Apache Doris vs ClickHouse
Apache Doris 和 ClickHouse 都是全球领先的实时分析型数据库,均支持列式存储与极速查询。Apache Doris 在三个关键领域具有显著优势:Join 查询性能提升 2-10 倍(基于先进的 MPP 架构与基于成本的查询优化器)、通过存算分离降低高达 70% 的基础设施成本(支持计算与存储资源独立扩缩)、以及卓越的实时更新性能(写时合并引擎在高频数据更新时仍能保持稳定的查询性能)。
精选案例
"利用 Apache Doris 替换 ClickHouse 后,快手成功升级为湖仓一体架构,实现统一存储并简化数据链路,无需数据导入,Doris 可直接访问湖仓数据。结合 Doris 的物化视图改写与自动物化服务,实现了高性能查询与灵活的数据治理。"
亮点:
- 直接查询数据湖数据,缩短数据链路
- 查询性能提升,满足多场景查询加速
- 借助物化视图,实现更灵活数据治理
"内容库数据平台经过分析引擎从 ClickHouse 到 Apache Doris 的替换、数据架构语义层的初步引入到深度应用,有效提高了数据时效性、降低了运维成本、解决了数据管理割裂等问题。"
亮点:
- 具备多表查询和联邦查询性能特性
- 兼容 MySQL 协议,降低运维成本
- 支持部分列更新,满足多种数据更新方式
"我们用 Apache Doris 替换了 ClickHouse,构建了新的日志平台,目前规模已达 50 台服务器、2PB 数据量。此次架构升级后,系统在查询响应、并发处理、稳定性及运维效率等多方面均取得了显著提升。"
亮点:
- 全文检索性能提升 3-7 倍
- 峰值写入吞吐达 6GB/s
- 支持 500+ 并发查询,较 ClickHouse 提升超 2 倍
为什么选择 Apache Doris
| Apache Doris | ClickHouse | |
|---|---|---|
| 系统架构 |
|
|
| Join 查询性能 |
|
|
| 实时更新 |
|
|
| 事务支持 |
|
|
| 查询并发 |
|
|
| 数据 API |
|
|
| 湖仓能力 |
|
|
| 运维 |
|
|
| 性能测试 |
|
|
| 成本效益(存算分离) |
|
|
| 开源协议 |
|
|
性能对比
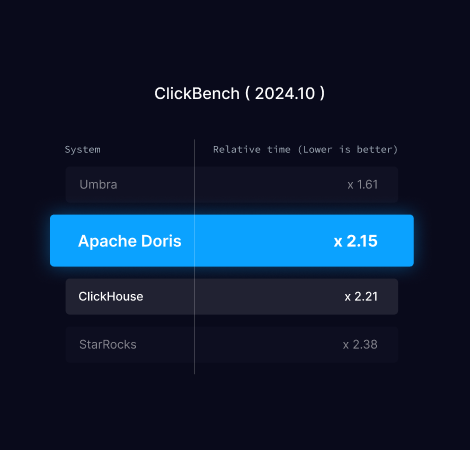
ClickBench 性能测试
ClickBench 是专用于评估分析型数据库性能的基准测试工具,其核心验证场景聚焦于海量宽表处理效能,而非复杂多表关联场景。该性能测试采用头部网络分析平台真实业务数据构建,覆盖点击流分析、结构化日志处理等典型 OLAP 应用场景。
测试体系由特定查询集合构成,重点验证聚合运算能力与单表处理性能(不涉及复杂表关联操作),因此该测试成为评估实时数据库的标准之一,尤其适用于验证系统在 PB 级数据规模下的数据处理与实时分析能力。
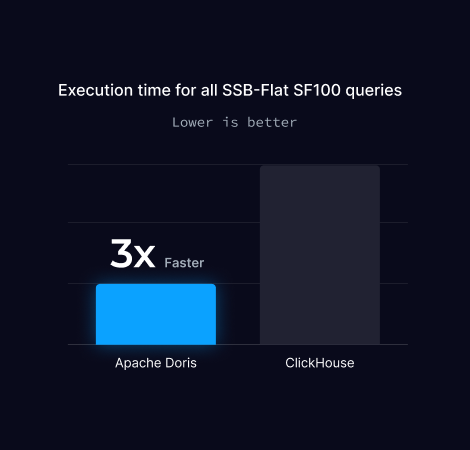
SSB-Flat SF100 性能测试
SSB-Flat SF100 是专为测试分析型数据库大宽表处理能力设计的性能测试。
该测试基于星型模式基准(SSB)改造,通过将星型结构扁平化为单一宽表,聚焦单表查询性能验证。其中 SF100 代表数据规模为基准量的 100 倍,可有效评估系统在超大规模数据下的查询效率与扩展能力。
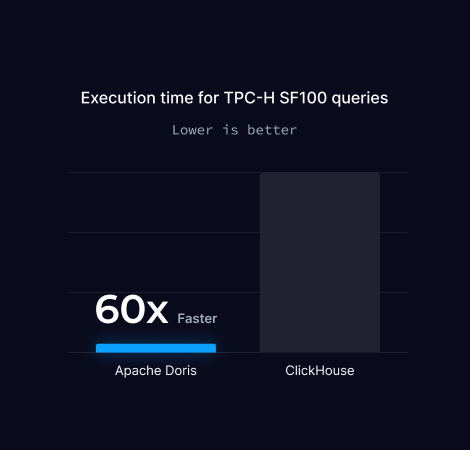
TPC-H SF100 性能测试
TPC-H SF100 是业界公认的数据库性能测试标准,包含 22 条模拟真实企业场景的复杂 SQL 查询。SF100 代表数据规模为基准量的 100 倍,适用于在大规模数据场景下,检验查询性能的验证、评估系统扩展能力。
注:由于 ClickHouse 在测试过程中存在 7 个未能完成的查询,最终测试的总耗时结果为 Doris 完整执行 22 个查询的时间、ClickHouse 仅为成功执行 15 个查询的时间。
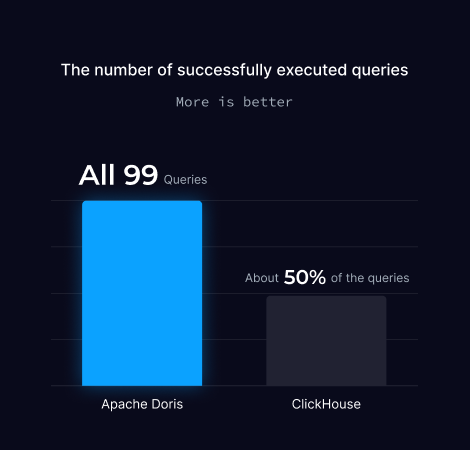
TPC-DS 1TB 性能测试
TPC-DS 1TB 是数据仓库与分析型数据库的权威性能测试,采用约 1TB 数据集(24 张表共约 63.5 亿条数据)构建雪花模型。
测试中涵盖 99 条复杂查询,以全面检验数据库在关联查询、聚合计算及嵌套子查询等场景的性能表现,模拟网络销售、门店销售等真实业务场景。
注:由于 TPC-DS 性能测试中使用了大量关联子查询,而 ClickHouse 在测试时(2024 年 9 月)尚未支持该功能,导致约半数查询无法执行。