Apache Doris 概述
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库,以高效、简单、统一著称:在亚秒级时间内返回海量数据查询结果,一套系统同时支持高并发点查询和高吞吐复杂分析。
核心亮点
| 能力 | 数据 |
|---|---|
| 查询延迟 | < 1 秒(亚秒级响应) |
| 写入延迟 | 秒级(实时数据入库) |
| 并发能力 | 10,000+ QPS |
| 存储规模 | PB 级 / 单集群数百台机器 |
| SQL 接口 | MySQL 协议兼容层,ANSI SQL 语法 |
典型使用场景
Apache Doris 广泛应用于以下三大类场景:
实时数据分析
企业内外部实时报表、仪表盘、用户行为分析、AB 实验平台、日志检索分析。
代表案例:
- 实时大屏看板:双十一订单量实时监控,秒级更新
- 用户画像分析:人群圈选与精准营销
- 日志检索分析:问题定位与性能优化
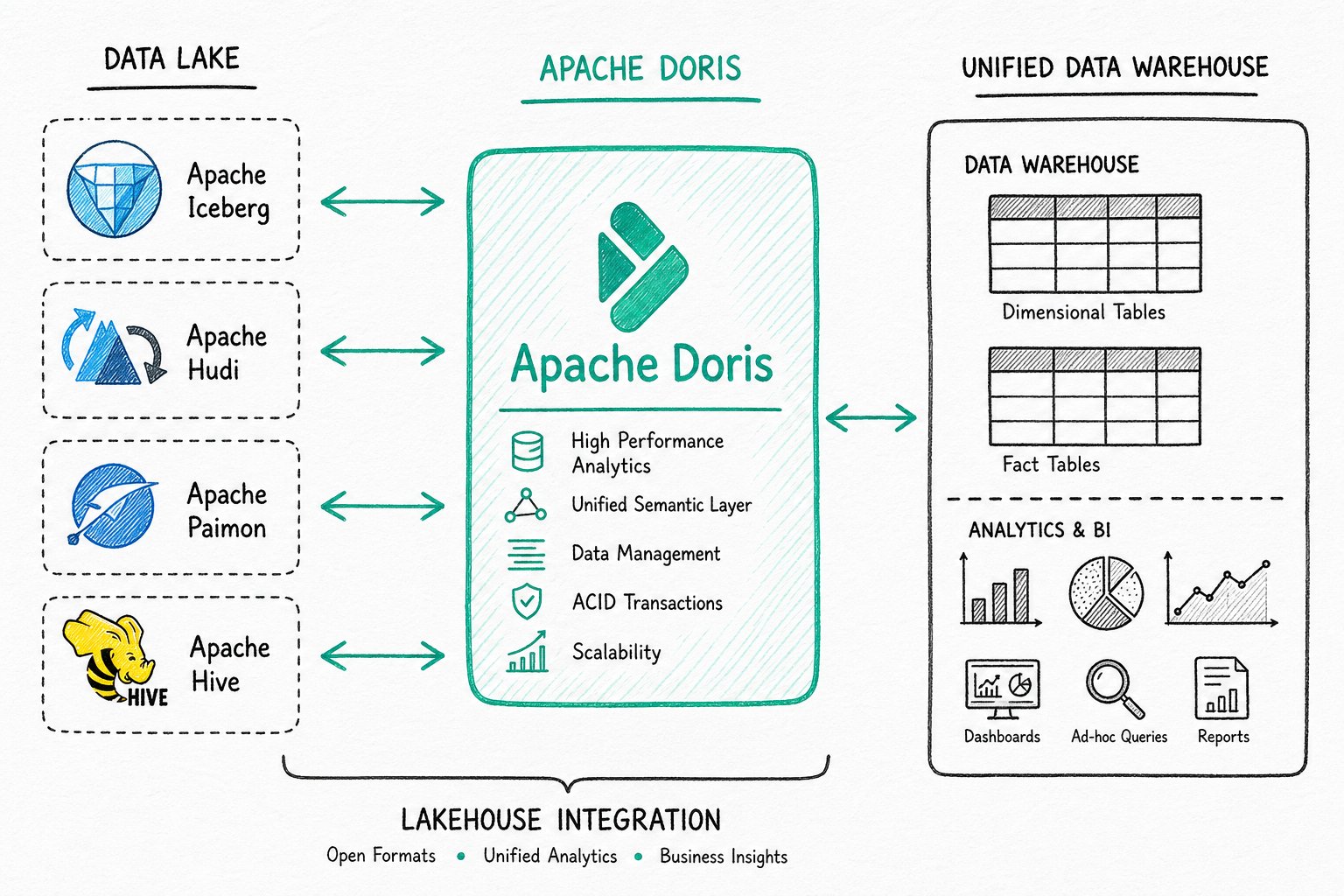
湖仓融合分析
统一数仓构建、数据湖联邦查询加速、混合负载分析。
混合检索分析(AI 数据栈)
在大模型时代,Apache Doris 深度融合文本搜索、向量搜索、AI 函数能力,构建从数据存储、检索到分析的完整 AI 数据栈。
| 场景 | 说明 |
|---|---|
| Agent Facing Analytics | AI Agent 毫秒级实时决策(反欺诈检测、智能推荐) |
| 混合检索与分析 | 同时执行向量相似度搜索 + 关键词过滤 + 聚合分析,一条 SQL |
| RAG 应用 | 企业知识库问答、智能客服、文档助手 |
| 语义搜索 | 跨语言检索、同义词识别、意图理解 |
| AI 可观测性 | 模型训练监控、推理追踪、日志分析 |
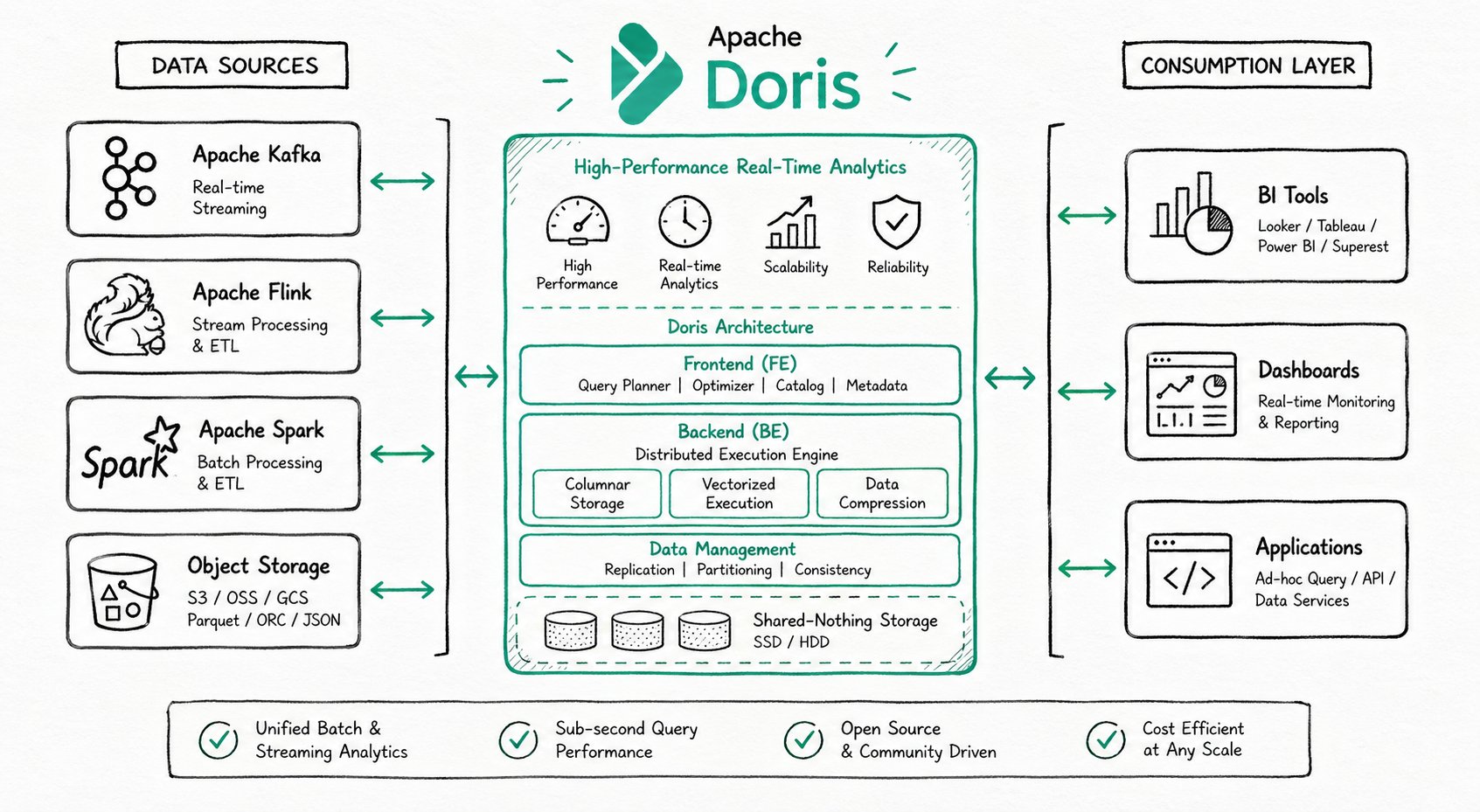
系统架构
Apache Doris 高度兼容 MySQL 协议,支持标准 SQL,可通过各类客户端工具访问,与 BI 工具无缝集成。部署 Apache Doris 时,可以根据业务需求选择存算一体架构或存算分离架构。
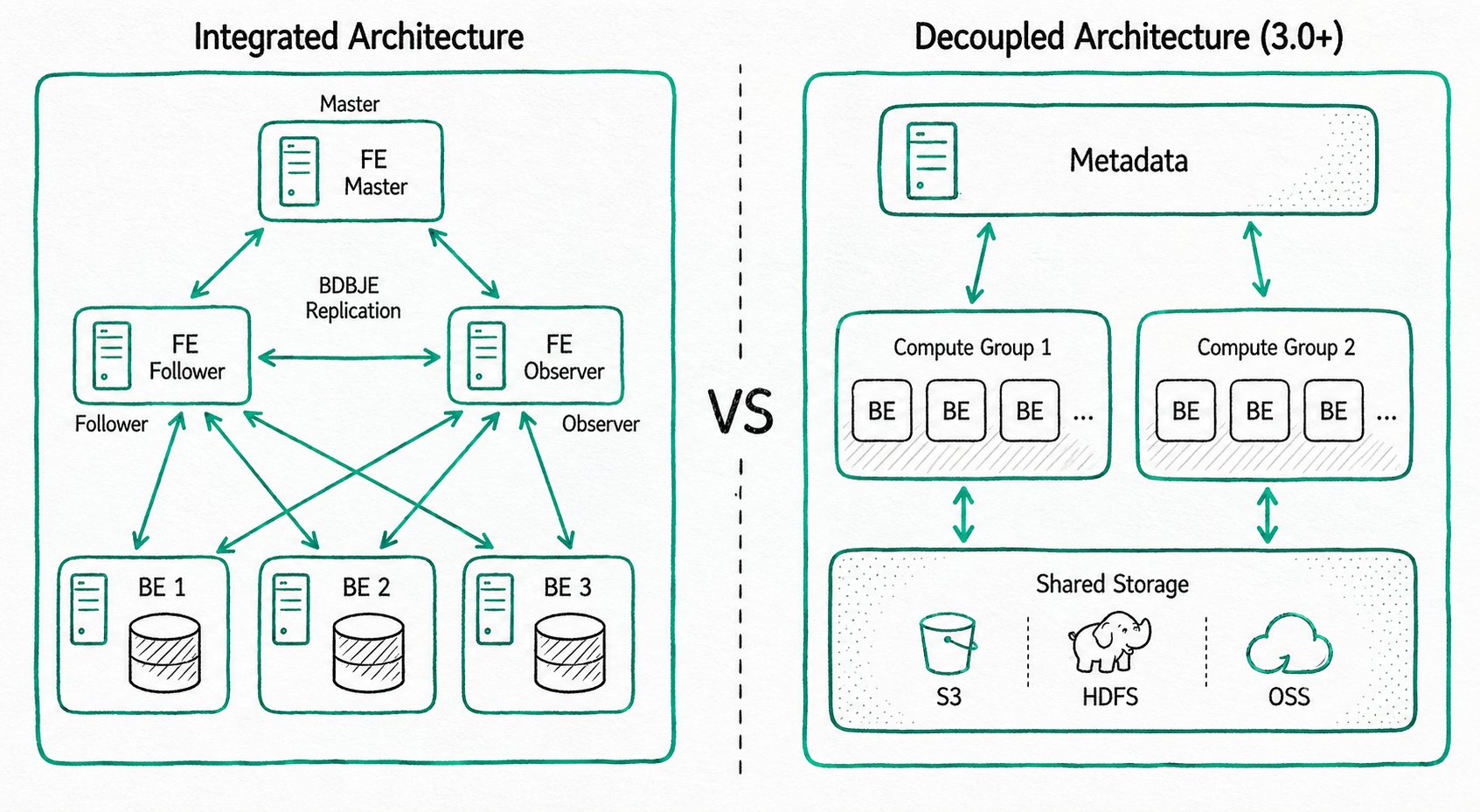
存算一体架构
精简架构,包含两类进程:
- Frontend (FE):接收请求、查询解析、元数据管理、节点管理
- Backend (BE):数据存储、查询执行(多副本存储)
生产环境部署多个 FE 节点实现高可用,FE 节点分为 Master、Follower、Observer 三种角色。
存算分离架构(共享存储)
存储和计算分离,独立扩展存储容量和计算资源:
- 计算层:多个计算组,每组可作为独立租户
- 存储层:S3/HDFS/OSS 等共享存储
如何选择:业务规模可控、追求简单运维 → 存算一体;需要弹性扩缩容 → 存算分离。
技术特点
存储引擎
Apache Doris 采用列式存储技术,按列进行数据的编码、压缩和读取,实现极高的压缩比的同时减少大量非相关数据的扫描,从而更有效地利用 IO 和 CPU 资源。Doris 针对超宽表(10000+ 列)场景做了深度优化,确保稀疏列的高效存储与查询。为满足不同业务场景需求,Doris 提供多种索引结构(Sorted Compound Key、Min/Max、BloomFilter、倒排索引、向量索引)和存储模型(明细模型、聚合模型、主键模型),并支持强一致的单表物化视图和异步刷新的多表物化视图。
- 列式存储:按列编码、压缩、读取,高压缩比 + 减少 IO
- 多种索引:Sorted Compound Key、Min/Max、BloomFilter、倒排索引、向量索引
- 存储模型:明细模型、聚合模型、主键模型(支持行级别更新)
- 物化视图:单表强一致物化视图 + 多表异步物化视图
向量索引和倒排索引是支持 Hybrid Search(混合检索与分析)的核心技术,详见 AI 概述。
查询引擎
Apache Doris 查询引擎基于 MPP(大规模并行处理)架构,支持节点间和节点内并行执行,以及多个大型表的分布式 Shuffle Join。在复杂多表关联(Join)场景中,Doris 通过全局查询规划、分布式 Join 策略和运行时过滤(Runtime Filter)技术,大幅减少数据传输量,加速 Join 性能。Doris 采用向量化执行技术,所有内存结构按列式布局,可显著减少虚函数调用、提高缓存命中率并有效利用 SIMD 指令,在宽表聚合场景下性能提升 5-10 倍。结合自适应查询执行(AQE)和 Pipeline 执行引擎,根据运行时统计信息动态优化执行计划,充分利用多核 CPU 能力。
- MPP 架构:节点间/节点内并行执行,大表分布式 Shuffle Join
- 向量化执行:内存结构列式布局,SIMD 指令,5-10x 性能提升
- 自适应查询执行 (AQE):Runtime Filter 动态优化 Join
- Pipeline 执行引擎:多核 CPU 并行,限制线程数解决膨胀
混合检索能力(AI 增强)
Apache Doris 在单条 SQL 中融合结构化分析 + 全文检索 + 向量搜索能力,一套系统同时支持向量相似度搜索、关键词过滤和聚合分析,无需数据迁移和异构系统集成。结合 VARIANT 类型原生支持动态 JSON 结构和 Light Schema Change 秒级变更字段能力,为 RAG 应用、语义搜索、企业知识库等 AI 场景提供高效的数据支撑。
SELECT * FROM products
WHERE match(query_vector, 'summer breathable shoes') -- Vector similarity search
AND body MATCH 'breathable lightweight' -- Full-text keyword search
AND category_id = 1 -- Structured filtering
GROUP BY brand
ORDER BY sales_count DESC;
- 一体化架构:无需数据迁移,无需异构系统
- 混合查询性能:单 SQL 同时执行向量 + 关键词 + 聚合
- VARIANT 类型:原生支持动态 JSON,Light Schema Change 秒级变更
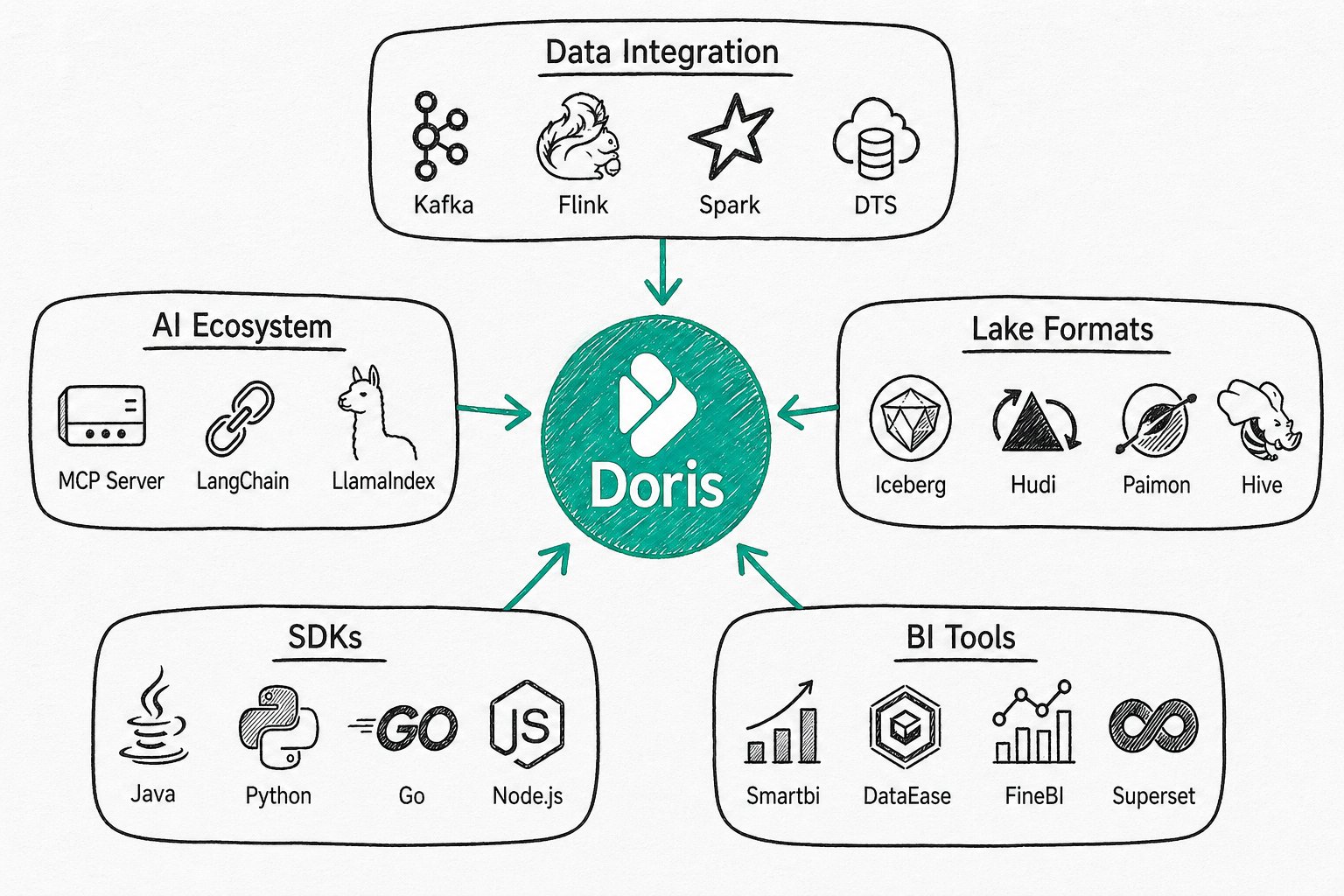
生态集成
Apache Doris 与主流数据生态深度集成。