Managing Lake Tables
TL;DR Once a lake catalog is connected, Apache Doris treats Iceberg, Hive, and Paimon tables like first-class objects. Supported operations include
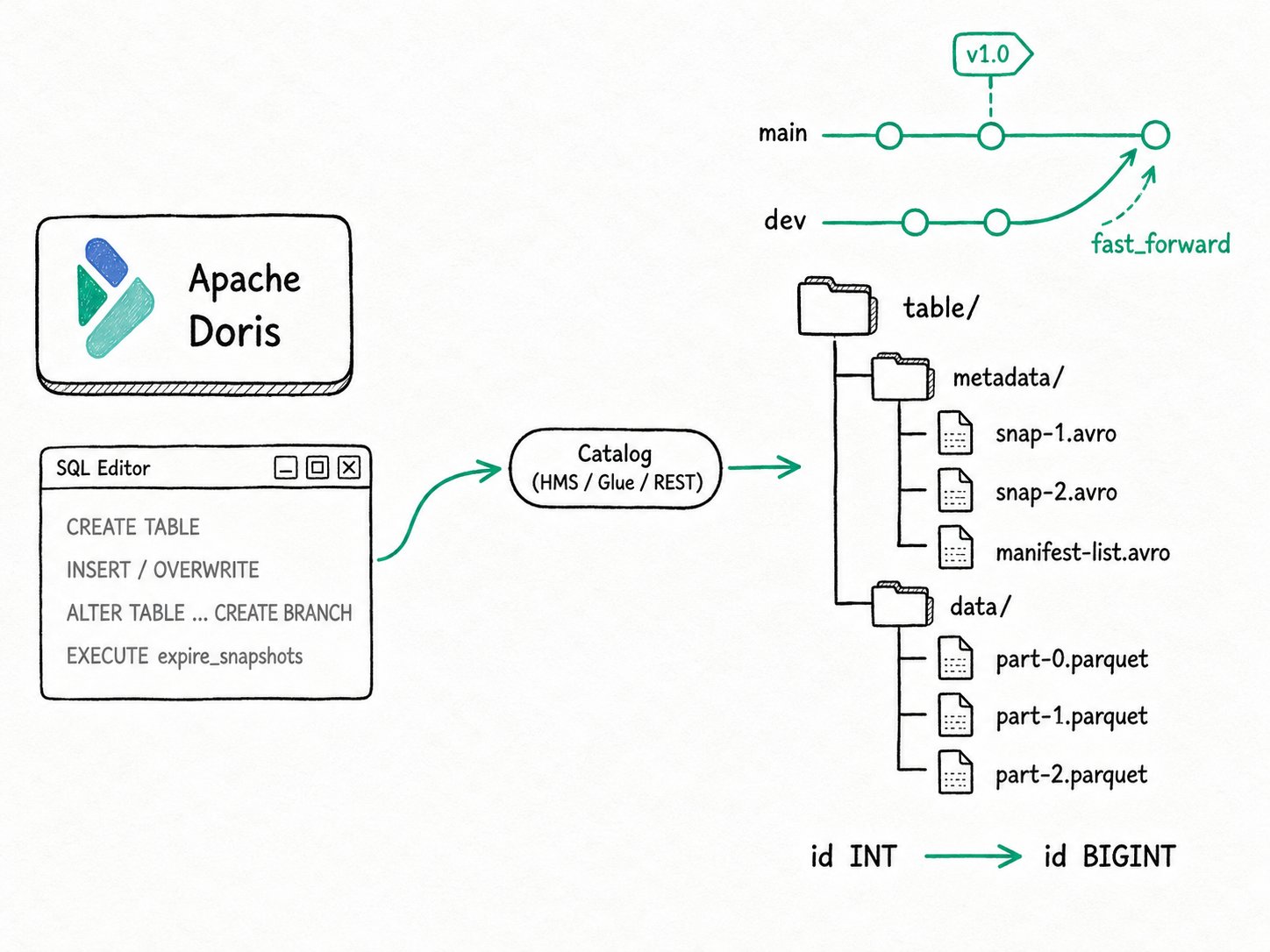
CREATE TABLE,INSERT,INSERT OVERWRITE,UPDATE,DELETE, schema and partition evolution, Iceberg branches and tags, snapshot time travel, and maintenance likeexpire_snapshotsandrewrite_data_files. All metadata commits go through the catalog (HMS, Glue, REST, JDBC), so Trino, Spark, and Flink see the same writes.
Why use Apache Doris lake table management?
Apache Doris lake table management lets one cluster handle both federated reads and lake writes through SQL, so teams stop running a separate Spark or Flink cluster just to mutate Iceberg, Hive, or Paimon tables. Most lakehouse engines start as readers. You connect them to an Iceberg catalog, query a few tables, and then run into the same wall: any write has to go back through Spark or Flink. So you end up running two clusters, learning two SQL dialects, and reconciling two sets of permissions for the same data. Multi-catalog federation built on top of catalog integrations is the read half of the story; this card is the write half.
Apache Doris does both sides. The same SQL that queries a Doris internal table can create an Iceberg table, append rows, overwrite a partition, evolve the schema, fork a branch, expire old snapshots, and compact small files. The cluster that powers the dashboards also maintains the lake.
- One engine for federated reads and lake writes, instead of pinning a Spark job to every ETL step.
- Standard SQL DDL and DML against Iceberg, Hive, and Paimon, so the team is not learning a new dialect per format.
- Catalog-native commits. An Apache Doris
INSERTinto Iceberg shows up in Trino, Spark, and Flink with no extra sync step.
What is Apache Doris lake table management?
Apache Doris lake table management is the write and lifecycle surface the engine exposes on top of an external catalog, covering DDL, DML, schema evolution, branches, tags, and table-action maintenance. After CREATE CATALOG connects Apache Doris to HMS, Glue, REST, JDBC, S3 Tables, or DLF, the catalog becomes a writable namespace. Apache Doris translates CREATE TABLE, ALTER TABLE, INSERT, UPDATE, DELETE, and MERGE INTO into the right manifest writes, snapshot commits, and metastore calls for each format.
For the connection layer itself, see Multi Catalog and the Lakehouse overview. This card is about what you do after the catalog is connected.
Key terms
Catalog: the connection object that points Apache Doris at a metastore and a storage system. Writes commit through the catalog's API.Snapshot: an immutable version of an Iceberg or Paimon table. Every write produces a new one; reads can target a specific snapshot.BranchandTag: named references to snapshots in Iceberg and Paimon. A branch moves with new commits, a tag is fixed.Schema evolution: adding, dropping, renaming, or promoting columns without rewriting data files.Table action: a maintenance operation invoked throughALTER TABLE ... EXECUTE, such asexpire_snapshots,rewrite_data_files, orrewrite_manifests.
How does Apache Doris lake table management work?
Apache Doris lake table management runs in five stages: connect a catalog, plan against the right format, stage data files on BEs, commit atomically through the catalog API, and maintain tables in place with SQL.
- Connect a catalog.
CREATE CATALOG iceberg_ctl PROPERTIES (...)registers a metastore and a storage backend. Apache Doris caches metadata, but writes always commit through the catalog's API so other engines stay in sync. - Plan against the right format. The Nereids planner sees an external table and routes the statement through the format's writer: Iceberg manifest commits, Paimon delta commits, or Hive partition rewrites.
- Stage data files. BE writers produce Parquet (or ORC for Hive) data files in the table location. Iceberg V2 deletes go into Position Delete files, V3 deletes go into Puffin Deletion Vectors, Paimon writes LSM-tree segments.
- Commit atomically. The FE assembles the manifest list and asks the catalog to swap the table pointer. If the commit conflicts with a concurrent write, Apache Doris detects the snapshot mismatch and the statement fails cleanly.
- Maintain in place. Maintenance runs as SQL on the same cluster:
EXECUTE expire_snapshots,EXECUTE rewrite_data_files,EXECUTE rewrite_manifests,ALTER TABLE ... CREATE BRANCH, and so on.
What each format supports is uneven. Iceberg is the most complete: full DDL and DML, V2 and V3 delete strategies, branches, tags, partition evolution, and table actions. Paimon supports reads, time travel, branches, and tags through Apache Doris; writes for primary-key Paimon tables still go through Flink. Hive supports CREATE, INSERT, INSERT OVERWRITE, and CTAS, but partition-targeted writes and concurrent INSERT OVERWRITE on the same partition need the same care you would take from Spark or Hive itself. Hudi is read-only today.
Quick start
SWITCH iceberg_ctl;
CREATE DATABASE IF NOT EXISTS sales;
CREATE TABLE sales.orders (
order_id BIGINT, region STRING, amount DECIMAL(10,2), ts DATETIME
) PARTITION BY LIST (day(ts), region) ();
INSERT INTO sales.orders VALUES (1, 'bj', 99.50, '2026-05-08 10:00:00');
ALTER TABLE sales.orders CREATE BRANCH dev;
INSERT INTO sales.orders@branch(dev) VALUES (2, 'sh', 12.00, '2026-05-08 11:00:00');
SELECT COUNT(*) FROM sales.orders; -- main branch
SELECT COUNT(*) FROM sales.orders@branch(dev); -- dev branch
ALTER TABLE sales.orders EXECUTE expire_snapshots ("retain_last" = "5");
Expected result
+----------+
| count(*) |
+----------+
| 1 | -- main
| 2 | -- dev
+----------+
The main branch keeps the production row, the dev branch carries an extra row, and expire_snapshots trims old metadata. Trino or Spark pointed at the same REST or HMS catalog will read the same snapshots Doris just produced.
When should you use Apache Doris lake table management?
Apache Doris lake table management fits federated ELT into Iceberg or Hive, git-style Iceberg branches for dev workflows, reproducible time-travel reads, scheduled maintenance like expire_snapshots and rewrite_data_files, and SQL-driven schema and partition evolution. It is not a fit for high-concurrency single-row OLTP updates, real-time CDC into plain Hive, or any write into Hudi (read-only today).
Good fit
- Federated ELT pipelines that read from JDBC or Kafka catalogs and land curated data into Iceberg or Hive without leaving Apache Doris. See the Lakehouse overview for the write-back pattern.
- Team workflows that need git-style isolation on Iceberg:
ALTER TABLE ... CREATE BRANCH dev, validate against the dev branch, thenEXECUTE fast_forwardto publish. - Time-travel reads and reproducible backfills with
FOR VERSION AS OForFOR TIME AS OFon Iceberg, Paimon, and Hudi. - Maintenance on a schedule: nightly
expire_snapshots, hourlyrewrite_data_filesto compact small files from streaming jobs, periodicrewrite_manifestsafter big partition reshuffles. - Schema and partition evolution from a familiar SQL surface:
ADD COLUMN,MODIFY COLUMN,ADD PARTITION KEY day(ts),REPLACE PARTITION KEY ts_day WITH day(ts).
Not a good fit
- High-concurrency single-row OLTP-style updates. Lake commits are snapshot-based, so the per-statement overhead is too high. Use an Apache Doris Unique Key table for that workload.
- Real-time row-level upserts on Hive. Hive lacks delete files or merge-on-read. Use Iceberg V2 or V3, or Paimon primary-key tables, when CDC needs to land row by row.
- Partition-targeted
INSERT INTOon Hive. Apache Doris writes to the partition based on column values, not on aPARTITION (...)clause; if you need explicit partition routing on Hive, useINSERT OVERWRITEor do the load through Spark. - Concurrent
INSERT OVERWRITEon the same Hive partition from multiple writers. Hive has no atomic swap for partition data, so the result can be partial; serialize the writes or move that table to Iceberg. - Writing to Hudi. Apache Doris is a reader for Hudi today; use Spark or Flink for Hudi writes.
Further reading
- Multi Catalog: how Doris federates external catalogs and routes queries across them.
- Iceberg catalog reference: full DDL, DML, branch and tag, and table-action syntax with version notes.
- Hive catalog reference: write semantics, transactional table support, concurrent-write rules.
- Paimon catalog reference: read, time travel, batch incremental, branch and tag, system tables.
- Lakehouse overview: where managed lake tables fit in the broader federated-analytics story.
- Data Update and Delete: the internal-table counterpart for high-frequency row-level changes.
- Iceberg: the Iceberg-specific surface: seven catalog backends, V2/V3 deletes, branches, tags, and time travel.