数据分桶
一个分区可以根据业务需求进一步划分为多个数据分桶(Bucket),每个分桶都作为一个物理数据分片(Tablet)存储。合理的分桶策略可以有效降低查询时的数据扫描量,提升查询性能并增加并发处理能力。
本文按照建表时的决策路径组织:先选择分桶方式,再选择分桶键,最后确定分桶数量与后续维护方式。
快速决策
在建表时,可按以下顺序完成分桶设计:
| 步骤 | 决策项 | 关键依据 |
|---|---|---|
| 1 | 选择分桶方式 | 是否有高频过滤列、数据是否均匀、表模型 |
| 2 | 选择分桶键(仅 Hash 分桶) | 查询过滤条件、列基数、查询并发与吞吐特征 |
| 3 | 确定分桶数量 | 单 Tablet 数据大小、BE 数量、磁盘数 |
| 4 | 规划分桶维护策略 | 数据量增长趋势、是否使用动态分区 |
一、选择分桶方式
Doris 支持两种分桶方式:Hash 分桶与 Random 分桶。两者的核心差异如下:
| 对比项 | Hash 分桶 | Random 分桶 |
|---|---|---|
| 数据分布方式 | 按分桶键的 Hash 值划分 | 随机均匀分布 |
| 是否需要分桶键 | 需要 | 不需要 |
| 是否支持分桶剪裁 | 支持 | 不支持 |
| 适用表模型 | DUPLICATE / UNIQUE / AGGREGATE | 仅 DUPLICATE |
| 数据倾斜风险 | 取决于分桶键选择 | 较低 |
| 适用场景 | 高频按某列过滤的点查 | 任意维度分析、易倾斜数据 |
1. Hash 分桶
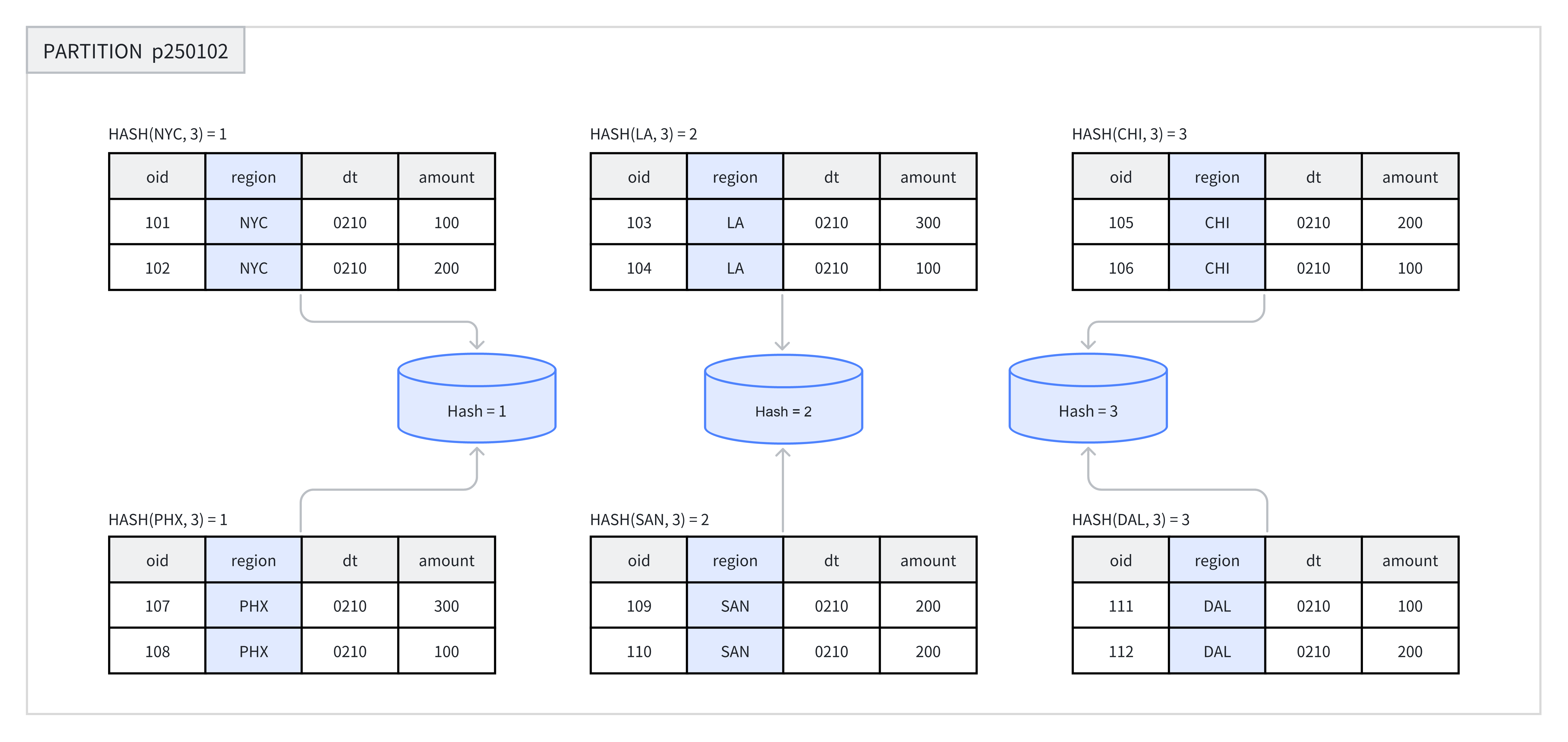
在创建表或新增分区时,用户需选择一列或多列作为分桶键,并明确指定分桶数量。在同一分区内,系统会根据分桶键和分桶数量进行 Hash 计算,Hash 值相同的数据会被分配到同一个分桶中。
例如下图中,p250102 分区根据 region 列被划分为 3 个分桶,Hash 值相同的行被归入同一个分桶。
推荐使用场景:
- 业务频繁基于某个字段进行过滤时,可将该字段作为分桶键,利用分桶剪裁提升查询效率;
- 表中数据分布较为均匀,不易出现倾斜。
示例: 创建带有 Hash 分桶的表,详细语法请参考 CREATE TABLE。
下面的示例使用 demo 库来限定表名;若集群上不存在请先创建:
CREATE DATABASE IF NOT EXISTS demo;
CREATE TABLE demo.hash_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
示例中,DISTRIBUTED BY HASH(region) 指定使用 Hash 分桶,并选择 region 列作为分桶键;BUCKETS 8 指定创建 8 个分桶。
2. Random 分桶
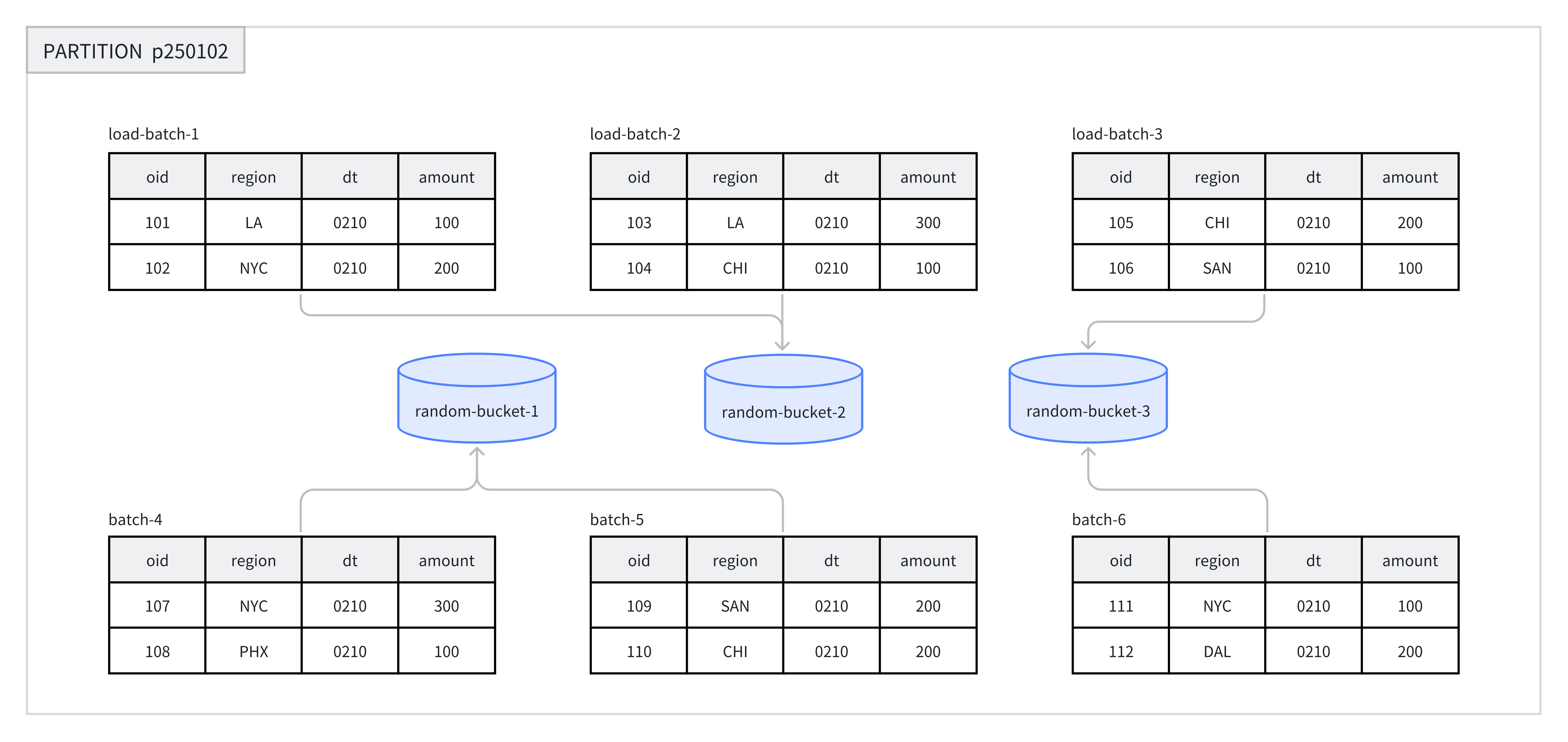
Random 分桶在每个分区中随机将数据分散到各个分桶中,不依赖于某个字段的 Hash 值。这种方式能够确保数据均匀分散,避免因分桶键选择不当而引发的数据倾斜问题。
在导入数据时,单次导入作业的每个批次会被随机写入到一个 Tablet 中,以此保证数据的均匀分布。例如下图中,8 个批次的数据被随机分配到 p250102 分区下的 3 个分桶中。
在使用 Random 分桶时,可以启用单分片导入模式(设置 load_to_single_tablet 为 true),单个批次的数据仅写入一个数据分片。这样可以:
- 提高大规模数据导入的并发度和吞吐量;
- 减少因数据导入和压缩(Compaction)操作造成的写放大问题;
- 提升集群稳定性。
推荐使用场景:
- 任意维度分析,业务无固定的过滤或关联列;
- 经常查询的列或组合列数据分布极不均匀,需避免数据倾斜。
不适用场景:
- 点查场景:Random 分桶无法基于分桶键进行剪裁,会扫描命中分区的所有数据;
- UNIQUE 与 AGGREGATE 表:仅 DUPLICATE 表支持 Random 分桶。
示例: 创建带有 Random 分桶的表,详细语法请参考 CREATE TABLE。
CREATE TABLE demo.random_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY RANDOM BUCKETS 8;
示例中,DISTRIBUTED BY RANDOM 指定使用 Random 分桶,无需选择分桶键;BUCKETS 8 指定创建 8 个分桶。
二、选择分桶键
只有 Hash 分桶需要选择分桶键,Random 分桶不需要。
分桶键可以是一列或多列,不同表模型对分桶键的限制如下:
| 表模型 | 可选分桶键 |
|---|---|
| DUPLICATE | 任意 Key 列或 Value 列 |
| AGGREGATE / UNIQUE | 必须为 Key 列(保证数据聚合的正确性) |
选择原则
按照业务查询特征,可参考以下原则选择分桶键:
| 原则 | 说明 | 收益 |
|---|---|---|
| 利用查询过滤条件 | 选择查询中频繁出现的过滤列作为分桶键 | 支持分桶剪裁,减少数据扫描量 |
| 利用高基数列 | 选择唯一值较多的列作为分桶键 | 数据均匀分布,避免倾斜 |
| 高并发点查场景 | 选择单列或较少列作为分桶键 | 单次查询仅触发一个分桶扫描,减少查询间 IO 影响 |
| 大吞吐查询场景 | 选择多列作为分桶键 | 数据分布更均匀;当查询条件不能完全匹配等值条件时,能提升整体吞吐 |
三、确定分桶数量
在 Doris 中,一个 Bucket 会被存储为一个物理文件(Tablet)。一个表的 Tablet 数量等于:
Tablet 总数 = partition_num(分区数) × bucket_num(分桶数)
一旦指定 Partition 的分桶数量,便不可更改。在确定分桶数量时,需预先考虑机器扩容情况。
自 2.0 版本起,Doris 支持根据机器资源和集群信息自动设置分区中的分桶数。可根据业务对预估精度的要求选择手动或自动方式。
1. 手动设置分桶数
通过 DISTRIBUTED 语句指定分桶数量:
-- Set hash bucket num to 8
DISTRIBUTED BY HASH(region) BUCKETS 8
-- Set random bucket num to 8
DISTRIBUTED BY RANDOM BUCKETS 8
决策原则
确定分桶数量时,遵循以下两个原则;当二者冲突时,优先考虑大小原则:
-
大小原则:每个 Tablet 的压缩后数据大小(不含索引)建议保持在 1 GB 到 20 GB 之间,Unique Key 表建议不超过 10 GB。
- Tablet 过小:聚合效果不佳,元数据管理压力增大;
- Tablet 过大:不利于副本迁移与补齐,Schema Change 失败重试代价升高;
- 可通过
SHOW TABLETS FROM your_table查看实际 Tablet 大小。
-
数量原则:在不考虑扩容的情况下,一个表的 Tablet 数量建议略多于整个集群的磁盘数量。
此外还需注意:
- 分桶数应设为 BE 数量的整数倍,以确保数据均匀分布;
- 单个分区的分桶数通常不应超过 128;如需更多,应优先考虑对表进行分区。
推荐配置示例
假设集群有 10 台 BE 机器,每台 BE 一块磁盘,可参考下表设置分桶数:
| 分区压缩后数据大小 | 建议分桶数量 |
|---|---|
| < 1 GB | 1 个分桶 |
| 1 - 10 GB | 10 个分桶 |
| 10 - 200 GB | 10 - 20 个分桶 |
| > 200 GB | 建议优先进行分区 |
表的数据量可以通过 SHOW DATA 命令查看,结果需除以副本数才是表的实际数据量。
2. 自动设置分桶数
自动推算分桶数功能会根据过去一段时间的分区大小,自动预测未来的分区大小,并据此确定分桶数量。
-- Set hash bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
-- Set random bucket auto
DISTRIBUTED BY RANDOM BUCKETS AUTO
properties("estimate_partition_size" = "20G")
estimate_partition_size 属性用于调整前期估算的分区大小:
- 该参数为可选设置,未指定时默认值为
10GB; - 该参数仅影响前期估算,与后续系统通过历史分区数据推算出的未来分区大小无关。
四、维护数据分桶
目前 Doris 仅支持修改新增分区的分桶数量,对于以下操作暂不支持:
- 不支持修改分桶类型;
- 不支持修改分桶键;
- 不支持修改已创建分桶的分桶数量。
在建表时,已通过 DISTRIBUTED 语句统一指定了每个分区的分桶数量。为了应对数据增长或减少的情况,在动态增加分区时,可单独指定新分区的分桶数量。
以下示例展示了如何通过 ALTER TABLE 命令修改新增分区的分桶数:
-- Modify hash bucket table
ALTER TABLE demo.hash_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY HASH(region) BUCKETS 16;
-- Modify random bucket table
ALTER TABLE demo.random_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY RANDOM BUCKETS 16;
-- Modify dynamic partition table
ALTER TABLE demo.dynamic_partition_tbl
SET ("dynamic_partition.buckets"="16");
修改分桶数量后,可以通过 SHOW PARTITION 命令查看修改结果。