Pipeline Execution Engine
TL;DR The Apache Doris pipeline execution engine has been the only execution engine since v3.0, replacing the legacy volcano model. Each query fragment is split into a DAG of pipelines that start at a source, end at a sink, and run as PipelineTasks on a fixed-size BE thread pool bounded by the BE's CPU budget. Operators yield instead of blocking, dependencies coordinate the DAG, and Local Shuffle re-balances skewed data inside the BE.
Why use the pipeline execution engine in Apache Doris?
The Apache Doris pipeline execution engine fixes three problems that the legacy volcano model could not: unbounded thread counts under concurrency, idle cores on skewed joins and aggregations, and per-fragment-instance tuning that was a guessing game. The volcano model that Apache Doris used to ship gave every fragment instance its own OS thread. With a few concurrent queries this is fine. With a hundred it becomes a problem: thousands of threads stack up, most of them blocked on IO or on each other, and the BE eventually thrashes the kernel scheduler and runs out of memory before it runs out of work.
There are two more wounds the old engine left open. Wide-table aggregations and joins on skewed data underused the cores: when one bucket holds 7 rows and the others hold 1, the 7-row task is the long pole and the rest of the cluster sits idle waiting for it. And tuning concurrency at the fragment-instance level was a guessing game with too many knobs.
Pipeline closes all three. The thread count is bounded, not query-count-bounded. Operators yield when they cannot make progress, freeing threads instead of holding them. And Local Shuffle redistributes skewed data inside the BE so the long pole is short.
What is the Apache Doris pipeline execution engine?
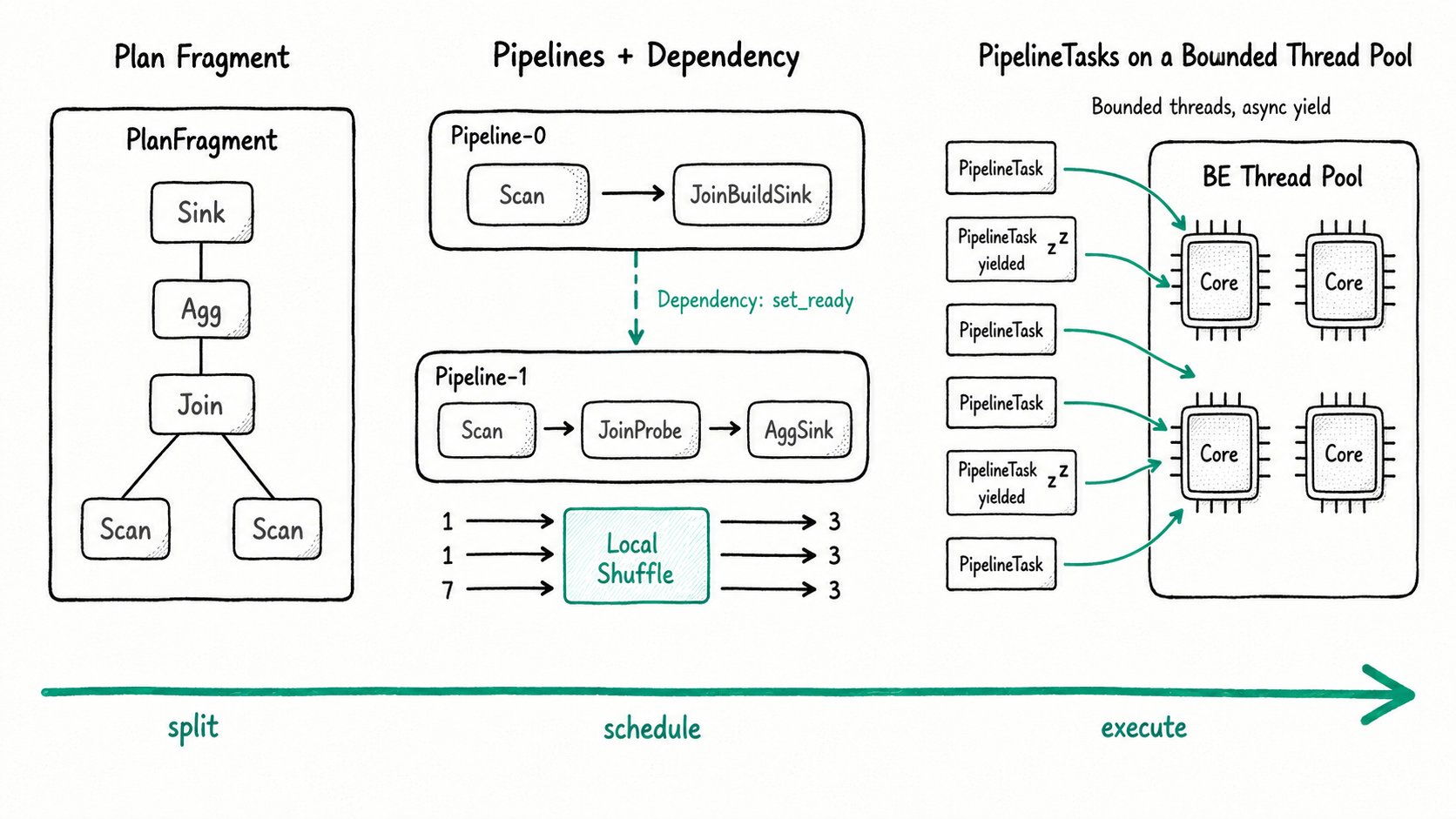
The Apache Doris pipeline execution engine is a push-based, async query execution model that turns each PlanFragment into a DAG of pipelines scheduled on a bounded BE thread pool. The FE compiles the query into a Plan, splits it into PlanFragments (one per BE), and each BE breaks each fragment into a DAG of Pipelines. A Pipeline is a chain that begins with one SourceOperator (a scan or an exchange), ends with one SinkOperator (a network shuffle or a hash-table writer), and may have any number of operators in between. Pipelines that have to wait on each other are coordinated by Dependencies. Each Pipeline materializes into multiple PipelineTasks, one per parallelism slot, that run on a fixed BE-wide thread pool.
Key terms
PlanFragment: the unit of work the FE sends to one BE. A query usually has several.Pipeline: a chain of operators on one BE. Runs as multiple PipelineTasks in parallel.PipelineTask: an executable instance of a pipeline bound to a parallelism slot. Yields when it blocks or when its time slice expires, freeing the thread.Operator: the node in the chain. Some PlanNodes split into a Sink + Source pair when they have to materialize: Join becomesJoinBuildOperator+JoinProbeOperator, Agg becomesAggSinkOperator+AggSourceOperator, Sort becomesSortSinkOperator+SortSourceOperator.Dependency: the ready signal between pipelines. When Pipeline-0 finishes building a hash table it callsset_ready, and Pipeline-1's probe wakes up.- Local Shuffle (Local Exchange): a Pipeline Breaker that re-shards data locally inside the BE using HASH or Round Robin, so a skewed scan does not turn into a skewed join.
parallel_pipeline_task_num: the session knob for per-fragment parallelism. Default0means half the CPU cores; usually best left alone.
How does the Apache Doris pipeline execution engine work?
The Apache Doris pipeline execution engine works in six stages: the FE plans and ships fragments, each BE turns a fragment into a pipeline DAG, PipelineTasks are spawned, they run on a bounded thread pool, Local Shuffle rebalances skewed data, and parallel scan keeps slow buckets from stalling the query.
- FE plans, splits, ships. The FE compiles the query, inserts
ExchangeNodeandDataSinkfor inter-BE shuffle, and sends each PlanFragment to a BE. - BE turns each fragment into a pipeline DAG. Blocking operators (hash-table build, sort, aggregation) become a Sink that ends one pipeline plus a Source that starts the next one. Dependencies wire the DAG together; a Join's probe waits on its build's
set_ready. - Spin up PipelineTasks. Each Pipeline becomes N PipelineTasks. All N share the same Operator chain; what differs is the per-task LocalState (which scan range, which hash-table partition, which output buffer).
- Run on a bounded thread pool. PipelineTasks are submitted to a fixed-size pool sized from the BE's CPU budget (
pipeline_executor_sizeif you override it). A task runs in a tight loop until either its time slice expires (pipeline_task_exec_time_slice, default 100ms) or it blocks on a Dependency. Either way it yields, and the thread picks up the next runnable task. - Local Shuffle when needed. If the planner sees a join, aggregation, or window function over potentially skewed input, it inserts a Local Exchange. Upstream tasks push batches in, downstream tasks pull rebalanced batches out, smoothing
(1, 1, 7)into(3, 3, 3)so every core finishes around the same time. - Parallel scan. A ScanOperator dynamically spawns multiple Scanners under the hood. Each Scanner takes 1 to 2 million rows, decompresses and filters them in place, and pushes the result into a DataQueue that the ScanOperator drains, so a slow bucket does not stall the query.
Quick start
The Pipeline engine is on by default in v3.0+; there is nothing to enable. The one knob you may ever need is parallel_pipeline_task_num.
-- Inspect the default (0 means "half the CPU cores")
SHOW VARIABLES LIKE 'parallel_pipeline_task_num';
-- Pin parallelism for one heavy query without touching the session
SELECT /*+ SET_VAR(parallel_pipeline_task_num=16) */
l_orderkey, COUNT(*) AS lines, SUM(l_extendedprice) AS gross
FROM lineitem
GROUP BY l_orderkey
ORDER BY gross DESC
LIMIT 100;
-- See the resulting plan and Local Exchange placement
EXPLAIN SELECT /*+ SET_VAR(parallel_pipeline_task_num=16) */
l_orderkey, COUNT(*) FROM lineitem GROUP BY l_orderkey;
Expected result
+-------------+-------+----------------+
| l_orderkey | lines | gross |
+-------------+-------+----------------+
| 7382118 | 7 | 431295.18 |
| ... |
+-------------+-------+----------------+
The hint applies only to this query. EXPLAIN shows the pipeline IDs, the Local Exchange (if planned), and the operator chain. With profiling enabled, the runtime profile reports per-PipelineTask ExecTime, YieldCounts, and MemoryReserveFailedTimes, which are the levers you actually use to tune real workloads.
When should you use the Apache Doris pipeline execution engine?
The Apache Doris pipeline execution engine runs every query on v3.0+ by default, so the practical question is when to tune it rather than whether to use it. Use the default for mixed concurrent workloads, join-heavy or skewed queries, and long-running scans; only override parallel_pipeline_task_num when profiling shows a real bottleneck.
Good fit
- Every Apache Doris workload on v3.0+. There is no other engine.
- Mixed concurrent workloads on a shared BE: the bounded thread pool keeps queries from stepping on each other.
- Join-heavy or aggregation-heavy queries on skewed input: Local Shuffle smooths the imbalance instead of letting the long pole drag the wall clock.
- Long-running scans on uneven buckets: parallel scan keeps the slow bucket from stalling the rest.
Not a good fit
- Tuning
parallel_pipeline_task_numon every ad-hoc query. The default is calibrated. Raise it only when profiling shows CPU is idle on a long-running fragment, and drop it to1for high-concurrency or trivial point queries instead. - Reading old advice that mentions enabling
enable_pipeline_engineorexperimental_enable_pipeline_x_engine. Those were experimental switches in the 2.x line; in 3.0+ they are no-ops because the volcano model has been deleted. - Confusing this engine with vectorized execution. They are different layers: vectorized execution decides what an operator does to a batch; Pipeline decides how those batches get scheduled across cores. See Vectorized Execution for the other half.
- Single-row primary-key lookups served at thousands of QPS. The cost of spinning up multiple PipelineTasks is not paid back at that point; use the High-Concurrency Point Query path, which sidesteps the heavy planner.
Further reading
- Pipeline Execution Engine reference: full architecture, including Dependency rules, Local Shuffle planning, and the parallel-scan mechanism.
- Parallelism tuning: when and how to set
parallel_pipeline_task_numper scenario, with the safe defaults table. - Data skew handling: the pragmatic counterpart to Local Shuffle for queries the planner could not auto-fix.
- Vectorized Execution: the operator layer Pipeline schedules. Often confused with Pipeline; the two are orthogonal.
- Workload Group: the layer that binds pipeline threads to per-group cgroups for CPU and concurrency limits.
- Evolution of the Apache Doris execution engine: the design history of how Doris went from volcano to Pipeline to PipelineX.
- MPP Architecture: the cross-BE coordinator above the Pipeline Engine — splits one SQL into a fragment DAG and assigns each fragment to BEs.