Unique Key
TL;DR The Apache Doris Unique Key model is the primary key table model — one row per primary key, with SQL
UPDATEandDELETElike a transactional database. Partial-column upserts go straight from Stream Load into the table. Since version 2.1 the Unique Key model runs on Merge-on-Write by default, so duplicates are resolved at write time and queries skip version merging at read time.
Why use the Apache Doris Unique Key model?
The Apache Doris Unique Key model gives an OLAP engine real primary-key semantics: one row per key, immediate uniqueness on write, and SQL UPDATE/DELETE that work without partition rewrites. Most analytical engines treat tables as append-only. Then CDC happens. A MySQL row gets updated, a user requests deletion under GDPR, a late event needs to overwrite an older one. With an append-only table model you can record those changes, but you cannot make the warehouse forget the old version without rewriting the whole partition.
- A Flink CDC job watches MySQL and needs every primary-key update to land in seconds.
- An order status table flips through
created,paid,shipped,delivered, and queries should only see the latest state. - A user profile table feeds real-time joins, and the join should never see yesterday's email address.
The Unique Key model is the table model for this. A new write with an existing key replaces the old row, UPDATE and DELETE work as SQL, and analytical queries still run at columnar speed. ClickHouse's ReplacingMergeTree is the closest analog in other OLAP engines, but it does not give you immediate uniqueness: duplicate rows stay visible until a background merge runs, and even after that the engine only guarantees eventual deduplication. A query right after the write can still see the old version, and SELECT ... FINAL is the workaround that forces dedup at read time, at a real cost. Unique Key skips that compromise. The new row replaces the old one at write time, and the next query sees one row per key.
What is the Apache Doris Unique Key model?
The Apache Doris Unique Key model is a table model that keeps exactly one row per primary key, enforced at write time by the Merge-on-Write engine. The UNIQUE KEY(...) clause in CREATE TABLE names the key columns; everything else is a value column. Two rows with the same key cannot coexist. A new write with an existing key replaces the row.
... UNIQUE KEY(order_id) ...
... UNIQUE KEY(tenant_id, user_id) ...
The FE catalog records this as KeysType.UNIQUE_KEYS, the contract the storage engine enforces from then on. The model is fixed at create time and cannot be altered later.
Key terms
- Primary key: the columns named in
UNIQUE KEY(...). They both sort the data on disk and enforce uniqueness. - Value columns: every other column. Stored as written, with no aggregation.
- Merge-on-Write (MoW): the default backend since 2.1. New writes look up the existing row, flip its row ID in a per-rowset delete bitmap, and append the new row to a fresh rowset.
- Merge-on-Read (MoR): the older backend. Writes append; reads merge multiple versions per key on the fly. Still selectable via
enable_unique_key_merge_on_write = false. - Delete bitmap: a Roaring bitmap keyed by
(rowset_id, segment_id, version)listing row IDs that queries should skip. The MoW artifact that replaces read-time merging. - Sequence column (
function_column.sequence_col): a value column that decides which write wins when two updates carry the same key. Out-of-order CDC events use this to keep the newer state. - Partial column update: an upsert that writes only some columns. Apache Doris reads the rest from the existing row and writes a complete row back.
__DORIS_DELETE_SIGN__: a hidden tinyint column. Set it to1through any load path to soft-delete the row.
How does the Apache Doris Unique Key model work?
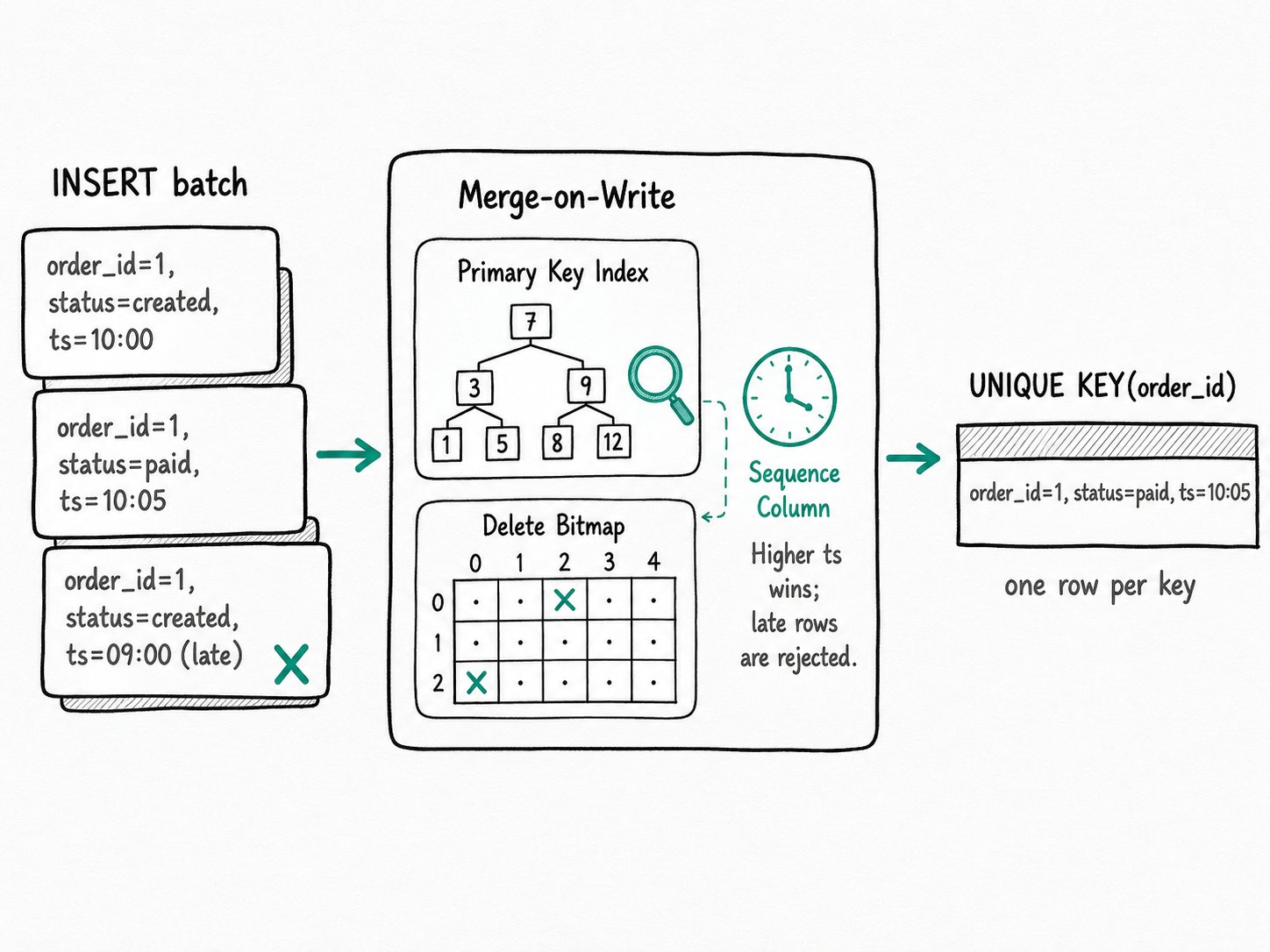
The Apache Doris Unique Key model runs each upsert in five stages: buffer the batch, look up keys in the per-segment primary-key index, flip delete-bitmap bits on old rows, resolve order with the sequence column, and publish the new rowset.
Take an upsert against a Unique Key MoW table.
- Buffer the batch. BEs collect the incoming rows in a memtable and sort them by key.
- Look up each key. For every key in the batch, the BE consults the per-segment primary-key index (one short read per key) to find any existing rowset and row ID. The index is a sorted, paginated structure built when each segment flushed, conceptually similar to a RocksDB partitioned index.
- Mark the old rows. Each affected rowset gets the old row IDs flipped on in its delete bitmap. The bitmap is per
(rowset_id, segment_id, version)and the old data stays on disk until compaction reclaims it. - Resolve order with the sequence column. If
function_column.sequence_colis set, MoW compares the incoming row's sequence value against the current row's__DORIS_SEQUENCE_COL__. The larger value wins. Equal values fall back to load order. The sequence type must be an integer orDATE/DATETIME. - Publish the new rowset. The transaction commits, the new version becomes visible, and queries from that point on filter through the merged delete bitmap. No version-merging step at read time.
DELETE FROM ... WHERE follows the same flow without the new rowset. Partial updates add one step: before writing, the BE reads the unmodified columns for each key so it can store a complete row.
Quick start
CREATE TABLE orders (
order_id BIGINT,
status VARCHAR(20),
amount DECIMAL(10, 2),
updated DATETIME
)
UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 4
PROPERTIES ("function_column.sequence_col" = "updated");
INSERT INTO orders VALUES
(1, 'created', 99.50, '2026-05-08 10:00:00'),
(1, 'paid', 99.50, '2026-05-08 10:05:00'),
(1, 'created', 99.50, '2026-05-08 09:00:00'); -- late event
Expected result
+----------+--------+--------+---------------------+
| order_id | status | amount | updated |
+----------+--------+--------+---------------------+
| 1 | paid | 99.50 | 2026-05-08 10:05:00 |
+----------+--------+--------+---------------------+
Three inserts, one row. The second INSERT overwrote the first because the keys matched. The third tried to overwrite again, but its updated value was older than the current sequence, so MoW kept the existing row. Drop the function_column.sequence_col property and the third row would have won purely on load order, which is what you do not want for CDC.
When should you use the Apache Doris Unique Key model?
The Apache Doris Unique Key model fits CDC sinks, real-time dimension and lookup tables, frequently changing order/user/balance tables, KV-style point lookups paired with store_row_column, GDPR row-level deletes, and wide-table assembly from multiple upstreams. It is not a fit for append-only event streams, tight single-row update loops, random or very wide primary keys, or count(*)-heavy workloads on the older Merge-on-Read backend.
Good fit
- CDC sinks from MySQL, Postgres, or any source with a primary key. Pair with a sequence column on the source's commit timestamp or LSN. See Kafka CDC Integration.
- Real-time dimension and lookup tables joined into fact-table queries.
- Order, user, balance, or session-state tables that change frequently and are queried analytically.
- KV-style point lookups, when you combine MoW with
store_row_columnand a prepared statement. See High-Concurrency Point Query. - GDPR row-level deletes by user ID, including soft-deletes through
__DORIS_DELETE_SIGN__for any load path. - Wide-table assembly where each upstream owns a column group and writes only its columns via
partial_columns: trueStream Load. See Partial Column Update.
Not a good fit
- Append-only event streams (logs, clickstreams, IoT readings). You pay the per-write key-index lookup for capability you do not use. Pick the Duplicate Key model instead. See Data Model.
- Tight loops of single-row
UPDATEs. Each statement is its own transaction, and commit overhead dominates. Batch through Stream Load withpartial_columns: true, or use Group Commit. - Random or very wide primary keys (UUIDs, long composite keys). Every load batch walks the PK index, and random keys defeat its cache locality. Prefer integers, keep the key narrow, and use the smallest type that fits. Floats, doubles, and complex types like
ARRAY,MAP,STRUCT,JSON, andVARIANTare rejected as key columns outright. - Using the partition key as a superset of the primary key. Partition columns must be a subset of the unique key, never the other way around. Otherwise the same key can land in two partitions and dedup breaks.
- Heavy
count(*)workloads on the MoR variant. MoR rebuilds versions at query time and counting is expensive. Either enable Merge-on-Write (default since 2.1) or, if the data is genuinely append-only, switch to Duplicate.
Further reading
- Unique Key Model: SQL syntax, Merge-on-Write vs. Merge-on-Read, partition rules, and creation properties in detail.
- Data Update and Delete: the SQL surface (
UPDATE,DELETE, partial-column upserts, atomic partition swaps) and the Merge-on-Write internals that power it. - Data Model: how Unique Key compares to Duplicate and Aggregate, and which workloads each model fits.
- Concurrency Control with the Sequence Column: allowed types, null handling, and how out-of-order writes are resolved.
- High-Concurrency Point Query: the short-circuit plan that turns a Unique Key table into a KV store.
- Apache Doris 2.1.0: Merge-on-Write becomes the Unique Key default