Embedding
TL;DR Apache Doris ships a built-in
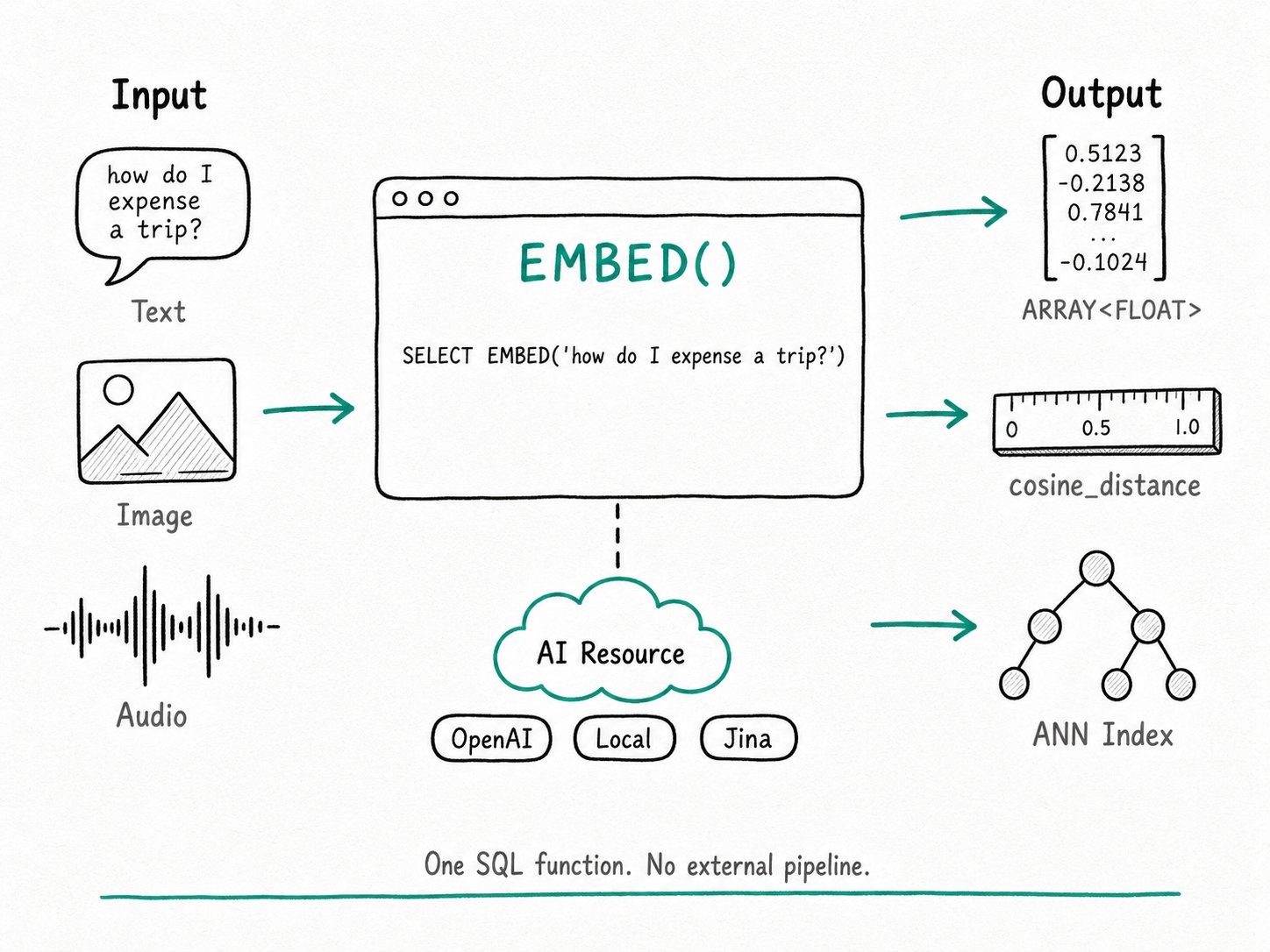
EMBED()SQL function that sends text (or an image, video, audio file) to an external embedding model and returns anARRAY<FLOAT>ready for a column or a distance function. The model is configured once as an AIRESOURCE, thenEMBED('your text')works anywhere a value is allowed. No UDFs, no client-side glue, no second service to operate.
Why use the EMBED function in Apache Doris?
The Apache Doris EMBED() function collapses the usual application-side embedding pipeline into one SQL call, so vectors are generated, stored, and queried inside the database without a separate ETL service. Vector search needs vectors, and vectors come from an embedding model. The usual setup looks like this: an application server pulls rows out of the database, sends them to OpenAI or a local model, gets vectors back, and writes them to a vector table. At query time the same round trip happens for the search string. You end up maintaining a small ETL service whose only job is to call an HTTP API and stash the result somewhere.
A few things tend to go wrong:
- The pipeline drifts out of sync with the source table. New rows land without embeddings until the next batch run.
- Backfills are jobs in their own right, often slower and more expensive than the original ingest.
- Two teams own one logical step. The data team owns the rows, the application team owns the vectors, and nobody owns the gap.
EMBED() pulls the whole loop back into SQL. The model is an Apache Doris resource, the call is a function, and the result is a column you can persist with INSERT or compute on the fly.
What is the Apache Doris EMBED function?
The Apache Doris EMBED() function is a built-in AI function that takes text or a multimodal file reference, asks an external embedding provider for a vector, and returns an ARRAY<FLOAT>. Apache Doris reaches the provider through an AI resource you set up once with CREATE RESOURCE. The same function call works at load time, so you can persist embeddings into a column, and at query time, so you can embed the user's search string on the fly without leaving SQL.
Key terms
- AI resource: a named connection to an embedding provider.
EMBED()ships dedicated adapters foropenai,gemini,voyageai,jina,qwen,minimax, plus alocaloption for in-house model servers. Stores the endpoint, model name, API key, and optional dimensions. EMBED([resource_name], input): the SQL function. With one argument, Apache Doris uses the session default; with two, the first names the resource explicitly.default_ai_resource: a session variable that picks a resource for the rest of the session.- Multimodal input: a JSON value describing a file (URI, content type, optional S3 credentials). Apache Doris presigns S3 URLs and forwards them to providers that support image, video, or audio embeddings.
How does the Apache Doris EMBED function work?
The Apache Doris EMBED() function works in five stages: register the AI resource, plan the call on the FE, batch rows on the BE, retry on failures, and return one ARRAY<FLOAT> per row.
- Register the model.
CREATE RESOURCEstores the provider type, endpoint, model name, and credentials. Apache Doris validates the resource with a probe call to the provider, except whenprovider_type = "local", where the check is skipped. - Plan the call. When the planner sees
EMBED(), it sends the work to the BE. The function processes the input column row by row, but it does not call the provider row by row. - Batch on the BE. The BE accumulates rows into a batch, capped by
embed_max_batch_size(default 5 inputs) and byai_context_window_size(default 128 KB of accumulated text). Each batch becomes one HTTP request, which keeps round trips and per-minute rate limits in check. - Retry and fail loudly. The provider call honors
ai.max_retriesandai.retry_delay_secondfrom the resource. If the API returns the wrong number of vectors, Apache Doris fails the query rather than risk misaligning rows with vectors. - Return a column. Every row gets its own
ARRAY<FLOAT>. You can store it, feed it tocosine_distance, or load it into an ANN index for vector search.
Quick start
CREATE RESOURCE "openai_embed" PROPERTIES (
"type" = "ai", "ai.provider_type" = "openai",
"ai.endpoint" = "https://api.openai.com/v1/embeddings",
"ai.model_name" = "text-embedding-3-small",
"ai.api_key" = "sk-xxx", "ai.dimensions" = "8"
);
SET default_ai_resource = "openai_embed";
CREATE TABLE notes (id INT, body STRING, vec ARRAY<FLOAT>)
DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 1;
INSERT INTO notes VALUES
(1, 'travel reimbursement policy', EMBED('travel reimbursement policy')),
(2, 'VPN setup guide', EMBED('VPN setup guide'));
SELECT id, body, cosine_distance(vec, EMBED('how do I expense a trip?')) AS d
FROM notes ORDER BY d ASC LIMIT 1;
Expected result
+----+-----------------------------+--------+
| id | body | d |
+----+-----------------------------+--------+
| 1 | travel reimbursement policy | 0.4463 |
+----+-----------------------------+--------+
The INSERT precomputes one vector per row. The SELECT embeds the query string once at runtime, then ranks rows by cosine distance. Two API calls in total, both hidden inside SQL.
When should you use the Apache Doris EMBED function?
The Apache Doris EMBED() function fits RAG and semantic search over corpora that already live in Apache Doris, backfills that keep the work inside SQL, hybrid pipelines that pair vectors with keyword filters, and multimodal embeddings whose source files live in S3. It is not a fit for per-row embedding over millions of rows on the hot path, models outside the supported provider list, or air-gapped clusters with no path to the provider.
Good fit
- RAG and semantic search where the corpus already lives in Apache Doris and you want one system to handle ingestion, embedding, and retrieval.
- Backfills over existing tables:
UPDATE t SET vec = EMBED(body) WHERE vec IS NULLkeeps the work inside the database. - Hybrid pipelines that pair
EMBED()with an ANN index for storage and aMATCH_*predicate for keyword filtering. See Hybrid Search. - Multimodal embeddings (image, video, audio) where the file lives in S3 and you would rather not write a download-then-upload script.
Not a good fit
- Real-time queries that embed at the per-row level over millions of rows. Each row is one provider call, so the bill and the latency scale with row count. Precompute once, reuse forever.
- Workloads that need a specific embedding model not on the supported provider list. The providers with an embedding adapter are OpenAI, Gemini, VoyageAI, Jina, Qwen, and MiniMax, plus
localfor an in-house model server. Apache Doris's broader AI resource list also accepts DeepSeek, MoonShot, Anthropic, Zhipu, and Baichuan, but those route through the LLM SQL Functions — chat / completion only, notEMBED(). Anything outside the embedding-adapter set needs to expose an OpenAI- or Gemini-compatible API to plug in. - Air-gapped clusters with no path to the provider. Use
provider_type = "local"against an in-house model server, or precompute vectors in your own pipeline. - Columns where the embedding model's dimension does not match the ANN index. The ARRAY length is fixed by the model (or by
ai.dimensionsfor models that allow truncation); the index is fixed at table creation. Mismatch fails at write time.
Cost and throughput notes
EMBED() runs only as fast as the provider behind it. Before you put EMBED() on a hot path, a few things are worth knowing:
- External APIs are rate limited. Raising
embed_max_batch_sizecuts round trips but pushes more tokens into each request, so tune the two together. - A row whose input exceeds
ai_context_window_sizegets its own batch automatically, so one oversized document does not stall the rest of the query. - The provider bills you for input tokens, not for rows. Embedding the same text twice costs twice. If you will read a vector more than once, persist it.
localproviders skip credential checks and run inside your network. That removes per-token billing but trades it for an inference server you have to operate.
Further reading
- EMBED function reference: full syntax, multimodal JSON input, and per-distance examples.
- AI Functions overview: every supported provider and the full property list for
CREATE RESOURCE. - Hybrid Search: how to combine
EMBED()with a full-text predicate and an ANN index in one query. - Vector index overview: how to store embeddings under HNSW or IVF for ANN-scale lookups.
- Inverted Index: the index used to pre-filter rows before vectors get ranked in a hybrid query.
- Reciprocal Rank Fusion: how to fuse BM25 and vector ranks once embeddings are in place.
- LLM SQL Functions:
EMBED()shares its AI resource model with theAI_*family; this is the other half of the AI SQL surface. - AI on Doris: the rest of the AI function family, including classification, generation, and cross-row aggregation.