Hybrid Search
TL;DR Apache Doris hybrid search combines full-text matching and vector similarity in one SQL query on one table. The table carries both an inverted index and an ANN index on the columns you would normally split between Elasticsearch and a vector database. A single
WHEREclause mixesMATCH_ANYwithl2_distance_approximateto filter and rank in one shot.
Why use hybrid search in Apache Doris?
Apache Doris hybrid search collapses two retrieval modes into one SQL query so you do not run a separate search cluster next to your warehouse. Search workloads rarely pick just one retrieval mode. A user searching "lightweight running shoes for trail" wants exact matches on "running" and "trail", but also semantic matches against listings that talk about "off-road" or "rugged terrain". The typical fix, splitting work across two systems, comes with the typical costs:
- Two ingest pipelines that have to stay in sync, or recall drifts.
- Two query languages, glued together by hand-written fusion logic.
- Two clusters to size, monitor, and pay for.
Apache Doris collapses that into one table and one SQL statement, served by the same MPP engine that runs the rest of your queries.
What is Apache Doris hybrid search?
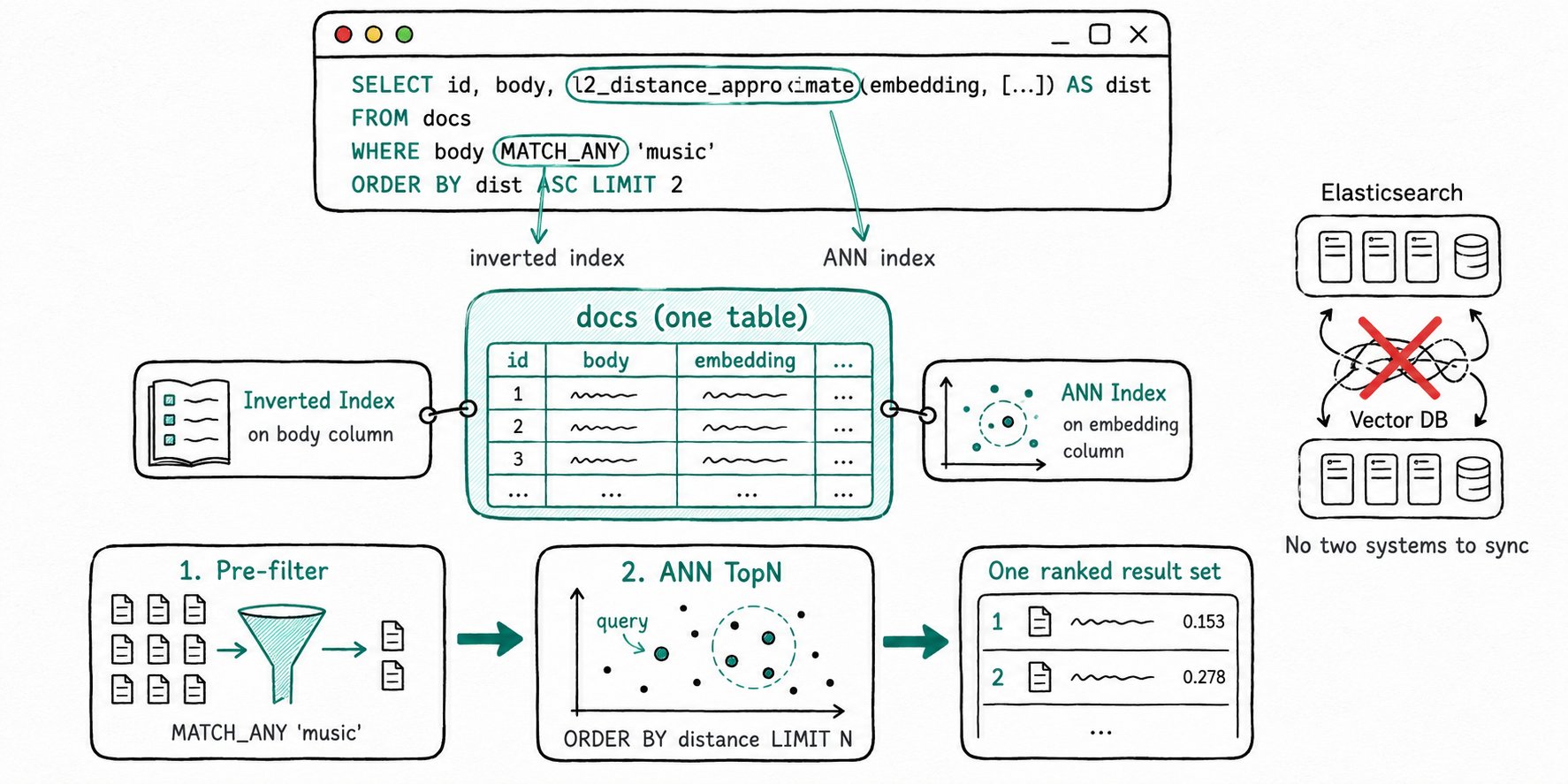
Apache Doris hybrid search is a query pattern, not a separate engine. A single table can carry both an inverted index (which powers MATCH_* operators and BM25 scoring via score()) and an ANN index (which powers approximate vector distance functions like l2_distance_approximate and inner_product_approximate). The Apache Doris planner reads from both indexes in one query and returns one ranked result set.
Key terms
- Inverted index: a full-text index on a
STRINGcolumn. Tokenizers includeenglish,standard, and Chinese. - ANN index: an approximate-nearest-neighbor index on an
ARRAY<FLOAT>column. Backends are HNSW, IVF, and IVF on-disk. - Pre-filter: the Apache Doris default strategy. Apply scalar and text predicates first, then take TopN by vector distance over the rows that survive.
How does Apache Doris hybrid search work?
Apache Doris hybrid search builds both indexes at load time, then runs them in a single MPP plan that filters with the inverted index and ranks with the ANN index.
- Index build at load time. When you ingest data, the inverted index tokenizes each text column; the ANN index builds an HNSW graph or IVF codebook over each vector. Both live alongside the base table, in the same storage tier.
- Plan in one shot. When a query mixes
MATCH_*operators and a vector distance function, the planner routes the text predicate to the inverted index and the distance function to the ANN index. There is no second query, no client-side join. - Filter, then rank. Apache Doris pre-filters with the inverted index first, then runs ANN TopN over the surviving row set. This is the inverse of the common "ANN first, filter after" pattern, and it keeps recall high when filters are selective.
- Adaptive fallback. If the filter is so selective that ANN traversal would skip too many candidates, Apache Doris falls back to brute-force vector scoring on the filtered set. The same SQL keeps working; only the execution path changes.
- Return. One sorted, limited result set. No external fusion service, no application-side ranking glue.
Quick start
CREATE TABLE docs (
id INT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
body STRING NOT NULL,
INDEX idx_body(body) USING INVERTED PROPERTIES("parser"="english"),
INDEX idx_vec(embedding) USING ANN
PROPERTIES("index_type"="hnsw","metric_type"="l2_distance","dim"="8")
) DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 1;
SELECT id, body,
l2_distance_approximate(embedding, [0.1,0.1,0.2,0.2,0.3,0.3,0.4,0.4]) AS dist
FROM docs
WHERE body MATCH_ANY 'music' -- inverted index pre-filter
ORDER BY dist ASC -- ANN TopN over the filtered rows
LIMIT 2;
Expected result
+----+---------------------+----------+
| id | body | dist |
+----+---------------------+----------+
| 1 | this is about music | 0.663325 |
| 3 | latest music trend | 1.280625 |
+----+---------------------+----------+
MATCH_ANY 'music' shrinks the candidate set to rows whose body contains "music"; the ANN index then ranks those rows by distance to the query vector and returns the closest two.
When should you use Apache Doris hybrid search?
Use Apache Doris hybrid search when you need keyword filtering and vector similarity over the same data, in one SQL query, without running a separate vector database.
Good fit
- RAG retrieval where keyword filters (tenant, doc type, date range) need to narrow the corpus before semantic ranking.
- Product or catalog search that mixes structured filters (brand, price, in-stock) with embedding similarity over title and description.
- Log and document search where users routinely mix "must contain X" with "looks like Y".
- Workloads that already store the data in Doris for SQL analytics and don't want to ship a copy to a vector database.
Not a good fit
- Pure billion-scale ANN with no filters and no analytics. A dedicated vector DB may use less memory and cost less per query.
- Tables that need
AGGREGATE KEY, orUNIQUE KEYwithout merge-on-write. ANN indexes today requireDUPLICATE KEYor MoWUNIQUE KEYtables. - Nullable vector columns. The vector column must be
NOT NULL ARRAY<FLOAT>with a fixed dimension that matches the index. - Workloads that depend on Reciprocal Rank Fusion across two scorers. Doris fuses via SQL
ORDER BY, not RRF. If you need RRF, issue two queries from the application and fuse the rankings yourself.
How it compares
| Aspect | Doris hybrid search | Elasticsearch + vector DB | Vector DB only |
|---|---|---|---|
| Ingest pipelines | one | two, kept in sync | one |
| Query path | one SQL | app-side fusion | one API |
| Filter expressiveness | full SQL (joins, range, agg) | DSL, limited joins | tag and metadata only |
| Analytics on same data | full MPP SQL | limited | none |
Hybrid search in Doris pays off when you already want joins or aggregations on the same data. For pure vector lookup at extreme scale, a dedicated vector DB is usually simpler to operate.
Further reading
- Vector Index: the ANN index that powers the vector half of hybrid search.
- Full-text Search: the inverted-index side, including tokenizers and the
MATCH_*operator family. - BM25 Relevance Scoring: how
score()ranks text matches; pair it with vector distance for the two-scorer pattern. - Reciprocal Rank Fusion: the SQL pattern for combining BM25 and vector rankings when single-pass fusion is not enough.
- Embedding:
EMBED()produces the vectors the ANN index reads from. - Vector index overview: full reference for index properties and query patterns.
- Inverted index overview: tokenizers, MATCH operators, and analyzer choices.
- Vector search practical guide: end-to-end walkthrough from data prep to tuning.
- AI on Doris: how hybrid search fits with the rest of Doris's AI features.