性能测试与分析
这里介绍 Doris Ann Index 的查询性能与导入性能。所有的性能测试都是通过 VectorDBBench 完成的。
如需查看单机与分布式下更大规模(10M/100M 级)数据集的测试结果,请参考大规模性能实测。
测试环境
测试涉及到的机器规格都是 16C64GB的机器,CPU型号为 Intel(R) Xeon(R) Platinum 8369B CPU @ 2.70GHz。FE BE 混合部署在一台 16C64GB 的机器上(注意这个不是推荐的生产环境部署方式,生产环境上建议 FE 与 BE 分离部署),测试的版本是 Apache Doris 4.0.2。采用的测试数据集是 VectorDBBench Performance768D1M,该数据集向量的维度为 768 维,一共一百万行。
测试结果
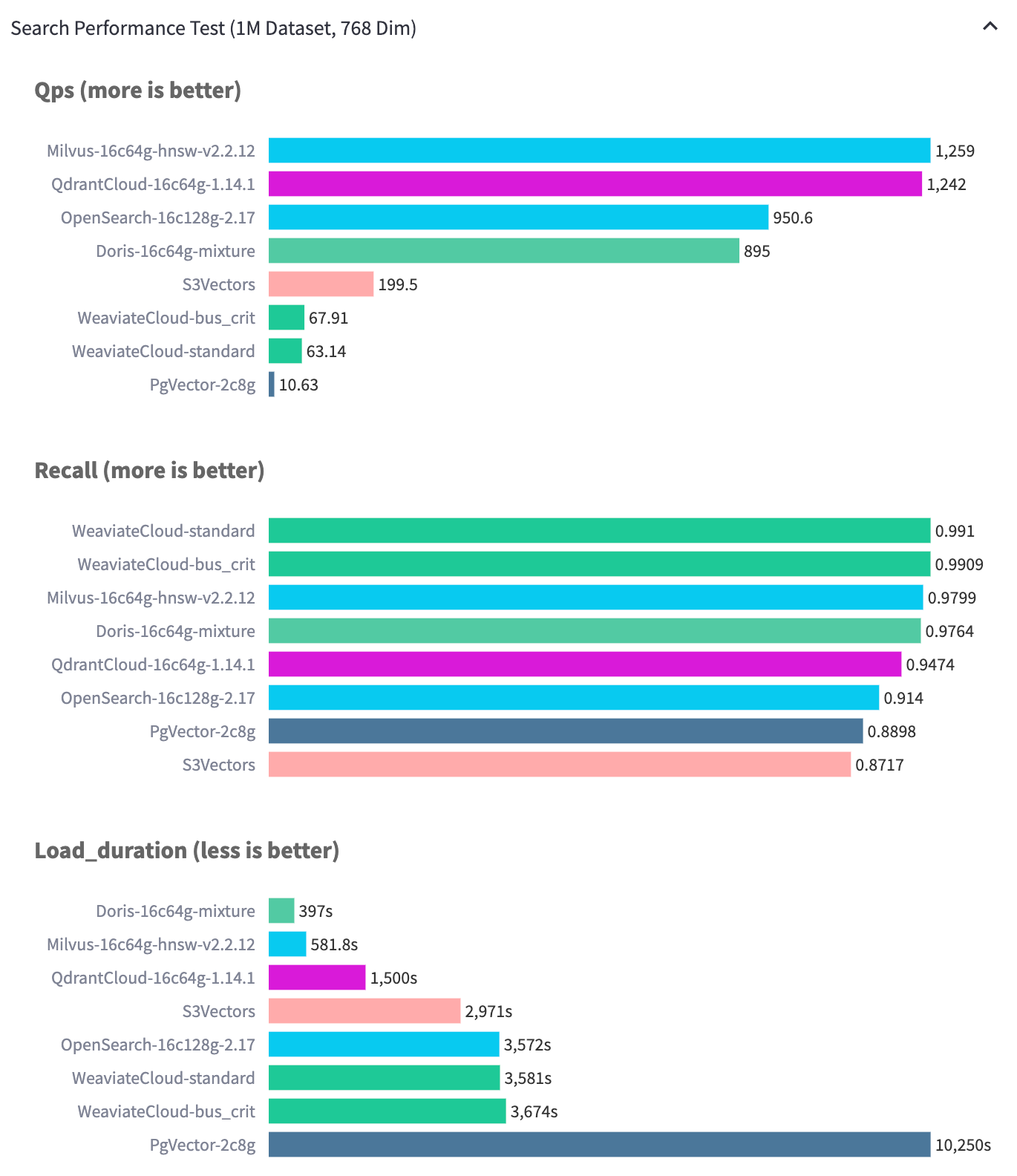
结果分析
┌──────────────────────┐
│ 召回率 Recall │
│ (Higher is Better) │
└──────────▲───────────┘
/ \
/ \
/ \
/ \
/ \
/ \
┌───────────┘ └───────────┐
│ │
│ │
▼ ▼
┌──────────────────────┐ ┌────────────────────────┐
│ 查询性能 QPS │ │ 导入速度 Indexing │
│ (Latency / QPS) │ │ Throughput │
│ (Lower Latency Better)│ │ (Higher is Better) │
└──────────────────────┘ └────────────────────────┘
在向量搜索场景下,对于一个成熟且可在生产环境稳定运行的向量数据库而言,查询性能(QPS/延迟)、召回率(Recall)、导入速度(Index Build Throughput) 三者通常构成一个难以同时最大化的 性能铁三角。向量数据库的系统设计往往需要在这三者之间进行取舍和权衡。 以目前业界最广泛使用的 HNSW(Hierarchical Navigable Small World)向量索引为例,它依赖图结构进行搜索优化。在 HNSW 中有三个关键超参数可调优:
- max_degree:图中每个节点的最大出度,决定图的稠密程度与整体连通性;
- ef_construction:构建索引时使用的“候选集大小”,越大意味着构建出的图质量越高;
- hnsw_ef_search:查询时的探索窗口大小,直接影响召回率和查询延迟。
从原理上讲,增大索引阶段的 max_degree 和 ef_construction 可以显著提高图结构的连通性与导航效率,从而带来更高的召回率。同时更高质量的图也意味着在查询阶段可以将 hnsw_ef_search 设置得更小,从而降低搜索代价、提升查询性能。然而,这些索引构建超参数的调大会带来显著的副作用:索引构建需要更多计算与内存资源,导入性能因此下降。这正是向量数据库在设计时需要面对的典型三难困境。 Apache Doris 在设计其向量搜索能力时,目标是构建一个更加均衡的性能三角形。它通过底层执行引擎的优化、存储格式改进,以及对 HNSW 构建流程的工程级并行化加速,使得在不牺牲索引质量与高召回的前提下,显著提升整体索引导入速度。
在 Performance768D1M 数据集上的测试结果表明:在保持索引质量一致的前提下,Apache Doris 的导入性能明显优于同类系统。更重要的是,Doris 并未因为提升导入速度而降低图结构的质量。在实际测试中,Apache Doris 能够在 QPS 达到 989.1 的情况下仍然保持 97% 以上的召回率,在性能三角的三个维度上均取得了较为均衡的结果。
复现方式
NUM_PER_BATCH=500000 vectordbbench doris --host 127.0.0.1 --port 9030 --http-port 8030 --case-type Performance768D1M --db-name vdb --num-concurrency 80 --stream-load-rows-per-batch 500000 --index-prop max_degree=128,ef_construction=256 --session-var hnsw_ef_search=100