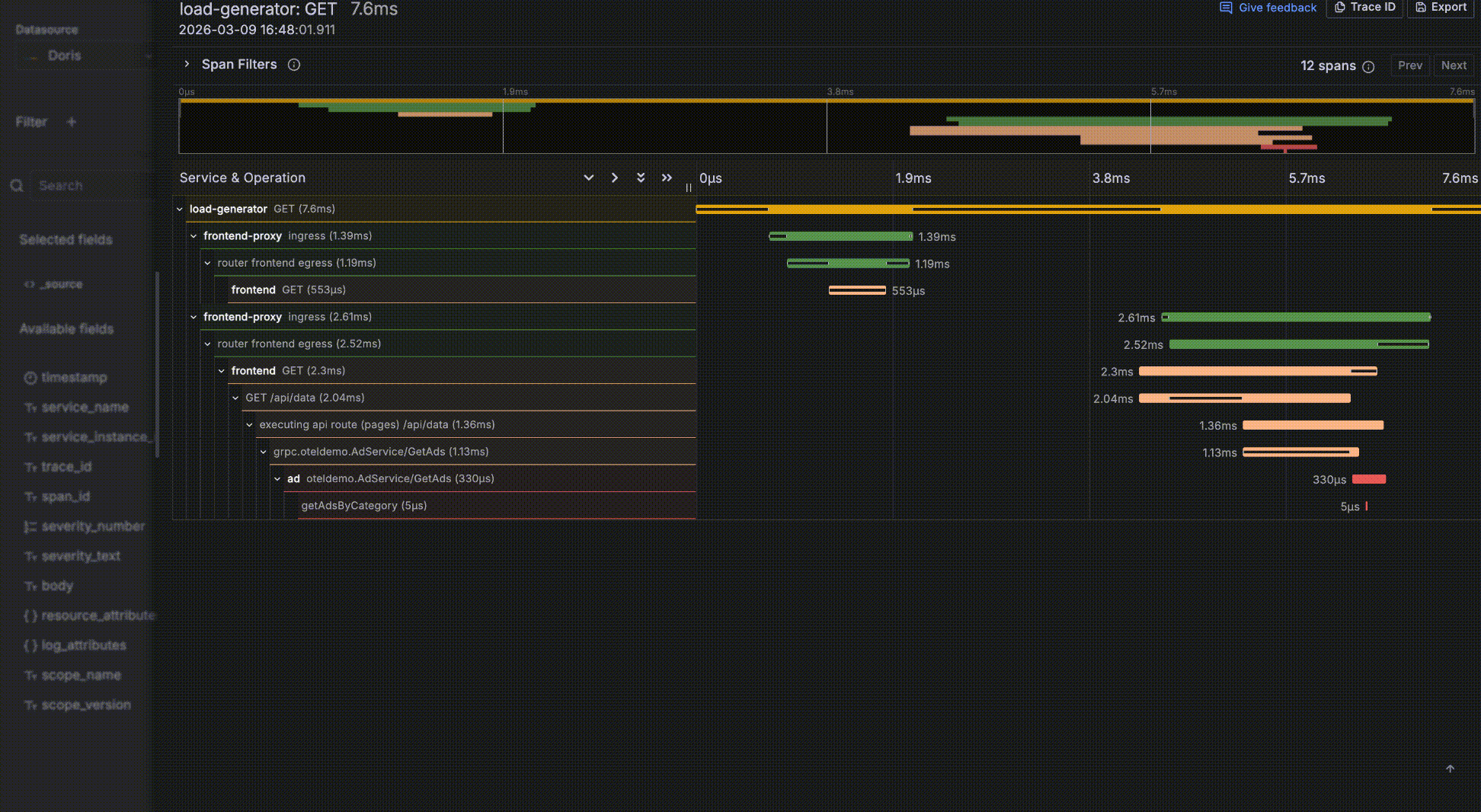
- 某条数据中如果有个字段 trace_id,将被识别为有关联的 trace,字段值会成为一个可点击的链接,点击会弹出 trace 瀑布图抽屉,实现 log 与 trace 的关联联动。
字段浏览
在左侧的字段浏览区可以查看当前 Table 中有哪些字段,并分析字段的值分布。
- 你可以点击字段右侧的 "+" 将字段加入右侧的明细数据表格中。
- 你可以点击字段名查看某个字段出现最多的 5个值,进一步点击值右边的 "+" "-" 动态添加过滤条件。