算子落盘
概述
Doris 的计算层是一个 MPP 的架构,所有的计算任务都是在 BE 的内存中完成的,各个 BE 之间也是通过内存来完成数据交换,所以内存管理对查询的稳定性有至关重要的影响,从线上查询统计看,有一大部分的查询报错也是跟内存相关。当前越来越多的用户将 ETL 数据加工,多表物化视图处理,复杂的 AdHoc 查询等任务迁移到 Doris 上运行,所以,需要将中间操作结果卸载到磁盘上,使那些所需内存量超出每个查询或每个节点限制的查询能够得以执行。具体来说,当处理大型数据集或执行复杂查询时,内存消耗可能会迅速增加,超出单个节点或整个查询处理过程中可用的内存限制。Doris 通过将其中的中间结果(如聚合的中间状态、排序的临时数据等)写入磁盘,而不是完全依赖内存来存储这些数据,从而缓解了内存压力。这样做有几个好处:
- 扩展性:允许 Doris 处理比单个节点内存限制大得多的数据集。
- 稳定性:减少因内存不足导致的查询失败或系统崩溃的风险。
- 灵活性:使得用户能够在不增加硬件资源的情况下,执行更复杂的查询。
为了避免申请内存时触发 OOM,Doris 引入了 reserve memory 机制,这个机制的工作流程如下:
- Doris 在执行过程中,会预估每次处理一个 Block 需要的内存大小,然后到一个统一的内存管理器中去申请;
- 全局的内存分配器会判断当前内存申请,是否超过了 Query 的内存限制或者超过了整个进程的内存限制,如果超过了,那么就返回失败;
- Doris 在收到失败消息时,会将当前 Query 挂起,然后选择最大的算子进行落盘,等到落盘结束后,Query 再继续执行。
目前支持落盘的算子有:
- Hash Join 算子
- 聚合算子
- 排序算子
- CTE
当查询触发落盘时,由于会有额外的硬盘读写操作,查询时间可能会显著增长,建议调大 FE Session 变量 query_timeout。同时落盘会有比较大的磁盘 IO,建议单独配置一个磁盘目录或者使用 SSD 磁盘降低查询落盘对正常的导入或者查询的影响。目前查询落盘功能默认关闭。
内存管理机制
Doris 的内存管理分为三个级别:进程级别、WorkloadGroup 级别、Query 级别。
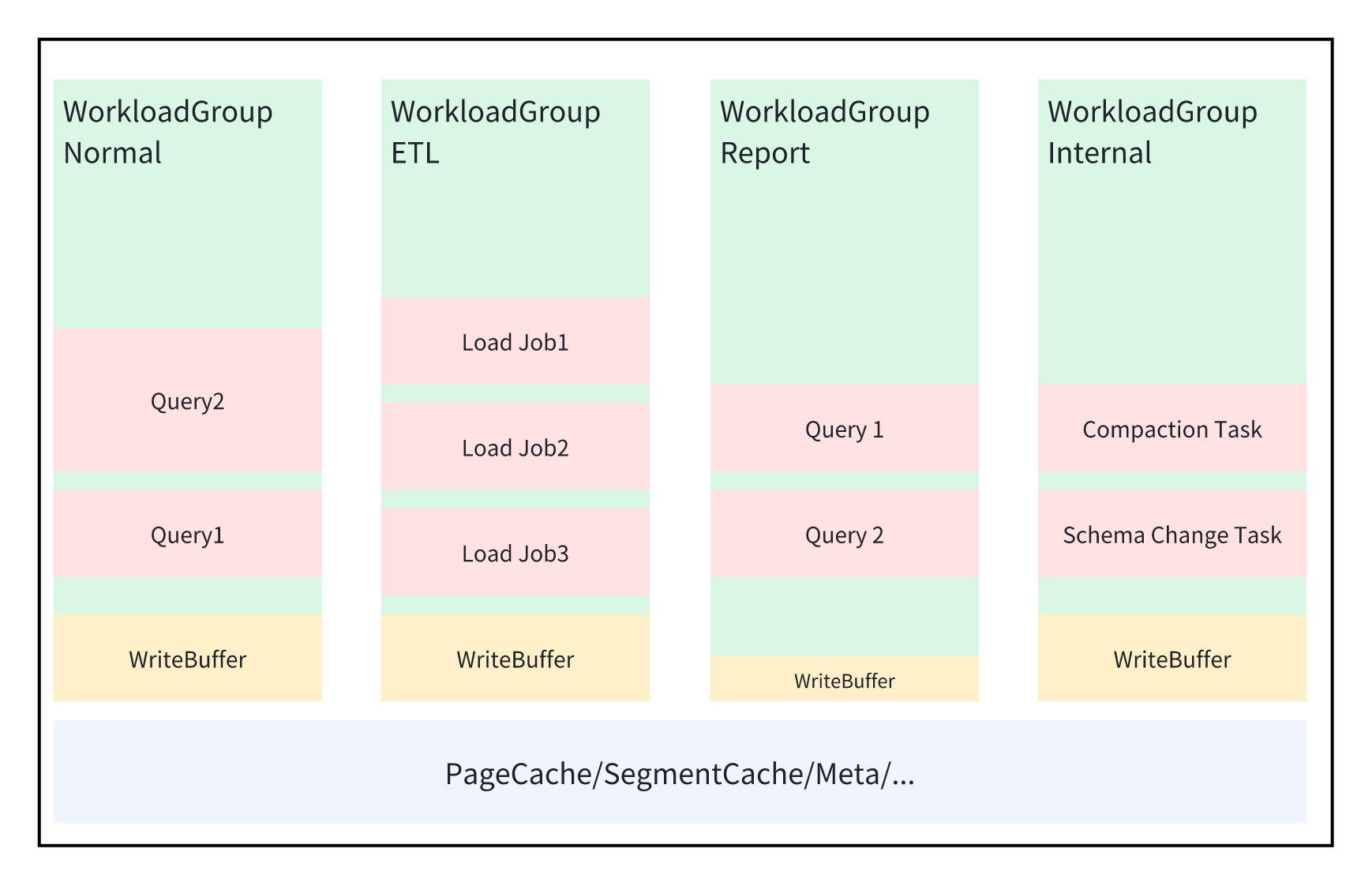
BE 进程内存配置
整个 BE 进程的内存由 be.conf 中的参数 mem_limit 控制,一旦 Doris 使用的内存超过这个阈值,Doris 就会把当前正在申请内存的 Query 取消,同时后台也会有一个定时任务,异步的 Kill 一部分 Query 来释放内存 或者 释放一些 Cache。所以 Doris 内部的各种管理操作(比如 spill disk,flush memtable 等)需要在快接近这个阈值的时候,就需要运行,尽可能的避免内存达到这个阈值,一旦到达这个阈值,为了避免整个进程 OOM,Doris 会采取一些非常暴力的自我保护措施。 当 Doris 的 BE 跟其他的进程混部(比如 Doris FE、Kafka、HDFS)的时候,会导致 Doris BE 实际可用的内存远小于用户设置的 mem_limit 导致内部的释放内存机制失效,然后导致 Doris 进程被操作系统的 OOM Killer 杀死。 当 Doris 进程部署在 K8S 里或者用 Cgroup 管理的时候,Doris 会自动感知容器的内存配置。
Workload Group 内存配置
- memory_limit,默认是 30%。表示当前 Workload Group 分配的内存占整个进程内存的百分比。
- enable_memory_overcommit,默认是 true。表示当前 Workload Group 的内存限制,是硬限还是软限。当这个值为 true 时,表示这个 Workload Group 内所有的任务使用的内存的大小可以超过 memory_limit 的限制。但是当整个进程的内存不足时,为了保证能够快速的回收内存,BE 会优先从那些超过自身限制的 Workload Group 中挑选 Query 去 cancel,此时并不会等待 Spill Disk。当用户不知道如何给多个 Workload Group 设置多少内存时,这种方式是一个比较易用的配置策略。
- write_buffer_ratio,默认是 20%。表示当前 Workload Group 内 write buffer 的大小。Doris 为了加快导入速度,数据首先会在内存里攒批(也就是构建 Memtable),然后到一定大小的时候,再整体排序,然后写入硬盘。但是如果内存里积攒太多的 Memtable 又会影响正常 Query 可用的内存,导致 Query 被 Cancel。所以 Doris 在每个 Workload Group 内都单独划分了一个 write buffer。对于写入比较大的 Workload Group,可以设置比较大的 write buffer,可以有效的提升写入的吞吐;对于查询比较多的 Workload Group 可以调小这个值。
- low watermark: 默认是 75%。
- high watermark:默认是 90%.
Query 内存管理
静态内存分配
Query 运行的内存受以下 2 个参数控制:
- exec_mem_limit,表示一个 query 最大可以使用的内存,默认值 2G;
- enable_mem_overcommit,默认是 true。表示一个 query 使用的内存是否可以超过 exec_mem_limit 的限制,默认值是 true,表示是可以超过这个限制的,此时当进程内存不足的时候,会去杀死那些超过内存限制的 query;false 表示 query 使用的内存不能超过这个限制,当超过的时候,会根据用户的设置选择落盘或者 kill。 这两个参数是 query 运行之前用户就需要在 session variable 里设置好,运行期间不能够动态修改。
基于 Slot 的内存分配
静态内存分配方式,在使用过程中我们发现,很多时候用户不知道一个 query 应该分配多少内存,所以经常把 exec_mem_limit 设置为整个 BE 进程内存的一半,也就是整个 BE 内所有的 query 使用的内存都不允许超过整个进程内存的一半,这个功能在这种场景下实际变成了一个类似熔断的功能。当我们要根据内存的大小做一些更精细的策略控制,比如 spill disk 时,由于这个值太大了,所以不能依赖它来做一些控制。 所以我们基于 Workload Group 实现了一个新的基于 slot 的内存限制方式,这个策略的原理如下:
- 每个 Workload Group 用户都配置了 2 个参数,memory_limit 和 max_concurrency,那么就认为整个 be 的内存被划分为 max_concurrency 个 slot,每个 slot 占用的内存是 memory_limit / max_concurrency。
- 默认情况下,每个 query 运行占用 1 个 slot,如果用户想让一个 query 使用更多的内存,那么就需要修改 query_slot_count 的值。
- 由于 Workload Group 的 slot 的总数是固定的,假如用户调大 query_slot_count,相当于每个 query 占用了更多的 slot,那么整个 Workload Group 可同时运行的 query 的数量就动态减少了,新来的 query 就自动排队。
Workload Group 的 slot_memory_policy,这个参数可以有 3 个可选的值:
- disabled,默认值,表示不启用,使用静态内存分配方式;
- fixed,每个 query 可以使用的的内存 = Workload Group 的 mem_limit * query_slot_count/ max_concurrency.
- dynamic,每个 query 可以使用的的内存 = Workload Group 的 mem_limit * query_slot_count/ sum(running query slots),它主要是克服了 fixed 模式下,会存在有一些 slot 没有使用的情况。 fixed 或者 dynamic 都是设置的 query 的硬限,一旦超过,就会落盘或者 kill;而且会覆盖用户设置的静态内存分配的参数。所以当要设置 slot_memory_policy 时,一定要设置好 Workload Group 的 max_concurrency,否则会出现内存不足的问题。
落盘
开启查询中间结果落盘
BE 配置项
spill_storage_root_path=/mnt/disk1/spilltest/doris/be/storage;/mnt/disk2/doris-spill;/mnt/disk3/doris-spill
spill_storage_limit=100%
- spill_storage_root_path:查询中间结果落盘文件存储路径,默认和 storage_root_path 一样。
- spill_storage_limit: 落盘文件占用磁盘空间限制。可以配置具体的空间大小(比如 100G, 1T)或者百分比,默认是 20%。如果 spill_storage_root_path 配置单独的磁盘,可以设置为 100%。这个参数主要是防止落盘占用太多的磁盘空间,导致无法进行正常的数据存储。 修改配置项之后,需要重启 BE 才能生效。
FE Session Variable
set enable_spill=true;
set exec_mem_limit = 10g
set enable_mem_overcommit = false
- enable_spill 表示一个 query 是否开启落盘;
- exec_mem_limit 表示一个 query 使用的最大的内存大小;
- enable_mem_overcommit query 是否可以使用超过 exec_mem_limit 大小的内存限制
Workload Group
默认 Workload Group 的 memory_limit 默认是 30%,可按实际的 Workload Group 的数量合理修改。如果只有一个 Workload Group,可以调整为 90%。
alter Workload Group normal properties ( 'memory_limit'='90%' );
监测落盘
审计日志
FE Audit Log 中增加了 SpillWriteBytesToLocalStorage 和 SpillReadBytesFromLocalStorage 字段,分别表示落盘时写盘和读盘数据总量。
SpillWriteBytesToLocalStorage=503412182|SpillReadBytesFromLocalStorage=503412182
Profile
如果查询过程中触发了落盘,在 Query Profile 中增加了 Spill 前缀的一些 Counter 进行标记和落盘相关 counter。以 HashJoin 时 Build HashTable 为例,可以看到下面的 Counter:
PARTITIONED_HASH_JOIN_SINK_OPERATOR (id=4 , nereids_id=179):(ExecTime: 6sec351ms)
- Spilled: true
- CloseTime: 528ns
- ExecTime: 6sec351ms
- InitTime: 5.751us
- InputRows: 6.001215M (6001215)
- MemoryUsage: 0.00
- MemoryUsagePeak: 554.42 MB
- MemoryUsageReserved: 1024.00 KB
- OpenTime: 2.267ms
- PendingFinishDependency: 0ns
- SpillBuildTime: 2sec437ms
- SpillInMemRow: 0
- SpillMaxRowsOfPartition: 68.569K (68569)
- SpillMinRowsOfPartition: 67.455K (67455)
- SpillPartitionShuffleTime: 836.302ms
- SpillPartitionTime: 131.839ms
- SpillTotalTime: 5sec563ms
- SpillWriteBlockBytes: 714.13 MB
- SpillWriteBlockCount: 1.344K (1344)
- SpillWriteFileBytes: 244.40 MB
- SpillWriteFileTime: 350.754ms
- SpillWriteFileTotalCount: 32
- SpillWriteRows: 6.001215M (6001215)
- SpillWriteSerializeBlockTime: 4sec378ms
- SpillWriteTaskCount: 417
- SpillWriteTaskWaitInQueueCount: 0
- SpillWriteTaskWaitInQueueTime: 8.731ms
- SpillWriteTime: 5sec549ms
系统表
backend_active_tasks
增加了 SPILL_WRITE_BYTES_TO_LOCAL_STORAGE 和 SPILL_READ_BYTES_FROM_LOCAL_STORAGE 字段,分别表示一个查询目前落盘中间结果写盘数据和读盘数据总量。
mysql [information_schema]>select * from backend_active_tasks;
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| BE_ID | FE_HOST | WORKLOAD_GROUP_ID | QUERY_ID | TASK_TIME_MS | TASK_CPU_TIME_MS | SCAN_ROWS | SCAN_BYTES | BE_PEAK_MEMORY_BYTES | CURRENT_USED_MEMORY_BYTES | SHUFFLE_SEND_BYTES | SHUFFLE_SEND_ROWS | QUERY_TYPE | SPILL_WRITE_BYTES_TO_LOCAL_STORAGE | SPILL_READ_BYTES_FROM_LOCAL_STORAGE |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| 10009 | 10.16.10.8 | 1 | 6f08c74afbd44fff-9af951270933842d | 13612 | 11025 | 12002430 | 1960955904 | 733243057 | 70113260 | 0 | 0 | SELECT | 508110119 | 26383070 |
| 10009 | 10.16.10.8 | 1 | 871d643b87bf447b-865eb799403bec96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | SELECT | 0 | 0 |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
2 rows in set (0.00 sec)
workload_group_resource_usage
增加了 WRITE_BUFFER_USAGE_BYTES 字段,表示 Workload Group 中的导入任务 Memtable 内存占用。
mysql [information_schema]>select * from workload_group_resource_usage;
+-------+-------------------+--------------------+-------------------+-----------------------------+------------------------------+--------------------------+
| BE_ID | WORKLOAD_GROUP_ID | MEMORY_USAGE_BYTES | CPU_USAGE_PERCENT | LOCAL_SCAN_BYTES_PER_SECOND | REMOTE_SCAN_BYTES_PER_SECOND | WRITE_BUFFER_USAGE_BYTES |
+-------+-------------------+--------------------+-------------------+-----------------------------+------------------------------+--------------------------+
| 10009 | 1 | 102314948 | 0.69 | 0 | 0 | 23404836 |
+-------+-------------------+--------------------+-------------------+-----------------------------+------------------------------+--------------------------+
1 row in set (0.01 sec)
测试
测试环境
机器配置
测试使用阿里云服务器,具体配置如下。
1FE:
16核(vCPU) 32 GiB 200 Mbps ecs.c6.4xlarge
3BE:
16核(vCPU) 64 GiB 0 Mbps ecs.g6.4xlarge
测试数据
测试数据使用 TPC-DS 10TB 作为数据输入,使用阿里云 DLF 数据源,使用 Catalog 的方式挂载到 Doris 内,SQL 语句如下:
CREATE CATALOG dlf PROPERTIES (
"type"="hms",
"hive.metastore.type" = "dlf",
"dlf.proxy.mode" = "DLF_ONLY",
"dlf.endpoint" = "dlf-vpc.cn-beijing.aliyuncs.com",
"dlf.region" = "cn-beijing",
"dlf.uid" = "217316283625971977",
"dlf.catalog.id" = "emr_dev",
"dlf.access_key" = "按情况填写",
"dlf.secret_key" = "按情况填写"
);
参考官网链接:https://doris.apache.org/zh-CN/docs/dev/benchmark/tpcds
测试结果
数据的规模是 10TB。内存和数据规模的比例是 1:52,整体运行时间 32000s,能够跑出所有的 99 条 query。未来我们将对更多的算子提供落盘能力(如 window function,Intersect 等),同时继续优化落盘情况下的性能,降低对磁盘的消耗,提升查询的稳定性。
| query | Time(ms) |
|---|---|
| query1 | 25590 |
| query2 | 126445 |
| query3 | 103859 |
| query4 | 1174702 |
| query5 | 266281 |
| query6 | 62950 |
| query7 | 212745 |
| query8 | 67000 |
| query9 | 602291 |
| query10 | 70904 |
| query11 | 544436 |
| query12 | 25759 |
| query13 | 229144 |
| query14 | 1120895 |
| query15 | 29409 |
| query16 | 117287 |
| query17 | 260122 |
| query18 | 97453 |
| query19 | 127384 |
| query20 | 32749 |
| query21 | 4471 |
| query22 | 10162 |
| query23 | 1772561 |
| query24 | 535506 |
| query25 | 272458 |
| query26 | 83342 |
| query27 | 175264 |
| query28 | 887007 |
| query29 | 427229 |
| query30 | 13661 |
| query31 | 108778 |
| query32 | 37303 |
| query33 | 181351 |
| query34 | 84159 |
| query35 | 81701 |
| query36 | 152990 |
| query37 | 36815 |
| query38 | 172531 |
| query39 | 20155 |
| query40 | 75749 |
| query41 | 527 |
| query42 | 95910 |
| query43 | 66821 |
| query44 | 209947 |
| query45 | 26946 |
| query46 | 131490 |
| query47 | 158011 |
| query48 | 149482 |
| query49 | 303515 |
| query50 | 298089 |
| query51 | 156487 |
| query52 | 97440 |
| query53 | 98258 |
| query54 | 202583 |
| query55 | 93268 |
| query56 | 185255 |
| query57 | 80308 |
| query58 | 252746 |
| query59 | 171545 |
| query60 | 202915 |
| query61 | 272184 |
| query62 | 38749 |
| query63 | 94327 |
| query64 | 247074 |
| query65 | 270705 |
| query66 | 101465 |
| query67 | 3744186 |
| query68 | 151543 |
| query69 | 15559 |
| query70 | 132505 |
| query71 | 180079 |
| query72 | 3085373 |
| query73 | 82623 |
| query74 | 330087 |
| query75 | 830993 |
| query76 | 188805 |
| query77 | 239730 |
| query78 | 1895765 |
| query79 | 144829 |
| query80 | 463652 |
| query81 | 15319 |
| query82 | 76961 |
| query83 | 32437 |
| query84 | 22849 |
| query85 | 58186 |
| query86 | 33933 |
| query87 | 185421 |
| query88 | 434867 |
| query89 | 108265 |
| query90 | 31131 |
| query91 | 18864 |
| query92 | 24510 |
| query93 | 281904 |
| query94 | 67761 |
| query95 | 3738968 |
| query96 | 47245 |
| query97 | 536702 |
| query98 | 97800 |
| query99 | 62210 |
| sum | 31797707 |
