Incremental Materialized View
TL;DR An Apache Doris incremental materialized view is a partitioned async MTMV with
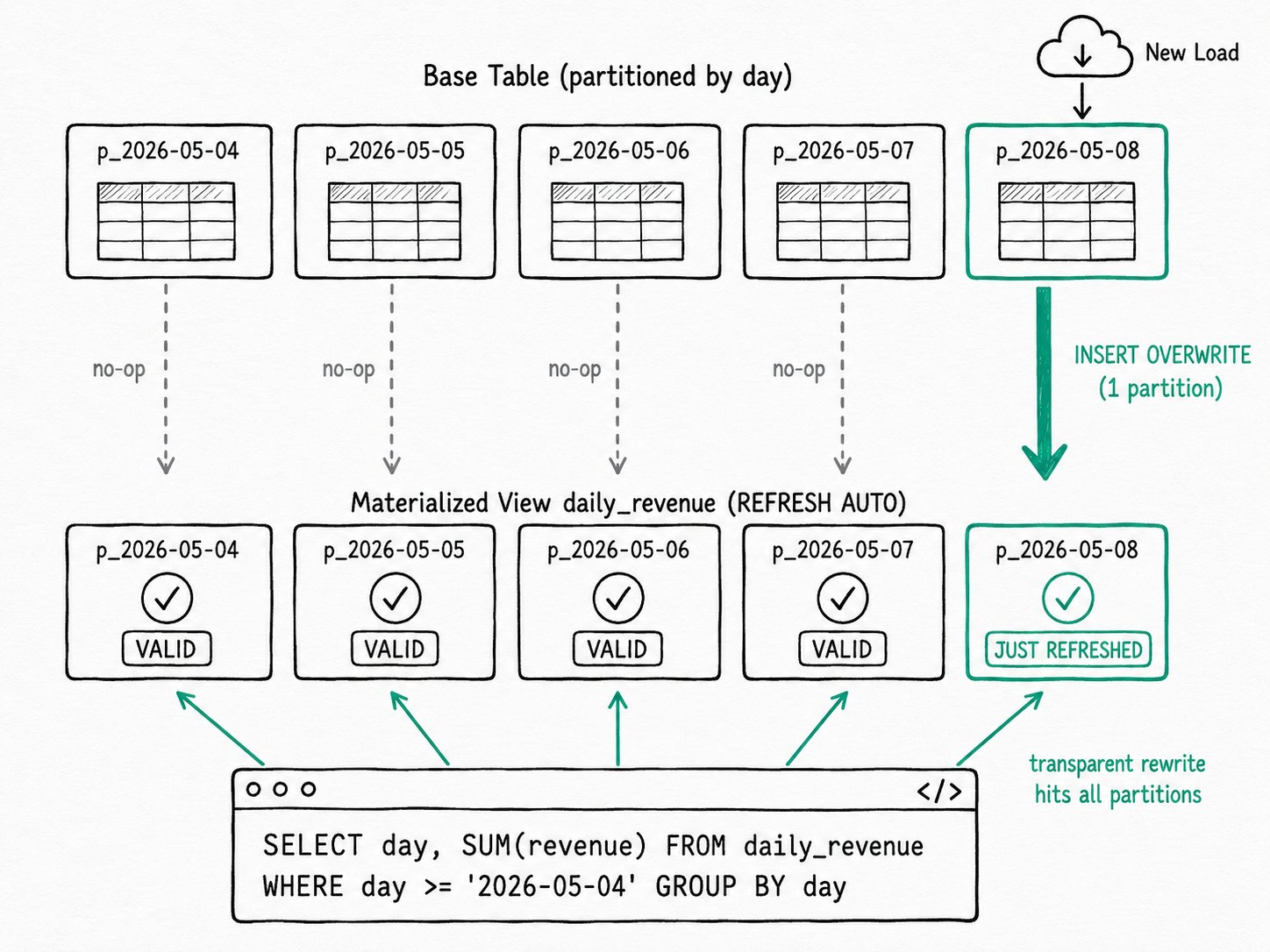
PARTITION BYandREFRESH AUTO. Apache Doris tracks staleness per partition, so today's load triggers a refresh of only today's view partition while the other 29 days stay untouched. Queries that span fresh and stale days still hit the view: the optimizer reads valid partitions from the MV andUNION ALLs the stale ones from the base table.
Why use incremental materialized views in Apache Doris?
Apache Doris incremental materialized views keep partitioned dashboards fresh by recomputing only the partitions whose base data changed, instead of re-aggregating the whole view on every load. You have a fact table partitioned by day and a materialized view that aggregates it for tomorrow's dashboard. Today's load only writes into today's partition, but a naive refresh recomputes the whole view anyway. The refresh re-aggregates 29 days that did not change, runs for an hour, and finishes after the dashboard is already stale.
- A 30-day partitioned fact table where each load only touches the latest day. A full refresh re-aggregates 29 days that did not change.
- BI dashboards that fall behind the load schedule because the MV refresh window is longer than the load interval.
- Hive- or Iceberg-backed lakehouse tables where rereading every partition through object storage is slow and expensive.
REFRESH AUTO on a partitioned async MV cuts that down to what actually changed. Apache Doris tracks staleness per partition, runs INSERT OVERWRITE only on the partitions whose base data moved, and leaves the rest of the view exactly as it was.
What is an Apache Doris incremental materialized view?
An Apache Doris incremental materialized view is a partitioned async materialized view (an MTMV) created with REFRESH AUTO. Apache Doris derives the view's partitions from one base table you point at in PARTITION BY, with an optional DATE_TRUNC that rolls daily base partitions up to monthly view partitions. When a base partition's data changes, only the view partition mapped to it is flagged invalid. The next refresh runs INSERT OVERWRITE for the invalid partitions, one statement at a time.
Key terms
MTMV: the internal table type backing every async MV. It's a Duplicate-model OLAP table whose partitions are managed by the refresh job, not by you.REFRESH AUTO: the refresh method that tries partitioned incremental refresh first and falls back to full refresh only when the MV's definition can't be partition-derived.REFRESH COMPLETEis the opt-out.Partition derivation: the FE's analysis that maps an MV partition column back to a base partition column through the MV's SQL. If derivation fails, Doris rejects the partition clause at create time.Partition invalidation: the per-partition stale flag set when base data backing that partition changes. Visible viaSHOW PARTITIONS FROM <mv>.Partition-granularity transparent rewrite: the rewriter can read valid MV partitions andUNION ALLthe rest from the base table, so a single stale partition no longer disqualifies the whole MV.
How does an Apache Doris incremental materialized view work?
An Apache Doris incremental materialized view works by mapping each MV partition back to a base partition at create time, flagging only the affected MV partitions when a load lands, and rebuilding just those partitions through INSERT OVERWRITE on the next refresh. The five-step flow below covers declaration, materialization, invalidation, refresh, and partition-granularity rewrite.
- You declare the partition mapping.
PARTITION BY (DATE_TRUNC(o_orderdate, 'MONTH'))tells Apache Doris to derive the MV's partitions fromorders.o_orderdate. Internal tables and Hive tables both work; Iceberg, Paimon, and Hudi gained partitioned refresh in 3.1, with Iceberg and Paimon also supporting automatic detection of base data changes — Hudi requires manual refresh. - Apache Doris materializes a partition layout. At create time, the FE walks the base partitions, applies the roll-up function, and emits matching MV partitions. New base partitions trigger new MV partitions on the next refresh.
- Loads invalidate partitions, not the whole view. A load that lands in
orderspartitionp_2026_05_08only flags the MV partitions whose key set covers that day. Loads on referenced non-partitioned tables still invalidate everything by default; list those tables inexcluded_trigger_tablesif you know they only insert and never update. - The refresh job rebuilds invalid partitions only. Each invalid partition becomes one
INSERT OVERWRITE. Therefresh_partition_numproperty controls how many partitions ride per statement (default 1), trading transactional granularity for throughput. A failure stops the task without rolling back partitions that already landed. - The optimizer rewrites at partition granularity. A query that touches both fresh and stale days reads the fresh days from the MV and the stale day from the base table through
UNION ALL. Setgrace_periodif you want the rewriter to accept partitions that are stale by less than N seconds.
Quick start
CREATE TABLE lineitem (
l_orderkey INT, l_extendedprice DECIMAL(15,2),
l_discount DECIMAL(15,2), l_ordertime DATETIME
) DUPLICATE KEY(l_orderkey)
PARTITION BY RANGE(l_ordertime)
(FROM ('2026-05-01') TO ('2026-05-09') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3;
CREATE MATERIALIZED VIEW daily_revenue
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 HOUR
PARTITION BY (DATE_TRUNC(l_ordertime, 'DAY'))
DISTRIBUTED BY RANDOM BUCKETS 2 AS
SELECT DATE_TRUNC(l_ordertime, 'DAY') AS d,
SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM lineitem GROUP BY DATE_TRUNC(l_ordertime, 'DAY');
Expected result
After loading new rows into the 2026-05-08 base partition only, SHOW PARTITIONS FROM daily_revenue confirms that one MV partition is the only one that ticked:
+--------------+--------+---------------------+
| PartitionName| State | VisibleVersionTime |
+--------------+--------+---------------------+
| p_20260507 | NORMAL | 2026-05-07 14:00:02 |
| p_20260508 | NORMAL | 2026-05-08 15:00:01 |
+--------------+--------+---------------------+
The earlier partitions kept their old VisibleVersionTime because nothing recomputed them. Only p_20260508 rebuilt, in one INSERT OVERWRITE statement against one day's data.
When should you use an Apache Doris incremental materialized view?
Use Apache Doris incremental materialized views for append-mostly fact tables partitioned by day or hour, multi-layer DWD/DWS/ADS modeling, and Hive/Iceberg/Paimon lakehouse tables you want to materialize locally. Skip them for sub-second freshness (use a sync MV), unpartitioned base tables, and Hudi tables where Apache Doris cannot detect base data changes automatically.
Good fit
- Append-mostly fact tables partitioned by day or hour, with downstream dashboards that aggregate by the same column.
- Multi-layer (DWD, DWS, ADS) modeling where a high-frequency base layer feeds a coarser-grained presentation layer through partition-mapped MVs.
- Hive, Iceberg (3.1+), or Paimon (3.1+) lakehouse tables that you want to materialize into Doris-local storage with cheap incremental refresh.
- Long-window queries where partition-granularity rewrite still serves results from the MV even while the most recent partition is briefly stale.
Not a good fit
- Real-time freshness in the seconds. Use a sync materialized view instead; sync MVs are merged into the base table's write path.
- Tables that don't have a partition column. Without a partition mapping the MV degrades to a full refresh, and you get none of the incremental benefits.
- MV definitions that can't be partition-derived. Apache Doris rejects the
PARTITION BYclause at create time when any of the eight derivation rules fails: aggregating the partition column (min(o_orderdate)), placing it on the NULL-generating side of an OUTER JOIN, dropping it fromGROUP BYor a window'sPARTITION BY, using a roll-up function other thanDATE_TRUNC, and so on. - Hudi base tables. Apache Doris cannot detect base data changes on Hudi today, so only manual refresh is meaningful, and the incremental decision can't be made automatically.
- Tables you also write to from Spark or Flink without going through Apache Doris. The metadata cache won't see those writes, so the MV will think it's still in sync. Force a refresh manually after each external write, or pick a different acceleration path.
Further reading
- Async materialized view overview: refresh modes, transparent rewrite, lakehouse caveats
- Async MV best practices: scenario assessment, refresh strategy, partitioned MV examples
CREATE ASYNC MATERIALIZED VIEW: full syntax, partition derivation rules, table properties- Sync materialized view: real-time, single-table acceleration
- Preaggregation and Rollup: the per-load Aggregate Key path and sync MV / ROLLUP companions to async MVs.
- Query Cache: another preaggregation path; precompute via MV or cache on first read.
- Data Lineage: how the audit log's
chosen_m_viewscolumn surfaces which MVs actually serve traffic. - Iceberg: a common base-table source for incremental MVs — snapshot diffs make change capture cheap.