Group Commit
TL;DR Apache Doris Group Commit batches many small
INSERT VALUESstatements or Stream Loads into one server-side transaction, so high-frequency clients stop drowning the FE in parse and plan work and the BE in tiny rowsets. Picksync_modeif the load should wait for visibility,async_modeif it should return as soon as the row is durable in the write-ahead log. Group Commit lifts the same workload from-235backpressure errors to over 100,000 rows per second on a single BE.
Why use group commit in Apache Doris?
Apache Doris Group Commit eliminates the per-write overhead that high-frequency clients impose on the FE planner and BE storage engine. Per-row INSERT INTO ... VALUES and tiny-batch Stream Loads are how a lot of real systems write to Doris. A microservice calls INSERT over JDBC every time a user clicks something. A Kafka consumer flushes whatever it has every few hundred milliseconds. An IoT collector pushes each event the moment it arrives. None of those clients can batch larger because the events don't exist yet. And without batching, every load opens its own transaction, takes its own trip through the FE planner, and produces a new tablet version. That is the one combination Doris's storage engine is unhappy with.
- High-frequency
INSERT VALUESsaturates the FE's parser and plan cache before it saturates the BE's CPU. - Small Stream Loads from streaming pipelines pile up tablet versions until background compaction can't keep up. The classic symptom is the
-235"too many segments" error. - Each load becomes its own transaction, which spends as much time on the commit handshake as on the actual data.
Group Commit folds many of those small writes into one transaction, on the server, without the client knowing or caring.
What is Apache Doris group commit?
Apache Doris Group Commit is a server-side buffer for small writes. The BE collects rows from many concurrent loads and commits them as one transaction every few seconds, or when the buffer fills. Group Commit layers on top of INSERT INTO ... VALUES, Stream Load, and JDBC prepared statements without changing their public API. You turn it on with one knob: a session variable for INSERT, an HTTP header for Stream Load, or a table property as the default. The mode you pick decides how the load returns.
Key terms
group_commit: session variable (for INSERT) and HTTP header (for Stream Load) that selects the mode. Values:off_mode,sync_mode,async_mode.sync_mode: rows are merged with concurrent loads on the BE, and the request blocks until the merged transaction commits and becomes visible.async_mode: rows are written to a write-ahead log on the BE, the request returns immediately with statusPREPARE, and the merged transaction commits later.WAL: per-BE write-ahead log used byasync_mode. Single-replica, lives on the receiving BE.group_commit_interval_msandgroup_commit_data_bytes: per-table flush triggers. Defaults: 10s and 128 MB.
How does Apache Doris group commit work?
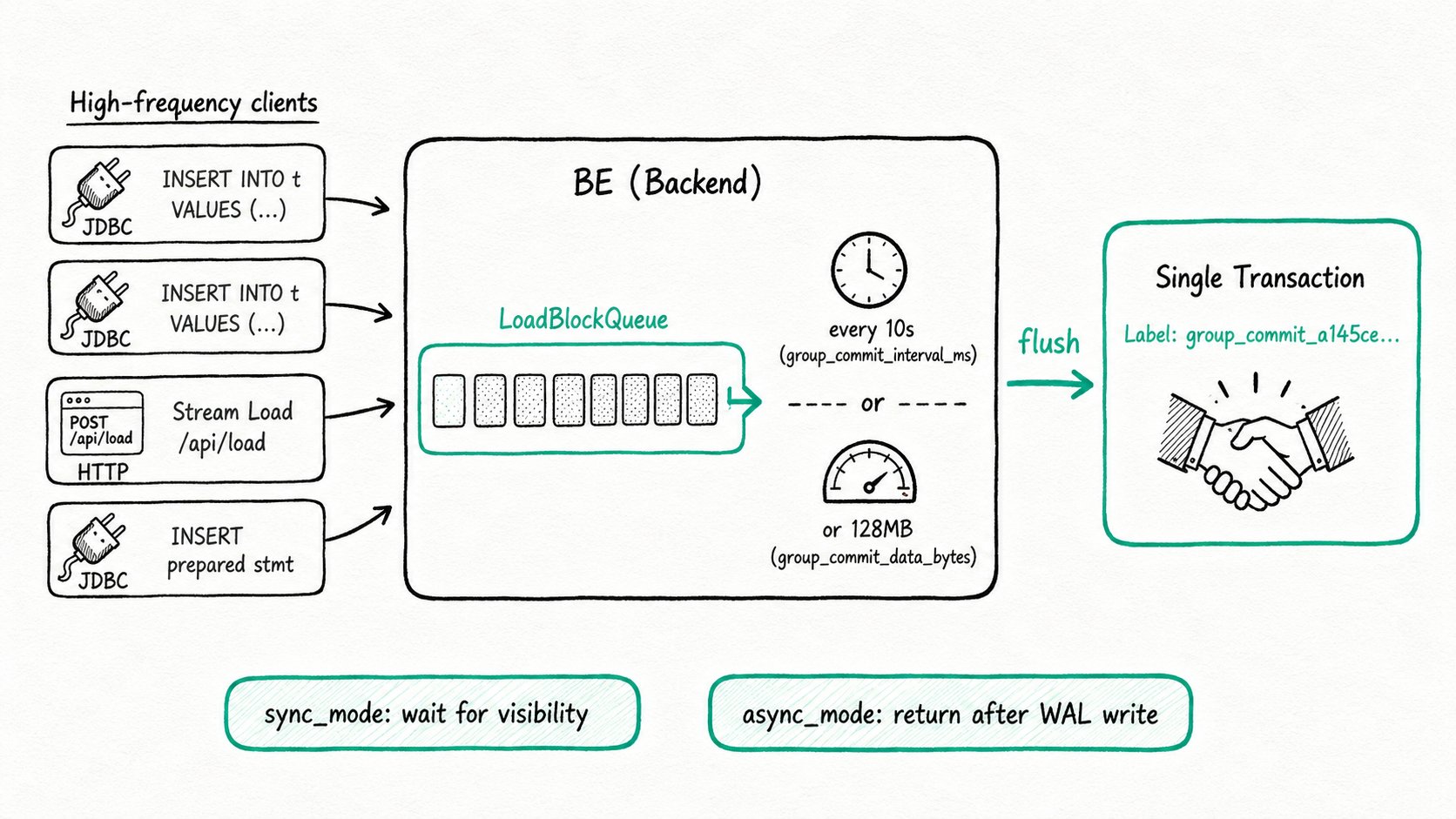
Apache Doris Group Commit funnels concurrent small loads into one shared BE queue per table, flushes the queue on a timer or size threshold, and commits the merged batch as a single FE transaction.
- Open or join a queue. A request lands on a BE. Instead of starting a fresh transaction, the BE drops the rows into a
LoadBlockQueuekeyed by table and the current open group-commit transaction. - (Async only) write to the WAL. In
async_mode, the rows are also persisted to the local WAL so the request can return as soon as they are durable. Insync_mode, this step is skipped. - Wait for a flush trigger. The BE flushes the queue when either
group_commit_interval_mselapses or the queue accumulatesgroup_commit_data_bytes. Both are per-table properties. - Commit one transaction for the batch. The BE pushes the merged batch through the storage engine and the FE commits exactly one transaction. The FE assigns one Label, prefixed
group_commit_, that every merged load shares. - Return.
sync_moderequests have been blocking up to this point and return now.async_moderequests already returned earlier; data becomes queryable here.
If a request hits a fallback condition (explicit transaction, user-specified Label, partial-column update, expressions in VALUES, low WAL disk in async_mode), Doris quietly takes the regular load path for that one request. The shape of the request is the only signal.
Quick start
CREATE TABLE events (
id BIGINT, ts DATETIME, payload STRING
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 4
PROPERTIES ("group_commit_interval_ms" = "1000");
SET group_commit = async_mode;
INSERT INTO events VALUES (1, NOW(), 'a');
INSERT INTO events VALUES (2, NOW(), 'b');
-- the second insert merges into the first one's transaction
Expected result
Query OK, 1 row affected (0.01 sec)
{'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'}
Both inserts return the same label and txnId, which is how you know they merged. The rows are not visible until the BE flushes (here, one second later, because the table set group_commit_interval_ms to 1000). For Stream Load, swap the session variable for a header: -H "group_commit:async_mode".
When should you use Apache Doris group commit?
Use Apache Doris Group Commit when many concurrent clients write small batches and you cannot batch larger on the client side.
Good fit
- Microservices doing per-event
INSERT INTO ... VALUESover JDBC at tens of TPS or more. - Kafka or Flink sinks that can only batch to sub-MB chunks and are tripping
-235errors on the BE. - IoT or click-stream pipelines where each event has to land within seconds but consolidating clients isn't an option.
- Tables where the tablet-version churn from individual loads is overwhelming background compaction.
Not a good fit
- Loads that need to be exactly one transaction with their callers' bookkeeping. Group Commit silently falls back when you use explicit
BEGIN ... COMMIT. For transactional sinks reach for Load Transactions directly. - Stream Load 2PC and writes that specify their own Label. Both bypass Group Commit; if you need exactly-once over checkpoints, stay with Stream Load 2PC.
- Partial-column updates. Group Commit does not support
partial_columns: trueand falls back to the normal load path. - Unique Key tables that need strict commit-order semantics. Group Commit does not preserve order across merged loads; declare a
function_column.sequence_colso the freshest version wins by user-supplied timestamp. - Single-load batches that are already large (hundreds of MB or more). Group Commit's coordination is wasted work compared with one regular load. Just submit the load.
Performance / numbers
From the Apache Doris 2.1.0 release notes:
- JDBC, 1 FE + 1 BE, TPC-H SF10 Lineitem, concurrency 20, fewer than 100 rows per insert: 106,900 rows/s on
async_mode. - Stream Load, 3 BEs, concurrency 10, sub-1 MB batches: 810,000 rows/s, 104 MB/s. The same workload without Group Commit returns
-235errors and stalls. - Stream Load, 3 BEs, 1 MB batches at concurrency 30: 2,077,723 rows/s.
Source: Apache Doris 2.1.0 release notes.
Further reading
- High-concurrency load optimization (Group Commit)
- Stream Load HTTP header reference
- INSERT INTO load
- Load Transactions: when you need explicit
BEGIN ... COMMITor 2PC - Stream Load: the synchronous HTTP load path that Group Commit batches on the server side.
- Apache Doris 2.1.0: Group Commit benchmarks
- Unique Key: the table model whose tight single-row UPDATE loops Group Commit is built to batch.