VARIANT Data Type
TL;DR Apache Doris
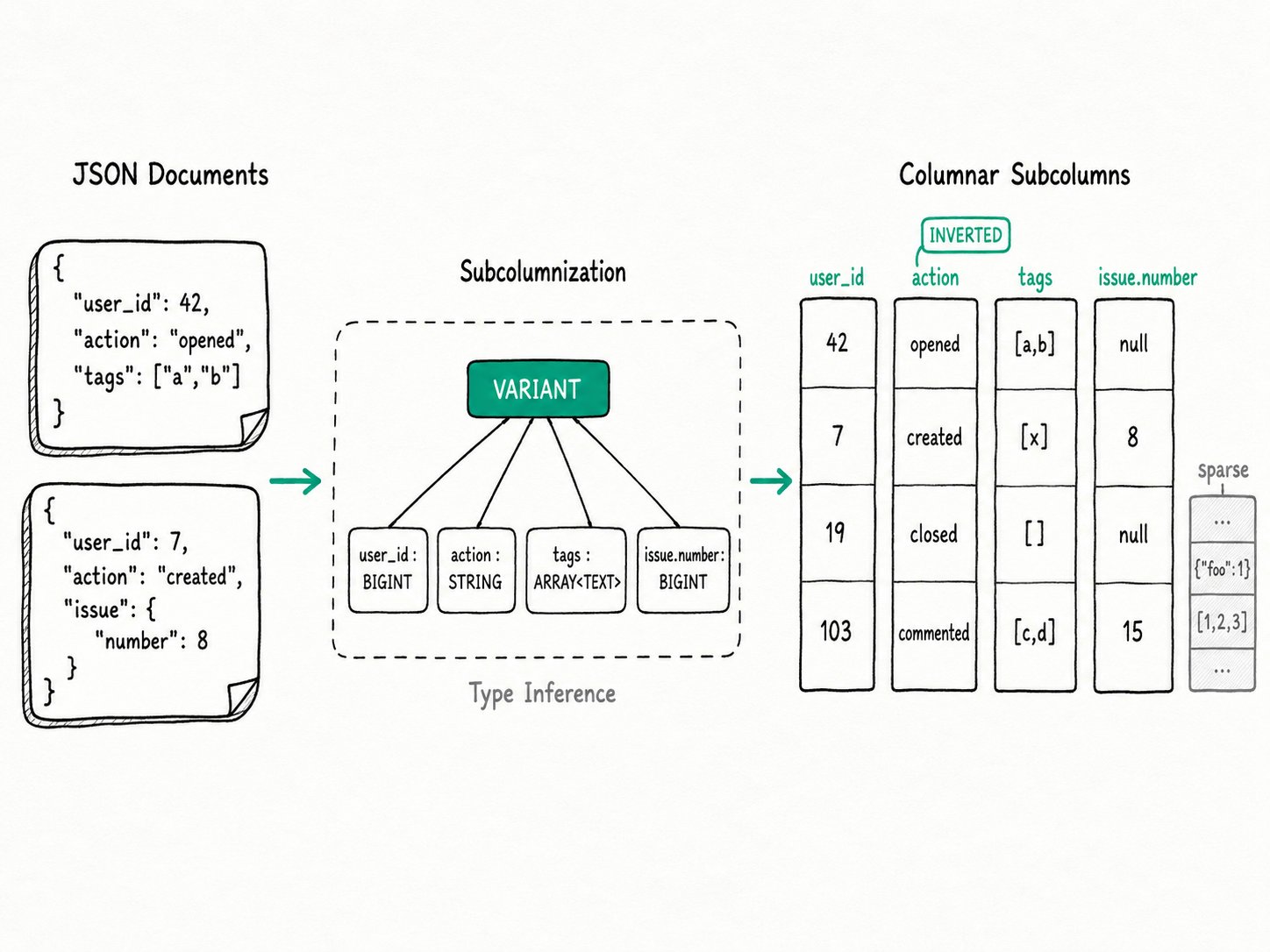
VARIANTis a column type for JSON whose shape changes over time. On write, Apache Doris parses each document, infers a type per JSON path, and persists hot paths as their own columnar subcolumns, defaulting to 2048 subcolumns per VARIANT column. Filters and aggregations onv['user_id']then read one column instead of parsing the whole document. VARIANT went GA in Apache Doris 2.1.0 (March 2024), inspired by Snowflake and ClickHouse.
Why use the VARIANT data type in Apache Doris?
The Apache Doris VARIANT data type ends the old trade-off between flexible JSON storage and column-store query speed. Storing JSON in an OLAP system has been a long compromise.
- A
STRINGorJSONBcolumn keeps you flexible, but every query that touches a path parses the whole document.WHERE payload['action'] = 'opened'over a billion rows reads every byte of every payload, even ifactionis one short field in a fat document. - Static columns are fast, but only if the schema is stable. When producers add fields next sprint, you are back to
ALTER TABLEmigrations or a JSON sidecar column.
Apache Doris VARIANT removes the choice. You declare one column, write JSON into it, and Apache Doris quietly turns the hot paths into real columnar storage. Queries stay in SQL; on disk the table looks a lot like one you would have designed by hand.
What is the Apache Doris VARIANT data type?
The Apache Doris VARIANT data type is a semi-structured column type backed by DataTypeVariant and ColumnVariant (formerly ColumnObject, modeled on ClickHouse's design). VARIANT accepts any valid JSON value: scalars, one-dimensional arrays, and nested objects. As rows arrive, the writer builds a prefix tree of paths, infers a type per path, and writes each path as its own page-encoded, page-indexed column inside the segment. You query JSON; on disk you get one subcolumn per path.
Key terms
Subcolumn: an independent on-disk column generated from a JSON path. Each subcolumn has its own encoding, compression, zone map, and bloom filter, just like a static column.Subcolumnization: the write-time process that promotes hot paths from JSON into subcolumns. Controlled byvariant_max_subcolumns_count, default2048.Schema Template: the optionalVARIANT<'path' : TYPE, ...>clause that pins selected paths to a fixed type so the storage and indexes stay stable across loads.Sparse column: a shared fallback column where long-tail paths land when the path count exceeds the subcolumn budget. One physical column, many logical paths.Type promotion: the rule that decides what to do when the same path arrives asINTin one row andSTRINGin another. Compatible types widen (TINYINTtoBIGINT); incompatible types fall back toJSONB.
How does the Apache Doris VARIANT data type work?
Apache Doris VARIANT works by parsing each JSON document at write time, inferring a type per JSON path, and persisting frequent paths as independent columnar subcolumns while long-tail paths land in a shared sparse column. For one path, the lifecycle on disk:
- Parse and infer. As JSON enters the memtable, the writer adds every leaf path to a prefix tree and picks the narrowest type that fits the values:
BIGINT,DOUBLE,STRING, one-dimensionalARRAY<T>, or a nestedVARIANT. - Promote or fall back. If a new value conflicts with the current type, Doris widens where it can (
TINYINTplusDOUBLEbecomesDOUBLE). If nothing widens, the path falls back toJSONBand queries lose pushdown on that path until the schema is corrected. - Write subcolumns or sparse. Paths with the highest non-null ratio become independent subcolumns, encoded and compressed exactly like static columns. Once
variant_max_subcolumns_countis reached, remaining low-frequency paths are packed into the sparse column. - Merge schemas. Each rowset records its own subcolumn schema. Compaction merges rowsets using the least common column schema, so a new field added today does not require an
ALTER TABLE. - Read by path.
SELECT v['user_id']resolves to one subcolumn and reads only that column, skipping pages by zone map and bloom filter the same way as static columns. Predicates push down:CAST(v['user_id'] AS BIGINT) = 42runs against the typed subcolumn, not the JSON text.
Inverted index works on subpaths the same way. INDEX idx_v(v) USING INVERTED PROPERTIES("parser" = "english") makes every text subcolumn searchable, and a Schema Template lets you pin an index to one specific path.
Quick start
CREATE TABLE github_events (
id BIGINT,
type VARCHAR(30),
payload VARIANT,
created_at DATETIME,
INDEX idx_payload (payload) USING INVERTED PROPERTIES("parser" = "english")
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 4
PROPERTIES ("storage_format" = "V3");
INSERT INTO github_events VALUES
(1, 'PushEvent', '{"action":"opened","commits":[{"sha":"abc"}],"size":4}', '2026-05-01'),
(2, 'IssueCommentEvent', '{"action":"created","issue":{"number":42}}', '2026-05-01');
SELECT CAST(payload['action'] AS STRING) AS action, COUNT(*) AS n
FROM github_events
WHERE payload['action'] MATCH 'opened'
GROUP BY action;
Expected result
+--------+---+
| action | n |
+--------+---+
| opened | 1 |
+--------+---+
The filter reads one subcolumn, hits the inverted index, and never touches the commits array. Run SET describe_extend_variant_column = true; DESC github_events; to see the inferred subcolumns (payload.action, payload.commits, payload.issue.number, ...) as if you had declared them by hand.
When should you use the Apache Doris VARIANT data type?
Use Apache Doris VARIANT when the JSON schema evolves but most queries hit a handful of familiar paths. Stick to static columns or STRUCT when the shape is fixed, and avoid VARIANT for primary, sort, or join keys.
Good fit
- Event logs and audit payloads where most queries hit a few familiar paths and the rest of the document is along for the ride.
- Telemetry and user-profile tables where producers keep adding fields and you cannot block ingest on a schema migration.
- Observability data with thousands of optional tags. Hot tags become subcolumns; the long tail goes to the sparse column without bloating compaction.
- Full-text search inside JSON, by combining
VARIANTwithUSING INVERTED.
Not a good fit
- Tables with a stable, well-understood schema. Plain typed columns are simpler to reason about, simpler to index, and they cannot accidentally promote to
JSONB. Reach forVARIANTonly when the schema actually changes. - Primary keys, sort keys, or join keys.
VARIANTcannot serve as either, andCAST(v['id'] AS BIGINT)as a join condition gives up most of the planner's options. Ifidis the join key, declare it as a staticBIGINT. - Whole-document searches like
WHERE v LIKE '%doris%'. The inverted index lives on subpaths, not the whole column. Keep the original JSON in a parallelSTRINGcolumn and index that, or enable DOC mode for fastSELECT v. - Fixed shapes you already know at design time. If every row has exactly
{a, b, c}and the types never change,STRUCTis a better contract: it forbids unexpected fields, whereVARIANTsilently absorbs them. - Very wide JSON (10k+ paths) without tuning. Default subcolumnization caps at 2048 paths. Beyond that, plan for sparse columns or DOC mode and read the VARIANT Workload Guide before loading production data.
Performance / numbers
- ClickBench, 43 queries on a 16-core / 64 GB EC2 instance: VARIANT used 12.7 GB versus 35.7 GB for JSON (~65% less), with hot-run queries about 8x faster than JSON and within ~10% of predefined static columns. Source: Variant in Apache Doris 2.1.0.
- GuanceDB migrating observability from Elasticsearch to Doris on VARIANT: machine cost down 70%, overall query speed ~2x, simple queries 4x+ faster. Source: same post.
Further reading
- VARIANT SQL reference: full syntax, type rules, indexes, configuration
- VARIANT Workload Guide: when to pick default, sparse, DOC mode, or Schema Template
- Importing VARIANT data: Stream Load, Routine Load, and Broker Load examples
- Columnar Storage feature card: how subcolumns are encoded, paged, and indexed under the hood
- Inverted Index overview: the index VARIANT uses for text-in-JSON search
- LLM SQL Functions: the
AI_*family whose JSON output (fromAI_EXTRACT,AI_CLASSIFY, and so on) is a natural fit for a VARIANT column. - Apache Doris blog: Variant in Apache Doris 2.1.0, the original announcement and benchmarks