Full-text Search
TL;DR Apache Doris full-text search turns text columns into searchable terms with an inverted index and exposes them through six
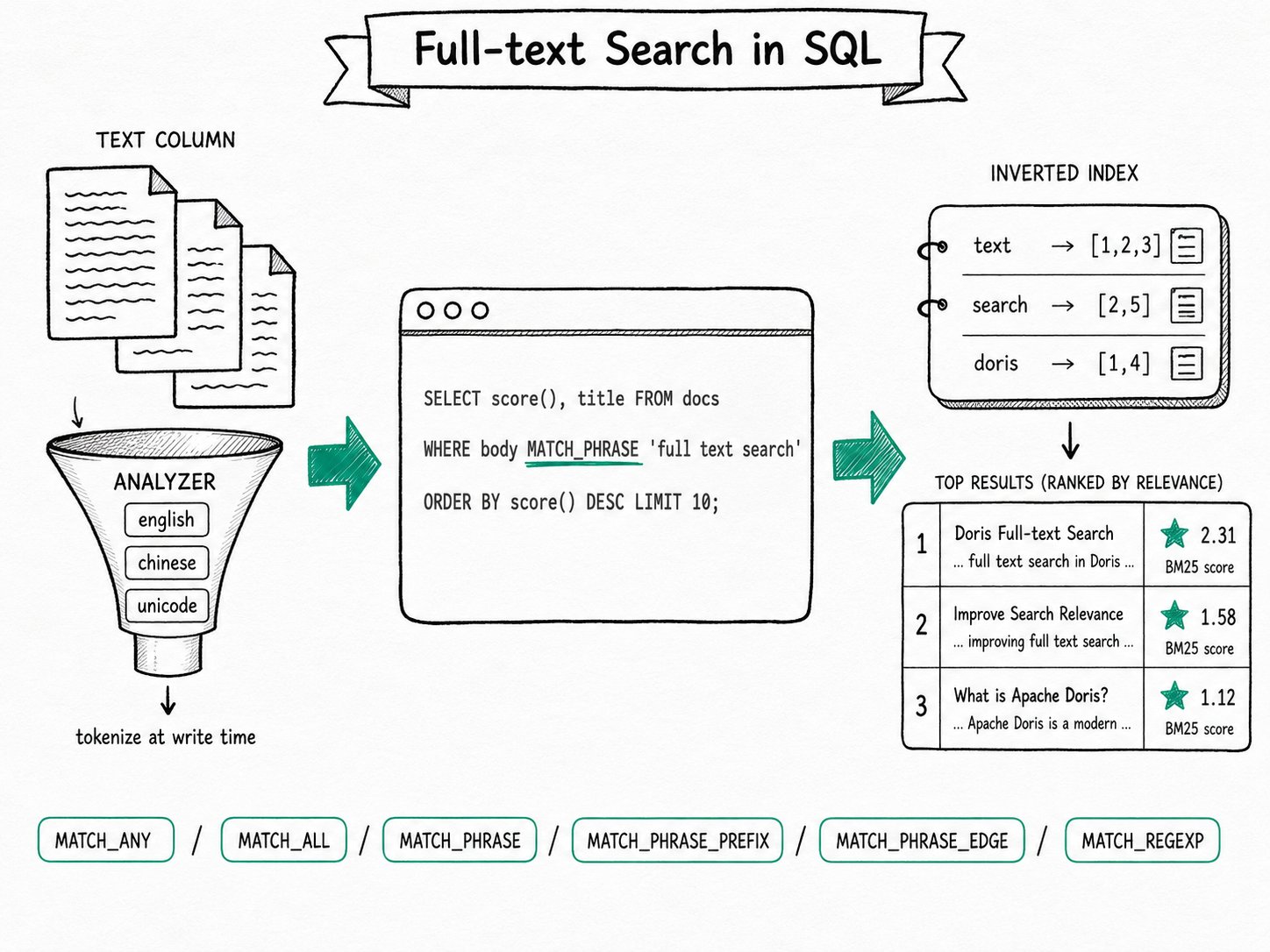
MATCH_*operators in SQL:MATCH_ANY,MATCH_ALL,MATCH_PHRASE,MATCH_PHRASE_PREFIX,MATCH_PHRASE_EDGE, andMATCH_REGEXP. You pick a tokenizer when you create the index and write a normal SQL query. The Apache Doris planner pushes the predicate down to the index, so no separate search cluster is required.
Why use full-text search in Apache Doris?
Apache Doris full-text search collapses real text retrieval and warehouse analytics into one engine, with token-aware operators that go far beyond LIKE substring matching. Most data warehouses give you LIKE '%foo%' and call it text search. That works for one row in ten thousand. It falls over the moment you need to find every order comment that mentions "battery" or "batteries", every log line that contains the phrase "connection refused", or every product whose description starts with "wireless".
LIKE reads each value end to end, byte by byte. The operator does not know that "Running" and "running" are the same word, or that "search engine optimization" is three terms in order rather than a substring. The usual workaround is to bolt Elasticsearch on the side, pay for a second cluster, and write fragile sync pipelines.
Apache Doris collapses that into one engine. The same table that serves your aggregations also serves your text queries, and the operator names look like SQL.
- Substring
LIKEfalls back to a full scan. The inverted index turns text predicates into a posting-list lookup. - Search-as-you-type, phrase search, and regex over tokens need match semantics that
LIKEcannot express. - Mixed structured and text predicates (
category = 'A' AND content MATCH_ANY 'doris') plan and execute in one query.
What is Apache Doris full-text search?
Apache Doris full-text search is a query feature built on top of the inverted index. You declare an INVERTED index on a STRING, TEXT, VARCHAR, or ARRAY<STRING> column, pick an analyzer, and the MATCH_* operators in your WHERE clauses get pushed down to the index. The base table stays a normal Apache Doris table, the same one your dashboards already query.
Key terms
- Analyzer (parser): the pipeline that turns raw text into searchable terms. Built-in choices include
none(exact match),english,chinese,unicode,standard, andicu. Custom analyzers can chain achar_filter, atokenizer, and one or moretoken_filterstages. - Term query: matches individual tokens.
MATCH_ANYis OR across terms,MATCH_ALLis AND across terms. - Phrase query: matches tokens in order and adjacent. Requires
"support_phrase" = "true"on the index for non-tokenizing parsers. score(): BM25 relevance score, available when you have a tokenized index, aMATCH_*predicate, and anORDER BY score() LIMIT N.
How does Apache Doris full-text search work?
Apache Doris full-text search works by tokenizing text at write time, recognizing each MATCH_* predicate in the Nereids optimizer, and pushing it down to the inverted index so non-matching rows are never decoded. The five-step lifecycle below covers parse, push-down, scoring, and combination with structured predicates.
- Tokenize at write time. When a row lands in a tablet, the analyzer splits each text value into terms. The inverted index records, for every term, which rows contain it and where.
- Parse the query. A
MATCH_*operator is recognized in Nereids as one ofMatch,MatchAny,MatchAll,MatchPhrase,MatchPhrasePrefix,MatchPhraseEdge, orMatchRegexp. Each carries the analyzer hint that controls how the query string itself is tokenized. - Push down to the index. The BE looks up the matching posting lists, intersects or unions them based on the operator, and returns a row bitmap. Non-matching rows are never decoded.
- Score, if asked. When the query has
SELECT score() ... ORDER BY score() DESC LIMIT N, Doris computes BM25 (term frequency, inverse document frequency, length normalization) and returns the top N. Without those three pieces, the predicate is a plain filter. - Combine freely. A single query can mix
MATCH_*with=,IN, range filters, joins, and aggregations. The optimizer treats text predicates as another pushdown.
Quick start
CREATE TABLE articles (
id INT,
title STRING,
body STRING,
INDEX idx_body (body) USING INVERTED
PROPERTIES("parser" = "english", "support_phrase" = "true")
) DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 1;
INSERT INTO articles VALUES
(1, 'Doris 4.0 release', 'Apache Doris adds BM25 scoring for full-text search'),
(2, 'Storage notes', 'Inverted indexes accelerate text and structured filters'),
(3, 'Vector primer', 'Approximate nearest neighbor search complements text search');
SELECT id, title, score() AS rel
FROM articles
WHERE body MATCH_ANY 'text search'
ORDER BY rel DESC LIMIT 3;
Expected result
+----+-------------------+----------+
| id | title | rel |
+----+-------------------+----------+
| 3 | Vector primer | 0.523248 |
| 2 | Storage notes | 0.346574 |
| 1 | Doris 4.0 release | 0.287682 |
+----+-------------------+----------+
MATCH_ANY 'text search' tokenizes the query into text and search, looks up both posting lists, and returns rows that contain either term. score() ranks them by BM25 once ORDER BY rel LIMIT 3 makes the optimizer treat it as a Top-N query.
Operator family at a glance
| Operator | Use it for |
|---|---|
MATCH / MATCH_ANY | Any-of-these-keywords search (OR) |
MATCH_ALL | Every-keyword-must-appear search (AND) |
MATCH_PHRASE 'a b' | Adjacent terms in order; supports ~slop and strict-order ~slop+ |
MATCH_PHRASE_PREFIX 'a b' | Phrase where the last term is a prefix; powers type-ahead |
MATCH_PHRASE_EDGE 'a b c' | First-term suffix, middle exact, last-term prefix |
MATCH_REGEXP '^abc.*' | Regex evaluated against tokens, not raw bytes |
When several inverted indexes with different analyzers exist on one column, append USING ANALYZER <name> to pick one at query time.
When should you use Apache Doris full-text search?
Use Apache Doris full-text search for log/trace search, e-commerce catalog search, mixed CJK and Latin content, search-as-you-type, and RAG pipelines that pair text matches with vector similarity. Reach for LIKE or n-gram indexes when you need intra-token substring search, fuzzy edit-distance matching, or result highlighting.
Good fit
- Log and trace search where users mix free text with structured filters (
level = 'ERROR' AND message MATCH_ANY 'timeout disconnect'). - E-commerce and catalog search where the same row has a price, a category, and a description.
- Mixed CJK / Latin content; the
chinese,unicode, andicuparsers handle both in one column. - Search-as-you-type, where
MATCH_PHRASE_PREFIXreturns completions without a separate auto-complete service. - RAG pipelines that pair text matches with embedding similarity. See Hybrid Search for combining
MATCH_*with vector distance in one SQL.
Not a good fit
- Substring search inside a single token (find every row where the column contains "ear" inside "year"). Tokenization deletes that view of the data. Use
LIKE, an N-Gram BloomFilter index, or a non-tokenized inverted index. - Fuzzy / edit-distance matching ("did you mean..."). Doris does not ship a built-in fuzzy operator today. Pre-process at write time with a phonetic or n-gram analyzer, or fuzz the query in your application.
- Result highlighting (returning the matched span with markup). Doris computes scores but does not emit highlight fragments today. Render highlights in the application from the matched terms.
- Cross-field relevance ranking like Elasticsearch's
dis_max.score()is per-predicate. UseSEARCH('title:foo OR body:foo')and tune at the application layer if you need richer scoring strategies.
Picking a tokenizer
The analyzer is the most consequential choice. It decides which queries can match, and the indexed terms are baked in at write time.
none: no tokenization. The whole value is one term. Good for IDs, tags, status enums, and exact-match filters.english: ASCII word-break with light normalization. Suitable for English prose.chinese: Chinese word segmentation withparser_modeoffine_grainedorcoarse_grained. Suitable for CJK content.unicode: language-agnostic word break for CJK and punctuation. A reasonable default for mixed content.standard: Unicode text-segmentation tokenizer; works for most languages.icu: ICU-based tokenizer for languages that need full Unicode segmentation rules (Thai, Khmer, mixed scripts).- Custom analyzers (3.1+): chain
edge_ngramfor prefix completion,word_delimiterfor camel case and hyphenated terms,lowercaseandasciifoldingfor case- and accent-insensitive search, and so on.
Changing the analyzer means rebuilding the index with BUILD INDEX.
Further reading
- Inverted Index: the index structure that powers these operators, including storage layout, build and compaction behavior.
- BM25 Relevance Scoring: how
score()is computed, when it activates, and how to tunek1andb. - Hybrid Search: combining
MATCH_*and vector ANN distance in one SQL, with pre-filter / fallback semantics. - Search Operators reference: the full operator catalog with slop syntax, prefix rules, and
USING ANALYZER. - Custom Analyzer guide: char filters, tokenizers, and token filters in detail.
- SEARCH Function: a single-string DSL that combines multiple operators across columns.
- Reciprocal Rank Fusion: the SQL pattern for fusing BM25 ranks with vector ranks when one scorer isn't enough.