Data Lineage
TL;DR Apache Doris extracts column-level lineage from the analyzed Nereids plan of every
INSERT,INSERT OVERWRITE, andCREATE TABLE AS SELECT, including JOIN, FILTER, GROUP BY, WINDOW, and CASE WHEN dependencies. Events flow through a SPI to whichever lineage backend you ship: a custom emitter, an OpenLineage receiver, Apache Atlas, or DataHub. For table-level lineage from ad-hoc queries, theaudit_logsystem table records the source tables and chosen materialized views per query.
Why use Apache Doris data lineage?
Apache Doris data lineage hands you the column-level dependencies the planner already computed, so impact analysis and audit questions can be answered without writing a SQL parser inside your governance tool. You change a column type on a base table, and four hours later a dashboard starts returning nulls. Or someone asks where the value in tgt_region_revenue.revenue actually comes from, and the honest answer is "somewhere in three years of INSERT statements." The dependencies are real and the SQL is in the system, but nobody has stitched it into a graph you can query. Writes that traverse multi-catalog federation or land into incremental materialized views make the graph even larger.
Writing your own SQL parser inside the governance tool is the wrong fix. The database already parsed the SQL. What you want is for it to hand you the dependencies it found, at column granularity, with the transformation that produced each output column attached. Then the lineage matches what ran, not a static reading of the DDL.
Typical questions this answers:
- If I drop
orders.o_discount, which downstream tables and columns break? - Where did this number on the dashboard come from?
- Which regulated tables did this user touch last week?
What is Apache Doris data lineage?
Apache Doris data lineage is column-level lineage extraction built into the Nereids planner, plus a SPI that ships the extracted events to whichever governance backend you run. There is no built-in viewer. Apache Doris is the producer; your existing tool (Atlas, DataHub, OpenMetadata, an internal service) is the consumer. For table-level lineage derived from query history, the audit_log table already records source tables and any matched materialized views per query, so you can build a coarse graph without writing a plugin at all.
Key terms
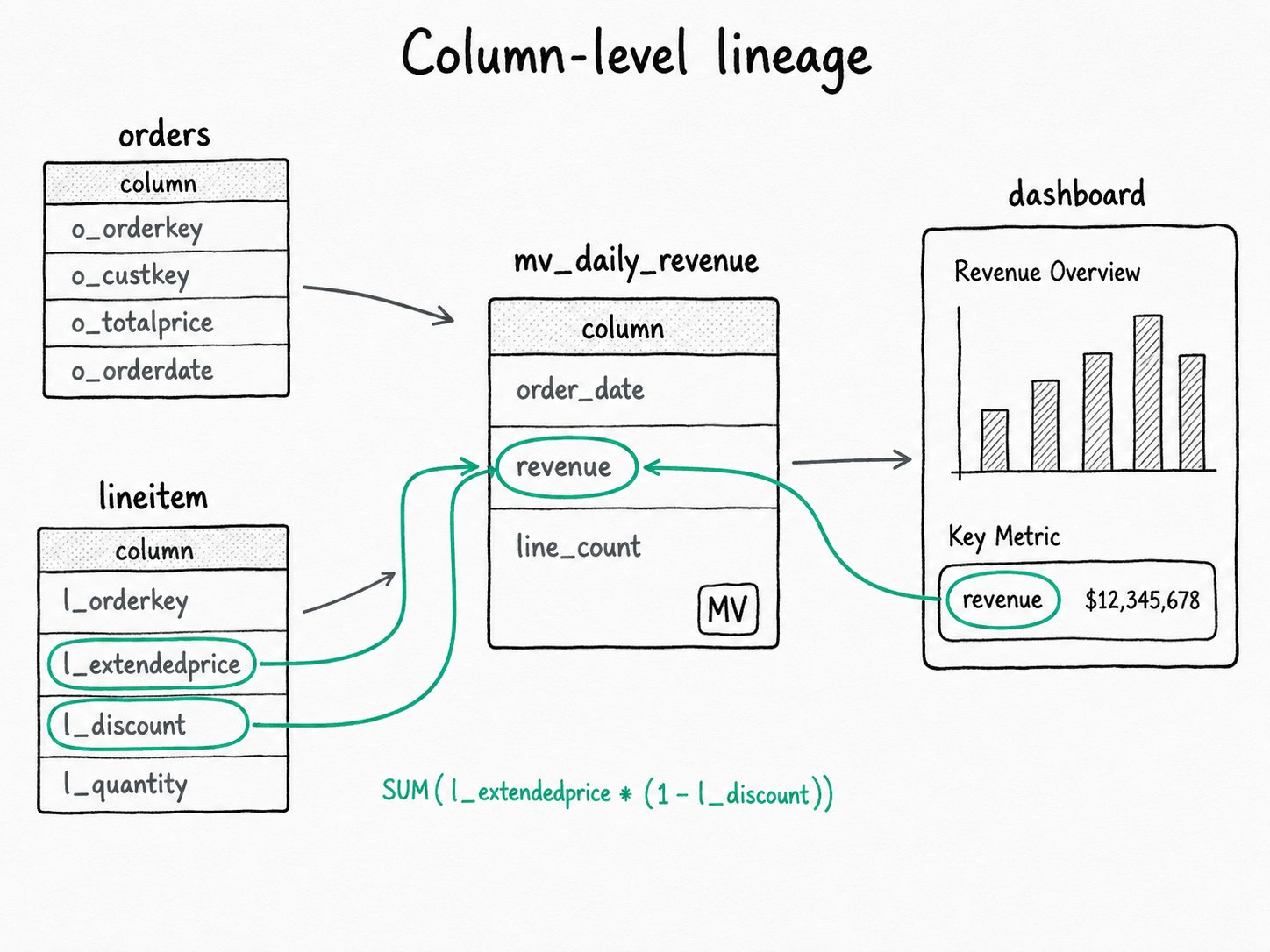
LineageInfo: the in-memory event format. Per output column, it holds the direct lineage type (IDENTITY,TRANSFORMATION,AGGREGATION) and the source expression, plus dataset-level indirect lineage (JOIN,FILTER,GROUP_BY,SORT) and per-column indirect lineage (WINDOW,CONDITIONAL).LineagePlugin: SPI you implement to receiveLineageInfoevents. Discovered viaServiceLoaderon the classpath or as an external jar in$plugin_dir/lineage/.activate_lineage_plugin: FE config naming the plugins that should receive events. Empty by default, so the planner does no lineage work until you enable a plugin.audit_log.queried_tables_and_views: anARRAY<STRING>column in__internal_schema.audit_logthat lists the catalog-qualified tables touched by each query.audit_log.chosen_m_views: companion column listing the materialized views the optimizer rewrote into.
How does Apache Doris data lineage work?
Apache Doris hooks the Nereids planner before optimization, walks the analyzed plan to resolve each output column back to its sources, records the JOIN/FILTER/GROUP BY/WINDOW/CASE WHEN dependencies, and ships the event off the query thread to every registered LineagePlugin.
- Hook the planner. Each write command (
INSERT INTO,INSERT OVERWRITE,CTAS) registers an analyze-plan hook. The hook grabs the analyzedLogicalPlanbefore optimization, so column references still carry their source slots and lineage matches the SQL the user wrote. - Extract direct lineage.
LineageInfoExtractorwalks the plan and resolves every output column back to its source expressions. A pure column reference becomesIDENTITY. A scalar expression becomesTRANSFORMATION. An aggregate function becomesAGGREGATION. CTE consumer slots get pre-resolved to producer slots so the chain does not stop at aWITHclause boundary. - Extract indirect lineage. JOIN keys, filter predicates, and GROUP BY columns are recorded as dataset-level indirect lineage, since they affect every output.
WindowExpressionpartition keys andCaseWhen/If/Coalescebranches are recorded per output column, so you can trace why a single value took the path it took. - Submit asynchronously. A single worker thread drains a bounded queue (
lineage_event_queue_size, default 50000) and dispatches each event to every active plugin in order. Plugin work happens off the query thread, so a slow downstream system slows the queue, not the query the user is waiting on. - Skip what does not matter.
VALUES-only inserts and writes targeting__internal_schemaare filtered out before extraction. The optimizer does not pay for events nobody wants.
For ad-hoc SELECT traffic that never lands in a write, the picture is simpler. The audit log already records the source tables and any matched materialized views per query, and you derive table-level lineage from there.
Quick start
-- 1. Enable the audit plugin so query-level lineage is recorded.
SET GLOBAL enable_audit_plugin = true;
-- 2. Run a query that joins two base tables.
SELECT n.n_name, SUM(o.o_totalprice)
FROM orders o JOIN nation n ON o.o_custkey = n.n_nationkey
GROUP BY n.n_name;
-- 3. Read the lineage out of the audit log.
SELECT time, queried_tables_and_views, chosen_m_views, stmt_id
FROM internal.__internal_schema.audit_log
WHERE user = CURRENT_USER() AND is_query = 1
ORDER BY time DESC LIMIT 5;
Expected result
+---------------------+--------------------------------------------+----------------+
| time | queried_tables_and_views | chosen_m_views |
+---------------------+--------------------------------------------+----------------+
| 2026-05-09 10:14:22 | ["internal.tpch.orders","internal.tpch. | [] |
| | nation"] | |
+---------------------+--------------------------------------------+----------------+
The row holds catalog-qualified table names and any MV the optimizer rewrote into. That is enough to draw a table-level graph for ad-hoc queries. For column-level lineage on writes, implement LineagePlugin, drop the jar in plugin_dir/lineage/, and add the plugin name to activate_lineage_plugin. From then on, every INSERT and CTAS produces a LineageInfo event.
When should you use Apache Doris data lineage?
Apache Doris data lineage fits impact analysis, compliance trails, MV governance, and feeding external catalogs (Atlas, DataHub, OpenMetadata) with column-level events; it is not a built-in lineage browser and does not cover pure SELECT traffic at column granularity.
Good fit
- Impact analysis on schema changes. "If I drop
orders.o_discount, which downstream tables and columns break?" is exactly what the per-column source expressions answer. - Audit and compliance trails that need to show every read of a regulated table over a time window. The audit log gives you the table list per query, with user, time, and SQL.
- Materialized view governance. Pair
chosen_m_viewsfrom the audit log with Async Materialized Views to see which MVs are actually serving traffic and which ones are dead weight. - Feeding an external metadata catalog (Apache Atlas, DataHub, OpenMetadata, an internal service) with column-level lineage from a
LineagePluginthat emits OpenLineage events. - Cross-engine lineage where Doris is one of several producers writing into a shared catalog.
Not a good fit
- A built-in lineage browser. Doris emits events. The visualization is your governance tool's job. If you want a graph today and have no governance stack, deploy DataHub or Marquez and point a plugin at it.
- Lineage for pure
SELECTqueries that never land in a write. The Nereids extractor only fires onINSERT,INSERT OVERWRITE, andCTAS. For read-only traffic, use thequeried_tables_and_viewsarray in the audit log to get table-level coverage. - Lineage across systems that never touch Doris. The plugin sees Doris-side queries. A Spark job that writes Parquet which Doris later reads needs Spark-side instrumentation (OpenLineage's Spark integration, for example), and the two streams meet in your catalog.
- Source-of-truth metadata storage. Lineage events are emitted, not retained inside Doris. Persist them in your catalog of choice.
- Operations on
__internal_schematargets andVALUES-only inserts. These are filtered out by design and will not produce lineage events.
Further reading
- audit_log system table: full column reference, including the
queried_tables_and_viewsandchosen_m_viewsarrays you query for table-level lineage. - Audit Log plugin: how to enable
enable_audit_plugin, configure batch interval and SQL length, and exclude internal users. - Async Materialized Views: the rewrite engine whose decisions show up in
chosen_m_viewsand whose base-table dependencies are tracked byMTMVRelationManager. - Incremental Materialized View: partition-level dependency tracking between MVs and base tables that complements column-level lineage on the write path.
- OpenLineage specification: the open standard for column-level lineage events; a useful target schema for a
LineagePluginimplementation. - Managing Lake Tables: writes against Iceberg, Paimon, and Hive produce lineage events too; this card covers the write paths involved.
- Apache Atlas overview: a common downstream sink that accepts OpenLineage today and renders the column-level graph.
- Iceberg: an external table format whose snapshot history feeds into the lineage graph alongside Doris internal tables.