Preaggregation and Rollup
TL;DR Apache Doris preaggregation merges rows that share a key at load time using the Aggregate Key model and per-column functions like
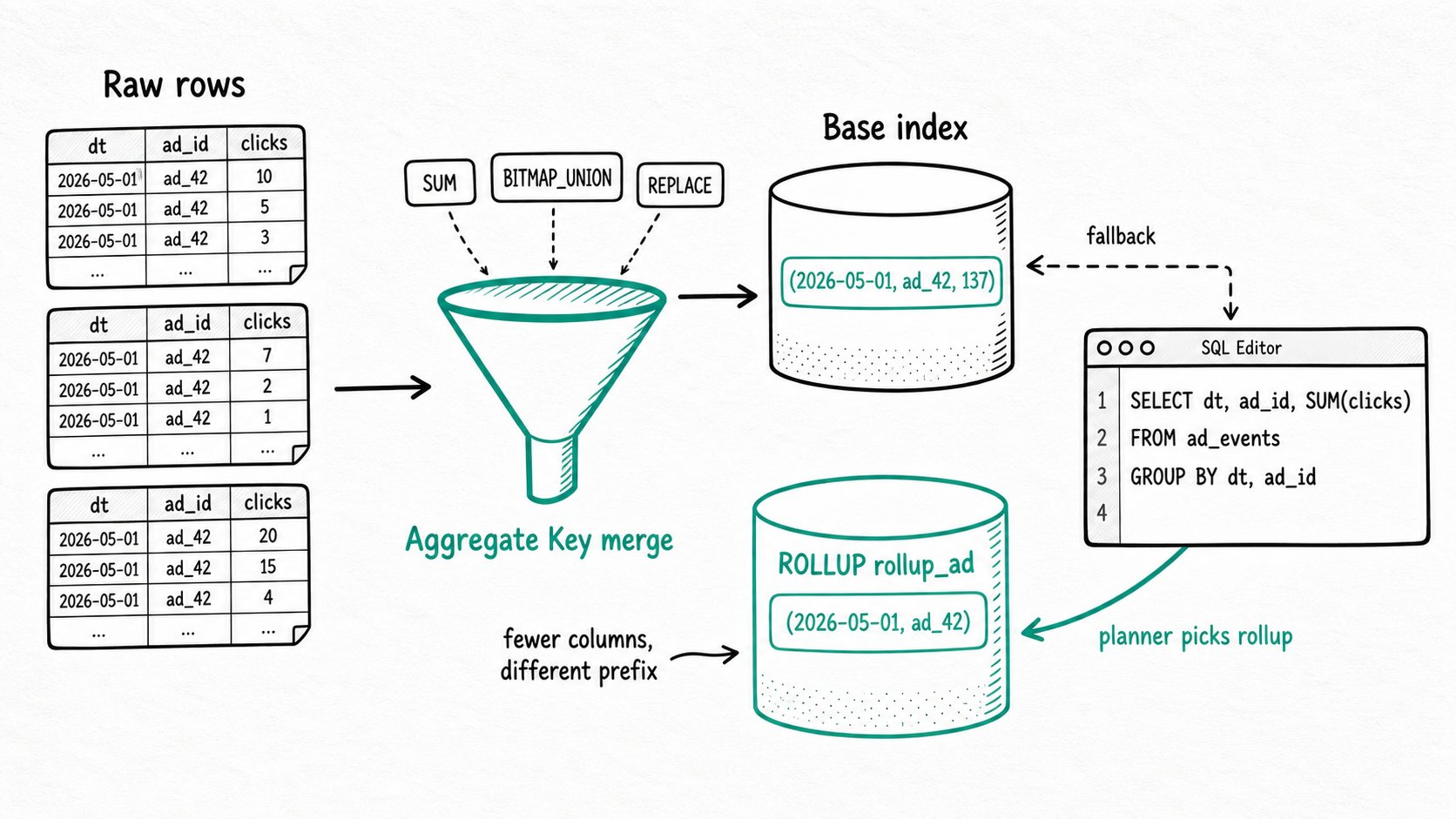
SUM,MAX,REPLACE, andBITMAP_UNION. AROLLUPis a second materialized index — with fewer columns or a different sort order — that the planner transparently picks for queries the base table cannot serve well. Queries read precomputed numbers instead of grouping raw rows on every request.
Why use preaggregation and rollup in Apache Doris?
Apache Doris preaggregation and rollup move repeated GROUP BY work from query time to load time, so dashboards read precomputed totals instead of rescanning the raw fact table on every refresh. A typical fact table is wide and granular: per-event ad clicks, per-request API logs, per-second device readings. The same dashboard then asks for daily totals, top-N users, or distinct viewers across a month. Without preaggregation, every query rescans millions of rows and re-runs the same GROUP BY you ran yesterday.
- Repeated work. Every dashboard refresh redoes the same aggregation over the same raw data.
- Wide scans. A coarse query reads every value column on the base table even when it only needs two.
- Cardinality math is expensive.
COUNT(DISTINCT user_id)on a billion-row table is a job, not a query.
Preaggregation moves the cost from query time to load time. A ROLLUP adds a second precomputed view for the queries the base table doesn't fit by itself; for cross-table or partition-mapped rewrites, reach for an incremental materialized view.
What is Apache Doris preaggregation and rollup?
Apache Doris preaggregation is the Aggregate Key table model that merges rows sharing a key using per-column aggregation functions, and a rollup is an extra materialized index over that table that the planner picks transparently. The Aggregate Key model is a table type. You declare which columns are keys and stamp each value column with an aggregation function. Apache Doris then merges rows that share a key both at load and during compaction, so the table never stores duplicates that have a defined merge rule.
A ROLLUP is a second materialized index over the same base table. It holds a column subset, possibly in a different sort order, with the same per-column functions applied. The query planner scores all available indexes for an incoming query and reads from whichever one matches best.
Key terms
- Aggregate Key model: a table model where rows with identical key values are merged using the value columns' declared aggregation functions.
- Aggregation functions:
SUM,MIN,MAX,REPLACE,REPLACE_IF_NOT_NULL,HLL_UNION,BITMAP_UNION,QUANTILE_UNION. These also work onROLLUPvalue columns. - Base index: the on-disk layout that mirrors your
CREATE TABLE. Always present. - Rollup index: an extra materialized layout the planner can read from instead of the base index.
- Sync materialized view: the
CREATE MATERIALIZED VIEWsyntax that supersedesALTER TABLE ADD ROLLUP. Same machinery, richer expressions, recommended for new designs.
How does Apache Doris preaggregation and rollup work?
Apache Doris preaggregation works in five stages: declaring the aggregation contract in DDL, merging rows on load and compaction, adding rollups for skewed query shapes, picking the best index per query, and preferring sync materialized views for new code.
- Define the aggregation contract. In
CREATE TABLE, theAGGREGATE KEY(...)clause names the key columns. Every other column gets a function:clicks BIGINT SUM,last_seen DATETIME REPLACE,unique_users BITMAP BITMAP_UNION. Apache Doris uses these functions to merge any two rows that share the keys. - Merge on load. When data arrives, Backend nodes fold incoming rows against existing rows that share the keys, then write a new immutable rowset. Background compaction merges those rowsets later using the same rules. Queries see the merged view, not the raw inputs.
- Add a rollup for skew query patterns.
ALTER TABLE ad_events ADD ROLLUP rollup_ad (dt, ad_id, clicks, cost)creates a second materialized index sorted by(dt, ad_id). Apache Doris rebuilds it as an asynchronous schema change, then keeps it in sync on every subsequent load inside the same transaction as the base write. - Pick an index per query. The Nereids optimizer scores every index against the query's predicates and group keys. It prefers indexes where the predicate columns sit at the prefix and where fewer columns need scanning. The chosen index shows up in
EXPLAINand in the BE profile. - Use sync MV for new code.
CREATE MATERIALIZED VIEWcovers everythingADD ROLLUPdoes plus expressions likebitmap_union(to_bitmap(user_id)). The Apache Doris source comment is blunt: "In function level, the mv completely covers the rollup in the future." Existing rollups keep working.
Quick start
CREATE TABLE ad_events (
dt DATE,
ad_id INT,
user_id BIGINT,
clicks BIGINT SUM,
cost DECIMAL(10,2) SUM
)
AGGREGATE KEY(dt, ad_id, user_id)
DISTRIBUTED BY HASH(ad_id) BUCKETS 4;
ALTER TABLE ad_events ADD ROLLUP rollup_ad (dt, ad_id, clicks, cost);
SELECT dt, ad_id, SUM(clicks) FROM ad_events
WHERE dt = '2026-05-01' GROUP BY dt, ad_id;
Expected result
EXPLAIN ... shows OlapScanNode: rollupName=rollup_ad
PREAGGREGATION: ON
The rollup drops user_id, so the planner picks it for any aggregate query that groups only by (dt, ad_id). Inserting the same (dt, ad_id, user_id) twice produces one row with summed clicks and cost, and the rollup ends up with one row per (dt, ad_id).
When should you use Apache Doris preaggregation and rollup?
Apache Doris preaggregation fits append-mostly fact tables with stable aggregation patterns, distinct-count and quantile rollups via BITMAP_UNION and HLL_UNION, and dashboards that run the same GROUP BY thousands of times a day. It is not a fit for raw per-row lookups, multi-table joins, or frequent point updates by primary key.
Good fit
- Append-mostly fact tables that get aggregated by a stable handful of dimensions.
- Distinct counts and quantiles.
BITMAP_UNIONandHLL_UNIONlet you merge precomputed sketches across days or partitions in milliseconds. - Top-N or "by hour" reports built from per-event data, where the same
GROUP BYruns thousands of times per day.
Not a good fit
- Tables where you also need raw per-row lookups. Aggregate Key has already merged the raw rows. Use the Duplicate Key model instead, with an async materialized view if you also want preaggregated views.
- Joins across tables. Both
ROLLUPand sync MV are single-table only. Use async materialized views when you need multi-table rewrites or partitioned refresh. - Frequent point updates by primary key. Use the Unique Key model with merge-on-write.
- Greenfield design that reaches for
ALTER TABLE ADD ROLLUP. WriteCREATE MATERIALIZED VIEWinstead. The grammars differ but the runtime is shared, and the MV path is where new features land.
Further reading
- Data Model: why Aggregate Key is one of three table models and where Duplicate Key and Unique Key fit.
- Aggregate Model: data layout, merge rules, and tuning
- Sync Materialized View: the modern replacement for
ADD ROLLUP - Async Materialized View: multi-table preaggregation with refresh modes
ALTER TABLE ROLLUPsyntax reference