Catalog Integrations
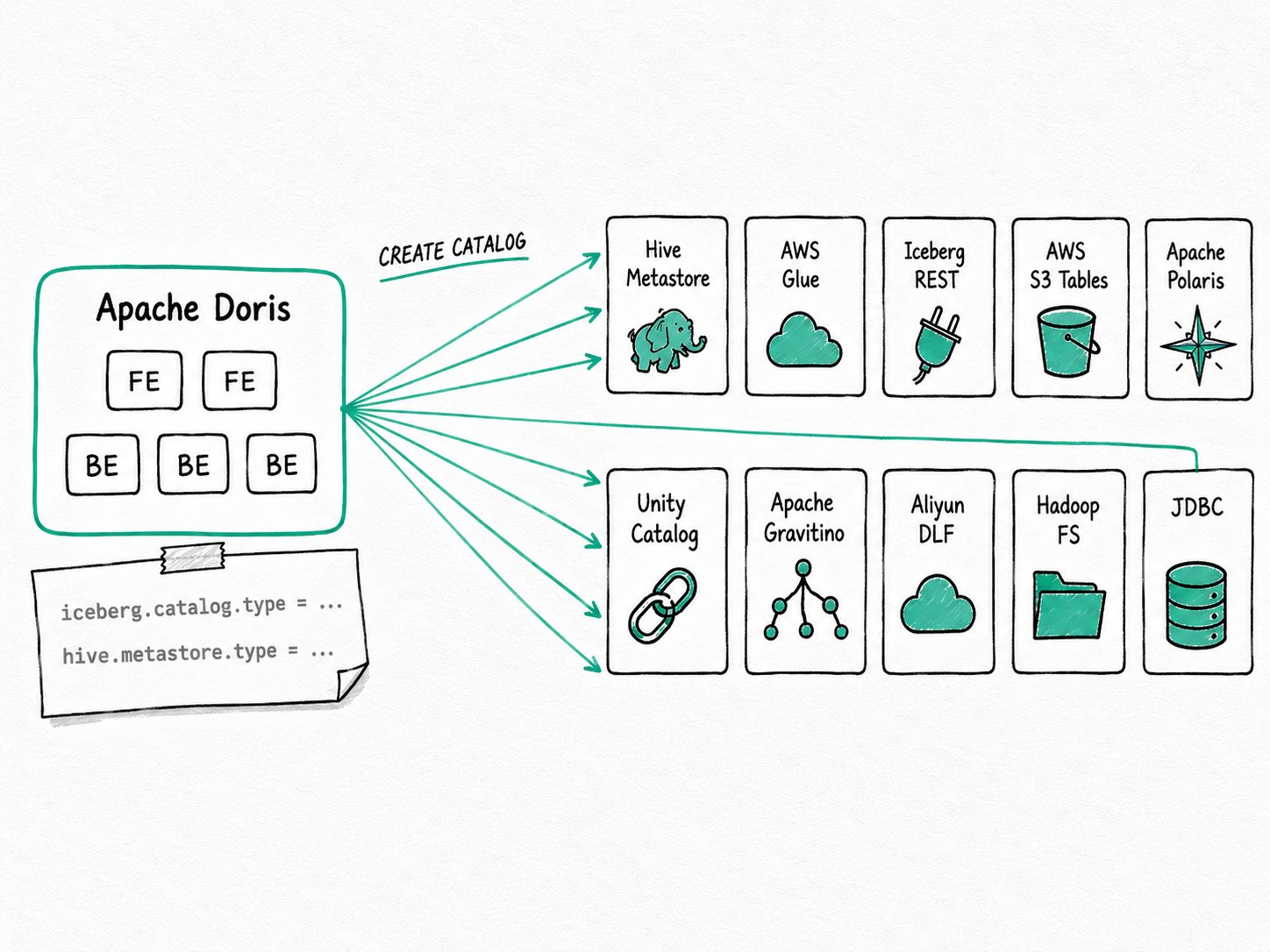
TL;DR Apache Doris catalog integrations cover most of the catalog services a lakehouse already uses: Hive Metastore, AWS Glue, the Iceberg REST spec (Tabular, Polaris, Lakekeeper, Snowflake Open Catalog, Gravitino, Unity), AWS S3 Tables, Aliyun DLF, file-based Hadoop, and a JDBC backend. Every backend sits behind one
CREATE CATALOGstatement, selected byiceberg.catalog.typeorhive.metastore.type. The same SQL works against every one of them once credentials and a warehouse are supplied.
Why use Apache Doris catalog integrations?
Apache Doris catalog integrations let one engine speak every common lakehouse catalog dialect, so the metastore choice does not dictate the query layer. Catalog choice is rarely up to the analytics engine. The metastore comes from somewhere else: a Hadoop cluster that picked Hive Metastore years ago, an AWS account that standardized on Glue, a platform team that just rolled out Polaris, a Databricks workspace that lives in Unity. If your query engine only speaks one of those, you either build a translation layer or limit the lake to whatever the engine supports.
Apache Doris takes the opposite stance: stay plural about the catalog, keep the SQL flat. You type CREATE CATALOG, pick a type, and get SHOW DATABASES, SELECT, joins, writes, and time travel against the same Iceberg or Hive table no matter where the metadata lives. Pair it with multi-catalog federation and a unified metadata cache, and you can also manage lake tables end to end.
- One engine for many metastores. No per-catalog query layer to operate.
- New catalog services arrive as another backend type. Iceberg REST, S3 Tables, Polaris, and Unity all reuse the same connection scaffolding.
- Migrating off a legacy metastore is a
CREATE CATALOGaway, not a re-platform.
What is an Apache Doris catalog integration?
An Apache Doris catalog integration is a backend driver that maps the external-catalog interface to a specific metadata service. For Iceberg tables the type is selected with iceberg.catalog.type; for Hive-style tables the choice flows through type = 'hms' plus hive.metastore.type. Storage credentials (S3, OSS, COS, HDFS) are layered on top of whichever catalog you pick.
The shipped backends today:
- Hive Metastore (
hms): the long-standing Thrift service, with simple or Kerberos auth, used for Hive, Iceberg, and Paimon tables. - AWS Glue (
glue): AWS's managed Hive-compatible catalog. Reachable as a Hive backend (hive.metastore.type=glue), as a native Iceberg Glue client (iceberg.catalog.type=glue), or via Glue's Iceberg REST endpoint when you sit in front of an S3 Table Bucket. - Iceberg REST (
rest): the open Iceberg REST Catalog spec. The same backend covers Tabular-style services, Apache Polaris, Lakekeeper, Snowflake Open Catalog, Apache Gravitino, and Databricks Unity's Iceberg REST endpoint. - AWS S3 Tables (
s3tables): AWS's managed Iceberg catalog tied to a Table Bucket; also reachable through Glue's REST endpoint with SigV4 signing. - Aliyun DLF (
dlf): Data Lake Formation 1.0 over its HMS-compatible interface for Iceberg and Hive; DLF 2.5+ via REST for Paimon. - Hadoop file system (
hadoop): file-based Iceberg metadata, no metastore daemon, useful for self-contained warehouses. - JDBC catalog (
jdbc): Iceberg metadata stored in a SQL database (Postgres, MySQL), useful when you need a transactional metastore without running a service. - Unity Catalog: reached through the Iceberg REST backend, with OAuth2 and vended credentials.
Key terms
type: the catalog family.iceberg,hms,paimon,hudi,jdbc, and similar.iceberg.catalog.type: the metastore driver inside the Iceberg family. One ofhms,rest,glue,dlf,jdbc,hadoop,s3tables.hive.metastore.type: the equivalent switch for Hive-style catalogs.hms(default) orglueordlf.- Vended credentials: an Apache Doris feature that asks the REST catalog for short-lived storage credentials per table, so you do not hand-roll AKs in the catalog properties.
- Warehouse: the storage root the catalog writes new tables under. Required for
hadoop, optional for most others.
How does an Apache Doris catalog integration work?
An Apache Doris catalog integration dispatches metadata calls through a backend driver chosen at CREATE CATALOG time, then funnels reads and writes through the same unified storage layer the BEs already use.
- Pick a backend. The Apache Doris
IcebergExternalCatalogFactoryswitches oniceberg.catalog.typeand instantiates one ofIcebergHMSExternalCatalog,IcebergGlueExternalCatalog,IcebergRestExternalCatalog,IcebergDLFExternalCatalog,IcebergJdbcExternalCatalog,IcebergHadoopExternalCatalog, orIcebergS3TablesExternalCatalog. Hive-family catalogs route the same way through thehmsdriver andhive.metastore.type. - Resolve metadata. The chosen backend handles
SHOW DATABASES, schema fetches, snapshot lookups, and partition listing through its native protocol (Thrift for HMS, AWS SDK for Glue, HTTP for REST). - Resolve storage. Whatever credentials you pass (
s3.access_key,oss.endpoint, vended creds from a REST catalog) flow into a unified storage layer the BEs use to read Parquet, ORC, or Avro files. - Cache for speed. Schemas, table objects, manifests, and views are cached per catalog under
meta.cache.iceberg.*keys. See Metadata Cache for the eviction model. - Plan and execute. From there it is the same MPP pipeline as an Apache Doris internal query, reusing the same data cache, materialized view rewrite, and vectorized execution.
Quick start
-- Connect to an Iceberg REST catalog (Polaris, Lakekeeper, Tabular,
-- Snowflake Open Catalog, Unity, or any spec-compatible service).
CREATE CATALOG iceberg_rest PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'iceberg.rest.uri' = 'https://catalog.example.com/api/catalog',
'warehouse' = 'analytics',
'iceberg.rest.security.type' = 'oauth2',
'iceberg.rest.oauth2.credential' = 'client_id:client_secret',
'iceberg.rest.vended-credentials-enabled' = 'true',
's3.endpoint' = 'https://s3.us-west-2.amazonaws.com',
's3.region' = 'us-west-2'
);
SWITCH iceberg_rest;
SELECT region, SUM(amount) FROM sales.orders WHERE dt = '2026-05-01' GROUP BY region;
Expected result
+--------+-----------+
| region | sum |
+--------+-----------+
| us | 184320.50 |
| eu | 91200.00 |
+--------+-----------+
SHOW CATALOGS lists iceberg_rest next to internal. The same query shape works after you swap the PROPERTIES block for a Glue, HMS, or S3 Tables backend; only the connection block changes.
When should you use Apache Doris catalog integrations?
Use Apache Doris catalog integrations whenever the lakehouse metadata already lives in an external service and you want one engine to read and write it without moving data.
Good fit
- An existing lake that already runs on Hive Metastore, Glue, DLF, or an Iceberg REST service, and you want Apache Doris to read and write it without moving data.
- Cross-region or cross-vendor work, for example reading a Glue catalog in one account and joining against a Polaris catalog in another. See Multi Catalog for the federation story.
- Migrations between catalog services. Bind both old and new as separate catalogs, run them side by side, and switch when ready.
- Cloud-native deployments that need vended credentials so the engine never sees long-lived storage keys.
- File-based or single-tenant Iceberg lakes where running a metastore daemon is overkill: the
hadoopbackend reads metadata straight off the file system.
Not a good fit
- Operational metadata stores like Confluent Schema Registry. They describe wire formats, not tables.
- Treating Apache Doris as the system of record for a lake's metadata. Writes go back to the bound catalog, but Apache Doris is not the catalog itself; for pure Apache Doris-managed tables, use the
internalcatalog. - Reading raw files when there is no catalog at all. Use Table Value Functions (
s3(),hdfs(),local()) instead of standing up an empty catalog.
Further reading
- Multi Catalog: the federation layer that lets you join across the catalogs you connected here.
- Managing Lake Table: the write, schema-evolution, and lifecycle story for Iceberg and Hive tables once a catalog is bound.
- Iceberg Catalog: per-property reference, version matrix, and the feature support table for each backend.
- AWS Glue, Iceberg REST Catalog, Hive Metastore, Aliyun DLF: full per-backend connection guides with examples.
- Catalog Overview: common properties (
include_database_list, case sensitivity, refresh) that apply across every backend. - Metadata Cache: the cache model that keeps repeat queries fast without losing freshness.
- Iceberg: the engine-level capabilities Doris exposes on top of any of the seven Iceberg catalog backends.