Data Update and Delete
TL;DR Apache Doris supports SQL
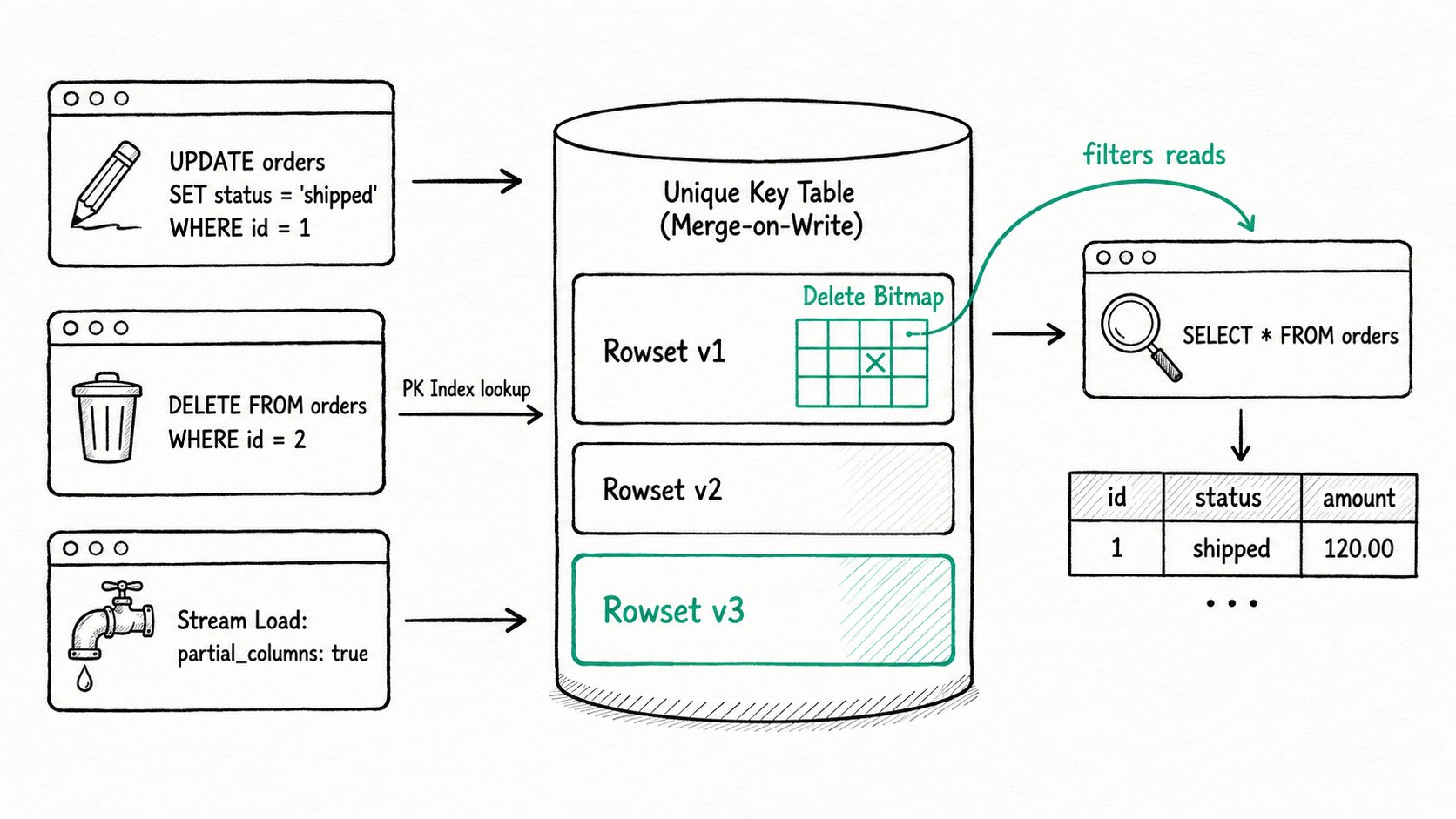
UPDATEandDELETElike a transactional database, with partial-column upserts from streaming loads, predicate-based bulk deletes, and atomic partition swaps. On Unique Key tables, the Merge-on-Write engine keeps query latency low by marking deleted rows in a per-rowset bitmap at write time instead of merging versions at read time. Merge-on-Write became the Unique Key default in version 2.1.
Why use data update and delete in Apache Doris?
Apache Doris data update and delete brings transactional row-level mutations to an analytical engine, so CDC, GDPR erasure, and one-off corrections do not turn into partition rewrites. Most analytical engines were built around the idea that warehouses are append-only. Then CDC happened, and so did GDPR, and so did the boring fact that production data has bugs. If your warehouse can't fix a single bad row without rewriting a partition, every late-arriving correction turns into an ops ticket.
- A Flink CDC job watches MySQL and needs every row update to land within seconds.
- A user requests deletion under GDPR. You need it gone from the warehouse, not "gone after the next compaction."
- One report shows the wrong number because a single row in a 10-billion-row fact table has a typo.
Apache Doris handles all three with first-class SQL: UPDATE, DELETE FROM ... WHERE, partial-column upserts from Stream Load, and TRUNCATE or atomic partition replace for bulk cleanup. None of them require the table to be small, and none rely on you to schedule a rewrite job afterward.
What is Apache Doris data update and delete?
Apache Doris data update and delete is a four-part surface — UPDATE SQL, predicate DELETE, partial-column upserts, and partition swaps — backed by the Merge-on-Write engine on Unique Key tables. Row-level UPDATE SQL works on Unique Key tables, predicate-based DELETE FROM ... WHERE works on any table, partial-column upserts are driven by ingestion (the partial_columns: true Stream Load header or the matching session variable), and partition-level operations include TRUNCATE PARTITION and atomic temp-partition replacement. Underneath, the Unique Key model uses Merge-on-Write (MoW) so deletes and updates take effect at write time rather than at query time. MoW shipped in 1.2 and became the Unique Key default in 2.1.
Key terms
Unique Key model: a table model where one row per primary key is kept. Required forUPDATEand for batch upserts.Merge-on-Write (MoW): at write time, Apache Doris looks up each new key in the existing data, marks the old row in a delete bitmap, and writes the new row to a fresh rowset.Delete bitmap: a per-rowset bitmap of row IDs that queries should skip, replacing per-key version merging at read time.Partial column update: a write that only touches some columns. Apache Doris reads the missing values from existing rows and writes a complete row back.Sequence column(function_column.sequence_col): a user-chosen column that tells MoW which version of a key wins when out-of-order writes arrive.__DORIS_DELETE_SIGN__: a hidden column you set to1to soft-delete a row through any load path.
How does Apache Doris data update and delete work?
Apache Doris data update and delete runs in five stages on a Unique Key MoW table: plan and read, look up keys, flip delete-bitmap bits on old rows, write new rows to a fresh rowset, and publish the new version.
Take an UPDATE against a Unique Key MoW table:
- Plan and read. The FE parses the statement, resolves the WHERE predicate, and routes a read across BE replicas. For partial-column writes, BEs additionally fetch the missing column values for each affected key.
- Look up keys. Each BE consults the in-memory primary key index per rowset to find which rowset and row IDs the affected keys currently live in.
- Mark old rows. Every rowset that holds an affected key has the corresponding row IDs flipped on in its delete bitmap. The old rows stay on disk until compaction sweeps them up.
- Write new rows. New values, plus any unchanged columns Apache Doris had to read for partial updates, land in a fresh rowset with the next version number.
- Publish. The transaction commits, the new version becomes visible, and queries from that point on filter through the merged delete bitmap. Old data is reclaimed at compaction.
DELETE FROM ... WHERE follows the same flow without the write step. On Aggregate or Duplicate tables, Apache Doris records the predicate in tablet metadata instead, and queries apply it at read time.
Quick start
CREATE TABLE orders (
order_id BIGINT,
status VARCHAR(20),
amount DECIMAL(10, 2),
updated DATETIME
)
UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 4
PROPERTIES ("function_column.sequence_col" = "updated");
INSERT INTO orders VALUES
(1, 'created', 99.50, '2026-05-08 10:00:00'),
(2, 'created', 149.00, '2026-05-08 10:01:00');
UPDATE orders SET status = 'shipped', updated = NOW() WHERE order_id = 1;
DELETE FROM orders WHERE order_id = 2;
Expected result
+----------+---------+--------+---------------------+
| order_id | status | amount | updated |
+----------+---------+--------+---------------------+
| 1 | shipped | 99.50 | 2026-05-08 11:42:31 |
+----------+---------+--------+---------------------+
Order 1 was rewritten in place; order 2 is gone. The function_column.sequence_col property protects the table from out-of-order writes: a CDC event with an older updated timestamp would lose to the row that's already there, even if it lands after the newer one.
When should you use Apache Doris data update and delete?
Apache Doris data update and delete fits CDC upserts into Unique Key tables, hot-column updates on wide tables, GDPR-style row-level deletes, atomic backfill swaps, and multi-stream wide-table assembly. It is not a fit for UPDATE on Aggregate or Duplicate tables, single-row updates fired in a tight loop, primary-key renames, or massive predicate DELETEs that a partition replace could handle in one shot.
Good fit
- Flink and Spark CDC pipelines that upsert into a Unique Key table, with the source primary key as the Apache Doris key.
- Hot-column updates on wide tables (order status, last-seen timestamp, current balance) via partial-column Stream Load.
- GDPR-style row-level deletes by user ID, including on append-only Duplicate tables.
- Backfills that swap a corrected partition in atomically with
ALTER TABLE ... REPLACE PARTITION. - Multi-stream wide-table assembly, where each upstream owns a column group and writes only its own columns.
Not a good fit
UPDATEon Aggregate or Duplicate tables. The statement is rejected. Reload through ingestion (Aggregate usesREPLACE_IF_NOT_NULLto overwrite values), or switch the table model.- High-frequency single-row
UPDATEs in a tight loop. Each statement is its own transaction and the commit overhead dominates. Batch updates through Stream Load withpartial_columns: trueinstead, or use Group Commit. - Renaming a primary key. There is no key-rewrite path; soft-delete the old row via
__DORIS_DELETE_SIGN__and insert a new one, ideally in the same load. - Predicate
DELETEover many billions of rows that match. Each delete records a predicate or bitmap that compaction has to chew through; a partition replace orINSERT OVERWRITEis faster. - Aggregate-model
DELETEon non-key columns. The predicate must filter on key columns only; the engine has no way to evaluate value-column conditions before aggregation.
Further reading
- Data update and delete overview
- Update overview: SQL UPDATE, partial column update, sequence column
- Partial column update
- Delete overview: predicate delete, batch delete, atomic replace
- Data Model: why Unique Key is the table model that powers UPDATE/DELETE, and where Duplicate and Aggregate fit.
- High-Concurrency Point Query: the short-circuit path that Unique Key Merge-on-Write tables unlock for KV-style reads.
- Binlog Table Stream: how committed row-level changes are exposed to downstream consumers.
- Apache Doris 2.1.0: Merge-on-Write becomes the Unique Key default
- Unique Key: the table model that powers SQL UPDATE/DELETE — Merge-on-Write resolves each upsert at write time.