Data Model
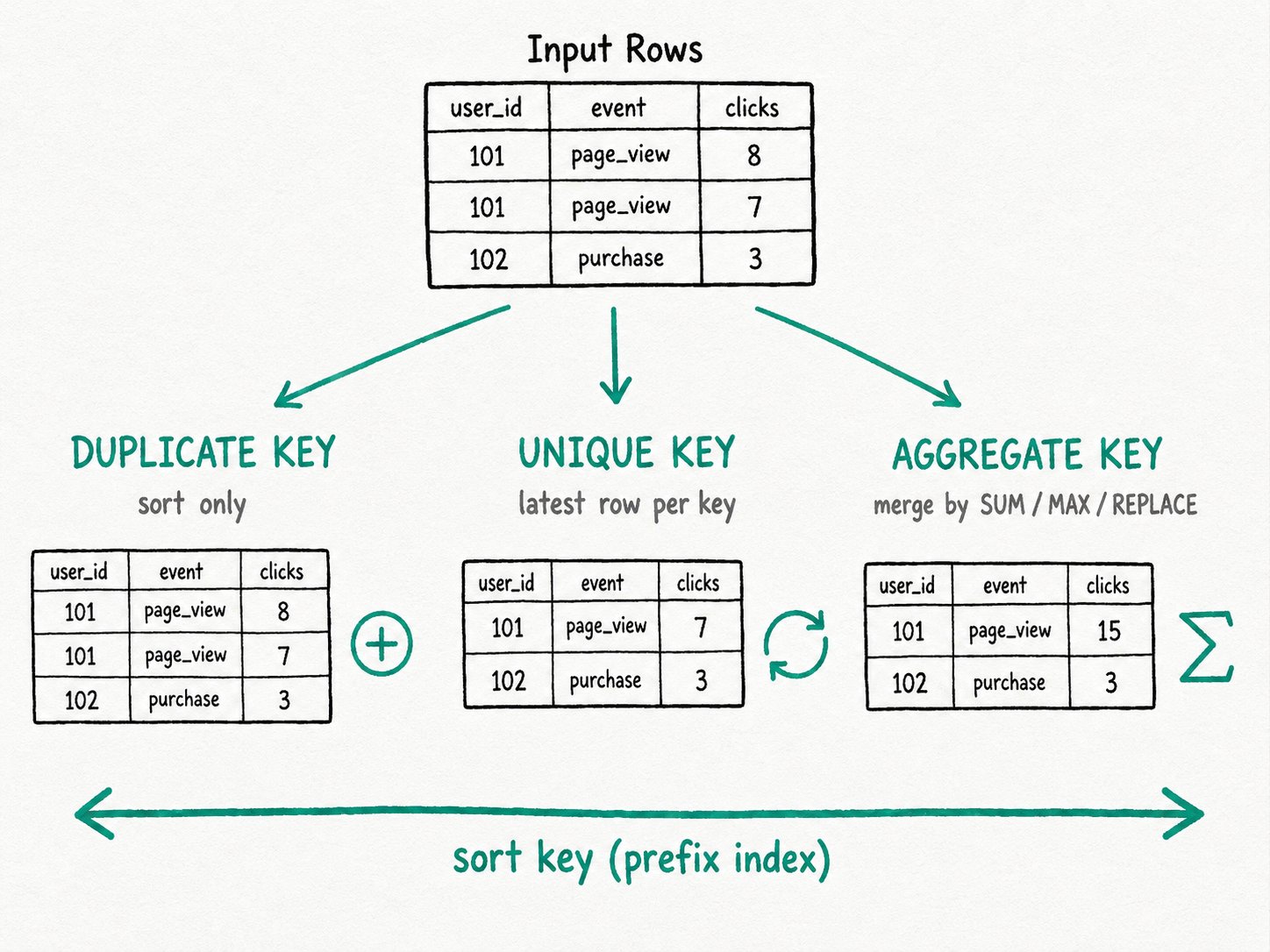
TL;DR Every Apache Doris OLAP table picks one of three models when you create it: Duplicate Key keeps every row, Unique Key keeps the latest row per primary key, and Aggregate Key folds rows together by per-column functions like
SUM. TheKEY(...)clause names the columns Apache Doris sorts on, and in Unique and Aggregate models those same columns also enforce uniqueness. The model is fixed atCREATE TABLEtime, so the choice up front decides what writes, updates, and queries you can run for the life of the table.
Why use the Apache Doris data model?
The Apache Doris data model is the first decision in any schema, and it is the one decision you cannot reverse. ALTER TABLE can add columns, drop columns, repartition, and swap encodings. It cannot turn a Duplicate table into a Unique table. If you get the model wrong, the fix is CREATE TABLE and a full reload.
- A logs table created as Aggregate loses the raw rows and cannot answer detail queries.
- An orders table created as Duplicate rejects
UPDATE, so a CDC pipeline has nowhere to land row changes. - A reporting table created as Unique pays the merge-on-write index cost on every load even when every query is
SUM(clicks) GROUP BY day.
The model decides whether duplicate keys are allowed, what UPDATE and DELETE mean, and what the storage engine does with rows that share a key. Pick by what the data is (raw events, current state, or pre-aggregated facts), not by the shape of the dashboard you are building this week.
What is the Apache Doris data model?
The Apache Doris data model is the contract the storage engine enforces on rows that share the same key columns. Apache Doris ships three: DUPLICATE KEY, UNIQUE KEY, and AGGREGATE KEY. The FE catalog calls them DUP_KEYS, UNIQUE_KEYS, and AGG_KEYS (see KeysType.java). The clause sits right after the column list in CREATE TABLE and names the key columns:
... DUPLICATE KEY(log_time, log_type)
... UNIQUE KEY(order_id)
... AGGREGATE KEY(dt, ad_id, user_id)
Key terms
- Key columns: the columns named in the
KEY(...)clause. They define the on-disk sort order, drive the prefix index, and (in Unique and Aggregate) enforce uniqueness. - Value columns: every other column. In Duplicate and Unique they store data as written. In Aggregate each one carries an aggregation function (
SUM,MAX,REPLACE,BITMAP_UNION, and so on). - Sort key: a synonym for the key columns when you are talking about storage layout. Data inside a tablet is sorted by the key columns regardless of which model you picked.
- Duplicate Key model: keys can repeat. Rows are appended as written. The
KEY(...)clause is sort-only. - Unique Key model: one row per key. New writes overwrite older rows with the same key. Supports SQL
UPDATE,DELETE, and partial-column upserts via Merge-on-Write. - Aggregate Key model: rows that share a key are merged using each value column's declared function. The merged row is what you read.
How does the Apache Doris data model work?
The Apache Doris data model enforces one of three per-row contracts at load time and again at compaction time, using the same DDL shape.
- Pick a model. The
DUPLICATE KEY,UNIQUE KEY, orAGGREGATE KEYclause sets theKeysTypefor the table. Apache Doris validates the rest of the DDL against it: Aggregate value columns must declare a function, Unique tables pick up the merge-on-write property, and Duplicate tables reject aggregation functions outright. - Order columns. Key columns must come before any value column in the column list. Apache Doris sorts data inside each tablet by the key columns and builds a sparse prefix index over the first 36 bytes of the sort key. That index is what makes range and equality predicates on the leading key columns fast.
- Apply the contract on load. Duplicate appends. Unique looks up the existing row by key, flips it on in a per-rowset delete bitmap, and writes the new row. Aggregate merges incoming rows against existing ones using each value column's function (
SUM,MAX,REPLACE, and so on). - Apply it again at compaction. Background compaction merges rowsets using the same rules. Duplicate concatenates. Unique drops rows the delete bitmap covers. Aggregate folds duplicates again with the value-column functions.
- Read. Queries see the model's view of the data: every appended row in Duplicate, the latest row per key in Unique, one merged row per key in Aggregate.
The model is written into tablet metadata and replicated across all replicas. There is no ALTER TABLE ... CHANGE MODEL. To change models you create a new table and reload.
Quick start
-- Duplicate: keep every event, sort by (log_time, log_type)
CREATE TABLE logs (
log_time DATETIME, log_type INT, msg VARCHAR(1024)
) DUPLICATE KEY(log_time, log_type)
DISTRIBUTED BY HASH(log_type) BUCKETS 4;
-- Unique: one row per order_id, with UPDATE / DELETE support
CREATE TABLE orders (
order_id BIGINT, status VARCHAR(20), amount DECIMAL(10,2)
) UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 4;
-- Aggregate: pre-sum clicks per (dt, ad_id) at load time
CREATE TABLE ad_stats (
dt DATE, ad_id INT, clicks BIGINT SUM
) AGGREGATE KEY(dt, ad_id)
DISTRIBUTED BY HASH(ad_id) BUCKETS 4;
Expected result
SHOW CREATE TABLE logs\G -- prints "DUPLICATE KEY(`log_time`, `log_type`)"
SHOW CREATE TABLE orders\G -- prints "UNIQUE KEY(`order_id`)"
SHOW CREATE TABLE ad_stats\G -- prints "AGGREGATE KEY(`dt`, `ad_id`)"
Identical column lists, but the storage engine treats writes very differently. Insert the same row into logs twice and you get two rows. Do the same on orders and you get one. Insert two rows into ad_stats with matching (dt, ad_id) and the clicks column sums.
When should you use the Apache Doris data model?
Pick the Apache Doris data model by what the data is (raw events, current state, or pre-aggregated facts), not by the shape of the dashboard you are building this week.
Good fit
- Duplicate for append-only data where you query raw rows: access logs, click streams, IoT readings, transaction details. No deduplication, no constraint on which columns predicates can hit.
- Unique for anything updated by primary key: CDC sinks from MySQL or Postgres, order status tables, user profiles, real-time dimension tables. See Data Update and Delete for
UPDATE, partial-column upserts, and Merge-on-Write internals. - Aggregate for fixed-shape rollup queries on append-mostly fact tables: per-day spend, per-ad clicks, distinct viewers via
BITMAP_UNION. See Preaggregation and Rollup for the full set of aggregation functions and howROLLUPextends them. - Any model: pick three or fewer leading key columns, prefer integers over strings, and use the smallest type that fits. The prefix index only sees the first 36 bytes of the sort key.
Not a good fit
- Aggregate when the workload also needs raw per-row lookups. The raw rows are gone the moment they hit the merge step. Use Duplicate, optionally with an async materialized view for the rollups.
- Aggregate when
count(*)runs constantly. Counting has to read and merge every key column, so the cost scales with key width. The classic workaround is a value column whose value is always1and whose aggregation isSUM; queryingSUM(count)is then equivalent and roughly 10x faster thancount(*)on a wide-key Aggregate table. - Unique when you only ever append and never update. The merge-on-write key index pays for capability you are not using. Pick Duplicate.
- Unique with the primary key as a partition key. Partition keys must be a subset of the unique key, not the other way around.
- Duplicate for tables that need
UPDATE. The statement is rejected; reload through ingestion, or pick Unique. - Aggregate for tables that need
UPDATEorDELETEon value columns. Aggregate'sDELETEpredicate is restricted to key columns because the engine has no way to evaluate value-column conditions before aggregation.
Further reading
- Table Model Overview: capability matrix and decision table
- Duplicate Key Model: append-only storage and sort key tuning
- Unique Key Model: Merge-on-Write vs. Merge-on-Read, partial column updates
- Aggregate Model: aggregation functions and
AGG_STATEfor custom merges - Table Model Best Practices: column ordering, type choice,
count(*)tuning - Prefix Index and Sort Key: how key columns drive query pruning
- Data Update and Delete: SQL UPDATE, DELETE, partial-column upsert, and the Merge-on-Write internals that the Unique Key model unlocks.
- Preaggregation and Rollup: the Aggregate Key model in depth, plus ROLLUP and sync materialized views.
- Partitioning and Bucketing: how the same key columns drive partition pruning and tablet placement.
- Unique Key: the primary key (one-row-per-key) variant alongside Duplicate and Aggregate — pick this when sources do upserts.