Routine Load
Doris 可以通过 Routine Load 导入方式持续消费 Kafka Topic 中的数据。在提交 Routine Load 作业后,Doris 会持续运行该导入作业,实时生成导入任务不断消费 Kafka 集群中指定 Topic 的消息。
Routine Load 是一个流式导入作业,支持 Exactly-Once 语义,保证数据不丢不重。
使用场景
支持数据源
Routine Load 支持从 Kafka 集群中消费数据。
支持数据文件格式
Routine Load 支持 CSV 及 JSON 格式的数据。
在导入 CSV 格式时,需要明确区分空值(null)与空字符串(''):
-
空值(null)需要用
\n表示,a,\n,b数据表示中间列是一个空值(null)。 -
空字符串('')直接将数据置空,
a,,b数据表示中间列是一个空字符串('')。
使用限制
在使用 Routine Load 消费 Kafka 中数据时,有以下限制:
-
支持的消息格式为 CSV 及 JSON 文本格式。CSV 每一个 message 为一行,且行尾不包含换行符。
-
默认支持 Kafka 0.10.0.0(含)以上版本。如果要使用 Kafka 0.10.0.0 以下版本(0.9.0、0.8.2、0.8.1、0.8.0),需要修改 BE 的配置,将
kafka_broker_version_fallback的值设置为要兼容的旧版本,或者在创建 Routine Load 的时候直接设置property.broker.version.fallback的值为要兼容的旧版本,使用旧版本的代价是 Routine Load 的部分新特性可能无法使用,如根据时间设置 Kafka 分区的 offset。
基本原理
Routine Load 会持续消费 Kafka Topic 中的数据,写入 Doris 中。
在 Doris 中,创建 Routine Load 作业后会生成一个常驻的导入作业,包括若干个导入任务:
-
导入作业(Load Job):一个 Routine Load Job 是一个常驻的导入作业,会持续不断地消费数据源中的数据。
-
导入任务(Load Task):一个导入作业会被拆解成若干个导入任务进行实际消费,每个任务都是一个独立的事务。
Routine Load 的导入具体流程如下图所示:
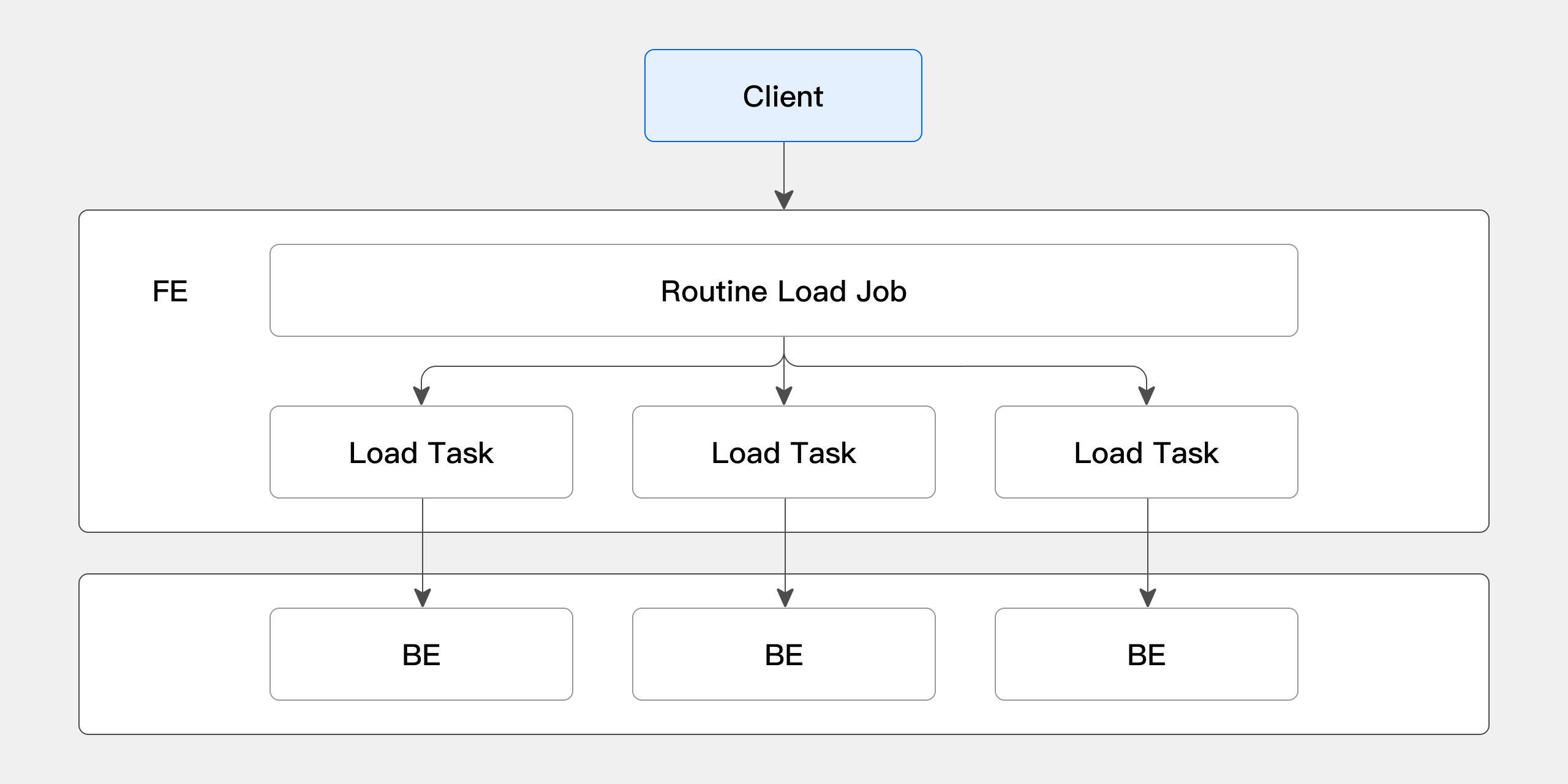
-
Client 向 FE 提交创建 Routine Load 作业请求,FE 通过 Routine Load Manager 生成一个常驻的导入作业(Routine Load Job)。
-
FE 通过 Job Scheduler 将 Routine Load Job 拆分成若干个 Routine Load Task,由 Task Scheduler 进行调度,下发到 BE 节点。
-
在 BE 上,一个 Routine Load Task 导入完成后向 FE 提交事务,并更新 Job 的元数据。
-
一个 Routine Load Task 提交后,会继续生成新的 Task,或对超时的 Task 进行重试。
-
新生成的 Routine Load Task 由 Task Scheduler 继续调度,不断循环。
自动恢复
为了确保作业的高可用性,引入了自动恢复机制。在非预期暂停的情况下,Routine Load Scheduler 调度线程会尝试自动恢复作业。对于 Kafka 侧的意外宕机或其他无法工作的情况,自动恢复机制可以确保在 Kafka 恢复后,无需人工干预,导入作业能够继续正常运行。
不会自动恢复的情况:
-
用户手动执行
PAUSE ROUTINE LOAD命令。 -
数据质量存在问题。
-
无法自动恢复的情况,例如库表被删除。
除了上述三种情况,其他暂停状态的作业都会尝试自动恢复。
快速上手
创建导入作业
在 Doris 内可以通过 CREATE ROUTINE LOAD 命令创建常驻 Routine Load 导入任务。详细语法可以参考 CREATE ROUTINE LOAD。Routine Load 可以消费 CSV 和 JSON 的数据。
导入 CSV 数据
- 导入数据样本
在 Kafka 中,有以下样本数据
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-csv --from-beginning
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
- 创建需要导入的表
在 Doris 中,创建被导入的表,具体语法如下
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
- 创建 Routine Load 导入作业
在 Doris 中,使用 CREATE ROUTINE LOAD 命令,创建导入作业
CREATE ROUTINE LOAD testdb.example_routine_load_csv ON test_routineload_tbl
COLUMNS TERMINATED BY ",",
COLUMNS(user_id, name, age)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092",
"kafka_topic" = "test-routine-load-csv",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
导入 JSON 数据
- 导入样本数据
在 Kafka 中,有以下样本数据
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-json --from-beginning
{"user_id":1,"name":"Emily","age":25}
{"user_id":2,"name":"Benjamin","age":35}
{"user_id":3,"name":"Olivia","age":28}
{"user_id":4,"name":"Alexander","age":60}
{"user_id":5,"name":"Ava","age":17}
{"user_id":6,"name":"William","age":69}
{"user_id":7,"name":"Sophia","age":32}
{"user_id":8,"name":"James","age":64}
{"user_id":9,"name":"Emma","age":37}
{"user_id":10,"name":"Liam","age":64}
- 创建需要导入的表
在 Doris 中,创建被导入的表,具体语法如下
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
- 创建 Routine Load 导入作业
在 Doris 中,使用 CREATE ROUTINE LOAD 命令,创建导入作业
CREATE ROUTINE LOAD testdb.example_routine_load_json ON test_routineload_tbl
COLUMNS(user_id,name,age)
PROPERTIES(
"format"="json",
"jsonpaths"="[\"$.user_id\",\"$.name\",\"$.age\"]"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092",
"kafka_topic" = "test-routine-load-json",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
如果需要将 JSON 文件中根节点的 JSON 对象导入,jsonpaths 需要指定为 $.,如:PROPERTIES("jsonpaths"="$.")。
查看导入状态
在 Doris 中,Routine Load 的导入作业情况和导入任务状态:
-
导入作业:主要用于查看导入任务目标表、子任务数量、导入延迟状态、导入配置与导入结果等信息。
-
导入任务:主要用于查看导入的子任务状态、消费进度以及下发的 BE 节点。
01 查看导入运行任务
可以通过 SHOW ROUTINE LOAD 命令查看导入作业情况。SHOW ROUTINE LOAD 描述了当前作业的基本情况,如导入目标表、导入延迟状态、导入配置信息、导入错误信息等。
如通过以下命令可以查看 testdb.example_routine_load_csv 的任务情况:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
02 查看导入运行作业
可以通过 SHOW ROUTINE LOAD TASK 命令查看导入子任务情况。SHOW ROUTINE LOAD TASK 描述了当前作业下的子任务信息,如子任务状态,下发 BE id 等信息。
如通过以下命令可以查看 testdb.example_routine_load_csv 的任务情况:
mysql> SHOW ROUTINE LOAD TASK WHERE jobname = 'example_routine_load_csv';
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| TaskId | TxnId | TxnStatus | JobId | CreateTime | ExecuteStartTime | Timeout | BeId | DataSourceProperties |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| 8cf47e6a68ed4da3-8f45b431db50e466 | 195 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 10429 | {"4":1231,"9":2603} |
| f2d4525c54074aa2-b6478cf8daaeb393 | 196 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 12109 | {"1":1225,"6":1216} |
| cb870f1553864250-975279875a25fab6 | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"2":7234,"7":4865} |
| 68771fd8a1824637-90a9dac2a7a0075e | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"3":1769,"8":2982} |
| 77112dfea5e54b0a-a10eab3d5b19e565 | 197 | PREPARE | 12177 | 2024-01-15 12:21:02 | 2024-01-15 12:21:02 | 20 | 12098 | {"0":3000,"5":2622} |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
暂停导入作业
可以通过 PAUSE ROUTINE LOAD 命令暂停导入作业。暂停导入作业后,会进入 PAUSED 状态,但导入作业并未终止,可以通过 RESUME ROUTINE LOAD 命令重启导入作业。
如通过以下命令可以暂停 testdb.example_routine_load_csv 导入作业:
PAUSE ROUTINE LOAD FOR testdb.example_routine_load_csv;
恢复导入作业
可以通过 RESUME ROUTINE LOAD 命令恢复导入作业。
如通过以下命令可以恢复 testdb.example_routine_load_csv 导入作业:
RESUME ROUTINE LOAD FOR testdb.example_routine_load_csv;
修改导入作业
可以通过 ALTER ROUTINE LOAD 命令修改已创建的导入作业。在修改导入作业前,需要使用 PAUSE ROUTINE LOAD 暂停导入作业,修改后需要使用 RESUME ROUTINE LOAD 恢复导入作业。
如通过以下命令可以修改期望导入任务并行度参数 desired_concurrent_number,并修改 Kafka Topic 信息:
ALTER ROUTINE LOAD FOR testdb.example_routine_load_csv
PROPERTIES(
"desired_concurrent_number" = "3"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.60:9092",
"kafka_topic" = "test-topic"
);
取消导入作业
可以通过 STOP ROUTINE LOAD 命令停止并删除 Routine Load 导入作业。删除后的导入作业无法被恢复,也无法通过 SHOW ROUTINE LOAD 命令查看。
可以通过以下命令停止并删除导入作业 testdb.example_routine_load_csv:
STOP ROUTINE LOAD FOR testdb.example_routine_load_csv;
绑定 Compute Group
在存算分离模式下,Routine Load 的 Compute Group 选择逻辑按优先级如下:
- 选择
use db@cluster语句指定的 Compute Group。 - 选择用户属性
default_compute_group指定的 Compute Group。 - 从当前用户有权限的 Compute Group 中选择一个。
在存算一体模式下,选择用户属性 resource_tags.location 中指定的 Compute Group。如果用户属性中未指定,那么就使用名为 default 的 Compute Group。
需要注意的是,Routine Load 作业的 Compute Group 只能在创建时指定,一旦 Routine Load 作业被创建后,其绑定的 Compute Group 就无法修改。
参考手册
导入命令
创建一个 Routine Load 常驻导入作业语法如下:
CREATE ROUTINE LOAD [<db_name>.]<job_name> [ON <tbl_name>]
[merge_type]
[load_properties]
[job_properties]
FROM KAFKA [data_source_properties]
[COMMENT "<comment>"]
创建导入作业的模块说明如下:
| 模块 | 说明 |
|---|---|
| db_name | 指定创建导入任务的数据库。 |
| job_name | 指定创建的导入任务名称,同一个 database 不能有名字相同的任务。 |
| tbl_name | 指定需要导入的表的名称,可选参数,如果不指定,则采用动态表的方式,这个时候需要 Kafka 中的数据包含表名的信息。 |
| merge_type | 数据合并类型。默认值为 APPEND。 merge_type 有三种选项: - APPEND:追加导入方式; - MERGE:合并导入方式; - DELETE:导入的数据皆为需要删除的数据。 |
| load_properties | 导入描述模块,包括以下组成部分: - column_spearator 子句 - columns_mapping 子句 - preceding_filter 子句 - where_predicates 子句 - partitions 子句 - delete_on 子句 - order_by 子句 |
| job_properties | 用于指定 Routine Load 的通用导入参数。 |
| data_source_properties | 用于描述 Kafka 数据源属性。 |
| comment | 用于描述导入作业的备注信息。 |
导入参数说明
01 FE 配置参数
| 参数名称 | 默认值 | 动态配置 | FE Master 独有配置 | 参数描述 |
|---|---|---|---|---|
| max_routine_load_task_concurrent_num | 256 | 是 | 是 | 限制 Routine Load 的导入作业最大子并发数量。建议维持在默认值。如果设置过大,可能导致并发任务数过多,占用集群资源。 |
| max_routine_load_task_num_per_be | 1024 | 是 | 是 | 每个 BE 限制的最大并发 Routine Load 任务数。max_routine_load_task_num_per_be 应该小于 routine_load_thread_pool_size。 |
| max_routine_load_job_num | 100 | 是 | 是 | 限制最大 Routine Load 作业数,包括 NEED_SCHEDULED,RUNNING,PAUSE。 |
| max_tolerable_backend_down_num | 0 | 是 | 是 | 只要有一个 BE 宕机,Routine Load 就无法自动恢复。在满足某些条件时,Doris 可以将 PAUSED 的任务重新调度,转换为 RUNNING 状态。该参数为 0 表示只有所有 BE 节点都处于 alive 状态时允许重新调度。 |
| period_of_auto_resume_min | 5(分钟) | 是 | 是 | 自动恢复 Routine Load 的周期。 |
02 BE 配置参数
| 参数名称 | 默认值 | 动态配置 | 描述 |
|---|---|---|---|
| max_consumer_num_per_group | 3 | 是 | 一个子任务最多生成几个 consumer 进行消费。 |
03 导入配置参数
在创建 Routine Load 作业时,可以通过 CREATE ROUTINE LOAD 命令指定不同模块的导入配置参数。
tbl_name 子句
指定需要导入的表的名称,可选参数。
如果不指定,则采用动态表的方式,这个时候需要 Kafka 中的数据包含表名的信息。目前仅支持从 Kafka 的 Value 中获取动态表名,且需要符合这种格式:以 json 为例:table_name|{"col1": "val1", "col2": "val2"}, 其中 tbl_name 为表名,以 | 作为表名和表数据的分隔符。CSV 格式的数据也是类似的,如:table_name|val1,val2,val3。注意,这里的 table_name 必须和 Doris 中的表名一致,否则会导致导入失败。注意,动态表不支持后面介绍的 column_mapping 配置。
merge_type 子句
可以通过 merge_type 模块指定数据合并的类型。merge_type 有三种选项:
-
APPEND:追加导入方式
-
MERGE:合并导入方式。仅适用于 Unique Key 模型。需要配合 [DELETE ON] 模块,以标注 Delete Flag 列
-
DELETE:导入的数据皆为需要删除的数据
load_properties 子句
可以通过 load_properties 模块描述导入数据的属性,具体语法如下
[COLUMNS TERMINATED BY <column_separator>,]
[COLUMNS (<column1_name>[, <column2_name>, <column_mapping>, ...]),]
[WHERE <where_expr>,]
[PARTITION(<partition1_name>, [<partition2_name>, <partition3_name>, ...]),]
[DELETE ON <delete_expr>,]
[ORDER BY <order_by_column1>[, <order_by_column2>, <order_by_column3>, ...]]
具体模块对应参数如下:
| 子模块 | 参数 | 说明 |
|---|---|---|
| COLUMNS TERMINATED BY | <column_separator> | 用于指定列分隔符,默认为 \t。例如需要指定逗号为分隔符,可以使用以下命令:COLUMN TERMINATED BY ","对于空值处理,需要注意以下事项:- 空值(null)需要用 - 空字符串('')直接将数据置空,a,,b 数据表示中间列是一个空字符串('') |
| COLUMNS | <column_name> | 用于指定对应的列名例如需要指定导入列 (k1, k2, k3),可以使用以下命令:COLUMNS(k1, k2, k3)在以下情况下可以缺省 COLUMNS 子句:- CSV 中的列与表中的列一一对应 - JSON 中的 key 列与表中的列名相同 |
| <column_mapping> | 在导入过程中,可以通过列映射进行列的过滤和转换。如在导入的过程中,目标列需要基于数据源的某一列进行衍生计算,目标列 k4 基于 k3 列使用公式 k3+1 计算得出,需要可以使用以下命令:COLUMNS(k1, k2, k3, k4 = k3 + 1)详细内容可以参考数据转换 | |
| WHERE | <where_expr> | 指定 where_expr 可以根据条件过滤导入的数据源。如只希望导入 age > 30 的数据源,可以使用以下命令:WHERE age > 30 |
| PARTITION | <partition_name> | 指定导入目标表中的哪些 partition。如果不指定,会自动导入对应的 partition 中。如希望导入目标表 p1 与 p2 分区,可以使用以下命令:PARTITION(p1, p2) |
| DELETE ON | <delete_expr> | 在 MERGE 导入模式下,使用 delete_expr 标记哪些列需要被删除。如需要在 MERGE 时删除 age > 30 的列,可以使用以下命令:DELETE ON age > 30 |
| ORDER BY | <order_by_column> | 仅针对 Unique Key 模型生效。用于指定导入数据中的 Sequence Column 列,以保证数据的顺序。如在 Unique Key 表导入时,需要指定导入的 Sequence Column 为 create_time,可以使用以下命令:ORDER BY create_time针对与 Unique Key 模型 Sequence Column 列的描述,可以参考文档数据更新/Sequence 列 |
job_properties 子句
在创建 Routine Load 导入作业时,可以指定 job_properties 子句以指定导入作业的属性。语法如下:
PROPERTIES ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
job_properties 子句具体参数选项如下:
| 参数 | 说明 |
|---|---|
| desired_concurrent_number | 默认值:256 参数描述:单个导入子任务(load task)期望的并发度,修改 Routine Load 导入作业切分的期望导入子任务数量。在导入过程中,期望的子任务并发度可能不等于实际并发度。实际的并发度会根据集群的节点数、负载情况,以及数据源的情况综合考虑,使用公式以下可以计算出实际的导入子任务数:
- topic_partition_num 表示 Kafka Topic 的 paritition 数量 - desired_concurrent_number 表示设置的参数大小 - max_routine_load_task_concurrent_num 为 FE 中设置 Routine Load 最大任务并行度的参数 |
| max_batch_interval | 每个子任务的最大运行时间,单位是秒,必须大于 0,默认值为 60(s)。max_batch_interval/max_batch_rows/max_batch_size 共同形成子任务执行阈值。任一参数达到阈值,导入子任务结束,并生成新的导入子任务。 |
| max_batch_rows | 每个子任务最多读取的行数。必须大于等于 200000。默认是 20000000。max_batch_interval/max_batch_rows/max_batch_size 共同形成子任务执行阈值。任一参数达到阈值,导入子任务结束,并生成新的导入子任务。 |
| max_batch_size | 每个子任务最多读取的字节数。单位是字节,范围是 100MB 到 1GB。默认是 1G。max_batch_interval/max_batch_rows/max_batch_size 共同形成子任务执行阈值。任一参数达到阈值,导入子任务结束,并生成新的导入子任务。 |
| max_error_number | 采样窗口内,允许的最大错误行数。必须大于等于 0。默认是 0,即不允许有错误行。采样窗口为 max_batch_rows * 10。即如果在采样窗口内,错误行数大于 max_error_number,则会导致例行作业被暂停,需要人工介入检查数据质量问题,通过 SHOW ROUTINE LOAD 命令中 ErrorLogUrls 检查数据的质量问题。被 where 条件过滤掉的行不算错误行。 |
| strict_mode | 是否开启严格模式,默认为关闭。严格模式表示对于导入过程中的列类型转换进行严格过滤。如果开启后,非空原始数据的列类型变换如果结果为 NULL,则会被过滤。 严格模式过滤策略如下: - 某衍生列(由函数转换生成而来),Strict Mode 对其不产生影响 - 当列类型需要转换,错误的数据类型将被过滤掉,在 SHOW ROUTINE LOAD 的 - 对于导入的某列类型包含范围限制的,如果原始数据能正常通过类型转换,但无法通过范围限制的,strict mode 对其也不产生影响。例如:如果类型是 decimal(1,0), 原始数据为 10,则属于可以通过类型转换但不在列声明的范围内。这种数据 strict 对其不产生影响。详细内容参考严格模式。 |
| timezone | 指定导入作业所使用的时区。默认为使用 Session 的 timezone 参数。该参数会影响所有导入涉及的和时区有关的函数结果。 |
| format | 指定导入数据格式,默认是 CSV,支持 JSON 格式。 |
| jsonpaths | 当导入数据格式为 JSON 时,可以通过 jsonpaths 指定抽取 JSON 数据中的字段。例如通过以下命令指定导入 jsonpaths:"jsonpaths" = "[\"$.userid\",\"$.username\",\"$.age\",\"$.city\"]" |
| json_root | 当导入数据格式为 JSON 时,可以通过 json_root 指定 JSON 数据的根节点。Doris 将通过 json_root 抽取根节点的元素进行解析。默认为空。例如通过一下命令指定导入 JSON 根节点:"json_root" = "$.RECORDS" |
| strip_outer_array | 当导入数据格式为 json 时,strip_outer_array 为 true 表示 JSON 数据以数组的形式展现,数据中的每一个元素将被视为一行数据。默认值是 false。通常情况下,Kafka 中的 JSON 数据可能以数组形式表示,即在最外层中包含中括号[],此时,可以指定 "strip_outer_array" = "true",以数组模式消费 Topic 中的数据。如以下数据会被解析成两行:[{"user_id":1,"name":"Emily","age":25},{"user_id":2,"name":"Benjamin","age":35}] |
| send_batch_parallelism | 用于设置发送批量数据的并行度。如果并行度的值超过 BE 配置中的 max_send_batch_parallelism_per_job,那么作为协调点的 BE 将使用 max_send_batch_parallelism_per_job 的值。 |
| load_to_single_tablet | 支持一个任务只导入数据到对应分区的一个 tablet,默认值为 false,该参数只允许在对带有 random 分桶的 olap 表导数的时候设置。 |
| partial_columns | 指定是否开启部分列更新功能。默认值为 false。该参数只允许在表模型为 Unique 且采用 Merge on Write 时设置。一流多表不支持此参数。具体参考文档部分列更新 |
| unique_key_update_mode | 指定 Unique Key 表的更新模式。可选值:
|
| partial_update_new_key_behavior | 在 Unique Merge on Write 表上进行部分列更新时,对新插入行的处理方式。有两种类型 APPEND、ERROR。- APPEND:允许插入新行数据- ERROR:插入新行时导入失败并报错 |
| max_filter_ratio | 采样窗口内,允许的最大过滤率。必须在大于等于 0 到小于等于 1 之间。默认值是 1.0,表示可以容忍任何错误行。采样窗口为 max_batch_rows * 10。即如果在采样窗口内,错误行数/总行数大于 max_filter_ratio,则会导致例行作业被暂停,需要人工介入检查数据质量问题。被 where 条件过滤掉的行不算错误行。 |
| enclose | 指定包围符。当 CSV 数据字段中含有行分隔符或列分隔符时,为防止意外截断,可指定单字节字符作为包围符起到保护作用。例如列分隔符为 ",",包围符为 "'",数据为 "a,'b,c'",则 "b,c" 会被解析为一个字段。 |
| escape | 指定转义符。用于转义在字段中出现的与包围符相同的字符。例如数据为 "a,'b,'c'",包围符为 "'",希望 "b,'c 被作为一个字段解析,则需要指定单字节转义符,例如"",将数据修改为 "a,'b,'c'"。 |
04 data_source_properties 子句
在创建 Routine Load 导入作业时,可以指定 data_source_properties 子句以指定 Kafka 数据源的属性。语法如下:
FROM KAFKA ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
data_source_properties 子句具体参数选项如下:
| 参数 | 说明 |
|---|---|
| kafka_broker_list | 指定 Kafka 的 broker 连接信息。格式为 <kafka_broker_ip>:<kafka port>。多个 broker 之间以逗号分隔。例如在 Kafka Broker 中默认端口号为 9092,可以使用以下命令指定 Broker List:"kafka_broker_list" = "<broker1_ip>:9092,<broker2_ip>:9092" |
| kafka_topic | 指定要订阅的 Kafka 的 topic。一个导入作业仅能消费一个 Kafka Topic。 |
| kafka_partitions | 指定需要订阅的 Kafka Partition。如果不指定,则默认消费所有分区。 |
| kafka_offsets | 待消费的 Kafka Partition 中起始消费点(offset)。如果指定时间,则会从大于等于该时间的最近一个 offset 处开始消费。offset 可以指定从大于等于 0 的具体 offset,也可以使用以下格式: - OFFSET_BEGINNING: 从有数据的位置开始订阅。 - OFFSET_END: 从末尾开始订阅。 - 时间格式,如:"2021-05-22 11:00:00" 如果没有指定,则默认从 可以指定多个其实消费点,使用逗号分隔,如: 注意,时间格式不能和 OFFSET 格式混用。 |
| property | 指定自定义 kafka 参数。功能等同于 kafka shell 中 "--property" 参数。当参数的 Value 为一个文件时,需要在 Value 前加上关键词:"FILE:"。创建文件可以参考 CREATE FILE 命令文档。更多支持的自定义参数,可以参考 librdkafka 的官方 CONFIGURATION 文档中,client 端的配置项。如:"property.client.id" = "12345"、"property.group.id" = "group_id_0"、"property.ssl.ca.location" = "FILE:ca.pem"。 |
通过配置 data_source_properties 中的 kafka property 参数,可以配置安全访问选项。目前 Doris 支持多种 Kafka 安全协议,如 plaintext(默认)、SSL、PLAIN、Kerberos 等。
导入状态
通过 SHOW ROUTINE LOAD 命令可以查看导入作业的状态,具体语法如下:
SHOW [ALL] ROUTINE LOAD [FOR jobName];
如通过 SHOW ROUTINE LOAD 会返回以下结果集示例:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
具体显示结果说明如下:
| 结果列 | 列说明 |
|---|---|
| Id | 作业 ID。由 Doris 自动生成。 |
| Name | 作业名称。 |
| CreateTime | 作业创建时间。 |
| PauseTime | 最近一次作业暂停时间。 |
| EndTime | 作业结束时间。 |
| DbName | 对应数据库名称 |
| TableName | 对应表名称。多表的情况下由于是动态表,因此不显示具体表名,会显示 multi-table。 |
| IsMultiTbl | 是否为多表。 |
| State | 作业运行状态,有 5 种状态: - NEED_SCHEDULE:作业等待被调度。在 CREATE ROUTINE LOAD 或 RESUME ROUTINE LOAD 后,作业会先进入到 NEED_SCHEDULE 状态; - RUNNING:作业运行中; - PAUSED:作业被暂停,可以通过 RESUME ROUTINE LOAD 恢复导入作业; - STOPPED:作业已结束,无法被重启; - CANCELLED:作业已取消。 |
| DataSourceType | 数据源类型:KAFKA。 |
| CurrentTaskNum | 当前子任务数量。 |
| JobProperties | 作业配置详情。 |
| DataSourceProperties | 数据源配置详情。 |
| CustomProperties | 自定义配置。 |
| Statistic | 作业运行状态统计信息。 |
| Progress | 作业运行进度。对于 Kafka 数据源,显示每个分区当前已消费的 offset。如 {"0":"2"} 表示 Kafka 分区 0 的消费进度为 2。 |
| Lag | 作业延迟状态。对于 Kafka 数据源,显示每个分区的消费延迟。如 {"0":10} 表示 Kafka 分区 0 的消费延迟为 10。 |
| ReasonOfStateChanged | 作业状态变更的原因 |
| ErrorLogUrls | 被过滤的质量不合格的数据的查看地址 |
| OtherMsg | 其他错误信息 |
导入示例
设置导入最大容错率
-
导入数据样例
1,Benjamin,18
2,Emily,20
3,Alexander,dirty_data -
建表结构
CREATE TABLE demo.routine_test01 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job01 ON routine_test01
COLUMNS TERMINATED BY ","
PROPERTIES
(
"max_filter_ratio"="0.5",
"max_error_number" = "100",
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test01;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
+------+------------+------+
2 rows in set (0.01 sec)
从指定消费点消费数据
-
导入数据样例
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
建表结构
CREATE TABLE demo.routine_test02 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job02 ON routine_test02
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad02",
"kafka_partitions" = "0",
"kafka_offsets" = "3"
); -
导入结果
mysql> select * from routine_test02;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
指定 Consumer Group 的 group.id 与 client.id
-
导入数据样例
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
建表结构
CREATE TABLE demo.routine_test03 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job03 ON routine_test03
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.group.id" = "kafka_job03",
"property.client.id" = "kafka_client_03",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test03;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+------------+------+
3 rows in set (0.01 sec)
设置导入过滤条件
-
导入数据样例
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
建表结构
CREATE TABLE demo.routine_test04 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job04 ON routine_test04
COLUMNS TERMINATED BY ",",
WHERE id >= 3
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad04",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test04;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
导入指定分区数据
-
导入数据样例
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
建表结构
CREATE TABLE demo.routine_test05 (
id INT NOT NULL COMMENT "ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age",
date DATETIME COMMENT "Date"
)
DUPLICATE KEY(`id`)
PARTITION BY RANGE(`id`)
(PARTITION partition_a VALUES [("0"), ("1")),
PARTITION partition_b VALUES [("1"), ("2")),
PARTITION partition_c VALUES [("2"), ("3")))
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job05 ON routine_test05
COLUMNS TERMINATED BY ",",
PARTITION(partition_b)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad05",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test05;
+------+----------+------+---------------------+
| id | name | age | date |
+------+----------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
+------+----------+------+---------------------+
1 rows in set (0.01 sec)
设置导入时区
-
导入数据样例
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
建表结构
CREATE TABLE demo.routine_test06 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
date DATETIME COMMENT "date"
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job06 ON routine_test06
COLUMNS TERMINATED BY ","
PROPERTIES
(
"timezone" = "Asia/Shanghai"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad06",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test06;
+------+-------------+------+---------------------+
| id | name | age | date |
+------+-------------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
| 2 | Emily | 20 | 2024-02-05 11:00:00 |
| 3 | Alexander | 22 | 2024-02-06 12:00:00 |
+------+-------------+------+---------------------+
3 rows in set (0.00 sec)
设置 merge_type
指定 merge_type 进行 delete 操作
-
导入数据样例
3,Alexander,22
5,William,26导入前表中数据如下:
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+ -
建表结构
CREATE TABLE demo.routine_test07 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job07 ON routine_test07
WITH DELETE
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad07",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 4 | Sophia | 24 |
| 6 | Charlotte | 28 |
+------+----------------+------+
指定 merge_type 进行 merge 操作
-
导入数据样例
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38导入前表中数据如下:
mysql> SELECT * FROM routine_test08;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec) -
建表结构
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job08 ON routine_test08
WITH MERGE
COLUMNS TERMINATED BY ",",
DELETE ON id = 2
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad08",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> SELECT * FROM routine_test08;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
指定导入需要 merge 的 sequence 列
-
导入数据样例
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38导入前表中数据如下:
mysql> SELECT * FROM routine_test09;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec) -
建表结构
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"function_column.sequence_col" = "age"
); -
导入命令
CREATE ROUTINE LOAD demo.kafka_job09 ON routine_test09
WITH MERGE
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age),
DELETE ON id = 2,
ORDER BY age
PROPERTIES
(
"desired_concurrent_number"="1",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad09",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> SELECT * FROM routine_test09;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
导入完成列映射与衍生列计算
-
导入数据样例
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
建表结构
CREATE TABLE demo.routine_test10 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job10 ON routine_test10
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age, num=age*10)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad10",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> SELECT * FROM routine_test10;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
导入包含包围符的数据
-
导入数据样例
1,"Benjamin",18
2,"Emily",20
3,"Alexander",22 -
建表结构
CREATE TABLE demo.routine_test11 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job11 ON routine_test11
COLUMNS TERMINATED BY ","
PROPERTIES
(
"desired_concurrent_number"="1",
"enclose" = "\""
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> SELECT * FROM routine_test11;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.02 sec)
JSON 格式导入
以简单模式导入 JSON 格式数据
-
导入数据样例
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
建表结构
CREATE TABLE demo.routine_test12 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job12 ON routine_test12
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test12;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.02 sec)
匹配模式导入复杂的 JSON 格式数据
-
导入数据样例
{ "name" : "Benjamin", "id" : 1, "num":180 , "age":18 }
{ "name" : "Emily", "id" : 2, "num":200 , "age":20 }
{ "name" : "Alexander", "id" : 3, "num":220 , "age":22 } -
建表结构
CREATE TABLE demo.routine_test13 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job13 ON routine_test13
COLUMNS(name, id, num, age)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.name\",\"$.id\",\"$.num\",\"$.age\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad13",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test13;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
指定 JSON 根节点导入数据
-
导入数据样例
{"id": 1231, "source" :{ "id" : 1, "name" : "Benjamin", "age":18 }}
{"id": 1232, "source" :{ "id" : 2, "name" : "Emily", "age":20 }}
{"id": 1233, "source" :{ "id" : 3, "name" : "Alexander", "age":22 }} -
建表结构
CREATE TABLE demo.routine_test14 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job14 ON routine_test14
PROPERTIES
(
"format" = "json",
"json_root" = "$.source"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad14",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test14;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.01 sec)
导入完成列映射与衍生列计算
-
导入数据样例
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
建表结构
CREATE TABLE demo.routine_test15 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job15 ON routine_test15
COLUMNS(id, name, age, num=age*10)
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad15",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test15;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
灵活部分列更新
本示例演示如何使用灵活部分列更新,其中每行可以更新不同的列。这在 CDC 场景中非常有用,因为变更记录可能包含不同的字段。
-
导入数据样例(每条 JSON 记录更新不同的列):
{"id": 1, "balance": 150.00, "last_active": "2024-01-15 10:30:00"}
{"id": 2, "city": "Shanghai", "age": 28}
{"id": 3, "name": "Alice", "balance": 500.00, "city": "Beijing"}
{"id": 1, "age": 30}
{"id": 4, "__DORIS_DELETE_SIGN__": 1} -
建表(必须启用 Merge-on-Write 和 skip bitmap 列):
CREATE TABLE demo.routine_test_flexible (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) COMMENT "姓名",
age INT COMMENT "年龄",
city VARCHAR(50) COMMENT "城市",
balance DECIMAL(10,2) COMMENT "余额",
last_active DATETIME COMMENT "最后活跃时间"
)
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"enable_unique_key_merge_on_write" = "true",
"enable_unique_key_skip_bitmap_column" = "true"
); -
插入初始数据:
INSERT INTO demo.routine_test_flexible VALUES
(1, 'John', 25, 'Shenzhen', 100.00, '2024-01-01 08:00:00'),
(2, 'Jane', 30, 'Guangzhou', 200.00, '2024-01-02 09:00:00'),
(3, 'Bob', 35, 'Hangzhou', 300.00, '2024-01-03 10:00:00'),
(4, 'Tom', 40, 'Nanjing', 400.00, '2024-01-04 11:00:00'); -
导入命令:
CREATE ROUTINE LOAD demo.kafka_job_flexible ON routine_test_flexible
PROPERTIES
(
"format" = "json",
"unique_key_update_mode" = "UPDATE_FLEXIBLE_COLUMNS"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoadFlexible",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果:
mysql> SELECT * FROM demo.routine_test_flexible ORDER BY id;
+------+-------+------+-----------+---------+---------------------+
| id | name | age | city | balance | last_active |
+------+-------+------+-----------+---------+---------------------+
| 1 | John | 30 | Shenzhen | 150.00 | 2024-01-15 10:30:00 |
| 2 | Jane | 28 | Shanghai | 200.00 | 2024-01-02 09:00:00 |
| 3 | Alice | 35 | Beijing | 500.00 | 2024-01-03 10:00:00 |
+------+-------+------+-----------+---------+---------------------+
3 rows in set (0.01 sec)注意:
id=4的行因为__DORIS_DELETE_SIGN__被删除,每行只更新了其对应 JSON 记录中包含的列。
导入复杂类型
导入 Array 数据类型
-
导入数据样例
{ "id" : 1, "name" : "Benjamin", "age":18, "array":[1,2,3,4,5]}
{ "id" : 2, "name" : "Emily", "age":20, "array":[6,7,8,9,10]}
{ "id" : 3, "name" : "Alexander", "age":22, "array":[11,12,13,14,15]} -
建表结构
CREATE TABLE demo.routine_test16
(
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
array ARRAY<int(11)> NULL COMMENT "test array column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job16 ON routine_test16
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad16",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test16;
+------+----------------+------+----------------------+
| id | name | age | array |
+------+----------------+------+----------------------+
| 1 | Benjamin | 18 | [1, 2, 3, 4, 5] |
| 2 | Emily | 20 | [6, 7, 8, 9, 10] |
| 3 | Alexander | 22 | [11, 12, 13, 14, 15] |
+------+----------------+------+----------------------+
3 rows in set (0.00 sec)
导入 Map 数据类型
-
导入数据样例
{ "id" : 1, "name" : "Benjamin", "age":18, "map":{"a": 100, "b": 200}}
{ "id" : 2, "name" : "Emily", "age":20, "map":{"c": 300, "d": 400}}
{ "id" : 3, "name" : "Alexander", "age":22, "map":{"e": 500, "f": 600}} -
建表结构
CREATE TABLE demo.routine_test17 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
map Map<STRING, INT> NULL COMMENT "test column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job17 ON routine_test17
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad17",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test17;
+------+----------------+------+--------------------+
| id | name | age | map |
+------+----------------+------+--------------------+
| 1 | Benjamin | 18 | {"a":100, "b":200} |
| 2 | Emily | 20 | {"c":300, "d":400} |
| 3 | Alexander | 22 | {"e":500, "f":600} |
+------+----------------+------+--------------------+
3 rows in set (0.01 sec)
导入 Bitmap 数据类型
-
导入数据样例
{ "id" : 1, "name" : "Benjamin", "age":18, "bitmap_id":243}
{ "id" : 2, "name" : "Emily", "age":20, "bitmap_id":28574}
{ "id" : 3, "name" : "Alexander", "age":22, "bitmap_id":8573} -
建表结构
CREATE TABLE demo.routine_test18 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
bitmap_id INT COMMENT "test",
device_id BITMAP BITMAP_UNION COMMENT "test column"
)
AGGREGATE KEY (`id`,`name`,`age`,`bitmap_id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job18 ON routine_test18
COLUMNS(id, name, age, bitmap_id, device_id=to_bitmap(bitmap_id))
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad18",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select id, BITMAP_UNION_COUNT(pv) over(order by id) uv from(
-> select id, BITMAP_UNION(device_id) as pv
-> from routine_test18
-> group by id
-> ) final;
+------+------+
| id | uv |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
3 rows in set (0.00 sec)
导入 HLL 数据类型
-
导入数据样例
2022-05-05,10001,Test01,Beijing,windows
2022-05-05,10002,Test01,Beijing,linux
2022-05-05,10003,Test01,Beijing,macos
2022-05-05,10004,Test01,Hebei,windows
2022-05-06,10001,Test01,Shanghai,windows
2022-05-06,10002,Test01,Shanghai,linux
2022-05-06,10003,Test01,Jiangsu,macos
2022-05-06,10004,Test01,Shaanxi,windows -
建表结构
create table demo.routine_test19 (
dt DATE,
id INT,
name VARCHAR(10),
province VARCHAR(10),
os VARCHAR(10),
pv hll hll_union
)
Aggregate KEY (dt,id,name,province,os)
distributed by hash(id) buckets 10; -
导入命令
CREATE ROUTINE LOAD demo.kafka_job19 ON routine_test19
COLUMNS TERMINATED BY ",",
COLUMNS(dt, id, name, province, os, pv=hll_hash(id))
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad19",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
导入结果
mysql> select * from routine_test19;
+------------+-------+----------+----------+---------+------+
| dt | id | name | province | os | pv |
+------------+-------+----------+----------+---------+------+
| 2022-05-05 | 10001 | Test01 | Beijing | windows | NULL |
| 2022-05-06 | 10001 | Test01 | Shanghai | windows | NULL |
| 2022-05-05 | 10002 | Test01 | Beijing | linux | NULL |
| 2022-05-06 | 10002 | Test01 | Shanghai | linux | NULL |
| 2022-05-05 | 10004 | Test01 | Heibei | windows | NULL |
| 2022-05-06 | 10004 | Test01 | Shanxi | windows | NULL |
| 2022-05-05 | 10003 | Test01 | Beijing | macos | NULL |
| 2022-05-06 | 10003 | Test01 | Jiangsu | macos | NULL |
+------------+-------+----------+----------+---------+------+
8 rows in set (0.01 sec)
mysql> SELECT HLL_UNION_AGG(pv) FROM routine_test19;
+-------------------+
| hll_union_agg(pv) |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.01 sec)
Kafka 安全认证
导入 SSL 认证的 Kafka 数据
导入命令样例:
CREATE ROUTINE LOAD demo.kafka_job20 ON routine_test20
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "ssl",
"property.ssl.ca.location" = "FILE:ca.pem",
"property.ssl.certificate.location" = "FILE:client.pem",
"property.ssl.key.location" = "FILE:client.key",
"property.ssl.key.password" = "ssl_passwd"
);
参数说明:
| 参数 | 介绍 |
|---|---|
| property.security.protocol | 使用的安全协议,如上述的例子使用的是 SSL |
| property.ssl.ca.location | CA(Certificate Authority)证书的位置 |
| property.ssl.certificate.location | (如果 Kafka server 端开启了 client 认证才需要配置)Client 的 public key 的位置 |
| property.ssl.key.location | (如果 Kafka server 端开启了 client 认证才需要配置)Client 的 private key 的位置 |
| property.ssl.key.password | (如果 Kafka server 端开启了 client 认证才需要配置)Client 的 private key 的密码 |
导入 Kerberos 认证的 Kafka 数据
导入命令样例:
CREATE ROUTINE LOAD demo.kafka_job21 ON routine_test21
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "SASL_PLAINTEXT",
"property.sasl.kerberos.service.name" = "kafka",
"property.sasl.kerberos.keytab"="/opt/third/kafka/kerberos/kafka_client.keytab",
"property.sasl.kerberos.principal" = "clients/stream.dt.local@EXAMPLE.COM"
);
参数说明:
| 参数 | 介绍 |
|---|---|
| property.security.protocol | 使用的安全协议,如上述的例子使用的是 SASL_PLAINTEXT |
| property.sasl.kerberos.service.name | 指定 broker service name,默认是 Kafka |
| property.sasl.kerberos.keytab | keytab 文件的位置 |
| property.sasl.kerberos.principal | 指定 kerberos principal |
建议在
krb5.conf中设置rdnbs=true。否则可能会出现报错:Server kafka/15.5.4.68@EXAMPLE.COM not found in Kerberos database
导入 PLAIN 认证的 Kafka 集群
导入命令样例:
CREATE ROUTINE LOAD demo.kafka_job22 ON routine_test22
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad22",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="admin",
"property.sasl.password"="admin"
);
参数说明:
| 参数 | 介绍 |
|---|---|
| property.security.protocol | 使用的安全协议,如上述的例子使用的是 SASL_PLAINTEXT |
| property.sasl.mechanism | 指定 SASL 认证机制为 PLAIN |
| property.sasl.username | SASL 的用户名 |
| property.sasl.password | SASL 的密码 |
一流多表导入
为 example_db 创建一个名为 test1 的 Kafka 例行动态多表导入任务。指定列分隔符和 group.id 和 client.id,并且自动默认消费所有分区,且从有数据的位置(OFFSET_BEGINNING)开始订阅。
这里假设需要将 Kafka 中的数据导入到 example_db 中的 tbl1 以及 tbl2 表中,我们创建了一个名为 test1 的例行导入任务,同时将名为 my_topic 的 Kafka 的 Topic 数据同时导入到 tbl1 和 tbl2 中的数据中,这样就可以通过一个例行导入任务将 Kafka 中的数据导入到两个表中。
CREATE ROUTINE LOAD example_db.test1
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
这个时候需要 Kafka 中的数据包含表名的信息。目前仅支持从 Kafka 的 Value 中获取动态表名,且需要符合这种格式:以 JSON 为例:table_name|{"col1": "val1", "col2": "val2"}, 其中 tbl_name 为表名,以 | 作为表名和表数据的分隔符。CSV 格式的数据也是类似的,如:table_name|val1,val2,val3。注意,这里的 table_name 必须和 Doris 中的表名一致,否则会导致导入失败。注意,动态表不支持后面介绍的 column_mapping 配置。
严格模式导入
为 example_db 的 example_tbl 创建一个名为 test1 的 Kafka 例行导入任务。导入任务为严格模式。
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),
PRECEDING FILTER k1 = 1,
WHERE k1 < 100 and k2 like "%doris%"
PROPERTIES
(
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic"
);
连接加密认证的 Kafka 服务
这里我们以访问 StreamNative 消息服务为例说明:
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(user_id, name, age)
FROM KAFKA (
"kafka_broker_list" = "pc-xxxx.aws-mec1-test-xwiqv.aws.snio.cloud:9093",
"kafka_topic" = "my_topic",
"property.security.protocol" = "SASL_SSL",
"property.sasl.mechanism" = "PLAIN",
"property.sasl.username" = "user",
"property.sasl.password" = "token:eyJhbxxx",
"property.group.id" = "my_group_id_1",
"property.client.id" = "my_client_id_1",
"property.enable.ssl.certificate.verification" = "false"
);
注意,如果没有在 BE 端配置信任的 CA 证书路径,需设置 "property.enable.ssl.certificate.verification" = "false",不验证服务器证书是否可信。
否则,需配置信任的 CA 证书路径:"property.ssl.ca.location" = "/path/to/ca-cert.pem"。
更多帮助
参考 SQL 手册 Routine Load。也可以在客户端命令行下输入 HELP ROUTINE LOAD 获取更多帮助信息。