向量搜索
Apache Doris 自 4.0 版本起原生支持 ANN(Approximate Nearest Neighbor,近似最近邻)向量搜索,基于 Faiss 实现 HNSW 与 IVF 索引,可在亿级向量数据上实现毫秒级 TopN 与范围检索。
适用场景
向量搜索是 RAG(Retrieval-Augmented Generation,检索增强生成)以及多模态检索的核心能力。其典型应用包括:
- RAG 检索:从大规模知识库中检索与用户查询最相关的 Top-K 文本片段,作为大模型生成的依据,缓解模型幻觉与知识时效性问题。
- 多模态检索:将图片、语音、视频等数据编码为向量,用于语义相似度查询。例如医学问答中检索病例资料与文献,辅助生成诊断建议。
- 推荐系统:基于范围搜索获取“相似但不重复”的候选内容,提升推荐多样性。
- 异常检测:定位远离正常模式的数据点。
向量检索的本质是:将查询与文档统一编码为语义向量后,从大规模向量集合中找出与查询最相似的 K 个向量。
快速导航
| 场景 | 跳转章节 |
|---|---|
| 了解如何创建向量索引 | 近似最近邻搜索 |
| 实现 Cosine 余弦相似度检索 | 使用 Cosine 相似度 |
| 基于距离阈值进行过滤 | 近似范围搜索 |
| 同时使用 TopN 与范围条件 | 组合搜索 |
| 在 ANN 检索前先用其他列过滤 | 带过滤条件的 ANN 搜索 |
| 调节查询行为参数 | 查询参数 |
| 节省内存与索引大小 | 向量量化 |
| 提升 QPS 与降低延迟 | 性能调优 |
| 使用 Python SDK 接入 | Python SDK |
| 了解使用限制 | 使用限制 |
近似最近邻搜索
Doris 不引入额外数据类型,向量以定长 Array<Float> 存储;针对距离检索提供基于 Faiss 的 ANN 索引类型。
建表示例
以常见的 SIFT 数据集为例:
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128",
"quantizer"="flat"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
各核心参数含义:
index_type:索引算法,可选hnsw(Hierarchical Navigable Small World 算法)、ivf(倒排文件索引)或ivf_on_disk(倒排列表落盘并通过缓存提供查询能力的 IVF)。metric_type:距离度量,l2_distance表示使用 L2 距离作为距离函数。dim:向量维度,128表示该列每条向量长度为 128。quantizer:编码方式,flat表示按原始 float32 存储各维度。
完整索引参数
| 参数 | 是否必填 | 支持/可选值 | 默认值 | 说明 |
|---|---|---|---|---|
index_type | 是 | hnsw、ivf、ivf_on_disk | (无) | 指定所使用的 ANN 索引算法。当前支持 HNSW、内存 IVF 和 IVF On-Disk。 |
metric_type | 是 | l2_distance、inner_product | (无) | 指定向量相似度/距离度量方式。L2 为欧氏距离;inner_product 可用于余弦相似度场景,但需先对向量进行归一化。 |
dim | 是 | 正整数 (> 0) | (无) | 指定向量维度,后续导入的所有向量维度必须与此一致,否则报错。 |
nlist | 否 | 正整数 | 1024 | IVF 的倒排桶数量。在 index_type=ivf 或 ivf_on_disk 时生效;取值越大通常有助于召回率/速度权衡,但会增加构建开销。 |
max_degree | 否 | 正整数 | 32 | HNSW 图中单个节点的最大邻居数(M),影响索引内存与搜索性能。 |
ef_construction | 否 | 正整数 | 40 | HNSW 构建阶段的候选队列大小(efConstruction),越大构图质量越好,但构建更慢。 |
quantizer | 否 | flat、sq8、sq4、pq | flat | 向量编码/量化方式:flat 为原始存储;sq8/sq4 为标量量化(8/4 bit);pq 为乘积量化。 |
pq_m | quantizer=pq 时必填 | 正整数 | (无) | 将原始高维向量分割成多少个子向量(dim 必须能被 pq_m 整除)。 |
pq_nbits | quantizer=pq 时必填 | 正整数 | (无) | 每个子向量量化的比特数,决定子空间码本大小(k = 2 ^ pq_nbits)。在 Faiss 中一般要求不大于 24。 |
数据导入
通过 S3 TVF 导入 SIFT 数据集:
INSERT INTO sift_1M
SELECT *
FROM S3(
"uri" = "https://selectdb-customers-tools-bj.oss-cn-beijing.aliyuncs.com/sift_database.tsv",
"format" = "csv");
select count(*) from sift_1M
--------------
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
查询示例
使用 l2_distance_approximate / inner_product_approximate 函数会触发 ANN 索引路径。
调用规则:
- 函数名必须与索引的
metric_type完全匹配:metric_type=l2_distance→ 使用l2_distance_approximatemetric_type=inner_product→ 使用inner_product_approximate
- 排序规则:
- L2 距离使用升序(
ORDER BY dist ASC,越小越近) - Inner Product 使用降序(
ORDER BY dist DESC,越大越近)
- L2 距离使用升序(
SELECT id,
l2_distance_approximate(
embedding,
[0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2]
) AS distance
FROM sift_1M
ORDER BY distance
LIMIT 10;
--------------
+--------+----------+
| id | distance |
+--------+----------+
| 178811 | 210.1595 |
| 177646 | 217.0161 |
| 181997 | 218.5406 |
| 181605 | 219.2989 |
| 821938 | 221.7228 |
| 807785 | 226.7135 |
| 716433 | 227.3148 |
| 358802 | 230.7314 |
| 803100 | 230.9112 |
| 866737 | 231.6441 |
+--------+----------+
10 rows in set (0.02 sec)
要与精确结果对比,可使用 l2_distance / inner_product(不带 _approximate 后缀)。在该示例中,精确搜索耗时约 290 毫秒;使用 ANN 索引后,查询延迟从约 290 毫秒降至约 20 毫秒。
10 rows in set (0.29 sec)
执行机制
ANN 索引以 segment 为粒度构建。在分布式表中:
- 每个 segment 返回其本地 TopN 结果。
- TopN 算子在 tablet 与 segment 之间合并结果,得到全局 TopN。
使用 Cosine 相似度
Doris 的 ANN 索引 metric_type 目前只支持 l2_distance 与 inner_product,不直接支持 cosine。当业务指标为余弦相似度时,可通过归一化将其等价转换为内积。
操作步骤
- 写入前:对向量做 L2 归一化(归一化到单位长度)。
- 建索引时:使用
metric_type="inner_product"。 - 查询时:使用
inner_product_approximate(...),并按ORDER BY ... DESC排序。
示例:
CREATE INDEX idx_emb_cosine ON your_table (embedding) USING ANN PROPERTIES (
"index_type"="hnsw",
"metric_type"="inner_product",
"dim"="768"
);
等价原理
- Cosine 相似度公式:
cos(x, y) = (x · y) / (||x|| ||y||) - 当向量已做 L2 归一化时(
||x|| = ||y|| = 1):cos(x, y) = x · y
因此,在单位向量空间里,最大化 cosine 相似度等价于最大化 inner product。如果不做归一化,inner product 与 cosine 不再等价。
近似范围搜索
除 TopN 最近邻搜索外,向量检索还有一类常见查询:基于距离阈值的范围搜索。该查询不返回固定数量,而是找出所有与目标向量距离满足条件的数据点。
典型应用:
- 推荐系统中获取“接近但不完全相同”的内容,增加多样性。
- 异常检测中定位远离正常模式的数据点。
示例:查找与目标向量 L2 距离大于 300 的数据数量:
SELECT count(*)
FROM sift_1M
WHERE l2_distance_approximate(
embedding,
[0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2])
> 300
--------------
+----------+
| count(*) |
+----------+
| 999271 |
+----------+
1 row in set (0.19 sec)
范围搜索同样通过 ANN 索引加速:系统先快速筛选候选向量集合,再计算精确的近似距离,从而显著降低开销。目前支持的范围条件:>、>=、<、<=。
组合搜索
组合搜索(Compound Search)指在同一条 SQL 中同时进行 ANN TopN 与 Range 条件过滤,返回满足范围约束的 TopN。
SELECT id,
l2_distance_approximate(
embedding, [0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2]) as dist
FROM sift_1M
WHERE l2_distance_approximate(
embedding, [0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2])
> 300
ORDER BY dist limit 10
--------------
+--------+----------+
| id | dist |
+--------+----------+
| 243590 | 300.005 |
| 549298 | 300.0317 |
| 429685 | 300.0533 |
| 690172 | 300.0916 |
| 123410 | 300.1333 |
| 232540 | 300.1649 |
| 547696 | 300.2066 |
| 855437 | 300.2782 |
| 589017 | 300.3048 |
| 930696 | 300.3381 |
+--------+----------+
10 rows in set (0.12 sec)
前过滤 vs 后过滤
| 策略 | 含义 | 优点 | 缺点 |
|---|---|---|---|
| 前过滤(Doris 采用) | 先做谓词过滤,再在剩余集合上取 TopN | 召回率高 | 速度相对较慢 |
| 后过滤 | 先做 TopN,再过滤 | 速度快 | 可能显著降低召回 |
在 Doris 中,组合搜索的两个阶段均可通过索引加速。但在某些场景(如第一阶段 Range 过滤率极高)双阶段同时使用索引可能导致召回下降。Doris 会根据谓词过滤率与索引类型综合决策,自适应判断是否对两阶段均使用索引。
带过滤条件的 ANN 搜索
带过滤条件的 ANN 搜索指:在执行 ANN TopN 之前先应用其他谓词过滤,返回满足条件的 TopN。
下面用一个 8 维示例说明混合搜索流程:
CREATE TABLE ann_with_fulltext (
id int NOT NULL,
embedding array<float> NOT NULL,
comment String NOT NULL,
value int NULL,
INDEX idx_comment(`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment',
INDEX ann_embedding(`embedding`) USING ANN PROPERTIES("index_type"="hnsw","metric_type"="l2_distance","dim"="8")
) DUPLICATE KEY (`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES("replication_num"="1");
INSERT INTO ann_with_fulltext VALUES
(1, [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8], 'this is about music', 10),
(2, [0.2,0.1,0.5,0.3,0.9,0.4,0.7,0.1], 'sports news today', 20),
(3, [0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2], 'latest music trend', 30),
(4, [0.05,0.06,0.07,0.08,0.09,0.1,0.2,0.3], 'politics update',40)
假设用户输入查询向量 [0.1,0.1,0.2,0.2,0.3,0.3,0.4,0.4],只在 comment 含 “music” 的文档中检索最相似的前 2 条:
SELECT id, comment,
l2_distance_approximate(embedding, [0.1,0.1,0.2,0.2,0.3,0.3,0.4,0.4]) AS dist
FROM ann_with_fulltext
WHERE comment MATCH_ANY 'music' -- 先用倒排索引过滤
ORDER BY dist ASC -- 在过滤后的结果集上做 ANN TopN
LIMIT 2;
+------+---------------------+----------+
| id | comment | dist |
+------+---------------------+----------+
| 1 | this is about music | 0.663325 |
| 3 | latest music trend | 1.280625 |
+------+---------------------+----------+
2 rows in set (0.04 sec)
带过滤条件的 ANN 搜索若希望利用向量索引加速 TopN,必须确保涉及的过滤列具备倒排等二级索引。
查询参数
除了在构建 HNSW 索引时可指定参数外,查询阶段也可通过会话变量调节行为:
| 会话变量 | 默认值 | 说明 |
|---|---|---|
hnsw_ef_search | 32 | HNSW 索引的 EF 搜索参数。控制搜索阶段 candidates 队列的最大长度,越大精度越高、耗时越高。 |
hnsw_check_relative_distance | true | 是否启用相对距离检查机制,以提升 HNSW 搜索的准确性。 |
hnsw_bounded_queue | true | 是否使用有界优先队列以优化 HNSW 的搜索性能。 |
向量量化
采用 FLAT 编码时,HNSW 索引(原始向量 + 图结构)可能占用大量内存。HNSW 必须全量驻留内存才能工作,因此在超大规模数据集上易成瓶颈。
Doris 提供两类量化方案:
| 量化方式 | 原理 | Doris 支持 |
|---|---|---|
| 标量量化 SQ(Scalar Quantization) | 压缩 FLOAT32 单维数值,减少内存开销 | sq8(INT8)、sq4(INT4) |
| 乘积量化 PQ(Product Quantization) | 分解高维向量并分别量化子向量 | pq |
标量量化(SQ)示例
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128",
"quantizer"="sq8" -- 指定使用 INT8 进行量化
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
在 768 维的 Cohere-MEDIUM-1M 与 Cohere-LARGE-10M 数据集测试中,SQ8 可将索引大小压缩至 FLAT 的约 1/3。
量化效果对比
| 数据集 | 向量维度 | 存储/索引方案 | 总磁盘占用 | 数据部分 | 索引部分 | 备注 |
|---|---|---|---|---|---|---|
| Cohere-MEDIUM-1M | 768D | Doris (FLAT) | 5.647 GB (2.533 + 3.114) | 2.533 GB | 3.114 GB | 1M 向量,原始 + HNSW FLAT 索引 |
| Cohere-MEDIUM-1M | 768D | Doris SQ INT8 | 3.501 GB (2.533 + 0.992) | 2.533 GB | 0.992 GB | INT8 对称量化 |
| Cohere-MEDIUM-1M | 768D | Doris PQ (pq_m=384, pq_nbits=8) | 3.149 GB (2.535 + 0.614) | 2.535 GB | 0.614 GB | 乘积量化 |
| Cohere-LARGE-10M | 768D | Doris (FLAT) | 56.472 GB (25.328 + 31.145) | 25.328 GB | 31.145 GB | 10M 向量 |
| Cohere-LARGE-10M | 768D | Doris SQ INT8 | 35.016 GB (25.329 + 9.687) | 25.329 GB | 9.687 GB | INT8 量化,索引显著减小 |
乘积量化(PQ)
Doris 也支持乘积量化,但使用 PQ 时需要提供额外参数:
pq_m:表示将原始的高维向量分割成多少个子向量(向量维度dim必须能被pq_m整除)。pq_nbits:表示每个子向量量化的比特数,决定子空间码本的大小,在 Faiss 中一般要求不大于 24。
PQ 量化在训练阶段对训练数据量有要求:至少需要与每一个聚类中心数量一样多,即训练点个数 n >= 2 ^ pq_nbits。
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="128",
"quantizer"="pq", -- 指定使用 PQ 进行量化
"pq_m"="2", -- 使用 PQ 时需要指定,表示将高维向量分割成 pq_m 个低维子向量
"pq_nbits"="2" -- 使用 PQ 时需要指定,表示每个子空间码本的比特数
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
量化的代价
量化会带来额外构建开销:构建阶段需要大量距离计算,且每次计算需对量化值解码。以 128 维向量为例,随着行数增长构建时间上升,SQ 相比 FLAT 可能引入约 10 倍构建成本。
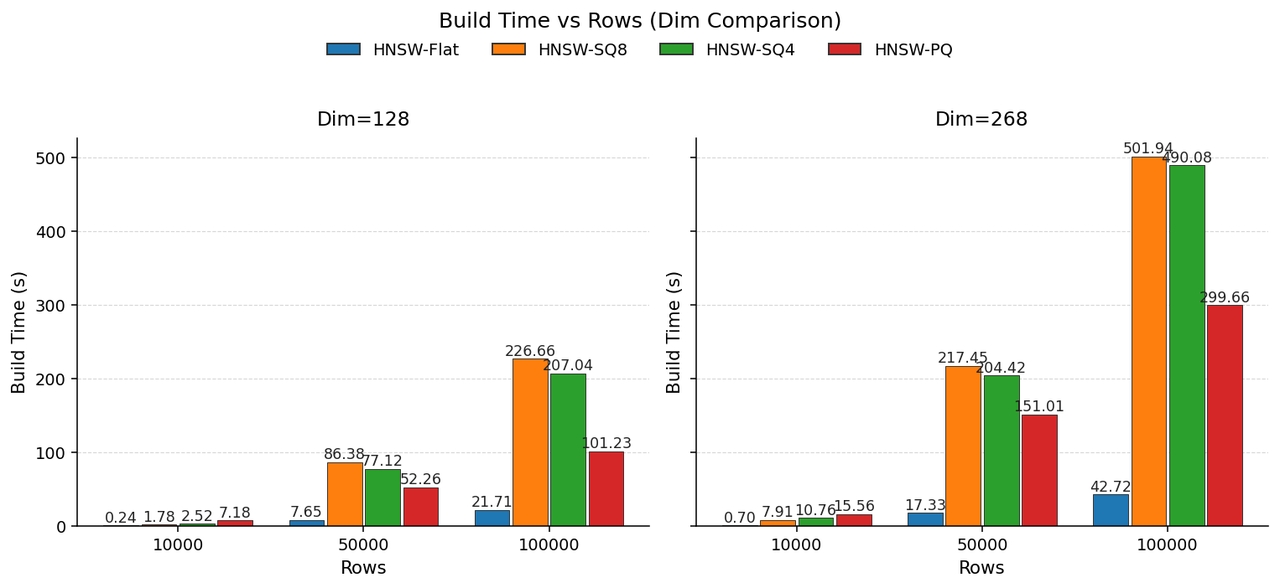
性能调优
向量搜索是典型的二级索引点查场景。若对 QPS 与延迟要求较高,可参考以下建议。经调优,在 FE 32C 64GB + BE 32C 64GB 机器上,Doris 可达到 3000+ QPS(数据集:Cohere-MEDIUM-1M)。
查询性能基准
| 并发 | 方案 | QPS | 平均延迟 (s) | P99 延迟 (s) | CPU 使用率 | 召回率 |
|---|---|---|---|---|---|---|
| 240 | Doris | 3340.4399 | 0.071368168 | 0.163399825 | 40% | 91.00% |
| 240 | Doris SQ INT8 | 3188.6359 | 0.074728852 | 0.160370195 | 40% | 88.26% |
| 240 | Doris SQ INT4 | 2818.2291 | 0.084663868 | 0.174826815 | 43% | 80.38% |
| 240 | Doris 暴力计算 | 3.6787 | 25.554878826 | 29.363227973 | 100% | 100.00% |
| 480 | Doris | 4155.7220 | 0.113387271 | 0.261086075 | 60% | 91.00% |
| 480 | Doris SQ INT8 | 3833.1130 | 0.123040214 | 0.276912867 | 50% | 88.26% |
| 480 | Doris SQ INT4 | 3431.0538 | 0.137636995 | 0.281631249 | 57% | 80.38% |
| 480 | Doris 暴力计算 | 3.6787 | 25.554878826 | 29.363227973 | 100% | 100.00% |
使用 Prepared Statement
常见 embedding 模型输出通常为 768 维或更高。若将该向量作为字面量直接写入 SQL,解析耗时可能超过实际执行时间,因此建议使用 Prepared Statement。当前 Doris 不支持通过 mysql client 直接执行相关命令,需要通过 JDBC 调用。
-
在 jdbc url 里面开启服务端 prepared statement
url = jdbc:mysql://127.0.0.1:9030/demo?useServerPrepStmts=true -
使用 prepared statement
// use `?` for placement holders, readStatement should be reused
PreparedStatement readStatement = conn.prepareStatement("SELECT id, l2_distance_approximate(embedding, cast (? as ARRAY<FLOAT>)) AS distance
FROM sift_1M
ORDER BY distance
LIMIT 10");
...
readStatement.setString("[0,11,77,24,3,0,0,0,28,70,125,8,0,0,0,0,44,35,50,45,9,0,0,0,4,0,4,56,18,0,3,9,16,17,59,10,10,8,57,57,100,105,125,41,1,0,6,92,8,14,73,125,29,7,0,5,0,0,8,124,66,6,3,1,63,5,0,1,49,32,17,35,125,21,0,3,2,12,6,109,21,0,0,35,74,125,14,23,0,0,6,50,25,70,64,7,59,18,7,16,22,5,0,1,125,23,1,0,7,30,14,32,4,0,2,2,59,125,19,4,0,0,2,1,6,53,33,2]");
ResultSet resultSet = readStatement.executeQuery();
减少 segment 数量
Doris 的 ANN 索引建立在 segment 上,segment 过多会引入额外开销。
- 建议:带 ANN 索引的表,每个 tablet 下 segment 数不应超过 5 个。
- 方法:调整
be.conf中的write_buffer_size与vertical_compaction_max_segment_size,增大单 segment 大小以减少数量;建议两者设置为10737418240(10 GB)。
减少 rowset 数量
每次导入都会生成一个 rowset,过多 rowset 同样会增加调度开销。建议使用 Stream Load 或 INSERT INTO SELECT 做批量导入。
ANN 索引常驻内存
当前 ANN 索引算法基于内存。若查询到的 segment 索引未驻留内存,会触发磁盘 I/O。为性能考虑建议常驻:在 be.conf 中设置:
enable_segment_cache_prune=false
parallel_pipeline_task_num = 1
ANN TopN 查询返回行数很少,无需高并行度,建议:
SET parallel_pipeline_task_num = 1;
enable_profile = false
若对延迟极其敏感,建议关闭 query profile:
SET enable_profile = false;
Python SDK
在 AI 时代,Python 已成为数据处理与智能应用开发的主流语言。为了让开发者更方便地在 Python 环境中使用 Doris 的向量搜索能力,社区贡献了 Python SDK:
- doris_vector_search:针对向量距离检索做了性能优化,是目前性能较好的 Doris vector search Python SDK。
使用限制
使用 Doris 向量索引时,需要注意以下限制:
-
数据类型限制:ANN Index 对应的列必须是
NOT NULLABLE的Array<Float>。导入时需确保该列每个向量的长度均等于索引属性中指定的维度(dim),否则会报错。 -
表模型限制:ANN Index 只能在 DuplicateKey 表模型上使用。
-
谓词列必须有二级索引:Doris 使用前过滤语义(谓词计算在 AnnTopN 之前)。当 SQL 中的谓词涉及到的列没有二级索引时,为保证结果正确性,Doris 会回退到暴力计算。例如:
SELECT id, l2_distance_approximate(embedding, [xxx]) AS distance
FROM sift_1M
WHERE round(id) > 100
ORDER BY distance limit 10;虽然
id是主键,但未在该列上构建倒排等可精确定位行号的二级索引,此类谓词在索引分析之后执行。为保证 ANN TopN 的前过滤语义,系统会回退为暴力计算。 -
距离函数与 metric 类型必须匹配:如果 SQL 中指定的距离函数与 DDL 中索引的
metric_type不匹配,那么 Doris 无法通过 ANN 索引进行 TopN 计算(即使你使用的是l2_distance_approximate/inner_product_approximate)。 -
inner_product 必须使用 DESC 排序:如果
metric_type是inner_product,那么只有ORDER BY inner_product_approximate() DESC LIMIT N(DESC不能省略)才能通过 ANN 索引加速。 -
函数参数顺序:
xxx_approximate()函数的第一个参数为ColumnArray,第二个参数为CAST或ArrayLiteral时,才能触发索引分析;交换位置会回退暴力搜索。
FAQ
Q1:Doris 的 ANN 索引支持哪些距离度量?
目前支持 l2_distance(欧氏距离)和 inner_product(内积)。如需 Cosine 相似度,请参考使用 Cosine 相似度章节。
Q2:为什么我的 ANN 查询没有走索引?
可能原因:
- 距离函数与
metric_type不匹配。 - 使用
inner_product时未使用ORDER BY ... DESC。 - 函数参数顺序颠倒(
ColumnArray必须为第一个参数)。 - 涉及的过滤列缺少倒排等二级索引,触发了暴力计算回退。
Q3:如何选择 HNSW、IVF、IVF On-Disk?
| 索引 | 内存占用 | 查询性能 | 适用场景 |
|---|---|---|---|
| HNSW | 高(必须全量驻留内存) | 高 | 中小规模、低延迟要求高 |
| IVF | 中 | 中 | 大规模数据 |
| IVF On-Disk | 低(落盘 + 缓存) | 中 | 超大规模数据、内存受限 |
Q4:内存不够用怎么办?
可以通过量化降低内存占用:
- 优先尝试
sq8(INT8 标量量化),通常可将索引压缩至原来的 1/3,召回率影响较小。 - 内存非常紧张时可使用
sq4或pq,但召回率会有一定下降。
Q5:如何在向量检索中结合关键字过滤?
为过滤列建立倒排索引,再使用带 WHERE 子句的 ANN 查询。详见带过滤条件的 ANN 搜索。
Q6:如何提升 QPS?
参考性能调优章节,重点:
- 使用 Prepared Statement 避免 SQL 解析开销。
- 减少 segment 与 rowset 数量。
- 设置 ANN 索引常驻内存。
parallel_pipeline_task_num = 1。- 关闭 query profile。