Vertical Compaction
TL;DR Apache Doris vertical compaction splits a wide table's schema into small column groups and merges one group at a time, instead of holding every column in memory like the classic row-wise compaction. The algorithm cuts compaction memory to roughly 1/10 and runs about 15% faster on wide tables, using a per-row sequence marker built from the key columns to keep the output identical. Vertical compaction has been enabled by default since Apache Doris 1.2.2.
Why use vertical compaction in Apache Doris?
Vertical compaction keeps Apache Doris compaction memory bounded on wide tables, where row-wise merging would otherwise pull every column into memory at once and OOM the BE. Compaction itself is the background job that merges a tablet's rowsets into fewer, bigger ones so queries don't have to walk across hundreds of versions. The classic algorithm reads one row from each input rowset, picks a winner, writes it out, and repeats. That works fine on a 5-column fact table. It falls over on a 200-column user table — especially when those columns hold sprawling VARIANT JSON payloads:
- A merging block has to hold every column for every row in the batch. Memory scales with column count and with batch size at the same time.
- The Backend (BE) runs many compaction tasks in parallel. Even a few wide-table tasks can push a node into OOM territory.
- Operators throttle the compaction thread pool to keep memory under control, rowsets then pile up, and loads start failing with error -235 once a tablet's version count exceeds
max_tablet_version_num.
Vertical compaction is the fix. It changes the unit of merging from "one row across all columns" to "one column group at a time across all rows," and pays for that with one extra structure: a per-row sequence marker.
What is Apache Doris vertical compaction?
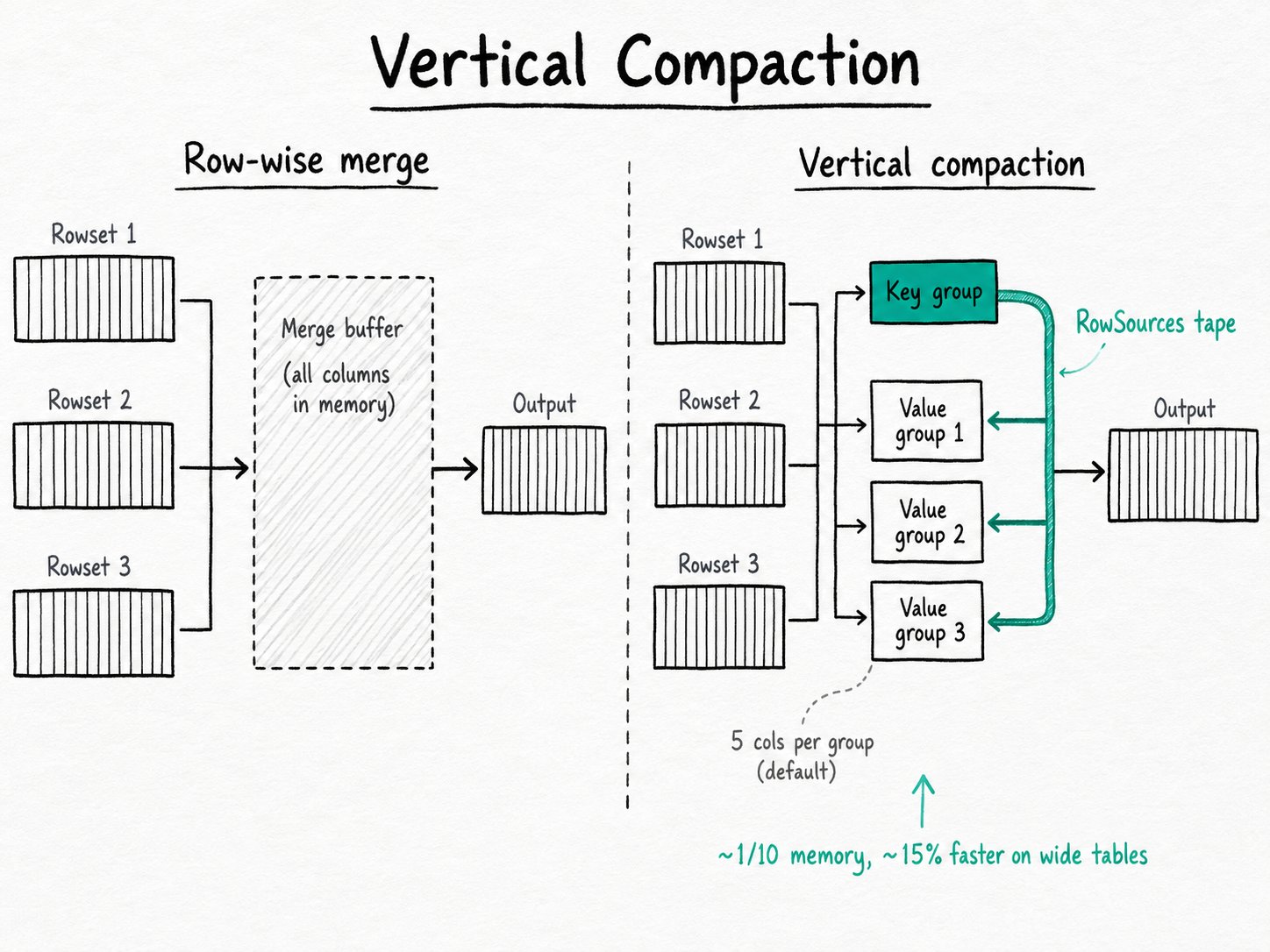
Apache Doris vertical compaction is a compaction algorithm that merges columns in groups rather than merging rows. The Backend splits the table schema into a key-column group plus several value-column groups (5 columns per group by default), merges the key group first to fix a global ordering, then merges each value group by replaying that ordering. The output rowset matches what row-wise compaction would produce; only the memory profile changes.
Key terms
Column group: a fixed-size slice of the schema. Default is 5 columns per group, configurable per table.Key group: the first group, built from the table's key columns. Merging this group decides the row order of the output.RowSourcesBuffer: an on-disk-backed buffer that records, for every output row, which input rowset and which input row it came from. Capped at 1 GB by default.Vertical merge iterator: the BE component that scans a single column group from all input rowsets and emits the merged column.enable_vertical_compaction: BE config flag,trueby default. Disabling it falls back to row-wise compaction.
How does Apache Doris vertical compaction work?
Apache Doris vertical compaction works by splitting the schema into column groups, merging the key group first to fix the row order, then replaying that order for every value group so non-group columns never sit in memory. The five-step flow below covers split, merge, replay, stitch, and spill.
- Split the schema into groups. The BE walks the tablet schema, puts the key columns into group 0, and chunks the remaining columns into groups of
vertical_compaction_num_columns_per_group(default 5). Whenenable_vertical_compact_variant_subcolumnsis on, the BE folds variant subcolumns into the same flow. - Merge the key group and record the order. The Merger heap-sorts the key columns across all input rowsets. As each row leaves the heap, it writes one entry into the RowSourcesBuffer recording where the row came from. The output of this pass is a sorted key column plus a global RowSources tape.
- Replay the tape for each value group. For every value group, the BE opens the same input rowsets, but only reads the columns in that group. It uses the RowSources tape, not a heap, to pick the next input. No comparison work, no holding non-group columns in memory.
- Stitch the groups into one rowset. The output writer assembles the groups into a single segment file. The result matches row-wise compaction byte for byte, including delete-bitmap and inverted-index updates.
- Spill the tape if it grows. RowSourcesBuffer is capped by
vertical_compaction_max_row_source_memory_mb(1 GB). If a merge produces more rows than the cap allows, the buffer spills to the tablet directory and streams during step 3.
One trade-off: vertical compaction reads each input rowset once per group instead of once total. On disk-bound clusters the IO cost goes up roughly by (num_groups - 1). The memory savings usually win, which is why it's the default. On narrow tables (5 columns or fewer) the schema produces exactly one group anyway and the algorithm degenerates back to the row-wise path.
Quick start
Vertical compaction is on by default. The example below shows the per-table override that controls how aggressively a wide table groups its columns:
CREATE TABLE user_profile (
user_id BIGINT,
name VARCHAR(64), age INT, country VARCHAR(32), city VARCHAR(64),
attr_01 STRING, attr_02 STRING, attr_03 STRING, attr_04 STRING,
attr_05 STRING, attr_06 STRING, attr_07 STRING, attr_08 STRING
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 4
PROPERTIES (
"vertical_compaction_num_columns_per_group" = "3"
);
SHOW CREATE TABLE user_profile;
Expected result
+--------------+--------------------------------------------------+
| Table | Create Table |
+--------------+--------------------------------------------------+
| user_profile | ... "vertical_compaction_num_columns_per_group" |
| | = "3" ... |
+--------------+--------------------------------------------------+
A group size of 3 trades a bit more IO for tighter memory use, which is what you want on tables with many large STRING or JSONB columns. Verify it took effect with SHOW CREATE TABLE. To roll the change back to defaults, drop the property with ALTER TABLE.
When should you use Apache Doris vertical compaction?
Use Apache Doris vertical compaction on wide schemas, on tablets that OOM under row-wise compaction, and on tables with sparse VARIANT subcolumns. Skip the tuning on narrow tables and on disk-bound clusters where extra read passes hurt more than the memory savings help.
Good fit
- Wide schemas: dozens of columns or more, especially when most columns are variable-length (
STRING,JSONB,ARRAY,MAP). The bigger the schema, the bigger the win. - Tablets that hit compaction OOM with the row-wise algorithm. Drop the group size from 5 to 2 or 3 instead of throttling the thread pool.
- Tables with sparse
VARIANTsubcolumns. The same code path also drivesenable_vertical_compact_variant_subcolumns, which avoids materializing absent subcolumns during merge. - Slow base compaction on wide tables. Smaller working sets per group keep the merge in CPU cache.
Not a good fit
- Narrow tables (one to five columns). The schema produces a single column group and you pay the row-source bookkeeping for no benefit. Harmless, but pointless.
- Tablets with a sequence-map column. The current implementation skips vertical compaction in that case (see
_tablet->tablet_schema()->has_seq_map()incompaction.cpp); merges fall back to the row-wise path automatically. - Disk-bound clusters where compaction IO already dominates. The extra read passes per group can amplify the bottleneck. Either widen the groups (raise
vertical_compaction_num_columns_per_group) or fix the IO ceiling first. - Treating vertical compaction as a fix for too-frequent loads. Memory pressure during compaction is often a symptom of pile-up, not the root cause. See Data Compaction and Group Commit for the load-side levers.
Performance / numbers
- Memory: roughly 1/10 of row-wise compaction on wide tables. Source: Doris compaction tuning docs.
- Throughput: about 15% faster end-to-end on the same wide-table benchmark. Source: same.
- Available since: Doris 1.2.2; default
truein current releases.
Further reading
- Data Compaction: how cumulative, base, and time-series policies sit on top of vertical compaction.
- Compaction tuning: vertical, segment, single-replica, time-series: operator-level knobs for every compaction variant.
- Compaction principles, types, and scheduling: the scoring and scheduling logic that picks which tablets to compact next.
- BE config reference: every
vertical_compaction_*flag with its default and unit. - Understanding Data Compaction in 3 Minutes (blog): the original write-up that introduces vertical compaction with diagrams.
- Unique Key: the table model that produces the per-rowset delete bitmaps vertical compaction has to reconcile.