导入时实现数据转换
Doris 在数据导入时提供了强大的数据转换能力,可以简化部分数据处理流程,减少对额外 ETL 工具的依赖。主要支持以下四种转换方式:
-
列映射:将源数据列映射到目标表的不同列。
-
列变换:使用函数和表达式对源数据进行实时转换。
-
前置过滤:在列映射和列变换前过滤掉不需要的原始数据。
-
后置过滤:在列映射和列变换后对数据最终结果进行过滤。
通过这些内置的数据转换功能,可以提高导入效率,并确保数据处理逻辑的一致性。
导入语法
Stream Load
通过在 HTTP header 中设置以下参数实现数据转换:
| 参数 | 说明 |
|---|---|
columns | 指定列映射和列变换 |
where | 指定后置过滤 |
注意: Stream Load 不支持前置过滤。
示例:
curl --location-trusted -u user:passwd \
-H "columns: k1, k2, tmp_k3, k3 = tmp_k3 + 1" \
-H "where: k1 > 1" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
Broker Load
在 SQL 语句中通过以下子句实现数据转换:
| 子句 | 说明 |
|---|---|
column list | 指定列映射,格式为 (k1, k2, tmp_k3) |
SET | 指定列变换 |
PRECEDING FILTER | 指定前置过滤 |
WHERE | 指定后置过滤 |
示例:
LOAD LABEL test_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE `test_tbl`
(k1, k2, tmp_k3)
PRECEDING FILTER k1 = 1
SET (
k3 = tmp_k3 + 1
)
WHERE k1 > 1
)
WITH S3 (...);
Routine Load
在 SQL 语句中通过以下子句实现数据转换:
| 子句 | 说明 |
|---|---|
COLUMNS | 指定列映射和列变换 |
PRECEDING FILTER | 指定前置过滤 |
WHERE | 指定后置过滤 |
示例:
CREATE ROUTINE LOAD test_db.label1 ON test_tbl
COLUMNS(k1, k2, tmp_k3, k3 = tmp_k3 + 1),
PRECEDING FILTER k1 = 1,
WHERE k1 > 1
...
Insert Into
Insert Into 可以直接在 SELECT 语句中完成数据转换,使用 WHERE 子句实现数据过滤。
列映射
列映射用于定义源数据列与目标表列之间的对应关系,能够处理以下场景:
- 源数据与目标表的列顺序不一致
- 源数据与目标表的列数量不匹配
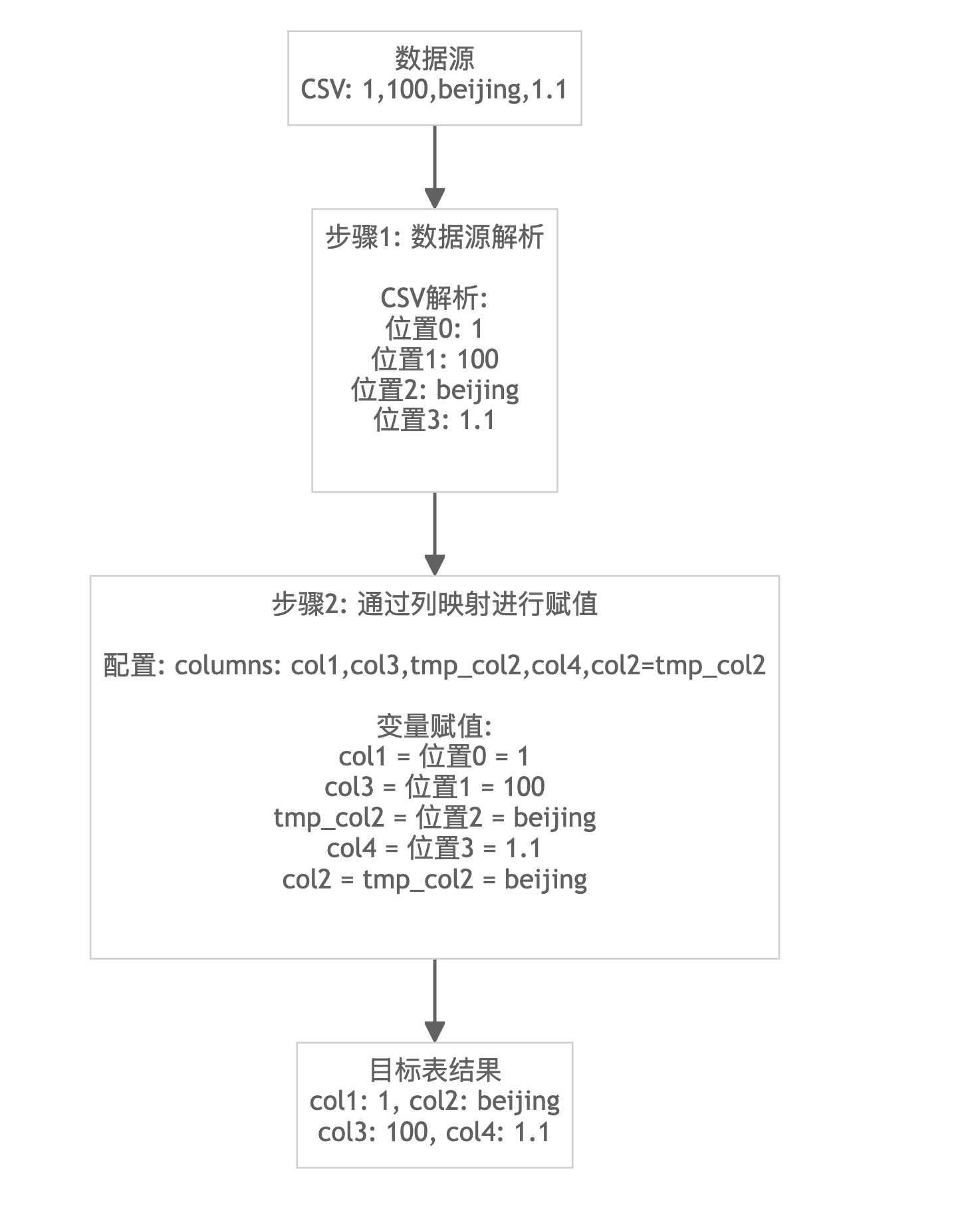
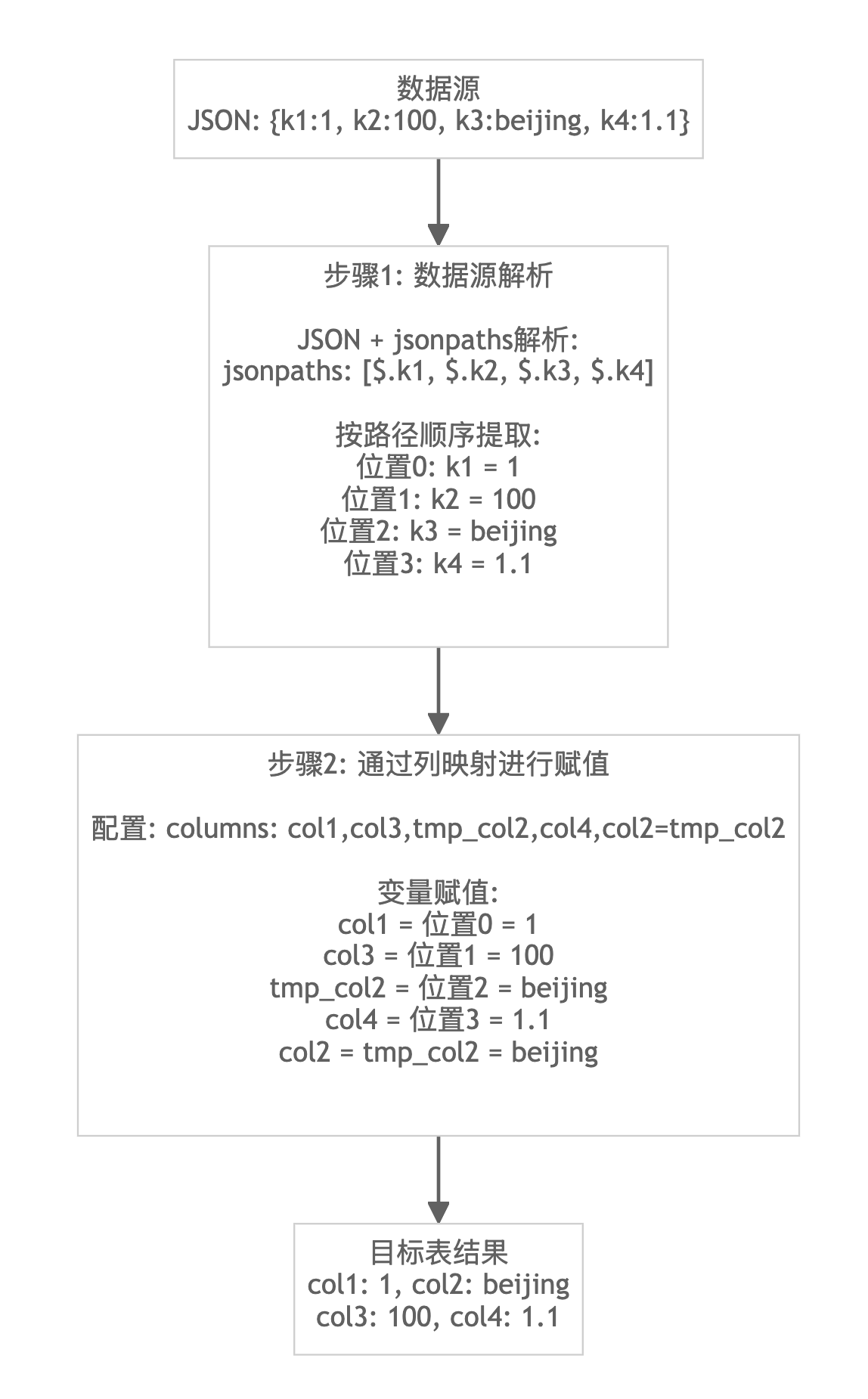
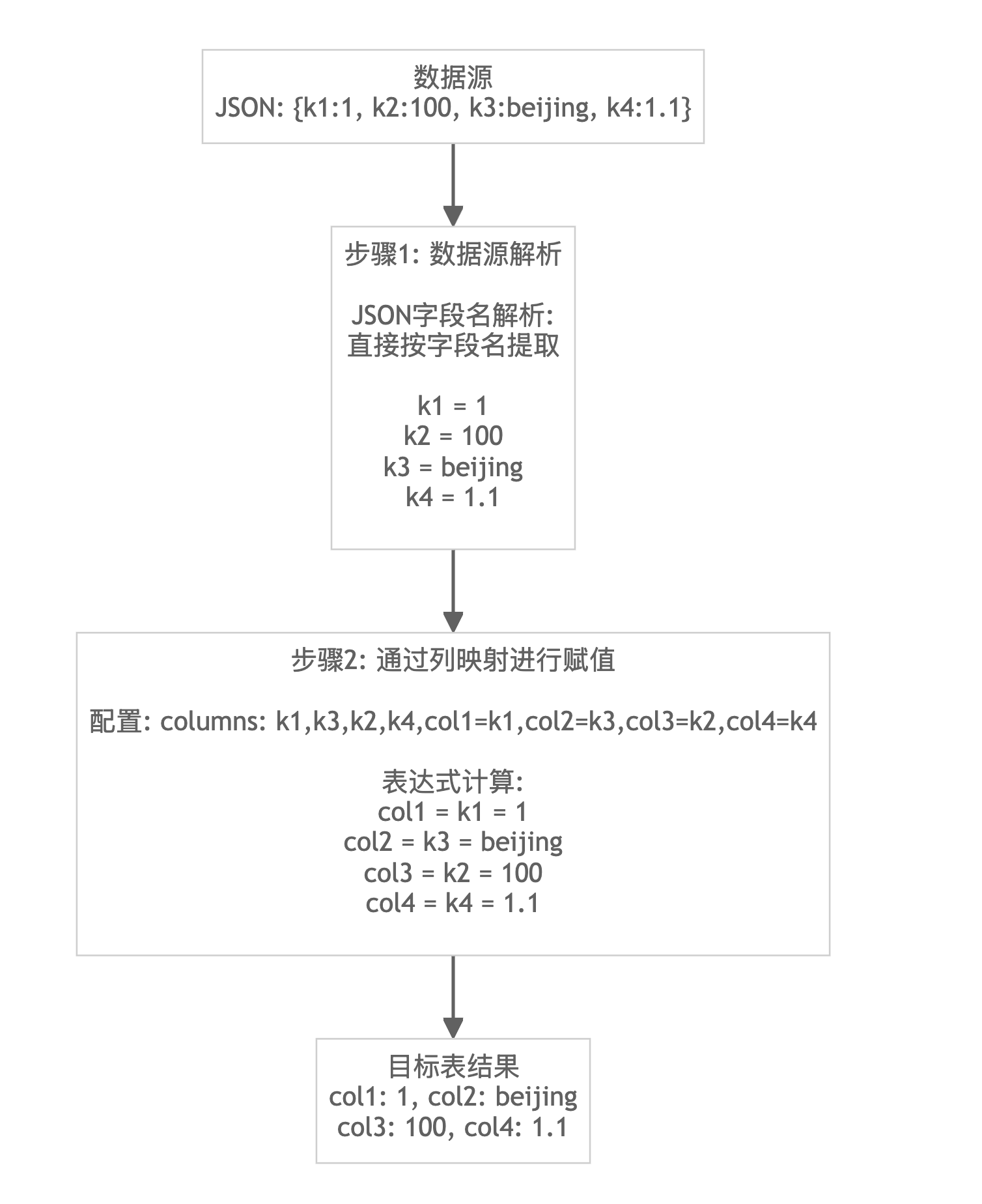
实现原理
列映射的实现可以分为两个核心步骤:
- 步骤 1:数据源解析 - 根据数据格式将原始数据解析为中间变量
- 步骤 2:通过列映射进行赋值 - 将中间变量按列名映射到目标表字段
以下是三种不同数据格式的处理流程:
导入 CSV 格式数据
指定 jsonpaths 导入JSON 格式数据
不指定 jsonpaths 导入JSON 格式数据
指定 jsonpaths 导入 JSON 数据
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
{"k1":1,"k2":"100","k3":"beijing","k4":1.1}
{"k1":2,"k2":"200","k3":"shanghai","k4":1.2}
{"k1":3,"k2":"300","k3":"guangzhou","k4":1.3}
{"k1":4,"k2":"\\N","k3":"chongqing","k4":1.4}
创建目标表
CREATE TABLE example_table
(
col1 INT,
col2 STRING,
col3 INT,
col4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(col1)
DISTRIBUTED BY HASH(col1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "columns:col1, col3, col2, col4" \
-H "jsonpaths:[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]" \
-H "format:json" \
-H "read_json_by_line:true" \
-T data.json \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.json")
INTO TABLE example_table
FORMAT AS "json"
(col1, col3, col2, col4)
PROPERTIES
(
"jsonpaths" = "[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]"
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(col1, col3, col2, col4)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]",
"read_json_by_line" = "true"
)
FROM KAFKA (...);
查询结果
mysql> SELECT * FROM example_table;
+------+-----------+------+------+
| col1 | col2 | col3 | col4 |
+------+-----------+------+------+
| 1 | beijing | 100 | 1.1 |
| 2 | shanghai | 200 | 1.2 |
| 3 | guangzhou | 300 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+------+------+
不指定jsonpaths导入 JSON 数据
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
{"k1":1,"k2":"100","k3":"beijing","k4":1.1}
{"k1":2,"k2":"200","k3":"shanghai","k4":1.2}
{"k1":3,"k2":"300","k3":"guangzhou","k4":1.3}
{"k1":4,"k2":"\\N","k3":"chongqing","k4":1.4}
创建目标表
CREATE TABLE example_table
(
col1 INT,
col2 STRING,
col3 INT,
col4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(col1)
DISTRIBUTED BY HASH(col1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "columns:k1, k3, k2, k4,col1 = k1, col2 = k3, col3 = k2, col4 = k4" \
-H "format:json" \
-H "read_json_by_line:true" \
-T data.json \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.json")
INTO TABLE example_table
FORMAT AS "json"
(k1, k3, k2, k4)
SET (
col1 = k1,
col2 = k3,
col3 = k2,
col4 = k4
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4, col1 = k1, col2 = k3, col3 = k2, col4 = k4),
PROPERTIES
(
"format" = "json",
"read_json_by_line" = "true"
)
FROM KAFKA (...);
查询结果
mysql> SELECT * FROM example_table;
+------+-----------+------+------+
| col1 | col2 | col3 | col4 |
+------+-----------+------+------+
| 1 | beijing | 100 | 1.1 |
| 2 | shanghai | 200 | 1.2 |
| 3 | guangzhou | 300 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+------+------+
调整列顺序
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
目标表有 k1, k2, k3, k4 四列,要实现如下映射:
列 1 -> k1
列 2 -> k3
列 3 -> k2
列 4 -> k4
创建目标表
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1,k3,k2,k4" \
-T data.csv \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k3, k2, k4)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
查询结果
mysql> select * from example_table;
+------+-----------+------+------+
| k1 | k2 | k3 | k4 |
+------+-----------+------+------+
| 2 | shanghai | 200 | 1.2 |
| 4 | chongqing | NULL | 1.4 |
| 3 | guangzhou | 300 | 1.3 |
| 1 | beijing | 100 | 1.1 |
+------+-----------+------+------+
源文件列数量多于表列数
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
目标表有 k1, k2, k3 三列,而源文件包含四列数据。我们只需要源文件的第 1、第 2、第 4 列,映射关系如下:
列 1 -> k1
列 2 -> k2
列 4 -> k3
要跳过源文件中的某些列,只需在列映射时使用任意不存在于目标表的列名。这些列名可以自定义,不受限制,导入时会自动忽略这些列的数据。
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:password \
-H "column_separator:," \
-H "columns: k1,k2,tmp_skip,k3" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k2, tmp_skip, tmp_k3)
SET (
k1 = tmp_k1,
k2 = tmp_k2,
k3 = tmp_k3
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_skip, k3),
PROPERTIES
(
"format" = "csv",
"column_separator" = ","
)
FROM KAFKA (...);
注意:示例中的
tmp_skip可以替换为任意名称,只要这些名称不在目标表的列定义中即可。
查询结果
mysql> select * from example_table;
+------+------+------+
| k1 | k2 | k3 |
+------+------+------+
| 1 | 100 | 1.1 |
| 2 | 200 | 1.2 |
| 3 | 300 | 1.3 |
| 4 | NULL | 1.4 |
+------+------+------+
源文件列数量少于表列数
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
目标表有 k1, k2, k3, k4, k5 五列,而源文件包含四列数据。我们只需要源文件的第 1、第 2、第 3、第 4 列,映射关系如下:
列 1 -> k1
列 2 -> k3
列 3 -> k2
列 4 -> k4
k5 使用默认值
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE,
k5 INT DEFAULT 2
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1,k3,k2,k4" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k3, tmp_k2, tmp_k4)
SET (
k1 = tmp_k1,
k3 = tmp_k3,
k2 = tmp_k2,
k4 = tmp_k4
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
说明:
- 如果 k5 列有默认值,将使用默认值填充
- 如果 k5 列是可空列(nullable)但没有默认值,将填充 NULL 值
- 如果 k5 列是非空列且没有默认值,导入会失败
查询结果
mysql> select * from example_table;
+------+-----------+------+------+------+
| k1 | k2 | k3 | k4 | k5 |
+------+-----------+------+------+------+
| 1 | beijing | 100 | 1.1 | 2 |
| 2 | shanghai | 200 | 1.2 | 2 |
| 3 | guangzhou | 300 | 1.3 | 2 |
| 4 | chongqing | NULL | 1.4 | 2 |
+------+-----------+------+------+------+
列变换
列变换功能允许用户对源文件中列值进行变换,支持使用绝大部分内置函数。列变换操作通常是和列映射一起定义的,即先对列进行映射,再进行变换。
将源文件中的列值经变换后导入表中
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
表中有 k1,k2,k3,k4 4 列,导入映射和变换关系如下:
列 1 -> k1
列 2 * 100 -> k3
列 3 -> k2
列 4 -> k4
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, tmp_k3, k2, k4, k3 = tmp_k3 * 100" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp_k3, k2, k4)
SET (
k3 = tmp_k3 * 100
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp_k3, k2, k4, k3 = tmp_k3 * 100),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
查询结果
mysql> select * from example_table;
+------+-----------+-------+------+
| k1 | k2 | k3 | k4 |
+------+-----------+-------+------+
| 1 | beijing | 10000 | 1.1 |
| 2 | shanghai | 20000 | 1.2 |
| 3 | guangzhou | 30000 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+-------+------+
通过 case when 函数,有条件的进行列变换
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
表中有 k1,k2,k3,k4 4 列。对于源数据中 beijing, shanghai, guangzhou, chongqing 分别转换为对应的地区 id 后导入:
列 1 -> k1
列 2 -> k2
列 3 进行地区 id 转换后 -> k3
列 4 -> k4
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, tmp_k3, k4, k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, tmp_k3, k4)
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_k3, k4, k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
查询结果
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 3 | 300 | 3 | 1.3 |
| 4 | NULL | 4 | 1.4 |
+------+------+------+------+
源文件中的 NULL 值处理
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
表中有 k1,k2,k3,k4 4 列。在对地区 id 转换的同时,对于源数据中 k1 列的 null 值转换成 0 导入:
列1 -> k1
列2 如果为null 则转换成0 -> k2
列3 -> k3
列4 -> k4
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, tmp_k2, tmp_k3, k4, k2 = ifnull(tmp_k2, 0), k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp_k2, tmp_k3, k4)
SET (
k2 = ifnull(tmp_k2, 0),
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp_k2, tmp_k3, k4, k2 = ifnull(tmp_k2, 0), k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
查询结果
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 3 | 300 | 3 | 1.3 |
| 4 | 0 | 4 | 1.4 |
+------+------+------+------+
前置过滤
前置过滤是在数据转换前对原始数据进行过滤的功能,可以提前过滤掉不需要处理的数据,减少后续处理的数据量,提高导入效率。该功能仅支持 Broker Load 和 Routine Load 两种导入方式。 前置过滤有以下应用场景:
- 转换前做过滤
希望在列映射和转换前做过滤的场景,能够先行过滤掉部分不需要的数据。
- 过滤列不存在于表中,仅作为过滤标识
比如源数据中存储了多张表的数据(或者多张表的数据写入了同一个 Kafka 消息队列)。数据中每行有一列表名来标识该行数据属于哪个表。用户可以通过前置过滤条件来筛选对应的表数据进行导入。
前置过滤有以下限制:
- 过滤列限制。
前置过滤只能对列表中的独立简单列进行过滤,无法对带有表达式的列进行过滤。如:在列映射为(a, tmp, b = tmp + 1)时,b 列无法作为过滤条件。
- 数据处理限制
前置过滤发生在数据转换之前,使用原始数据值进行比较,原始数据会视为字符串类型。如:对于 \N 这样的数据,会直接用 \N 字符串进行比较,而不会转换为 NULL 后再比较。
示例一:使用数值条件进行前置过滤
本示例展示如何使用简单的数值比较条件来过滤源数据。通过设置 k1 > 1 的过滤条件,实现在数据转换前过滤掉不需要的记录。
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
前置过滤条件为:
列1>1,即只导入 列1>1 的数据,其他数据过滤掉。
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
PRECEDING FILTER k1 > 1
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
PRECEDING FILTER k1 > 1
FROM KAFKA (...)
查询结果
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 2 | 200 | shanghai | 1.2 |
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+
示例二:使用中间列过滤无效数据
本示例展示如何处理包含无效数据的导入场景。
源数据为:
1,1
2,abc
3,3
建表语句
CREATE TABLE example_table
(
k1 INT,
k2 INT NOT NULL
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
对于k2列,类型为int,abc是不合法的脏数据,想要过滤该数据,可以引入中间列来过滤。
导入语句
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp, k2 = tmp)
PRECEDING FILTER tmp != "abc"
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp, k2 = tmp),
COLUMNS TERMINATED BY ","
PRECEDING FILTER tmp != "abc"
FROM KAFKA (...);
导入结果
mysql> select * from example_table;
+------+----+
| k1 | k2 |
+------+----+
| 1 | 1 |
| 3 | 3 |
+------+----+
后置过滤
后置过滤在数据转换后执行,可以根据转换后的结果进行过滤。
在列映射和转换缺省的情况下,直接过滤
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
表中有 k1,k2,k3,k4 4 列,在缺省列映射和转换的情况下,只导入源文件中第 4 列为大于 1.2 的数据行。
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, k3, k4" \
-H "where: k4 > 1.2" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
where k4 > 1.2
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
WHERE k4 > 1.2;
FROM KAFKA (...)
查询结果
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+
对经过列变换的数据进行过滤
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
表中有 k1,k2,k3,k4 4 列。在列变换示例中,我们将省份名称转换成了 id。这里我们希望过滤掉 id 为 3 的数据
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, tmp_k3, k4, k3 = case tmp_k3 when 'beijing' then 1 when 'shanghai' then 2 when 'guangzhou' then 3 when 'chongqing' then 4 else null end" \
-H "where: k3 != 3" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, tmp_k3, k4)
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
WHERE k3 != 3
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_k3, k4),
COLUMNS TERMINATED BY ","
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
WHERE k3 != 3;
FROM KAFKA (...)
查询结果
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 4 | NULL | 4 | 1.4 |
+------+------+------+------+
多条件过滤
假设有以下源数据(表头列名仅为方便表述,实际并无表头):
列 1,列 2,列 3,列 4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
表中有 k1,k2,k3,k4 4 列。过滤掉 k1 列为 null 的数据,同时过滤掉 k4 列小于 1.2 的数据
创建示例表
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
导入数据
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, k3, k4" \
-H "where: k1 is not null and k4 > 1.2" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
where k1 is not null and k4 > 1.2
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
WHERE k1 is not null and k4 > 1.2
FROM KAFKA (...);
查询结果
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+