产品概念
本文档介绍 Apache Doris 的核心产品概念,是理解其他文档的基础。这些概念涵盖了数据组织、存储模型、查询执行和查询优化等关键维度。
适用场景: 概念入门 · 阅读准备 · 技术预热
数据组织
Catalog / Database / Table
Apache Doris 采用 Catalog → Database → Table 三层层级结构来管理数据。
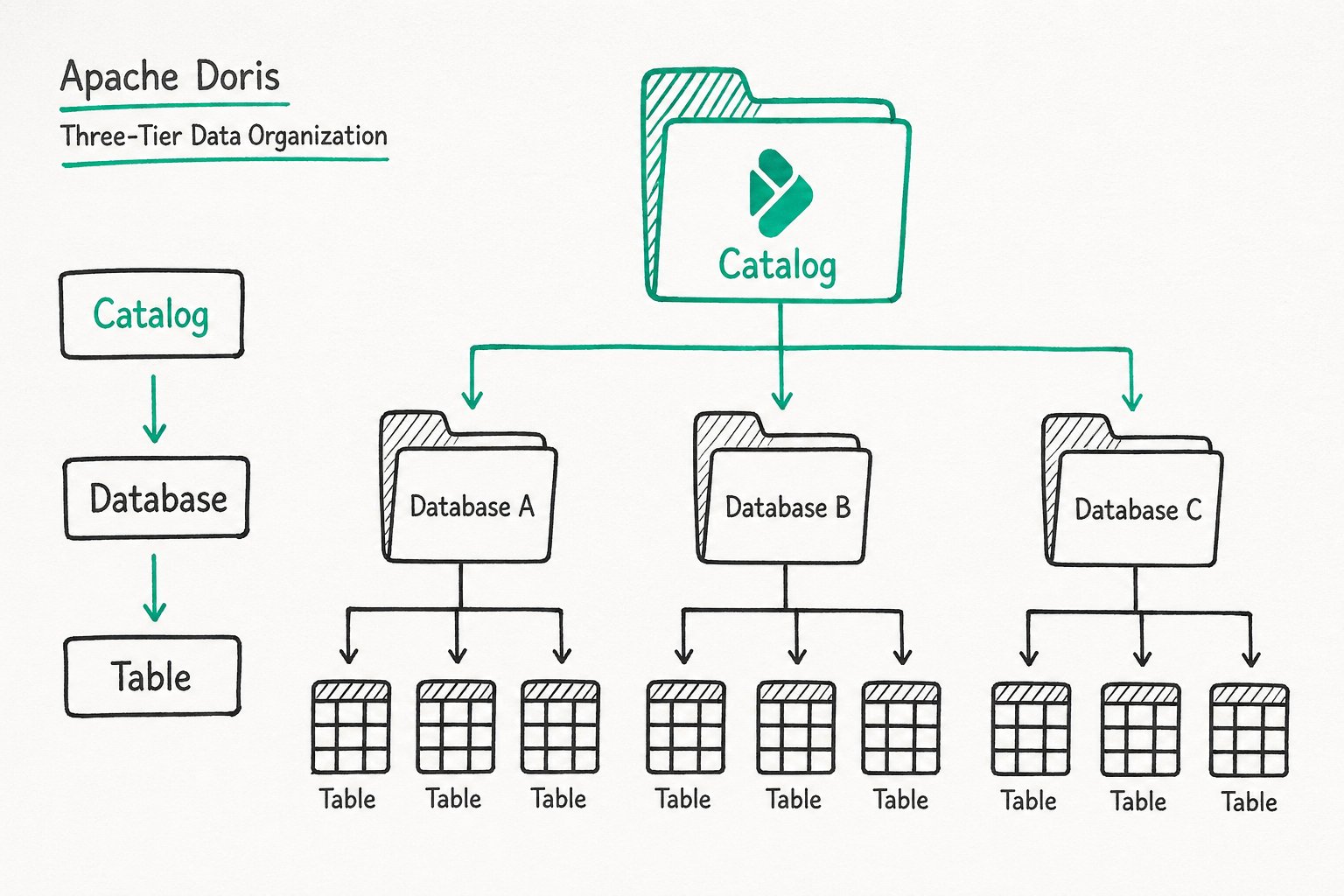
| 层级 | 说明 |
|---|---|
| Catalog | 逻辑命名空间,用于区分不同数据源。Doris 默认的 internal Catalog 即为内部存储,存放用户创建的 Database 和 Table。外部 Catalog 可对接 Hive、Iceberg、MySQL 等数据源,无需迁移即可跨源查询。 |
| Database | 数据库单元,用于隔离不同业务或项目的数据。可设置字符集、排序规则等属性。 |
| Table | 二维关系表,定义了数据的列结构(Schema)和表属性(分桶规则、生命周期等)。是数据存储和查询的基本单位。Doris 中的所有可查对象,都是以 Table 的形态呈现的。 |
为什么设计成三层?
层级设计实现了逻辑隔离与跨源统一访问的平衡。业务团队拥有独立的 Database,平台团队可以借助外部 Catalog 直接查询其他数据源的数据。
Internal Catalog(内部目录)
Internal Catalog 是 Doris 内置的默认 Catalog,名称固定为 internal,用于管理以 Doris 内部格式存储的表和数据。
职责:
- 存储所有用户创建的 Database(
CREATE DATABASE) - 存储所有用户创建的 Table(
CREATE TABLE) - 管理内部数据的导入、压缩、版本合并(Compaction)
用户执行 SHOW DATABASES 或 USE my_db 时,默认就是在 Internal Catalog 上下文中。
External Catalog(外部目录)
External Catalog 是对接外部数据源的逻辑组件,无需数据迁移即可直接查询外部数据。
| 外部数据源 | 说明 |
|---|---|
| Hive | 对接 Hive Metastore 或兼容 HMS 的数据湖 |
| Iceberg | 对接 Iceberg 表 |
| Paimon | 对接 Paimon 表 |
| JDBC | 对接 MySQL、PostgreSQL、OceanBase 等关系型数据库 |
针对 Iceberg 和 Paimon 的特别说明:
这两个数据源支持完整的数据管理能力,包括 DDL 操作(CREATE/DROP/ALTER TABLE)和 DML 操作(INSERT/UPDATE/DELETE),而不仅限于查询。用户可以在 Doris 中直接管理 Iceberg/Paimon 表结构,并执行数据写入。
使用场景:
- 数据湖分析:直接分析 Hive/Iceberg/Paimon 数据,无需 ETL
- 跨源查询:一张 SQL 中同时查询 Iceberg 数据源和 Doris 的数据
使用方式: 创建 External Catalog 后,可通过 SELECT * FROM catalog.database.table 直接查询。也可以通过 SWITCH catalog 切换对应的 Catalog。
Internal Catalog vs. External Catalog
| 对比项 | Internal Catalog | External Catalog |
|---|---|---|
| 名称 | 固定为 internal | 用户自定义命名 |
| 数据格式 | Doris 内部格式(列式存储) | 外部数据源格式(Parquet、ORC 等) |
| 数据存储位置 | BE 节点本地或对象存储 | 外部系统(HDFS、S3、Hive Metastore 等) |
| 创建方式 | CREATE DATABASE / CREATE TABLE | CREATE EXTERNAL CATALOG |
| 查询性能 | 高(数据本地) | 取决于外部数据源。Doris 也内置多种加速手段 |
| DDL/DML 支持 | 完整支持 | Iceberg/Paimon 完整支持;Hive/JDBC 仅支持查询 |
| 数据写入 | 支持(Stream Load 等) | 仅 Iceberg/Paimon 支持 |
分区和分桶(Partition & Bucket)
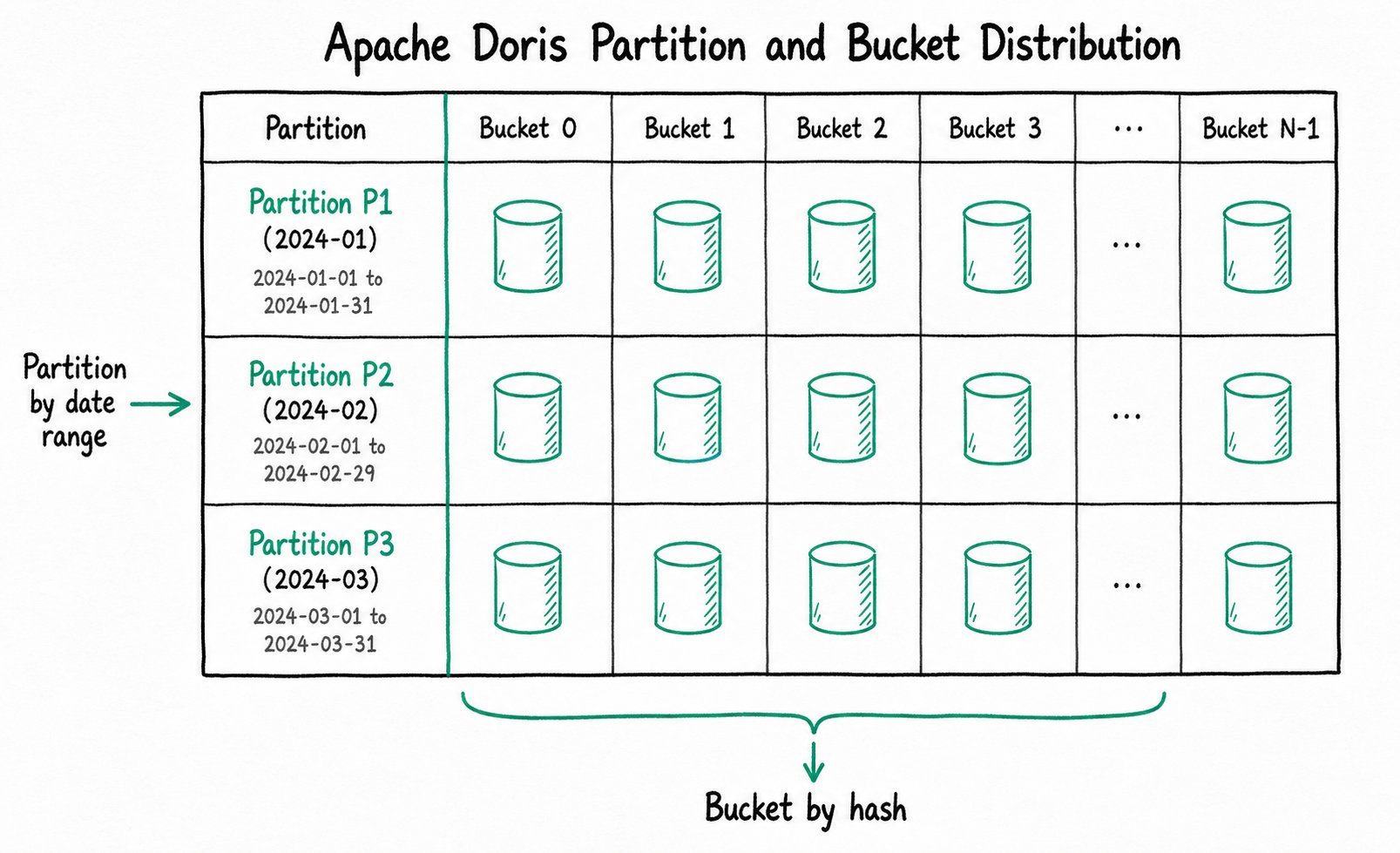
分区是将表中数据按某一列的值范围进行水平切分。一个表可以包含一个或多个分区,每个分区对应一段连续的数据区间。
典型用途:
- 按时间分区(按天/月/年),支持分区裁剪和历史数据管理
- 按地域或业务线分区,实现数据隔离
示例: 一张日志表按 date 列按天分区
Partition p20240101: date = '2024-01-01' 的数据
Partition p20240102: date = '2024-01-02' 的数据
Partition p20240103: date = '2024-01-03' 的数据
查询 WHERE date = '2024-01-02' 时,Doris 只扫描 p20240102 分区,跳过其他分区,大幅减少 I/O。
分桶是将表中数据按某一列的 Hash 值或桶数量进行水平切分,决定了数据在集群内的物理分布。
分桶对应的物理存储叫数据分片(Tablet),是最小的存储逻辑单元。
| 概念 | 说明 |
|---|---|
| 分桶键(Distribution Key) | 用于计算数据所属桶的列,通常选择高基数的列(如主键 ID)。 |
| 桶数量(Bucket Num) | 一个分区的物理分桶数,决定了数据并行度。 |
分桶 vs. 分区的区别:
| 维度 | 分区 | 分桶 |
|---|---|---|
| 划分依据 | 列值范围 | Hash 计算 |
| 用途 | 数据生命周期管理、分区裁剪 | 数据并行分布、JOIN 优化 |
| 层级关系 | 分区包含分桶 | 分桶属于分区 |
分区定义了数据的逻辑边界(如时间范围),分桶定义了数据的物理分布(如集群节点间的数据分散)。
存储模型
列式存储(Columnar Storage)
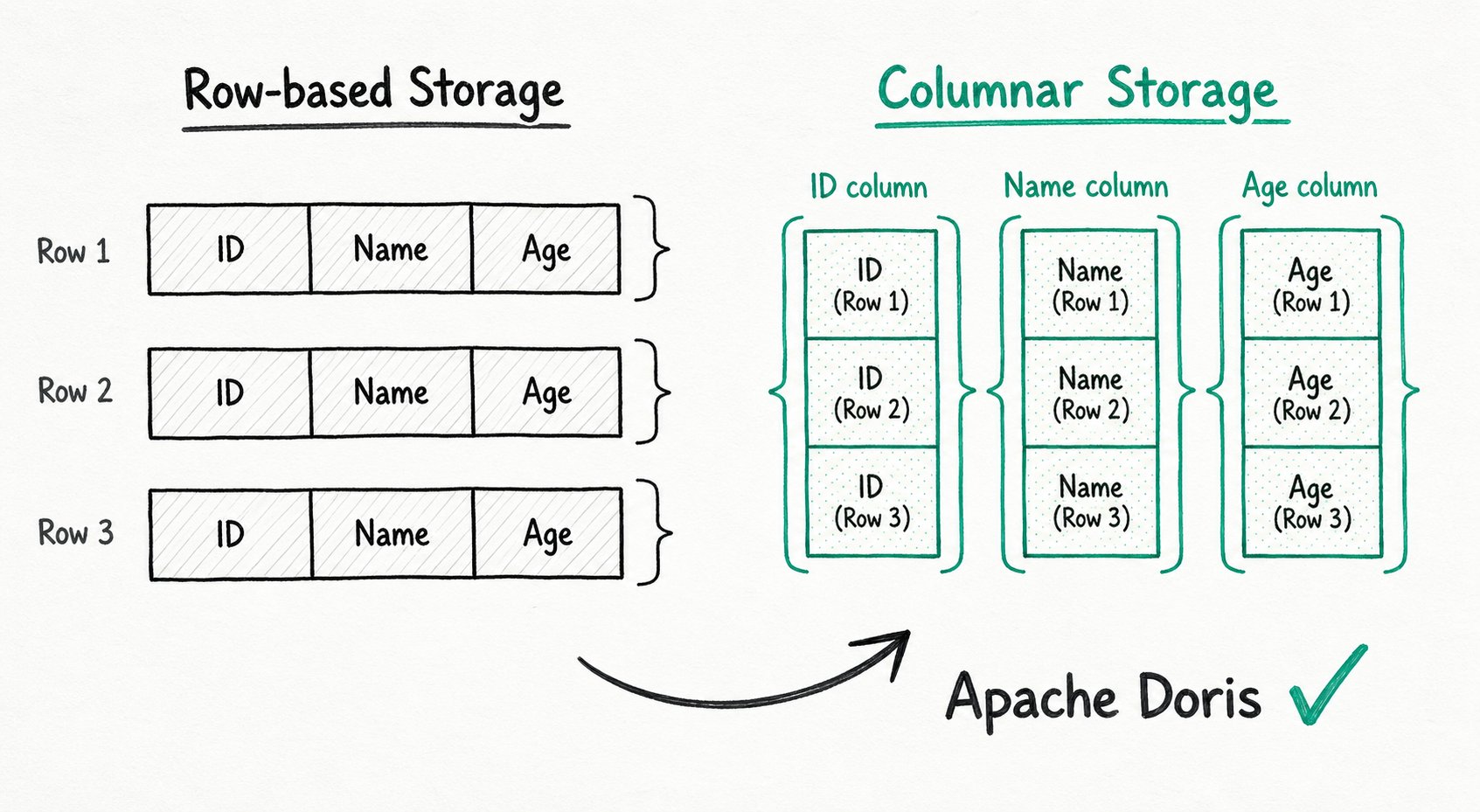
列式存储是将数据按列而非按行组织存放的格式。
行式存储 vs. 列式存储:
行式存储(一行连续存放):
[row1: id=1, name=alice, age=30] [row2: id=2, name=bob, age=25] ...
列式存储(一列连续存放):
[id列: 1, 2, 3, ...] [name列: alice, bob, carol, ...] [age列: 30, 25, 28, ...]
列式存储的优势:
| 优势 | 说明 |
|---|---|
| I/O 效率高 | 查询时只读取需要的列,避免扫描全表数据。对于只有几列的报表查询,I/O 可降低数十倍。 |
| 压缩率高 | 同一列数据类型一致,适合字典编码、位图压缩、RLE 等算法,存储空间大幅降低。 |
| 向量化友好 | 同列数据连续内存存放,CPU 缓存命中率高,配合 SIMD 指令实现高速计算。 |
数据模型
Doris 支持三种数据模型,用于处理不同业务场景的数据合并需求。
| 模型 | 说明 | 适用场景 |
|---|---|---|
| 明细模型(Duplicate) | 保留所有原始数据,相同主键的多条记录全部保留。 | 事实表明细存储、日志分析 |
| 聚合模型(Aggregate) | 相同主键的数据按聚合函数合并(如 SUM、MAX、MIN)。 | 指标统计、报表预聚合 |
| 主键模型(Primary Key) | 主键唯一,相同主键的记录会覆盖(支持行级更新)。 | 实时更新、CDC 数据入库 |
示例:
假设有以下原始数据(主键为 user_id):
| user_id | visit_date | pv |
|---|---|---|
| 1 | 2024-01-01 | 5 |
| 1 | 2024-01-01 | 3 |
| 2 | 2024-01-01 | 10 |
- 明细模型:保留所有 3 条记录
- 聚合模型(按 SUM 聚合):相同主键的
pv合并 → user_id=1 的 pv=8,user_id=2 的 pv=10 - 主键模型:相同主键的记录按时间戳覆盖,最终只保留最新的一条(如
pv=3覆盖pv=5)
查询执行
MPP(Massively Parallel Processing)
MPP 是大规模并行处理架构,用于执行复杂查询。
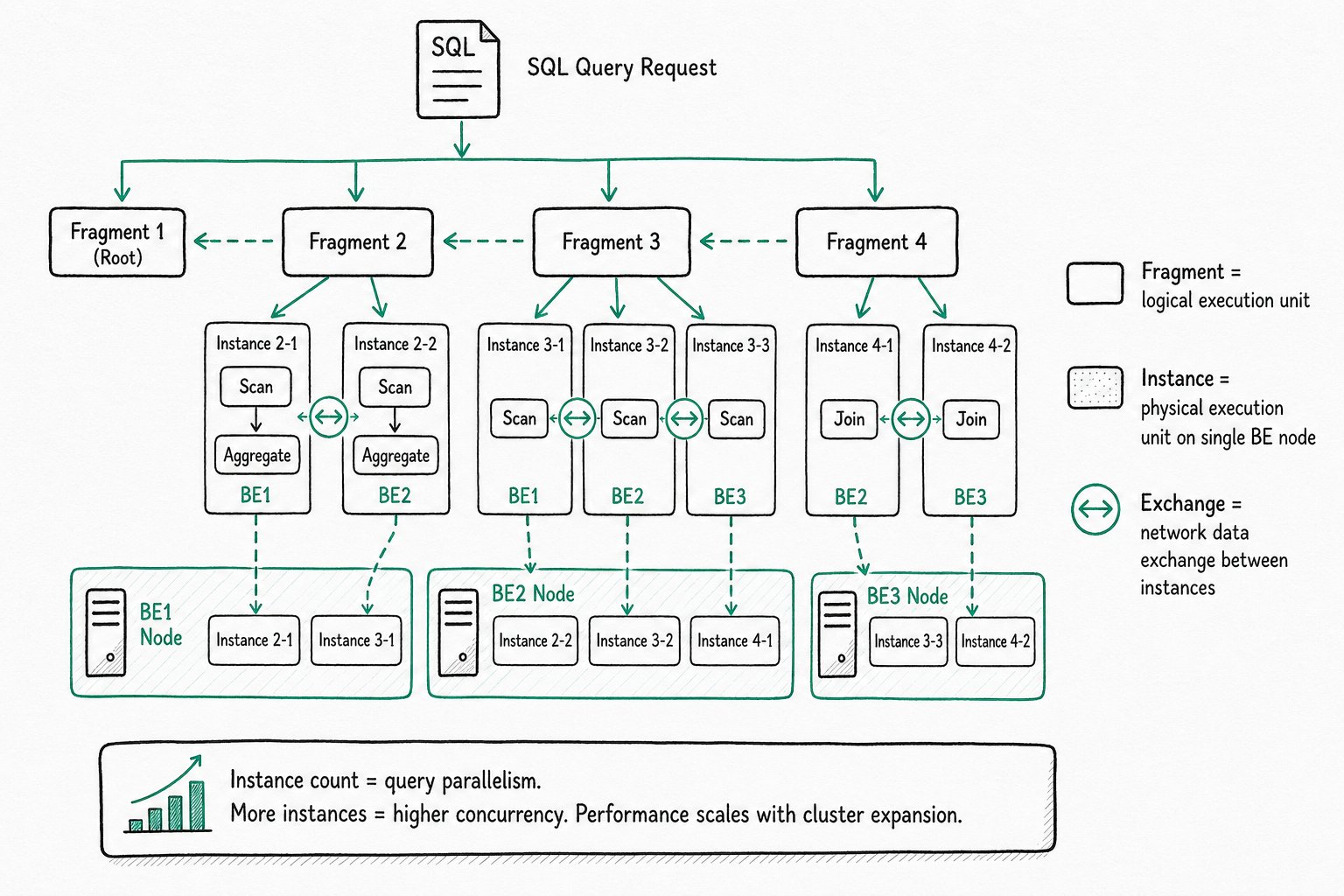
核心概念:
| 概念 | 说明 |
|---|---|
| Fragment | 逻辑执行单元,一个查询计划由多个 Fragment 组成 |
| Instance | 物理执行单元,由一组可在单个 BE 节点上执行的算子组成(如 Scan、Agg、Join) |
| Exchange | Instance 之间的网络数据交互算子 |
工作原理:
- FE 解析 SQL 并生成逻辑执行计划
- 计划拆分为多个 Fragment(逻辑执行单元)
- 每个 Fragment 实例化一个或多个 Instance,分发到多个 BE 节点并行执行
- 不同 Instance 之间通过 Exchange 算子进行网络数据交互
- 各节点执行完成后,结果在 FE 汇总
Instance 与并行度:
Instance 是查询的物理执行单元,运行在单个 BE 节点上,包含一组算子(Scan → Agg → Join 等)。Instance 的数量即为查询的并行度,数量越多并发度越高。每个执行节点拥有独享的资源(CPU、内存),单个查询请求可以充分利用所有执行节点的资源,因此查询性能可以随集群水平扩展而不断提升。
适用场景: 大表 JOIN、GROUP BY、ORDER BY 等需要跨节点数据交换的操作。
向量化执行引擎(Vectorized Execution)
向量化执行是一种按列批量处理数据的执行方式,结合 SIMD 指令实现计算加速。
传统行式执行 vs. 向量化执行:
| 维度 | 行式执行 | 向量化执行 |
|---|---|---|
| 处理单位 | 一次一行 | 一次一列(一批) |
| CPU 缓存 | 随机访问,缓存命中率低 | 顺序访问,缓存命中率高 |
| SIMD 指令 | 难以利用 | 充分发挥 |
| 聚合性能 | 基准 | 5~10x 提升 |
核心思想: 将算子的内层循环从"处理一行"变为"处理一列(一批数据)",减少函数调用开销,提高 CPU 利用率。
Pipeline 执行引擎(Pipeline Engine)
Pipeline 是一种多核并行的执行模型,通过流水线并行最大化利用多核资源。
解决的问题:
- 线程爆炸:传统模型为每个查询分配固定线程,查询激增时线程数失控
- 资源竞争:固定线程池导致查询间资源争抢
Pipeline 的特点:
| 特性 | 说明 |
|---|---|
| 线程数限制 | 并行度受 CPU 核数限制,而非查询数限制 |
| 算子链式调度 | 上下游算子形成流水线,数据连续流动 |
| 减少阻塞 | 减少线程切换和锁竞争,提升吞吐 |
在单次查询内,多个算子形成流水线并行;在集群层面,多个查询共享 CPU 资源,实现高效的多租户调度。
查询优化
物化视图(Materialized View)
物化视图是一种预计算技术,将查询结果存储为物理表,在数据导入时自动同步更新。
核心价值:
| 特性 | 说明 |
|---|---|
| 查询改写 | 用户查询原始表时,优化器自动判断是否可以透明改写为查询物化视图,用户无需修改 SQL |
| 自动同步 | 物化视图跟随原始表数据自动更新,无需人工维护 |
| 替代 ETL | 可替代传统的定时 ETL 流程,实现实时加速 |
适用场景:
- 大表聚合查询(如报表汇总)
- 数仓分层建模(事实表 → 汇总表)
- 预计算复杂 JOIN 结果
CBO(Cost-Based Optimizer)
CBO 是基于成本评估的查询优化器,会评估每种执行计划的资源消耗(I/O、CPU、网络),选择成本最低的计划。
CBO 优化的典型场景:
| 优化项 | 说明 |
|---|---|
| Join 顺序 | 多表 JOIN 时,评估不同顺序的成本,选择最优 |
| Join 算法 | 根据数据量选择 Hash Join / Nest Loop Join / Broadcast Join |
| 分布式执行 | 决定在哪些节点执行、是否需要 Shuffle |
为什么需要 CBO? SQL 只描述"做什么",不关心"怎么做"。同样的查询,数据量不同时最优执行方式可能完全不同。CBO 通过统计信息(行数、列基数、NDV 等)评估成本,选择最高效的执行路径。
RBO(Rule-Based Optimizer)
RBO 是基于规则优化的优化器,按照预定义规则对逻辑计划进行改写,不考虑实际数据特征。
典型优化规则:
| 规则 | 说明 |
|---|---|
| 常量折叠 | 1 + 2 → 3 |
| 谓词下推 | JOIN 前过滤条件先执行,减少中间结果 |
| 子查询改写 | 展平嵌套子查询为 JOIN |
| 公共表达式复用 | 多次出现的相同表达式只计算一次 |
CBO vs. RBO: RBO 确定性高、规则简单,适合规则固定的场景;CBO 更智能,能根据数据特征优化,但依赖统计信息准确性。 Doris 同时使用两者,RBO 处理确定性优化,CBO 处理复杂计划选择。
Runtime Filter
Runtime Filter 是查询执行时动态生成的过滤条件,下推到扫描节点,在数据读取阶段就进行过滤。
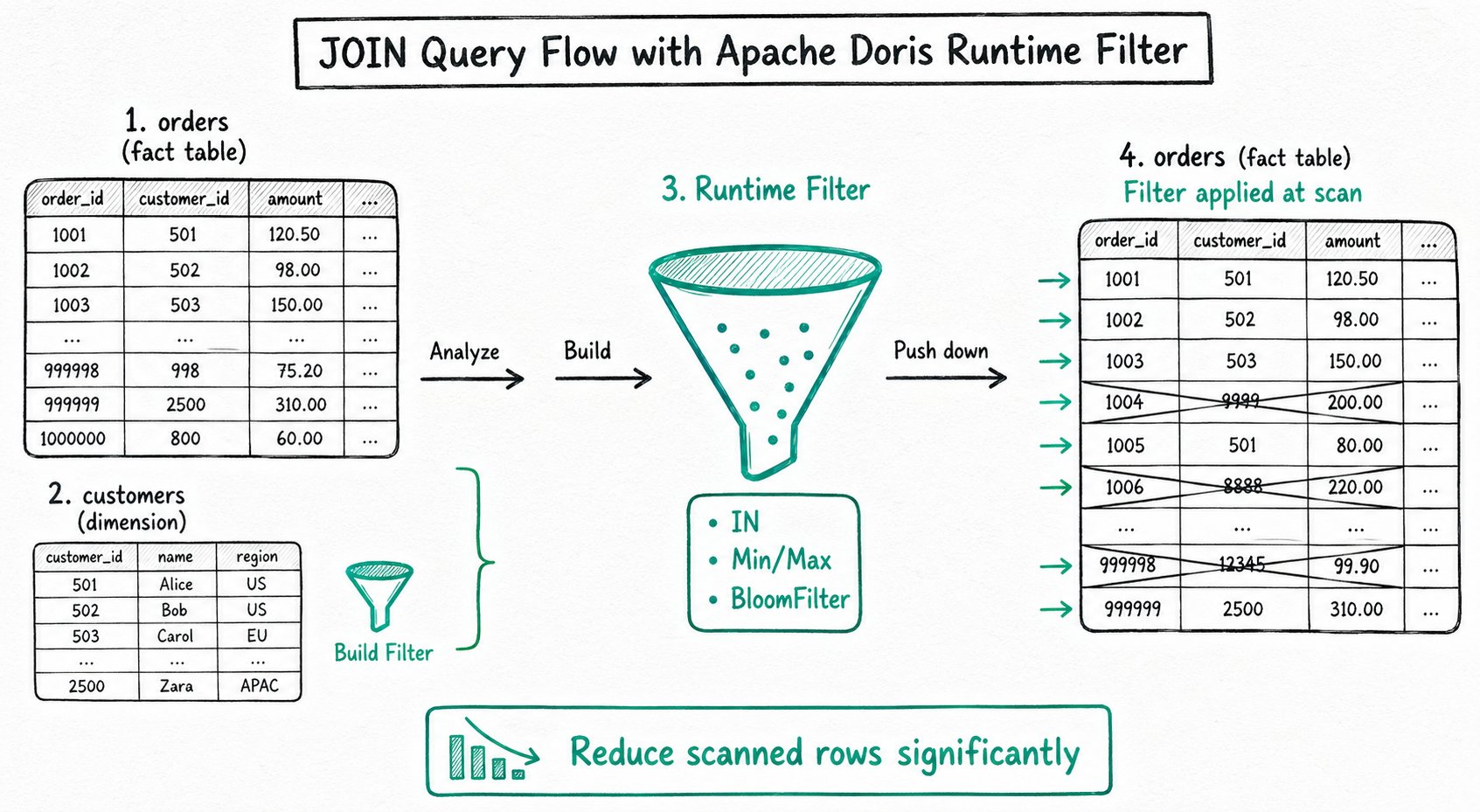
工作原理:
JOIN 时,假设大表 orders 和小表 customers 按 customer_id JOIN:
1. FE 分析小表,构建 Filter(如 customer_id IN {1, 5, 9})
2. 下推到扫描大表的节点
3. 读取大表数据时立即过滤,不符合条件的数据跳过处理
4. 减少 I/O 和后续算子的计算量
RF 类型:
| 类型 | 适用场景 |
|---|---|
| IN | 小表 JOIN 大表,等值 JOIN |
| Min/Max | 范围 JOIN,数据分布连续 |
| BloomFilter | 高基数列,等值 JOIN |
效果: 在星型模型中,大表 fact JOIN 小表 dimension 时,Runtime Filter 可将大表扫描量降低数倍至数十倍。
常见问题
Q: 分区和分桶有什么区别?
分区按列值范围划分,用于数据生命周期管理(如按天分区删除历史数据)和分区裁剪(查询时只扫描相关分区)。分桶按 Hash 计算数据分布,用于数据并行和 JOIN 优化。分区是逻辑概念,分桶是物理概念(决定数据分布到哪个 BE 节点)。
Q: 什么情况下应该选择主键模型而不是明细模型?
当你需要行级更新(如实时数据入库、CDC 同步)或希望相同主键合并时,选择主键模型。明细模型保留所有原始数据,适合日志分析和全量明细查询场景。
Q: MPP 和 Pipeline 是什么关系?
它们是两个不同维度的并行机制。MPP 是分布式并行,解决跨节点并行计算问题;Pipeline 是节点内并行,解决多核资源利用问题。两者结合实现"节点间并行 + 节点内流水线"的全链路并行。
Q: CBO 和 RBO 的统计信息从哪里来?
Doris 通过 ANALYZE 命令收集表和列的统计信息,包括表行数、列基数(NDV)、NULL 比例等。CBO 依赖这些统计信息进行成本评估。统计信息越准确,优化效果越好。建议在数据量变化较大后重新 ANALYZE。
Q: External Catalog 和普通 Database 有什么区别?
普通 Database 的数据存储在 Doris 内部,而 External Catalog 只是逻辑映射,实际数据仍存储在外部数据源。Doris 通过 External Catalog 直接读取外部数据,无需 ETL 迁移。常见用法是查询数据湖(Hive/Iceberg/Hudi)和跨源查询(MySQL、PostgreSQL 等)。
Q: 物化视图和普通视图有什么区别?
普通视图只是存储 SQL 查询逻辑,每次查询时实时计算,无性能收益。物化视图将查询结果物理存储下来,数据同步更新,对用户查询透明加速。物化视图适合固定模式的聚合报表场景。
延伸阅读
- [TODO] - 了解存算一体和存算分离架构
- [TODO] - 深入理解 CBO 和执行计划