监控和报警
本文档介绍如何为 Apache Doris 集群搭建一套完整的监控体系:通过 Prometheus 采集 FE / BE 暴露的监控指标,使用 Grafana 加载官方 Dashboard 模板进行可视化展示,并预留 Alertmanager 配置入口用于后续告警接入。
注:如果你在 Kubernetes 上部署 Doris 存算分离集群,监控搭建请参考 在 Kubernetes 上部署 Prometheus 和 Grafana;本文中的监控架构、指标格式与 Dashboard 面板说明同样适用。
适用场景
| 场景 | 说明 |
|---|---|
| 集群部署后接入监控 | Doris 集群已部署完成,需要采集 FE / BE 的运行指标并以图表方式展示 |
| 多集群统一观测 | 在同一套 Prometheus + Grafana 中同时监控多个 Doris 集群 |
| 故障排查与性能调优 | 通过 JVM、查询、Backend 任务等 Dashboard 快速定位异常节点和瓶颈 |
| 配置报警(规划中) | 后续基于 Prometheus + Alertmanager 配置邮件 / 短信等报警通道 |
前置条件
- Doris 集群已完成部署,FE 与 BE 进程运行正常。
- 可访问 FE 的 HTTP 端口(默认
8030)和 BE 的 Web Server 端口(默认8040)。 - 一台用于运行 Prometheus 与 Grafana 的服务器,可与所有 FE / BE 节点网络互通。
- 具备外网访问能力,能够从 Prometheus 与 Grafana 官网下载安装包以及 Dashboard 模板。
Dashboard 模板下载
Doris 提供两套 Grafana Dashboard 模板,按集群的存储模式选择对应模板,可直接导入使用。模板会不定期更新,更新方式见 Dashboard 更新。
| 存储模式 | Dashboard 模板 | 说明 |
|---|---|---|
| 存算一体(shared-nothing) | doris-grafana-dashboard.json | 传统 FE / BE 部署,本地存储;面板覆盖 FE、BE 两类组件 |
| 存算分离(compute-storage decoupled) | doris-grafana-dashboard-cloud.json | 面板覆盖 FE、BE / Compute Group、Meta Service 三类组件;适用于 Kubernetes 与非 Kubernetes 部署的存算分离集群 |
欢迎社区贡献更优的 Dashboard。
监控架构总览
Doris 使用 Prometheus 和 Grafana 进行监控数据的采集与展示。
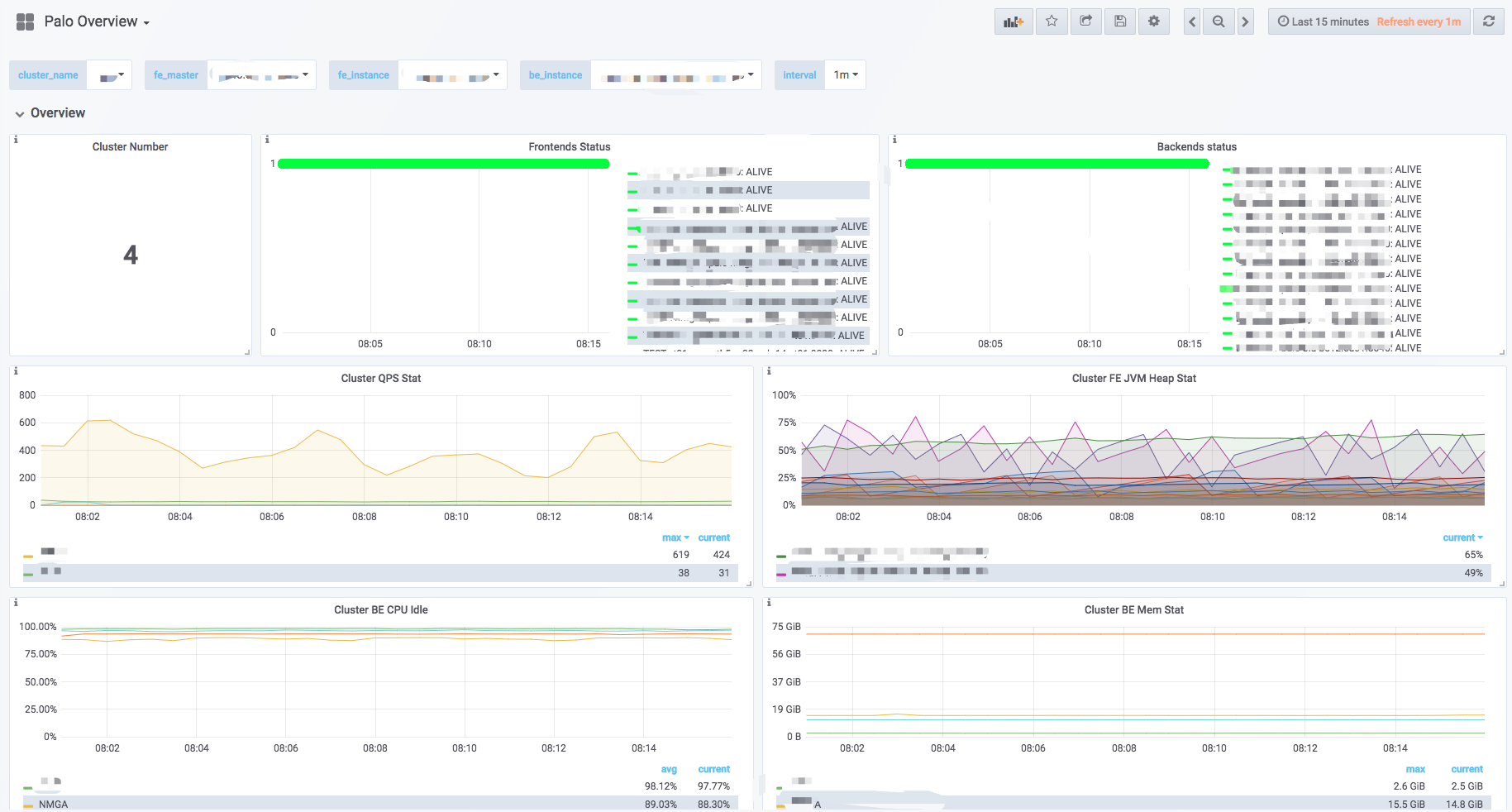
| 组件 | 角色 |
|---|---|
| Prometheus | 开源系统监控与报警套件,通过 Pull 或 Push 方式采集监控项并存入自身的时序数据库(TSDB),同时提供多维数据查询语言 |
| Grafana | 开源数据分析与展示平台,支持包括 Prometheus 在内的多种时序数据源,通过可配置的 Dashboard 将数据以图表形式展示 |
| Alertmanager | Prometheus 报警组件,独立部署,可配置邮件 / 短信等报警策略(本文不展开,参考官方文档) |
注:本文档仅提供一种使用 Prometheus 和 Grafana 进行 Doris 监控数据采集和展示的方式。原则上不开发、维护这些组件。更多关于这些组件的详细介绍,请移步对应官方文档进行查阅。
数据流示意
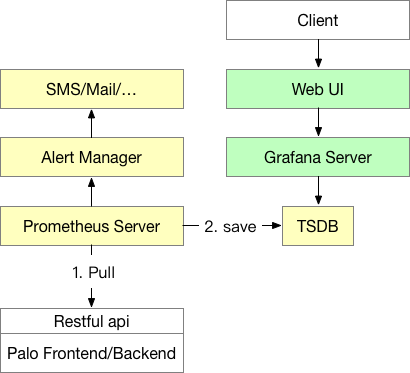
- Prometheus(黄色部分):Prometheus Server 是 Prometheus 的主进程,通过 Pull 的方式访问 Doris 节点的监控接口,然后将时序数据存入时序数据库 TSDB 中(TSDB 包含在 Prometheus 进程中,无需单独部署)。Prometheus 也支持通过搭建 Push Gateway 的方式,允许被监控系统将监控数据通过 Push 的方式推到 Push Gateway,再由 Prometheus Server 通过 Pull 的方式从 Push Gateway 中获取数据。
- Alertmanager:Alertmanager 为 Prometheus 报警组件,需单独部署(暂不提供方案,可参照官方文档自行搭建)。通过 Alertmanager,用户可以配置报警策略,接收邮件、短信等报警。
- Grafana(绿色部分):Grafana Server 为 Grafana 的主进程。启动后,用户可以通过 Web 页面对 Grafana 进行配置,包括数据源的设置、用户设置、Dashboard 绘制等。这里也是最终用户查看监控数据的地方。
监控数据格式
Doris 的监控数据通过 Frontend 和 Backend 的 HTTP 接口向外暴露,以 Key-Value 文本形式呈现,每个 Key 还可能携带若干 Label 加以区分。集群部署完成后,可在浏览器中直接访问以下接口查看节点的实时监控数据:
| 节点类型 | 接口地址 |
|---|---|
| Frontend | fe_host:fe_http_port/metrics |
| Backend | be_host:be_web_server_port/metrics |
| Broker | 暂不提供 |
访问后将看到如下监控项结果(示例为 FE 部分监控项):
# HELP jvm_heap_size_bytes jvm heap stat
# TYPE jvm_heap_size_bytes gauge
jvm_heap_size_bytes{type="max"} 8476557312
jvm_heap_size_bytes{type="committed"} 1007550464
jvm_heap_size_bytes{type="used"} 156375280
# HELP jvm_non_heap_size_bytes jvm non heap stat
# TYPE jvm_non_heap_size_bytes gauge
jvm_non_heap_size_bytes{type="committed"} 194379776
jvm_non_heap_size_bytes{type="used"} 188201864
# HELP jvm_young_size_bytes jvm young mem pool stat
# TYPE jvm_young_size_bytes gauge
jvm_young_size_bytes{type="used"} 40652376
jvm_young_size_bytes{type="peak_used"} 277938176
jvm_young_size_bytes{type="max"} 907345920
# HELP jvm_old_size_bytes jvm old mem pool stat
# TYPE jvm_old_size_bytes gauge
jvm_old_size_bytes{type="used"} 114633448
jvm_old_size_bytes{type="peak_used"} 114633448
jvm_old_size_bytes{type="max"} 7455834112
# HELP jvm_gc jvm gc stat
# TYPE jvm_gc gauge
<GarbageCollector>{type="count"} 247
<GarbageCollector>{type="time"} 860
# HELP jvm_thread jvm thread stat
# TYPE jvm_thread gauge
jvm_thread{type="count"} 162
jvm_thread{type="peak_count"} 205
jvm_thread{type="new_count"} 0
jvm_thread{type="runnable_count"} 48
jvm_thread{type="blocked_count"} 1
jvm_thread{type="waiting_count"} 41
jvm_thread{type="timed_waiting_count"} 72
jvm_thread{type="terminated_count"} 0
...
这是一段以 Prometheus 格式 呈现的监控数据。以其中一项为例:
# HELP jvm_heap_size_bytes jvm heap stat
# TYPE jvm_heap_size_bytes gauge
jvm_heap_size_bytes{type="max"} 8476557312
jvm_heap_size_bytes{type="committed"} 1007550464
jvm_heap_size_bytes{type="used"} 156375280
字段含义如下:
#开头的行为注释行。HELP是该监控项的描述说明;TYPE表示该监控项的数据类型,示例中为Gauge,即标量数据。还有Counter、Histogram等数据类型,具体可参见 Prometheus 官方文档。jvm_heap_size_bytes是监控项名称(Key);type="max"是名为type的 Label,取值为max。一个监控项可以携带多个 Label。- 最后的数字
8476557312即为该监控项的实际数值。
搭建监控系统
完成 Doris 部署后,按以下顺序搭建监控系统:
- 部署 Prometheus,配置抓取 FE / BE 的
/metrics接口。 - 部署 Grafana,将 Prometheus 配置为数据源。
- 在 Grafana 中导入 Doris 官方 Dashboard 模板。
- 在 Grafana 页面中查看 Dashboard 并按需调整。
部署 Prometheus
1. 下载与解压
在 Prometheus 官网 下载最新版本的 Prometheus。这里以 2.43.0-linux-amd64 版本为例。在准备运行监控服务的机器上解压下载后的 tar 文件。
2. 编写配置文件
打开配置文件 prometheus.yml。配置文件为 YAML 格式,注意保持统一的缩进和空格。这里使用最简单的静态文件方式进行监控配置;Prometheus 也支持多种 服务发现 方式,可以动态地感知节点的加入和删除。
示例配置如下:
# my global config
global:
scrape_interval: 15s # 全局的采集间隔,默认是 1m,这里设置为 15s
evaluation_interval: 15s # 全局的规则触发间隔,默认是 1m,这里设置 15s
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'DORIS_CLUSTER' # 每一个 Doris 集群,我们称为一个 job。这里可以给 job 取一个名字,作为 Doris 集群在监控系统中的名字。
metrics_path: '/metrics' # 这里指定获取监控项的 restful api。配合下面的 targets 中的 host:port,Prometheus 最终会通过 host:port/metrics_path 来采集监控项。
static_configs: # 这里开始分别配置 FE 和 BE 的目标地址。所有的 FE 和 BE 都分别写入各自的 group 中。
- targets: ['fe_host1:8030', 'fe_host2:8030', 'fe_host3:8030']
labels:
group: fe # 这里配置了 fe 的 group,该 group 中包含了 3 个 Frontends
- targets: ['be_host1:8040', 'be_host2:8040', 'be_host3:8040']
labels:
group: be # 这里配置了 be 的 group,该 group 中包含了 3 个 Backends
- job_name: 'DORIS_CLUSTER_2' # 我们可以在一个 Prometheus 中监控多个 Doris 集群,这里开始另一个 Doris 集群的配置。配置同上,以下略。
metrics_path: '/metrics'
static_configs:
- targets: ['fe_host1:8030', 'fe_host2:8030', 'fe_host3:8030']
labels:
group: fe
- targets: ['be_host1:8040', 'be_host2:8040', 'be_host3:8040']
labels:
group: be
关键字段说明:
| 字段 | 说明 |
|---|---|
scrape_interval | 全局采集间隔,建议设置为 15s |
evaluation_interval | 全局规则触发间隔,建议设置为 15s |
job_name | 每个 Doris 集群对应一个 job,作为该集群在监控系统中的标识 |
metrics_path | 指标接口路径,固定为 /metrics |
static_configs.targets | FE / BE 节点的 host:port 列表,FE 默认端口 8030,BE 默认端口 8040 |
labels.group | 节点分组标签,建议分别取值 fe 和 be |
3. 启动 Prometheus
通过以下命令在后台启动 Prometheus,并指定其 Web 端口为 8181:
nohup ./prometheus --web.listen-address="0.0.0.0:8181" &
启动后,Prometheus 会立即开始采集数据,并将数据存放在 data 目录中。
4. 停止 Prometheus
目前 Prometheus 没有提供正式的进程停止方式,直接 kill -9 即可。也可以将 Prometheus 注册为 service,以 service 的方式启停。
5. 访问 Prometheus
通过浏览器打开 8181 端口即可访问 Prometheus 页面。点击导航栏中 Status -> Targets,可以看到所有分组 Job 的监控主机节点。正常情况下,所有节点都应为 UP,表示数据采集正常。点击某一个 Endpoint 即可看到当前的监控数值。
如果节点状态不为 UP,可先访问 Doris 的 /metrics 接口(见 监控数据格式)检查是否可达,或查询 Prometheus 相关文档尝试解决。
更多高级使用方式,请参阅 Prometheus 官方文档。
部署 Grafana
1. 下载与解压
在 Grafana 官网 下载最新版本的 Grafana。这里以 8.5.22.linux-amd64 版本为例。在准备运行监控服务的机器上解压下载后的 tar 文件。
2. 编写配置文件
打开配置文件 conf/defaults.ini,仅需关注以下配置项,其余使用默认即可:
# Path to where grafana can store temp files, sessions, and the sqlite3 db (if that is used)
data = data
# Directory where grafana can store logs
logs = data/log
# Protocol (http, https, socket)
protocol = http
# The ip address to bind to, empty will bind to all interfaces
http_addr =
# The http port to use
http_port = 8182
3. 启动 Grafana
通过以下命令在后台启动 Grafana,访问端口为上面配置的 8182:
nohup ./bin/grafana-server &
4. 停止 Grafana
目前 Grafana 没有提供正式的进程停止方式,直接 kill -9 即可。也可以将 Grafana 注册为 service,以 service 的方式启停。
5. 访问 Grafana
通过浏览器打开 8182 端口即可访问 Grafana 页面。默认用户名和密码均为 admin。
6. 配置数据源
初次登录后,根据提示配置数据源(Data Source)。这里的数据源即上一步部署的 Prometheus。
数据源配置 Setting 页面说明如下:
| 字段 | 设置说明 |
|---|---|
| Name | 数据源名称,自定义,如 doris_monitor_data_source |
| Type | 选择 Prometheus |
| URL | 填写 Prometheus 的 Web 地址,如 http://host:8181 |
| Access | 选择 Server 方式,通过 Grafana 进程所在服务器访问 Prometheus |
| 其余选项 | 保持默认即可 |
点击页面最下方的 Save & Test,若显示 Data source is working,则表示数据源可用。
7. 导入 Dashboard
确认数据源可用后,按以下步骤导入 Doris 官方 Dashboard 模板:
- 点击左侧导航栏的
+号,开始添加 Dashboard。 - 下载本文 Dashboard 模板下载 中提供的 JSON 文件。
- 点击上方的
New dashboard->Import dashboard->Upload .json File,将下载的 JSON 文件导入。 - 导入后可命名 Dashboard,默认为
Doris Overview;选择数据源时,选择之前创建的doris_monitor_data_source。 - 点击
Import完成导入,即可看到 Doris Dashboard 的展示。
更多高级使用方式,请参阅 Grafana 官方文档。
Dashboard 说明
Dashboard 的内容可能会随版本升级不断变化,本文档不保证为最新内容。
顶栏

| 元素 | 说明 |
|---|---|
| 左上角 | Dashboard 名称 |
| 右上角 | 当前监控时间范围,可下拉选择不同的时间范围,也可指定定时刷新页面的间隔 |
cluster_name | 即 Prometheus 配置文件中的各个 job_name,代表一个 Doris 集群,切换后下方图表将展示对应集群的监控信息 |
fe_master | 对应集群的 Master Frontend 节点 |
fe_instance | 对应集群的所有 Frontend 节点,切换后下方图表将展示对应 Frontend 的监控信息 |
be_instance | 对应集群的所有 Backend 节点,切换后下方图表将展示对应 Backend 的监控信息 |
interval | 速率相关监控项的采样间隔(注:15s 间隔可能导致部分图表无法显示) |
Row
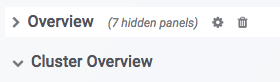
在 Grafana 中,Row 是一组图表的集合(如上图中的 Overview 与 Cluster Overview)。点击 Row 可对其进行折叠。当前 Dashboard 包含以下 Row(持续更新中):
| Row | 说明 |
|---|---|
| Overview | 所有 Doris 集群的汇总展示 |
| Cluster Overview | 选定集群的汇总展示 |
| Query Statistic | 选定集群的查询相关监控 |
| FE JVM | 选定 Frontend 的 JVM 监控 |
| BE | 选定集群的 Backends 的汇总展示 |
| BE Task | 选定集群的 Backends 任务信息展示 |
图表
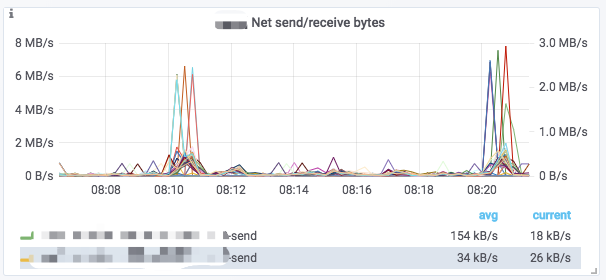
一个典型的图表通常包含以下要素:
- 鼠标悬停在左上角的
i图标上,可以查看该图表的说明。 - 点击下方的图例,可以单独查看某一监控项;再次点击则恢复显示所有。
- 在图表中拖拽可选定时间范围。
- 标题的
[]中显示选定的集群名称。 - 一些数值对应左边的 Y 轴,一些对应右边的 Y 轴,可通过图例末尾的
-right区分。 - 点击图表名称 ->
Edit,可对图表进行编辑。
Dashboard 更新
当官方更新 Dashboard 模板后,按以下步骤覆盖更新:
- 点击 Grafana 左边栏的
+,再点击Dashboard。 - 点击左上角的
New dashboard,再点击右侧出现的Import dashboard。 - 点击
Upload .json File,选择最新的模板文件。 - 选择数据源。
- 点击
Import (Overwrite),完成模板更新。
常见问题
Q: Prometheus Targets 中节点状态为 DOWN,怎么处理?
检查 Prometheus 服务器到 FE / BE 节点的网络连通性,确认目标地址、端口正确,并能直接访问 /metrics 接口。
Q: 浏览器无法访问 FE / BE 的 /metrics,怎么处理?
确认 FE http_port(默认 8030)与 BE webserver_port(默认 8040)已开放,且节点进程运行正常。
Q: Grafana 显示 Data source is not working,怎么处理?
检查 Grafana 数据源 URL 是否与 Prometheus 实际监听地址一致,并确认 Grafana 服务器到 Prometheus 网络可达。
Q: Dashboard 中部分图表为空,怎么处理?
检查 interval 选择是否过小(如 15s 可能导致速率类图表无数据),并确认 Prometheus 已成功采集相关 job。
Q: 配置文件 YAML 解析报错,怎么处理?
YAML 严格依赖缩进和空格,检查是否使用 Tab 缩进或缩进层级不一致。
Q: Broker 节点没有监控数据,怎么处理?
当前版本 Broker 暂不提供 /metrics 接口。