High-Concurrency Point Query
TL;DR Apache Doris is a columnar OLAP engine, but for primary-key equality lookups it switches lanes. Combine the Unique Key model with Merge-on-Write, row-format storage (
store_row_column), the short-circuit query path, and a server-sidePreparedStatement, and aSELECT * FROM t WHERE pk = ?query stops behaving like an OLAP query at all. One round-trip to the BE, one row back, no plan parsing, no fragment scheduling. That is how the same database serves a dashboard widget and a fact-table aggregation without standing up a second one.
Why use high-concurrency point query in Apache Doris?
The Apache Doris high-concurrency point query path exists for the long tail of "look up one row by ID" queries that hide inside most analytics workloads. A user-facing dashboard fetches the row for the customer who just clicked. A risk service reads a feature vector by entity ID on every API call. A recommendation backend pulls the latest profile per user. None of these are analytical, but the data lives next to the analytical data, and nobody wants to run a separate KV store just to serve them.
Default Apache Doris is a poor fit for that traffic, and the reasons are structural:
- Columnar storage reads many small column files to reconstruct one row, amplifying random IO on wide tables.
- The Frontend planner runs the same parse, analyze, optimize, and fragment pipeline whether the query reads one row or one billion. At thousands of QPS the FE CPU saturates before the BE notices.
- Every query opens its own coordinator, allocates fragments, and ships RPCs. That is overhead a
WHERE id = 42cannot afford. - Page Cache is column-oriented, and large analytical scans evict it constantly, so point queries miss cache exactly when they need it.
The Apache Doris high-concurrency point query is the answer to that traffic. It reshapes storage, planning, execution, and caching so a primary-key lookup costs one round trip and a few microseconds of FE CPU.
What is the Apache Doris high-concurrency point query?
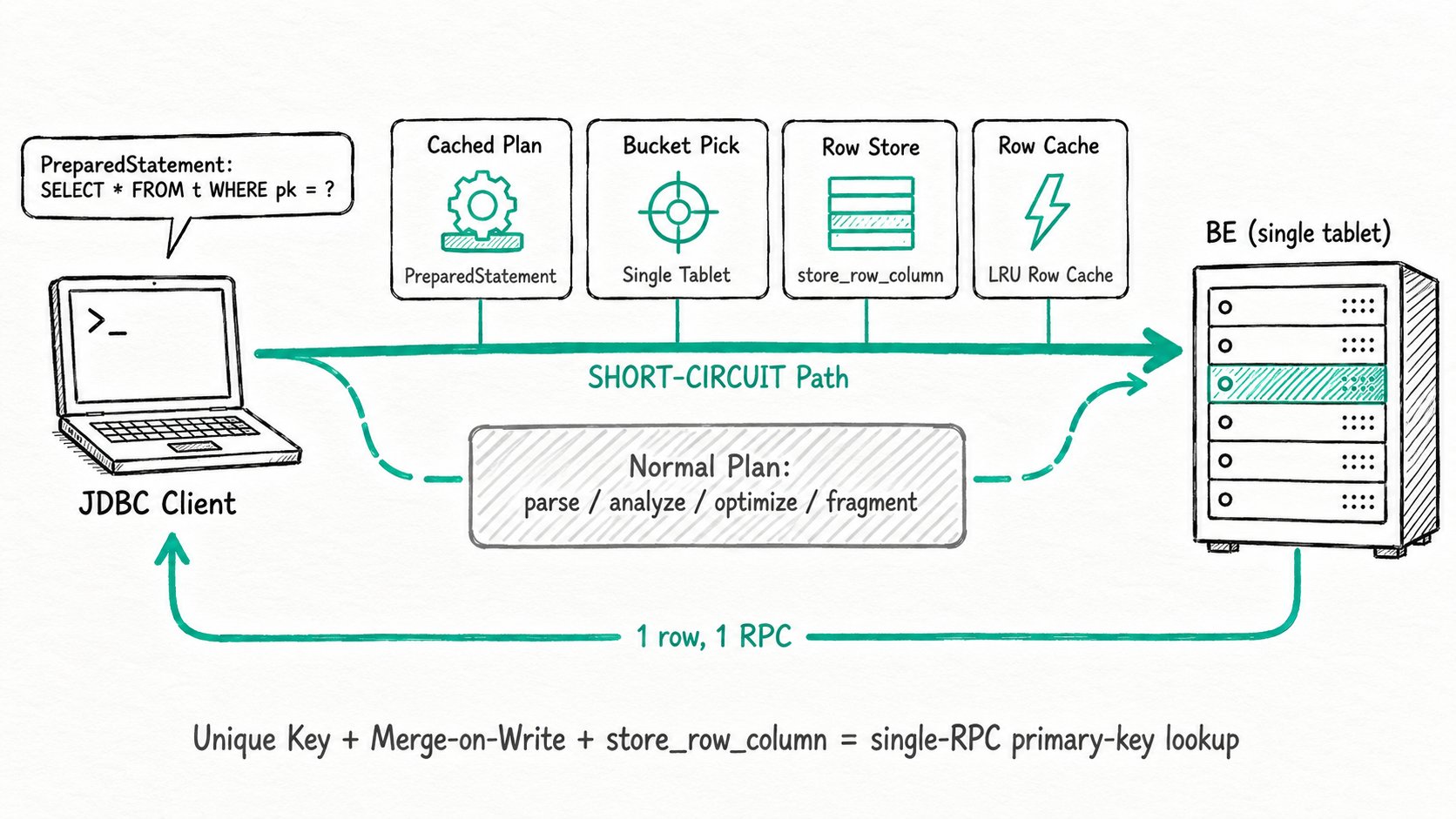
The Apache Doris high-concurrency point query is a four-layer optimization that activates automatically when the table and the query both fit a strict shape: a Unique Key table with Merge-on-Write and row-store enabled, queried with equality predicates that cover the full primary key. When the conditions hold, the planner takes the short-circuit path and the BE serves the row from a row-format column instead of stitching it from per-column files.
Key terms
Unique Key model: an Apache Doris table model where rows are addressed by a primary key. Withenable_unique_key_merge_on_write=true, the latest version of each row is materialized at write time, so reads do not merge versions on the fly.store_row_column: a table property that adds a hidden column holding each row in a row-encoded blob, so the BE reads one column instead of N to return a whole row.SHORT-CIRCUIT: a marker inEXPLAINoutput that appears once the planner has skipped the normal distributed plan and routed the query through a single-tablet, single-RPC path.PreparedStatement: server-side statement caching over the MySQL protocol. Apache Doris caches the parsed statement, output expressions, and descriptor table per session, then reuses them acrossEXECUTEcalls.Row Cache: a separate LRU cache that holds whole rows. It survives the eviction pressure that the columnar Page Cache suffers under mixed analytical and point-query workloads.
How does the Apache Doris high-concurrency point query work?
The Apache Doris high-concurrency point query path threads five layers together: storage layout, FE plan rewrite, short-circuit dispatch, server-side PreparedStatement reuse, and a BE row lookup with optional Row Cache.
- Storage layout. When you set
store_row_column=trueat table creation, the BE writes each row both into the columnar segments and into a row-encoded hidden column. From Apache Doris 3.0 onward you can scope this to a subset withrow_store_columns="k1,v1,v2"to limit the storage overhead. - Plan rewrite (FE). The Nereids rule
LogicalResultSinkToShortCircuitPointQuerychecks the query shape: single Unique table, equality conjuncts on every key column, no joins or subqueries, no aggregations. If everything matches, it flips theisShortCircuitQueryflag in theStatementContext. - Short-circuit dispatch. Instead of building fragments and shipping them, the FE resolves the bucket through
PartitionPruneV2ForShortCircuitPlan, picks the one tablet that can hold the key, and sends a single RPC to the BE that owns it. - Server-side
PreparedStatementreuse. WithuseServerPrepStmts=true, the FE caches theShortCircuitQueryContextper session UUID. SubsequentEXECUTEcalls skip parsing and planning entirely; only the parameter values change. - BE row lookup. The
point_query_executorlocates the row by key, reads the row-format column, and returns the bytes. The optional Row Cache short-circuits even the segment read on a hit.
Quick start
CREATE TABLE tbl_point_query (
k1 INT,
v1 VARCHAR(64),
v2 DECIMAL(27, 9)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1
PROPERTIES (
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true"
);
EXPLAIN SELECT * FROM tbl_point_query WHERE k1 = 42;
Expected result (excerpt)
0:VOlapScanNode
TABLE: tbl_point_query, PREAGGREGATION: ON
PREDICATES: k1 = 42 AND __DORIS_DELETE_SIGN__ = 0
partitions=1/1, tablets=1/1
SHORT-CIRCUIT
The SHORT-CIRCUIT line is the one that matters. Without it, the same DDL plus a query that cannot satisfy the conditions (a join, a missing key column, an inequality) falls back to the regular distributed plan. To collect the FE CPU savings on top, connect the client with jdbc:mysql://host:9030/db?useServerPrepStmts=true&cachePrepStmts=true and use PreparedStatement with ? placeholders. Confirm in fe.audit.log that repeat queries log Stmt=EXECUTE(...) rather than the raw SQL.
When should you use the Apache Doris high-concurrency point query?
The Apache Doris high-concurrency point query fits any online service that reads a row by primary key per request, especially when the data already lives in a Unique Key table alongside the analytical workload.
Good fit
- Online services that read a row by primary key per request: user profiles, feature vectors, status flags, lookup tables.
- Mixed OLAP and point-query workloads where a separate KV store would duplicate data and operational load.
- High-QPS clients that already use
PreparedStatementover JDBC. - Wide Unique Key tables where you can scope the row store to a few hot columns with
row_store_columns.
Not a good fit
- Range queries (
k1 BETWEEN 1 AND 1000). The short-circuit path requires equality on every key column. Run them through a normal scan and lean on data pruning. - Multi-row aggregations or joins. Even a
GROUP BY pkdisqualifies the rewrite. Run them as ordinary OLAP queries. - Lookups by a non-key column. Add a secondary or inverted index, not row-store.
- Tables you forgot to enable row-store on at create time.
store_row_columnis only settable inCREATE TABLE. If you need it on an existing table, recreate and reload. - Pure write-heavy workloads with rare reads. Row-format storage inflates space and write IO. If you barely read by key, skip it and live with column-only storage.
Performance and verification
Apache Doris reports that enabling server-side PreparedStatement on top of the short-circuit path delivers more than a 4x throughput improvement when FE CPU is the bottleneck. This is the same 4x cited from the prepared-statement angle in the Prepared Statement card — one combined gain, not two stackable ones. Numbers depend on row width, row cache hit rate, and how many FE Observers absorb traffic, so treat that as a planning floor, not a benchmark.
Two checks tell you the path is live:
EXPLAINon the query showsSHORT-CIRCUITin the scan node.fe.audit.logshowsStmt=EXECUTE(...)for repeat lookups, not the raw SQL string.
If the FE CPU is still the ceiling, scale Observers and use JDBC load balancing (jdbc:mysql:loadbalance://host1,host2,host3/db?useServerPrepStmts=true&cachePrepStmts=true) to spread connections. On compute-storage decoupled deployments, also consider SET GLOBAL enable_snapshot_point_query=false and the BE flag enable_file_cache_keep_base_compaction_output=1 so Base Compaction output stays in the file cache.
Further reading
- High-Concurrency Point Query (full guide)
- Row Store storage layout
- Index overview: secondary, bloom, inverted
- Data pruning: making non-point queries fast
- MPP Architecture: the full distributed execution path the point-query short-circuit is built to skip.
- Unique Key: the table model point query pairs with via
store_row_columnto act as a KV store.